Scrape the current driver url
How to get specific page detail using range methods
best practice: after button click apply time.sleep to load page fully
Q1. scrape the following details of each product listed in first 3 pages of your search
results and save it in a data frame and csv. In case if any product has less than 3 pages in search results then
scrape all the products available under that product name. Details to be scraped are: "Brand
Name", "Name of the Product", "Price", "Return/Exchange", "Expected Delivery", "Availability" and
Step 1: install selenium using python
pip install --upgrade selenium
Step 2: Import Required Libraries
import pandas as pd
from selenium import webdriver
import warnings
warnings.filterwarnings('ignore')
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException,ElementClickInterceptedException
Step 3: Start a WebDriver Instance
driver=webdriver.Chrome()
Step 4: Navigate to a Webpage
Navigate to the webpage where you want to interact with the search input bar:
driver.get('https://www.amazon.in/')
Step 5: Find the Search Input Element guitar by sending S Keys to the Input Element and then submit button
scrape current page url and current page all product url
wait = WebDriverWait(driver, 10)
search = wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="twotabsearchtextbox"]')))
search.send_keys('Guitar')
search_elements = wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="nav-search-submit-button"]')))
all_urls=[]
search_elements.click()
current_url = driver.current_url
all_urls.append(current_url)
heading = driver.find_elements(By.XPATH, '//div[@class="a-section a-spacing-small puis-padding-left-small puis-padding-right-small"]/div[1]/h2/a')
mylist=[]
for element in heading:
text = element.get_attribute('href')
mylist.append(text)
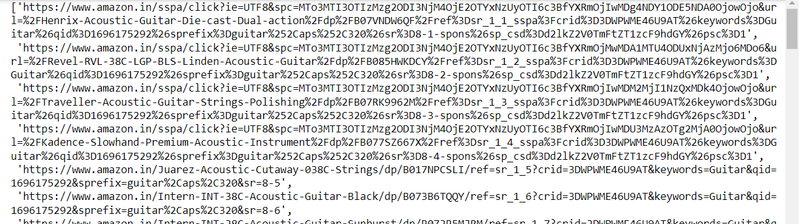
mylist
output
Step6:scrape next 3 page url and their all product url
Scrape the current driver url
How to get specific page detail using range methods
import time
time.sleep(5)
# Create an empty list to store the URLs
for page in range(0, 2):
try:
# Find and click the "Next" button
next_button = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.LINK_TEXT, 'Next')))
next_button.click()
# Wait for the new page to load (you may need to adjust the wait time)
time.sleep(5)
# Get the current page's URL and add it to the list
current_url = driver.current_url
all_urls.append(current_url)
heading = driver.find_elements(By.XPATH, '//div[@class="a-section a-spacing-small puis-padding-left-small puis-padding-right-small"]/div[1]/h2/a')
for element in heading:
text = element.get_attribute('href')
mylist.append(text)
except (TimeoutException, NoSuchElementException, ElementClickInterceptedException):
# If there's no "Next" button or a timeout occurs, exit the loop
break
len(mylist)
=================Another Methods===================
Step7: scrape each product detail of all 3 pages
import time
brands=[]
products_name=[]
prices=[]
delivery_dates=[]
url=[]
for i in mylist:
driver.get(i)
time.sleep(5)
try:
brand = driver.find_element(By.ID,'productTitle')
brand_text = brand.text
brands.append(brand_text)
product_name = driver.find_element(By.ID,'bylineInfo')
product_name_text = product_name.text
products_name.append(product_name_text)
price = driver.find_element(By.CLASS_NAME,'a-price-whole')
price_text = price.text
prices.append(price_text)
delivery_date = driver.find_element(By.CLASS_NAME,'a-text-bold')
delivery_date_text = delivery_date.text
delivery_dates.append(delivery_date_text)
current_url = driver.current_url
url.append(current_url)
# Perform actions on the element if needed
# For example, to get the text inside the element:
except NoSuchElementException:
break
len(mylist)
output
155
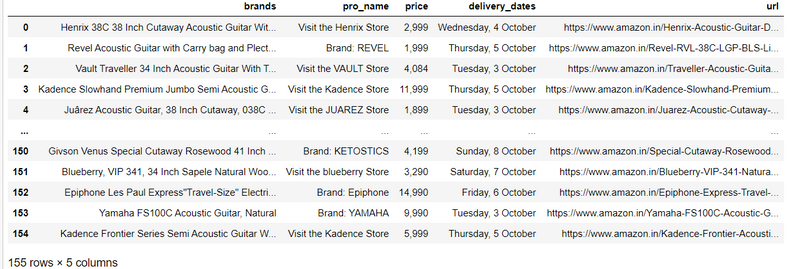
Step8: convert product detail in data frame
import pandas as pd
df= pd.DataFrame({'brands':brands,'pro_name':products_name,'price':prices,'delivery_dates':delivery_dates,'url':url})
df
=========================================
by doubt clearing

Top comments (0)