How to select anchor tag text element and click using By.LINK_TEXT
How to scrape all second/third/four td element of every tr(for loop)
How to scrape data td or tr elements By TAG_NAME
How to scrape inner tag of table or tbody
How to replace $ to rs from all element of list using for loop,listcomprhension,reg exp,lambda
How to remove $ from all element of list using for loop,listcomprhension,reg exp,lambda
Learning Points
Use of list slicing to get 20 records
Use of len to know total no of elments(tr/td)
Use of append to store data in list
Step 1: install selenium using python
pip install --upgrade selenium
Step 2: Import Required Libraries
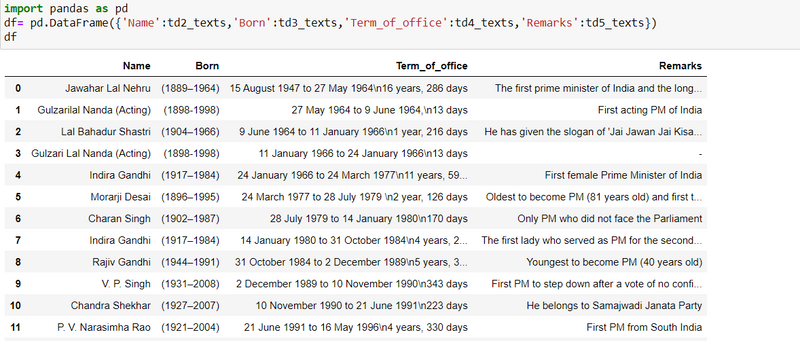
import pandas as pd
from selenium import webdriver
import warnings
warnings.filterwarnings('ignore')
from selenium.webdriver.common.by import By
import time
Step 3: Start a WebDriver Instance
driver=webdriver.Chrome()
Step 4: Navigate to a Webpage
Navigate to the webpage where you want to interact with the search input bar:
driver.get('https://www.jagranjosh.com/')
Step 5: click anchor tag text GK element
anchor_tag = driver.find_element(By.LINK_TEXT, 'GK')
anchor_tag.click()
Step 6: click inner page anchor tag text List of all Prime Ministers of India element
anchor_tag = driver.find_element(By.LINK_TEXT, 'List of all Prime Ministers of India')
anchor_tag.click()
Step 7:scrape the all name
How to scrape all second/third/four td element of every tr(for loop)
step1:find all tr elements by tag name
step2:apply for loop in above found all tr elements
step3:find all td elements by tag name
step5: if length of td contain more than two/three/four
step6: store all td data in list using append
step7:get only 19 element using list slicing
tr_elements = driver.find_elements(By.TAG_NAME, 'tr')
# Initialize an empty list to store the text from the second <td> in each <tr>
td2_texts = []
# Iterate through the <tr> elements and extract text from the second <td> in each
for tr in tr_elements:
# Find all <td> elements within the current <tr>
td_elements = tr.find_elements(By.TAG_NAME, 'td')
# Check if there are at least two <td> elements in the current <tr>
if len(td_elements) >= 2:
# Extract the text from the second <td> and append it to the list
td2_texts.append(td_elements[1].text)
td2_texts= td2_texts[:19]
td2_texts
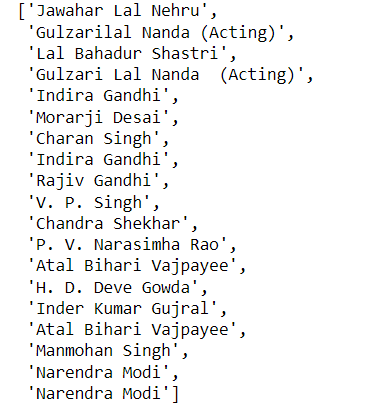
Step 8: Scrape the all born date results
tr_elements = driver.find_elements(By.TAG_NAME, 'tr')
# Initialize an empty list to store the text from the second <td> in each <tr>
td3_texts = []
# Iterate through the <tr> elements and extract text from the second <td> in each
for tr in tr_elements:
# Find all <td> elements within the current <tr>
td_elements = tr.find_elements(By.TAG_NAME, 'td')
# Check if there are at least two <td> elements in the current <tr>
if len(td_elements) >= 3:
# Extract the text from the second <td> and append it to the list
td3_texts.append(td_elements[2].text)
td3_texts
output

