Extraxt data from html data
Extraxt data from web url
How to extract metdata from weburl
Extraxt data from html data
Basic Header Splitting (h1, h2)
from langchain.text_splitter import HTMLHeaderTextSplitter
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_text = """
<h1>Main Title</h1>
<p>This is the introduction.</p>
<h2>Section 1</h2>
<p>Details about section 1.</p>
<h2>Section 2</h2>
<p>Details about section 2.</p>
"""
html_header_splits = html_splitter.split_text(html_text)
Output:
[
"<h1>Main Title</h1>\n<p>This is the introduction.</p>",
"<h2>Section 1</h2>\n<p>Details about section 1.</p>",
"<h2>Section 2</h2>\n<p>Details about section 2.</p>"
]
Example 2: Nested Header Splitting (h1, h2, h3)
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2"), ("h3", "Header 3")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_text = """
<h1>Main Title</h1>
<p>Introductory paragraph.</p>
<h2>Subsection A</h2>
<p>Details about subsection A.</p>
<h3>Subtopic A1</h3>
<p>Information on subtopic A1.</p>
<h3>Subtopic A2</h3>
<p>Information on subtopic A2.</p>
"""
html_header_splits = html_splitter.split_text(html_text)
Output:
[
"<h1>Main Title</h1>\n<p>Introductory paragraph.</p>",
"<h2>Subsection A</h2>\n<p>Details about subsection A.</p>",
"<h3>Subtopic A1</h3>\n<p>Information on subtopic A1.</p>",
"<h3>Subtopic A2</h3>\n<p>Information on subtopic A2.</p>"
]
Example 3: Large Chunks with Overlap (h1, h2, Overlap)
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on, chunk_size=1000, chunk_overlap=200)
html_text = """
<h1>Main Topic</h1>
<p>This is a very long introductory paragraph...</p>
<h2>Part 1</h2>
<p>Content for part 1...</p>
<h2>Part 2</h2>
<p>Content for part 2...</p>
"""
html_header_splits = html_splitter.split_text(html_text)
Output:
[
"<h1>Main Topic</h1>\n<p>This is a very long introductory paragraph...</p>",
"<h2>Part 1</h2>\n<p>Content for part 1...</p>",
"<h2>Part 2</h2>\n<p>Content for part 2...</p>"
]
Example 4: Detailed Sectioning with h4 Headers
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2"), ("h3", "Header 3"), ("h4", "Header 4")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_text = """
<h1>Main Title</h1>
<p>Introduction text.</p>
<h2>Section 1</h2>
<h3>Subsection 1.1</h3>
<h4>Subsubsection 1.1.1</h4>
<p>Details on subsubsection 1.1.1.</p>
"""
html_header_splits = html_splitter.split_text(html_text)
Output:
[
"<h1>Main Title</h1>\n<p>Introduction text.</p>",
"<h2>Section 1</h2>",
"<h3>Subsection 1.1</h3>",
"<h4>Subsubsection 1.1.1</h4>\n<p>Details on subsubsection 1.1.1.</p>"
]
Example 5: Excluding Specific Headers
headers_to_split_on = [("h2", "Header 2"), ("h3", "Header 3")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_text = """
<h1>Main Title</h1>
<p>This section is excluded as per header rules.</p>
<h2>Included Section</h2>
<p>Content for the included section.</p>
"""
html_header_splits = html_splitter.split_text(html_text)
Output:
[
"<h2>Included Section</h2>\n<p>Content for the included section.</p>"
]
Example 6: Split by Deeply Nested Headers (h1, h2, h3, h4, h5)
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2"), ("h3", "Header 3"), ("h4", "Header 4"), ("h5", "Header 5")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_text = """
<h1>Main Title</h1>
<h2>Section 1</h2>
<h3>Subsection 1.1</h3>
<h4>Topic 1.1.1</h4>
<h5>Detail 1.1.1.1</h5>
<p>Final detailed content.</p>
"""
html_header_splits = html_splitter.split_text(html_text)
Output:
[
"<h1>Main Title</h1>",
"<h2>Section 1</h2>",
"<h3>Subsection 1.1</h3>",
"<h4>Topic 1.1.1</h4>",
"<h5>Detail 1.1.1.1</h5>\n<p>Final detailed content.</p>"
]
Example 7: Small Chunks with Short Overlap
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on, chunk_size=100, chunk_overlap=10)
html_text = """
<h1>Overview</h1>
