Note:
we cannot fill nan value for object type we have to convert it into float or int then fill by mean
we cannot fill nan value for object type we can fill by most frequent means by mode
Selecting specific columns and saving to a Django model:
import pandas as pd
from myapp.models import MyModel
data = pd.read_csv('data.csv')
selected_data = data[['column1', 'column2']] # Select desired columns
for index, row in selected_data.iterrows():
my_model = MyModel(field1=row['column1'], field2=row['column2'])
my_model.save()
Filtering rows based on a condition and saving to a Django model:
import pandas as pd
from myapp.models import MyModel
data = pd.read_csv('data.csv')
filtered_data = data[data['column1'] > 10] # Filter rows based on condition
for index, row in filtered_data.iterrows():
my_model = MyModel(field1=row['column1'], field2=row['column2'])
my_model.save()
Selecting and filtering rows using query and saving to a Django model:
import pandas as pd
from myapp.models import MyModel
data = pd.read_csv('data.csv')
selected_data = data.query("column1 == 'A'") # Select rows based on a query
for index, row in selected_data.iterrows():
my_model = MyModel(field1=row['column1'], field2=row['column2'])
my_model.save()
Dropping specific columns and saving the remaining data to a Django model:
import pandas as pd
from myapp.models import MyModel
data = pd.read_csv('data.csv')
data.drop(['column1', 'column2'], axis=1, inplace=True) # Drop desired columns
for index, row in data.iterrows():
my_model = MyModel(field1=row['column3'], field2=row['column4'])
my_model.save()
Example
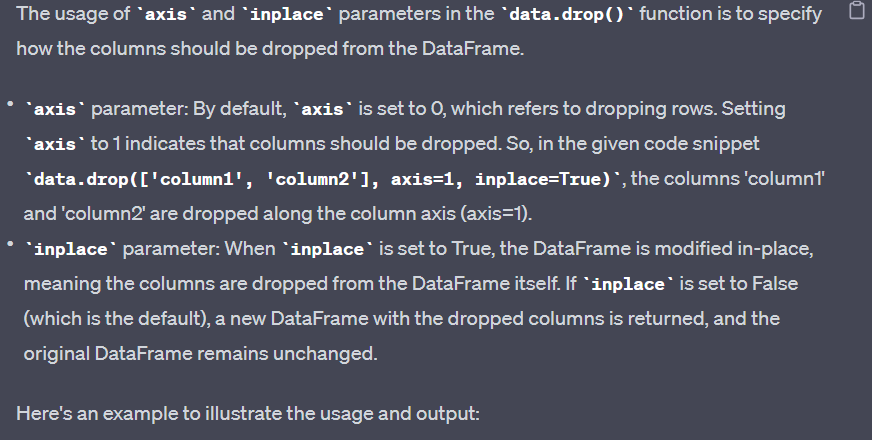
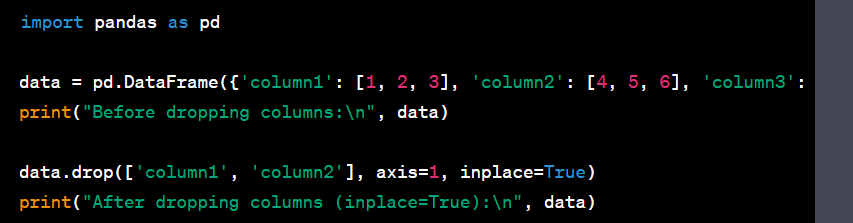
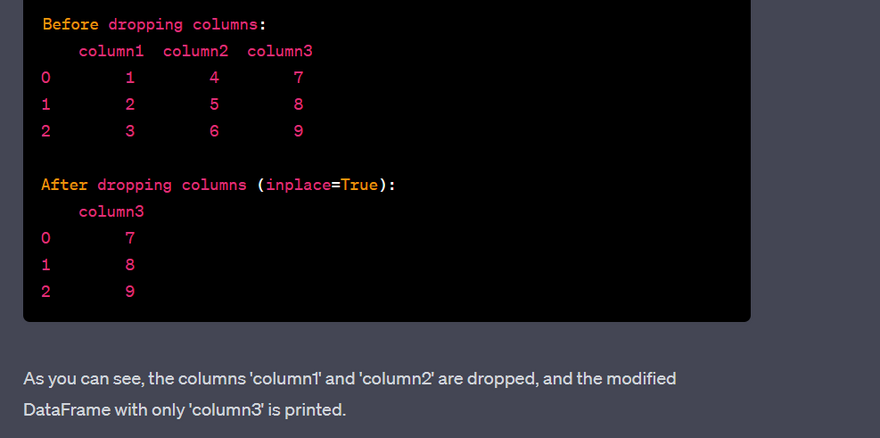
Dropping rows based on a condition and saving the remaining data to a Django model:
import pandas as pd
from myapp.models import MyModel
data = pd.read_csv('data.csv')
data = data[data['column1'] != 'A'] # Drop rows based on condition
for index, row in data.iterrows():
my_model = MyModel(field1=row['column1'], field2=row['column2'])
my_model.save()
Selecting rows based on a range of indices and saving to a Django model:
import pandas as pd
from myapp.models import MyModel
data = pd.read_csv('data.csv')
selected_data = data.loc[5:10] # Select rows based on index range
for index, row in selected_data.iterrows():
my_model = MyModel(field1=row['column1'], field2=row['column2'])
my_model.save()
Dropping duplicate rows and saving the unique data to a Django model:
import pandas as pd
from myapp.models import MyModel
data = pd.read_csv('data.csv')
data.drop_duplicates(inplace=True) # Drop duplicate rows
for index, row in data.iterrows():
my_model = MyModel(field1=row['column1'], field2=row['column2'])
my_model.save()