Step 9: Scrape the all term_of_office results
tr_elements = driver.find_elements(By.TAG_NAME, 'tr')
# Initialize an empty list to store the text from the second <td> in each <tr>
td4_texts = []
# Iterate through the <tr> elements and extract text from the second <td> in each
for tr in tr_elements:
# Find all <td> elements within the current <tr>
td_elements = tr.find_elements(By.TAG_NAME, 'td')
# Check if there are at least two <td> elements in the current <tr>
if len(td_elements) >= 4:
# Extract the text from the second <td> and append it to the list
td4_texts.append(td_elements[3].text)
td4_texts
output
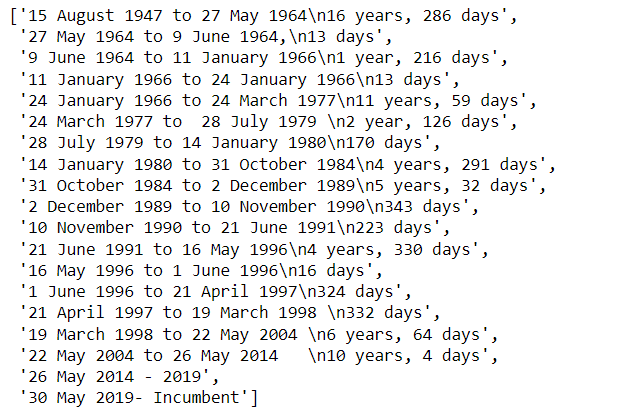
Step 10: Scrape the all remark
tr_elements = driver.find_elements(By.TAG_NAME, 'tr')
# Initialize an empty list to store the text from the second <td> in each <tr>
td5_texts = []
# Iterate through the <tr> elements and extract text from the second <td> in each
for tr in tr_elements:
# Find all <td> elements within the current <tr>
td_elements = tr.find_elements(By.TAG_NAME, 'td')
# Check if there are at least two <td> elements in the current <tr>
if len(td_elements) >= 5:
# Extract the text from the second <td> and append it to the list
td5_texts.append(td_elements[4].text)
td5_texts
output
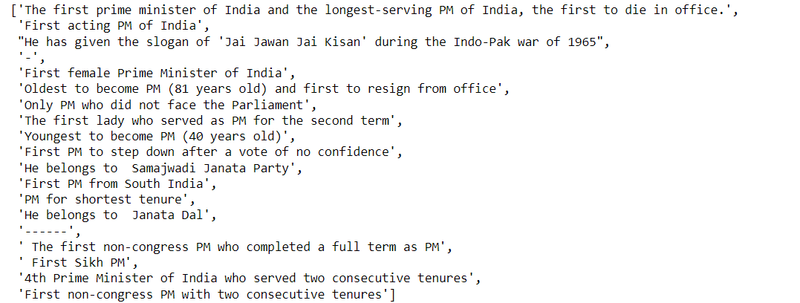
step11: make a dataframe
==========================================================
Write a python program to scrape the details for all billionaires from www.forbes.com. Details to be scrapped:
“Rank”, “Name”, “Net worth”, “Age”, “Citizenship”, “Source”, “Industry”.
Step 1: install selenium using python
pip install --upgrade selenium
Step 2: Import Required Libraries
import pandas as pd
from selenium import webdriver
import warnings
warnings.filterwarnings('ignore')
from selenium.webdriver.common.by import By
import time
Step 3: Start a WebDriver Instance
driver=webdriver.Chrome()
Step 4: Navigate to a Webpage
Navigate to the webpage where you want to interact with the search input bar:
driver.get("https://www.forbes.com/real-time-billionaires/#583345d23d78")
step 5: scrape the name results
How to scrape inner tag of table or tbody
element = driver.find_elements(By.XPATH, '//table[@class="ng-scope ng-table"]/tbody/tr/td[3]/div[1]/h3')
name=[]
for element in element:
elements=element.text
name.append(elements)
name
output