<p>This is a very brief overview.</p>
<h2>Details</h2>
<p>Some additional details here.</p>
"""
html_header_splits = html_splitter.split_text(html_text)
Output:
[
"<h1>Overview</h1>\n<p>This is a very brief overview.</p>",
"<h2>Details</h2>\n<p>Some additional details here.</p>"
]
Example 8: Use with HTML from Web Page
url = "https://example.com"
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2"), ("h3", "Header 3")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
Output:
[
"<h1>Main Header from Web Page</h1>\n<p>Introductory paragraph.</p>",
"<h2>Section 1</h2>\n<p>Details about section 1.</p>",
"<h3>Subsection 1.1</h3>\n<p>Information on subsection 1.1.</p>"
]
Example 9: Split by Only h2 Headers (Exclude h1)
headers_to_split_on = [("h2", "Header 2")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_text = """
<h1>Excluded Title</h1>
<p>This section is not included in output.</p>
<h2>Included Section</h2>
<p>Content for the included section.</p>
"""
html_header_splits = html_splitter.split_text(html_text)
Output:
[
"<h2>Included Section</h2>\n<p>Content for the included section.</p>"
]
Example 10: Complex Document with All Headers
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2"), ("h3", "Header 3"), ("h4", "Header 4")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_text = """
<h1>Main Topic</h1>
<p>Introductory paragraph.</p>
<h2>First Section</h2>
<p>Overview of the first section.</p>
<h3>Subsection 1.1</h3>
<p>Details of subsection 1.1</p>
<h4>Subtopic 1.1.1</h4>
<p>Additional content here.</p>
"""
html_header_splits = html_splitter.split_text(html_text)
Output:
[
"<h1>Main Topic</h1>\n<p>Introductory paragraph.</p>",
"<h2>First Section</h2>\n<p>Overview of the first section.</p>",
"<h3>Subsection 1.1</h3>\n<p>Details of subsection 1.1</p>",
"<h4>Subtopic 1.1.1</h4>\n<p>Additional content here.</p>"
]
These examples demonstrate how HTMLHeaderTextSplitter can be customized for different splitting needs by adjusting headers, chunk sizes, and overlap settings. Each configuration produces structured, organized output based on HTML headings.
Extraxt data from web url
Example 1: Basic Split with Main Headers (h1, h2)
from langchain.text_splitter import HTMLHeaderTextSplitter
url = "https://en.wikipedia.org/wiki/Artificial_intelligence"
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<h1>Artificial Intelligence</h1>\n<p>Introduction to AI...</p>",
"<h2>History</h2>\n<p>Overview of AI's history...</p>",
"<h2>Applications</h2>\n<p>AI applications include...</p>"
]
Example 2: Deep Split Including Subsections (h1, h2, h3)
url = "https://www.who.int/news-room/fact-sheets/detail/climate-change-and-health"
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2"), ("h3", "Header 3")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<h1>Climate Change and Health</h1>\n<p>Introduction to climate change...</p>",
"<h2>Overview</h2>\n<p>Key points on climate change and health...</p>",
"<h3>Impact on Health</h3>\n<p>Details on health impacts...</p>"
]
Example 3: Full Document Structure with Detailed Subsections (h1, h2, h3, h4)
url = "https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Introduction"
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2"), ("h3", "Header 3"), ("h4", "Header 4")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<h1>JavaScript Guide</h1>\n<p>Introductory content on JavaScript...</p>",
"<h2>Overview</h2>\n<p>Introduction to JavaScript basics...</p>",
"<h3>Features</h3>\n<p>JavaScript's core features...</p>",
"<h4>Data Types</h4>\n<p>Explanation of JavaScript data types...</p>"
]
Example 4: Large Chunks with Overlap (h1, h2, with Overlap)
url = "https://www.un.org/en/about-us/history-of-the-un"