Selecting rows based on multiple conditions and saving to a Django model:
selected_data = data[(data['column1'] == 'A') & (data['column2'] > 10)] # Select rows based on multiple conditions
for index, row in selected_data.iterrows():
my_model = MyModel(field1=row['column1'], field2=row['column2'])
my_model.save()
Dropping missing values (NaN) and saving the clean data to a Django model:
import pandas as pd
from myapp.models import MyModel
data = pd.read_csv('data.csv')
data.dropna(inplace=True) # Drop rows with missing values
for index, row in data.iterrows():
my_model = MyModel(field1=row['column1'], field2=row['column2'])
my_model.save()
In this example, we import data from a CSV file using pd.read_csv(). Then, we perform various data selection and dropping operations using different methods and conditions. Finally, we iterate over the resulting data using iterrows() and save the selected or cleaned data to a Django model (MyModel) using the save() method.
==================================================================
Sure! Here are 9 different ways to remove irrelevant columns from a dataset using various Python libraries, along with examples and their corresponding output:
Using pop() method from Pandas:
import pandas as pd
# Example dataset
data = pd.DataFrame({
'col1': [1, 2, 3],
'col2': [4, 5, 6],
'col3': [7, 8, 9]
})
# Remove column 'col1'
data.pop('col1')
print(data)
Output:
col2 col3
0 4 7
1 5 8
2 6 9
Using drop() method from Pandas:
import pandas as pd
# Example dataset
data = pd.DataFrame({
'col1': [1, 2, 3],
'col2': [4, 5, 6],
'col3': [7, 8, 9]
})
# Remove column 'col1'
data = data.drop('col1', axis=1)
print(data)
Output:
col2 col3
0 4 7
1 5 8
2 6 9
Using list comprehension to select relevant columns:
import pandas as pd
# Example dataset
data = pd.DataFrame({
'col1': [1, 2, 3],
'col2': [4, 5, 6],
'col3': [7, 8, 9]
})
# Select relevant columns
relevant_columns = ['col2', 'col3']
data = data[relevant_columns]
print(data)
Output:
col2 col3
0 4 7
1 5 8
2 6 9
Using iloc[] to select column indices:
Copy code
import pandas as pd
# Example dataset
data = pd.DataFrame({
'col1': [1, 2, 3],
'col2': [4, 5, 6],
'col3': [7, 8, 9]
})
# Select relevant columns by index
data = data.iloc[:, 1:]
print(data)
Output:
col2 col3
0 4 7
1 5 8
2 6 9
Using loc[] to select column names:
import pandas as pd
# Example dataset
data = pd.DataFrame({
'col1': [1, 2, 3],
'col2': [4, 5, 6],
'col3': [7, 8, 9]
})
# Select relevant columns by name
data = data.loc[:, ['col2', 'col3']]
print(data)
Output:
col2 col3
0 4 7
1 5 8
2 6 9
Using NumPy's indexing to select relevant columns:
import pandas as pd
import numpy as np
# Example dataset
data = pd.DataFrame({
'col1': [1, 2, 3],
'col2': [4, 5, 6],
'col3': [7, 8, 9]
})

Top comments (0)