Difference between find and find_all commands in webscarpping
Find an Element by Tag,class,id,paragraph tag,anchor tag,
Find the First Div with a Specific Class
Find the multiple text using First Div with a Specific Class
Find the First Element with a Specific Attribute
Find the First Element with a Specific Text
Find the First Element with a Specific Tag and Class:
Find the First Image tag with a Specific Alt text
Find the First Element within a Specific Section:
Find the First Element within a Specific Parent Element
Find the First Table on the Page:
Find the First row on the Page:
Navigate the HTML Tree (Parent)
Navigate the HTML Tree (Children):
Get Text Inside an Element:
Extract Attribute Value:
Find Next Sibling Element:
Find Previous Sibling Element:
Find Element by CSS Selector:
Loop Through Elements and Extract Data:
Extract Links (Hrefs)/Images (Srcs):/table data
Extract Data from Nested Elements:
BeautifulSoup Prettify (for formatting HTML):
print content of request/request object/status code
print html content in formatted way
print html title tag/Getting the name of the tag/parent of tag
Extracting Text from the tags(Removing the tags from the content of the page p tag/li tag)
Extracting Links
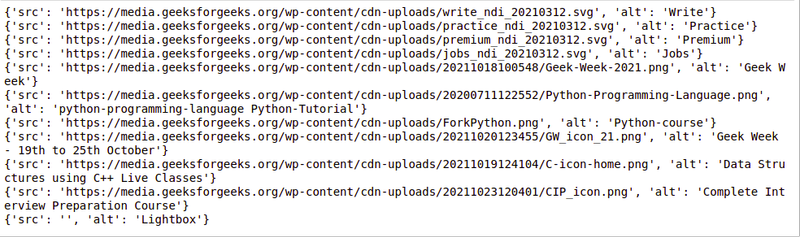
Extracting Image Information
Scraping multiple Pages
element = soup.find('h1')
Find an Element by Class:
element = soup.find(class_='example-class')
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
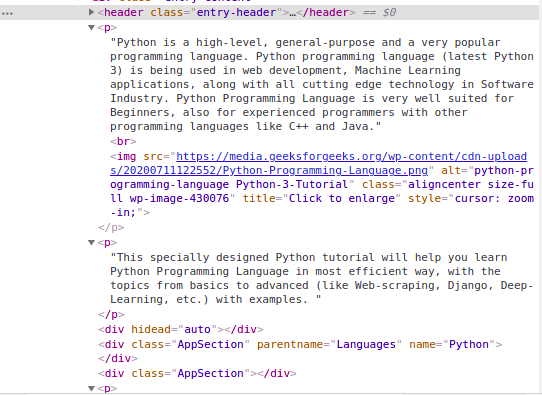
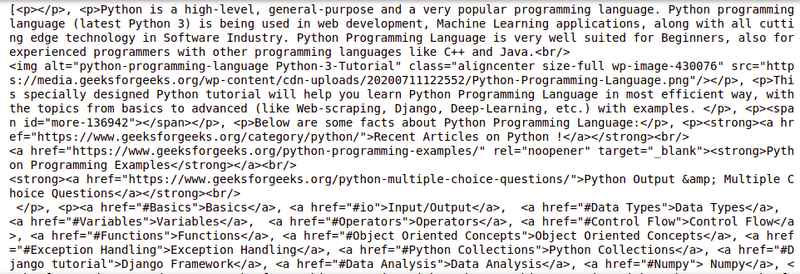
s = soup.find('div', class_='entry-content')
content = s.find_all('p')