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on, chunk_size=1500, chunk_overlap=200)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<h1>History of the United Nations</h1>\n<p>Overview of UN's formation...</p>",
"<h2>Founding and Objectives</h2>\n<p>Details on founding principles...</p>",
"<h2>Major Events</h2>\n<p>Key events in UN history...</p>"
]
Example 5: Split by Selected Subsections (h2, h3 Only)
url = "https://www.nasa.gov/mission_pages/apollo/missions/index.html"
headers_to_split_on = [("h2", "Header 2"), ("h3", "Header 3")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<h2>Apollo Missions</h2>\n<p>Overview of Apollo program...</p>",
"<h3>Apollo 11</h3>\n<p>Details of the Apollo 11 mission...</p>",
"<h3>Apollo 13</h3>\n<p>Details of the Apollo 13 mission...</p>"
]
Example 6: Small Chunks for Specific Details (h2, h3, h4 with Small Chunk Size)
url = "https://www.fao.org/sustainable-development-goals"
headers_to_split_on = [("h2", "Header 2"), ("h3", "Header 3"), ("h4", "Header 4")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on, chunk_size=500, chunk_overlap=50)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<h2>FAO's Role in SDGs</h2>\n<p>FAO contributions to SDGs...</p>",
"<h3>Goal 2: Zero Hunger</h3>\n<p>FAO efforts in reducing hunger...</p>",
"<h4>Sub-goal 2.1</h4>\n<p>Targeting food security...</p>"
]
Example 7: Extract Only Main Topics (h1 Only)
url = "https://www.w3.org/standards/"
headers_to_split_on = [("h1", "Header 1")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<h1>Web Standards</h1>\n<p>Overview of W3C standards...</p>",
"<h1>W3C Technologies</h1>\n<p>Introduction to W3C's role...</p>"
]
Example 8: Multi-level Sections and Subsections (h1, h2, h3, h4, h5)
url = "https://www.nationalgeographic.com/environment/"
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2"), ("h3", "Header 3"), ("h4", "Header 4"), ("h5", "Header 5")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<h1>Environment</h1>\n<p>Introductory content on environmental topics...</p>",
"<h2>Climate Change</h2>\n<p>Articles on climate change...</p>",
"<h3>Impact on Oceans</h3>\n<p>Details on ocean impacts...</p>",
"<h4>Sea Level Rise</h4>\n<p>Implications of sea level rise...</p>"
]
Example 9: Extract Headers with Specific Topics (h2, h3)
url = "https://data.unicef.org/topic/education/"
headers_to_split_on = [("h2", "Header 2"), ("h3", "Header 3")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<h2>Education</h2>\n<p>Overview of UNICEF's education initiatives...</p>",
"<h3>Primary Education</h3>\n<p>Focus on primary education...</p>",
"<h3>Secondary Education</h3>\n<p>Details on secondary education...</p>"
]
Example 10: All Headers for Full Document Parsing (h1, h2, h3, h4, h5, h6)
url = "https://www.health.harvard.edu/topics/mental-health"
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2"), ("h3", "Header 3"), ("h4", "Header 4"), ("h5", "Header 5"), ("h6", "Header 6")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<h1>Mental Health</h1>\n<p>Introduction to mental health topics...</p>",
"<h2>Common Conditions</h2>\n<p>Overview of mental health conditions...</p>",
"<h3>Anxiety Disorders</h3>\n<p>Details on anxiety disorders...</p>",
"<h4>Treatment Options</h4>\n<p>Various treatment options explained...</p>"
]
Splitting by Anchor Tags () to Extract Links
from langchain.text_splitter import HTMLHeaderTextSplitter
url = "https://en.wikipedia.org/wiki/Web_scraping"
headers_to_split_on = [("a", "Anchor")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<a href='/wiki/Data_scraping'>Data scraping</a>",
"<a href='/wiki/Robotic_process_automation'>Robotic process automation</a>",
"<a href='/wiki/Web_crawler'>Web crawler</a>"
]
Explanation: This example extracts all anchor tags () from the Wikipedia page on web scraping, allowing you to retrieve all internal and external links within the page.