step 6: scrape the rank results
element = driver.find_elements(By.XPATH, '//table[@class="ng-scope ng-table"]/tbody/tr/td[2]/div/span')
rank=[]
for element in element:
elements=element.text
rank.append(elements)
rank
output

step 7: scrape the net worth results
element = driver.find_elements(By.XPATH, '//table[@class="ng-scope ng-table"]/tbody/tr/td[4]/div/span')
net_worth=[]
for element in element:
elements=element.text
net_worth.append(elements)
net_worth
replace $ to rs using 4 methods
How to replace $ to rs from all element of list using for loop,listcomprhension,reg exp,lambda **
**How to remove $ from all element of list using for loop,listcomprhension,reg exp,lambda
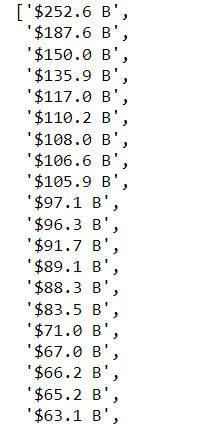
element = driver.find_elements(By.XPATH, '//table[@class="ng-scope ng-table"]/tbody/tr/td[4]/div/span')
net_worth=[]
for element in element:
elements=element.text
net_worth.append(elements)
net_worth = ["rs" + item[1:] for item in net_worth]
net_worth
output
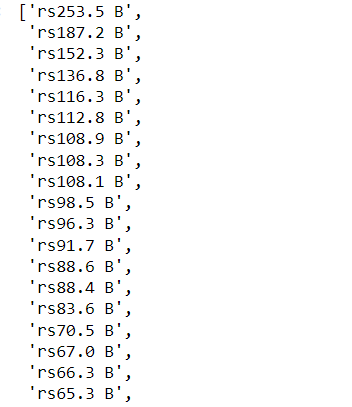
=====================================
element = driver.find_elements(By.XPATH, '//table[@class="ng-scope ng-table"]/tbody/tr/td[4]/div/span')
net_worth=[]
for element in element:
elements=element.text
net_worth.append(elements)
for item in net_worth:
# Remove the dollar sign "$" and add "rs" to the beginning of each item
updated_item = "rs" + item[1:]
updated_list.append(updated_item)
updated_list
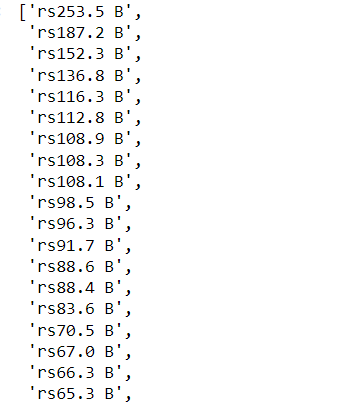
import re
element = driver.find_elements(By.XPATH, '//table[@class="ng-scope ng-table"]/tbody/tr/td[4]/div/span')
net_worth=[]
for element in element:
elements=element.text
net_worth.append(elements)
pattern = re.compile(r'\$')
# Initialize an empty list to store the modified strings
updated_list = []
# Iterate through the original list
for item in net_worth:
# Use the sub() method to replace "$" with "rs"
updated_item = pattern.sub('rs', item)
updated_list.append(updated_item)
updated_list
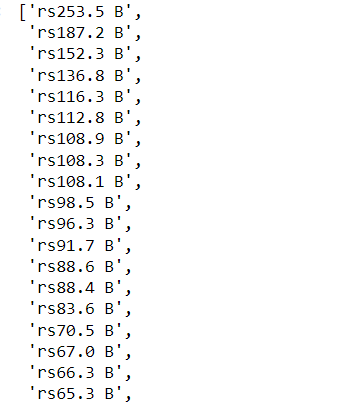
element = driver.find_elements(By.XPATH, '//table[@class="ng-scope ng-table"]/tbody/tr/td[4]/div/span')
net_worth=[]
for element in element:
elements=element.text
net_worth.append(elements)
updated_list = []
updated_list = list(map(lambda x: x.replace('$', 'rs'), net_worth))
updated_list
remove $ from all elements of list
element = driver.find_elements(By.XPATH, '//table[@class="ng-scope ng-table"]/tbody/tr/td[4]/div/span')
net_worth=[]
for element in element:
elements=element.text
net_worth.append(elements)
updated_list = [item.replace('$', '') for item in net_worth]
updated_list
output