Example 2: Splitting by Table Rows ( Explanation: This example splits each row of the world population table into a separate chunk, enabling easy access to structured population data by region. Example 3: Splitting by Paragraph Tags ( ) for Detailed Content Segmentation Explanation: Each paragraph ( ) is split individually, which is useful for summarizing or analyzing individual pieces of content, like news updates or article summaries. Example 4: Extracting Hyperlinks from Specific Sections with Headers and Anchors (h2, a) Explanation: This splits the content into sections by headers (h2) and captures links within each section (a), making it easier to create a navigable content structure. Example 5: Splitting by Table Cells ( Explanation: This example parses individual table cells ( Example 6: Combining Headers and Paragraphs (h1, p) for Article Summaries Explanation: This example captures the main title (h1) and each paragraph (p), which is useful for summarizing articles by retrieving only the key content. Example 7: Extracting Data from a Mixture of Tags (h2, td) Explanation: By combining headers (h2) with table cells (td), this example retrieves a mix of section headers and key data points, which can be valuable for presenting facts or statistics. Example 8: Splitting by List Items ( Explanation: This example captures each list item ( Example 9: Extracting Content from Sections and Links (h2, a) Explanation: This example pulls out headers (h2) and links (a), making it suitable for collecting information on Python applications across different domains. Example 10: Extracting Headings and Links for Navigation Structure (h1, a) Extract specific table data Expected Output The output would look like this: ...) for Structured Data Extraction
url = "https://www.worldometers.info/world-population/"
headers_to_split_on = [("tr", "Table Row")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<tr><td>World Population</td><td>7,800,000,000</td></tr>",
"<tr><td>Asia</td><td>4,641,054,775</td></tr>",
"<tr><td>Africa</td><td>1,340,598,147</td></tr>"
]
url = "https://www.bbc.com/news/world"
headers_to_split_on = [("p", "Paragraph")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<p>The latest global news...</p>",
"<p>Updates on recent events around the world...</p>",
"<p>COVID-19 cases have continued to decline...</p>"
]
url = "https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide"
headers_to_split_on = [("h2", "Header 2"), ("a", "Anchor")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<h2>JavaScript Basics</h2>",
"<a href='/docs/Web/JavaScript/Data_structures'>Data Structures</a>",
"<a href='/docs/Web/JavaScript/Closures'>Closures</a>",
"<h2>Control Flow</h2>",
"<a href='/docs/Web/JavaScript/Control_flow'>Control Flow Guide</a>"
]
) for Tabular Data
url = "https://www.imdb.com/chart/top"
headers_to_split_on = [("td", "Table Cell")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<td>The Shawshank Redemption</td>",
"<td>1994</td>",
"<td>9.3</td>",
"<td>The Godfather</td>",
"<td>1972</td>",
"<td>9.2</td>"
]
) from IMDb's Top 250 list, making it easy to isolate movie titles, release years, and ratings for further processing.
url = "https://www.scientificamerican.com/article/what-is-climate-change/"
headers_to_split_on = [("h1", "Header 1"), ("p", "Paragraph")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<h1>What is Climate Change?</h1>",
"<p>Climate change refers to...</p>",
"<p>The effects of climate change...</p>"
]
url = "https://www.worldbank.org/en/news/factsheet"
headers_to_split_on = [("h2", "Header 2"), ("td", "Table Cell")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<h2>Global Development Indicators</h2>",
"<td>GDP Growth</td>",
"<td>2.5%</td>",
"<h2>Environmental Statistics</h2>",
"<td>CO2 Emissions</td>",
"<td>5.1 Metric Tons</td>"
]
url = "https://www.cdc.gov/coronavirus/2019-ncov/prevent-getting-sick/prevention.html"
headers_to_split_on = [("li", "List Item")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<li>Wash your hands often...</li>",
"<li>Maintain a safe distance...</li>",
"<li>Wear a mask...</li>"
]
url = "https://www.python.org/about/apps/"
headers_to_split_on = [("h2", "Header 2"), ("a", "Anchor")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<h2>Web Development</h2>",
"<a href='/about/apps/#web-development'>Learn More</a>",
"<h2>Data Science</h2>",
"<a href='/about/apps/#data-science'>Learn More</a>"
]
url = "https://www.fda.gov/food"
headers_to_split_on = [("h1", "Header 1"), ("a", "Anchor")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
Expected Output:
[
"<h1>Food</h1>",
"<a href='/food/food-safety'>Food Safety</a>",
"<a href='/food/nutrition'>Nutrition</a>",
"<a href='/food/labeling-nutrition'>Labeling & Nutrition</a>"
]
import requests
from bs4 import BeautifulSoup
from langchain.text_splitter import HTMLHeaderTextSplitter
# Step 1: Fetch the HTML content of the webpage
url = "https://example.com" # Replace with the actual URL containing multiple tables
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# Step 2: Locate and isolate the specific table by unique identifier
# Example: finding by class or id, or selecting by position in the list of tables
# Adjust "specific-table-class" to the unique class or id of the desired table
target_table = soup.find("table", {"class": "specific-table-class"}) # Or use {"id": "specific-table-id"}
# Step 3: Convert the table HTML to a string for further processing
table_html = str(target_table)
# Step 4: Initialize HTMLHeaderTextSplitter with desired tags within the table (e.g., <tr> for rows, <td> for cells)
headers_to_split_on = [("tr", "Table Row"), ("td", "Table Cell")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
# Step 5: Split the content of the specific table
html_header_splits = html_splitter.split_text(table_html)
# Step 6: Output the extracted chunks from the specific table
for chunk in html_header_splits:
print(chunk)
For example, if the table has this structure:
<table class="specific-table-class">
<tr><td>Country</td><td>GDP</td><td>Population</td></tr>
<tr><td>USA</td><td>21.43 Trillion</td><td>331 Million</td></tr>
<tr><td>China</td><td>14.34 Trillion</td><td>1.4 Billion</td></tr>
</table>
[
"<tr><td>Country</td><td>GDP</td><td>Population</td></tr>",
"<td>Country</td>",
"<td>GDP</td>",
"<td>Population</td>",
"<tr><td>USA</td><td>21.43 Trillion</td><td>331 Million</td></tr>",
"<td>USA</td>",
"<td>21.43 Trillion</td>",
"<td>331 Million</td>",
"<tr><td>China</td><td>14.34 Trillion</td><td>1.4 Billion</td></tr>",
"<td>China</td>",
"<td>14.34 Trillion</td>",
"<td>1.4 Billion</td>"
]
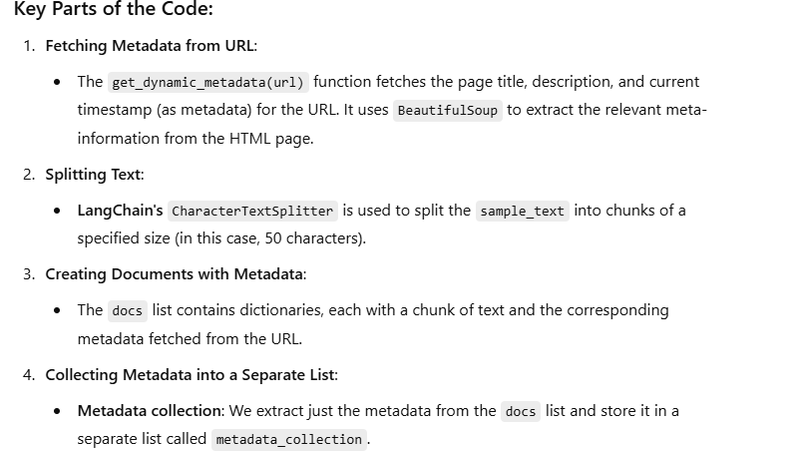
How to extract metdata from weburl
import requests
from datetime import datetime
from langchain.text_splitter import CharacterTextSplitter
from bs4 import BeautifulSoup