===================
element = driver.find_elements(By.XPATH, '//table[@class="ng-scope ng-table"]/tbody/tr/td[4]/div/span')
net_worth=[]
for element in element:
elements=element.text
net_worth.append(elements)
updated_list = []
for item in net_worth:
updated_item = item.replace('$', '')
updated_list.append(updated_item)
updated_list
=======================
element = driver.find_elements(By.XPATH, '//table[@class="ng-scope ng-table"]/tbody/tr/td[4]/div/span')
net_worth=[]
for element in element:
elements=element.text
net_worth.append(elements)
updated_list = []
pattern = re.compile(r'\$')
updated_list = [pattern.sub('', item) for item in net_worth]
updated_list
element = driver.find_elements(By.XPATH, '//table[@class="ng-scope ng-table"]/tbody/tr/td[4]/div/span')
net_worth=[]
for element in element:
elements=element.text
net_worth.append(elements)
updated_list = []
updated_list = list(map(lambda x: x.replace('$', ''), net_worth))
updated_list
step 8: scrape the age results
element = driver.find_elements(By.XPATH, '//table[@class="ng-scope ng-table"]/tbody/tr/td[6]/div/span')
age=[]
for element in element:
elements=element.text
age.append(elements)
age
output

step 9: scrape the source results
element = driver.find_elements(By.XPATH, '//table[@class="ng-scope ng-table"]/tbody/tr/td[7]/div/span')
source=[]
for element in element:
elements=element.text
source.append(elements)
source
output

step 10: scrape the citizenship results
element = driver.find_elements(By.XPATH, '//table[@class="ng-scope ng-table"]/tbody/tr/td[8]/div/span')
citizenship=[]
for element in element:
elements=element.text
citizenship.append(elements)
citizenship
output

step 11: make a dataframe
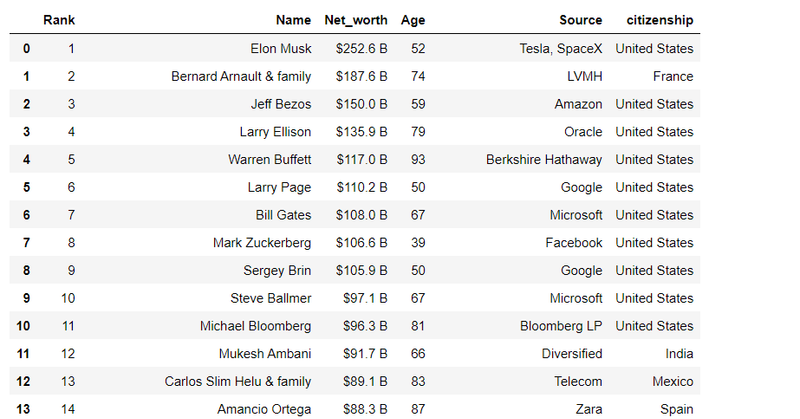
import pandas as pd
df= pd.DataFrame({'Rank':rank,'Name':name,'Net_worth':net_worth,'Age':age,'Source':source,'citizenship':citizenship})
df

Top comments (0)