# Define a function to fetch and parse the URL to retrieve dynamic metadata
def get_dynamic_metadata(url):
try:
# Fetch the HTML content of the URL
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Extract title and description from the HTML
title = soup.title.string if soup.title else "No Title"
description = soup.find('meta', attrs={'name': 'description'}) or soup.find('meta', attrs={'property': 'og:description'})
description_content = description['content'] if description else "No Description"
except Exception as e:
title = "Error fetching title"
description_content = "Error fetching description"
print(f"Error fetching data from URL: {e}")
return {
"timestamp": datetime.now().isoformat(),
"source_url": url,
"page_title": title,
"page_description": description_content
}
# Sample text (normally fetched from a webpage URL)
sample_text = """
LangChain is a powerful library for building applications with language models. It supports text splitting, tokenization, metadata handling, and more. With LangChain, you can process large documents and work with structured text effectively. Visit our website for more detailed information.
"""
# Define the URL from which you want to fetch dynamic metadata
url = "https://example.com" # Replace with your URL
# Initialize the text splitter with the desired chunk size
splitter = CharacterTextSplitter(chunk_size=50)
# Split the sample text into chunks
texts = splitter.split_text(sample_text)
# Fetch dynamic metadata from the URL
dynamic_metadata = get_dynamic_metadata(url)
# Create documents with dynamic metadata and chunked text
docs = [{"text": chunk, "metadata": dynamic_metadata} for chunk in texts]
# Separate out the metadata from the documents into a collection
metadata_collection = [doc["metadata"] for doc in docs]
# Print the documents and the collected metadata separately
print("Documents with Text and Metadata:")
for doc in docs:
print(doc)
print("\nMetadata Collection (separate list):")
for meta in metadata_collection:
print(meta)
{
"text": "LangChain is a powerful library for building applicatio",
"metadata": {
"timestamp": "2024-11-14T13:45:00",
"source_url": "https://example.com",
"page_title": "Example Domain",
"page_description": "Example Domain is a web page for demonstration purposes."
}
},
{
"text": "ns with language models. It supports text splitting, tokeniz",
"metadata": {
"timestamp": "2024-11-14T13:45:00",
"source_url": "https://example.com",
"page_title": "Example Domain",
"page_description": "Example Domain is a web page for demonstration purposes."
}
},
SUMMARY
Extraxt data from html data
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2"), ("h3", "Header 3"), ("h4", "Header 4")]
html_header_splits = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on).split_text(html_text)
Extraxt data from web url
url = "https://en.wikipedia.org/wiki/Artificial_intelligence"
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")]
html_header_splits = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on).split_text_from_url(url)
Splitting by Anchor Tags ==
headers_to_split_on = [("a", "Anchor")]
HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on).split_text_from_url(url)
Splitting by Table Rows () for Structured Data Extraction=============
headers_to_split_on = [("tr", "Table Row")]
HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on).split_text_from_url(url)
Splitting by Paragraph Tags
headers_to_split_on = [("p", "Paragraph")]
HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on).split_text_from_url(url)
Extracting Hyperlinks from Specific Sections with Headers and Anchors (h2, a)========================
headers_to_split_on = [("h2", "Header 2"), ("a", "Anchor")]

Top comments (0)