print(content)
Output:
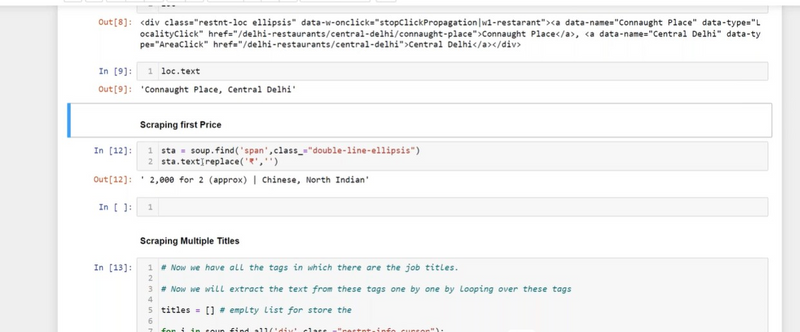
Find the multiple text using First Div with a Specific Class
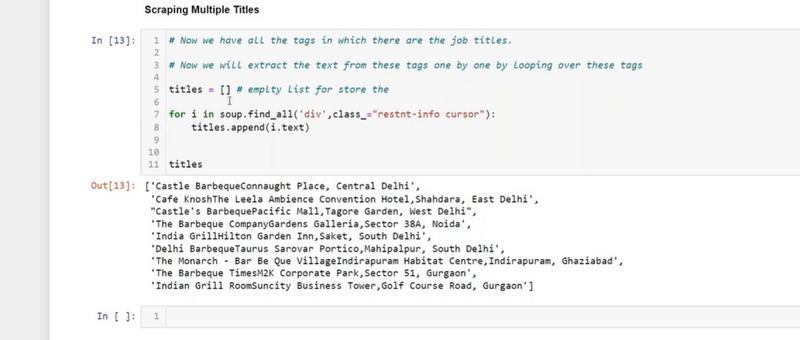
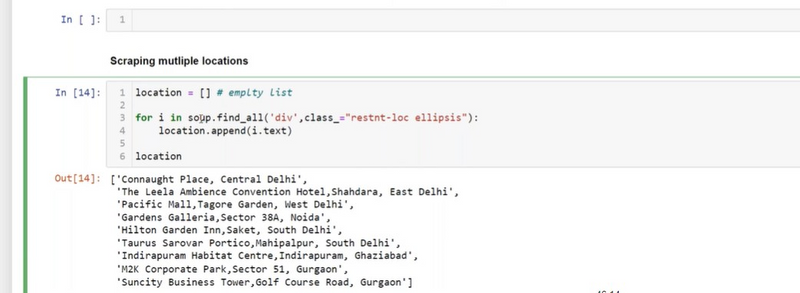
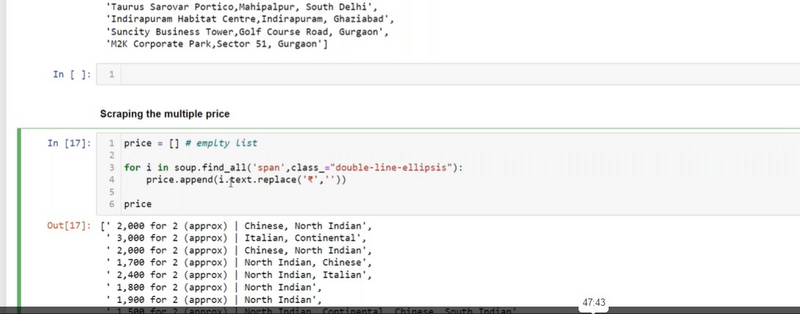
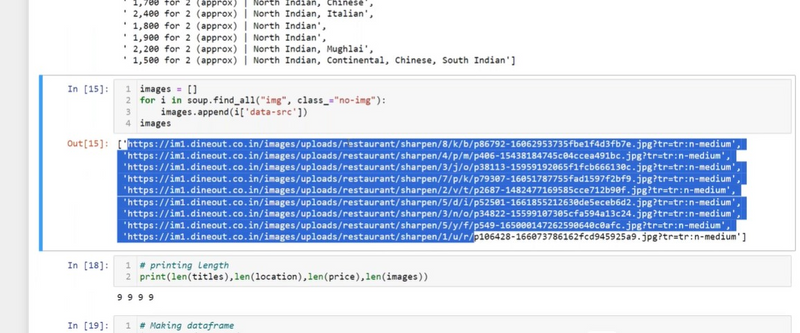
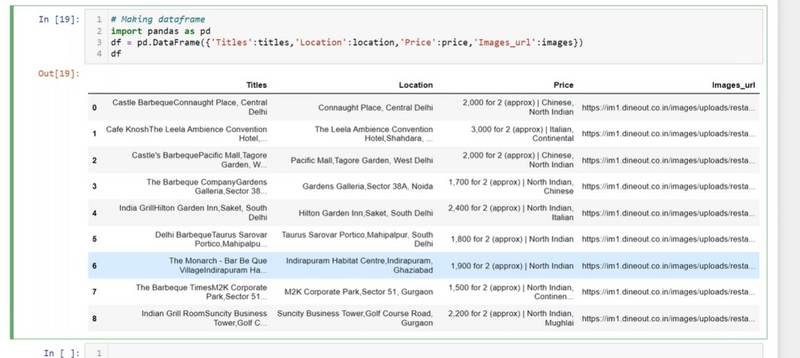
Find an Element by ID:
element = soup.find(id='example-id')
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
# Finding by id
s = soup.find('div', id= 'main')
# Getting the leftbar
leftbar = s.find('ul', class_='leftBarList')
# All the li under the above ul
content = leftbar.find_all('li')
print(content)
Output:
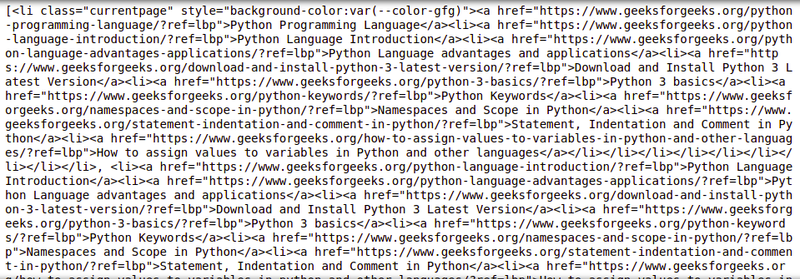
Find the First Paragraph Tag:
paragraph = soup.find('p')
Find the First Anchor Tag:
link = soup.find('a')
Find the First Div with a Specific Class:
div = soup.find('div', class_='example-class')
Find the First Element with a Specific Attribute:
element = soup.find(attrs={'data-type': 'example'})
Find the First Element with Specific Text:
element = soup.find(text='Example Text')
Find the First Element with a Specific Tag and Class:
element = soup.find('h2', class_='example-class')
Find the First Element with Specific Attributes:
element = soup.find(attrs={'data-type': 'example', 'data-id': '123'})
Find the First Image Tag with Specific Alt Text:
img = soup.find('img', alt='Image Description')
Find the First Element within a Specific Section:
section = soup.find('section', id='section-1')
element = section.find('p')
Find the First Element within a Specific Parent Element:
parent_element = soup.find('div', class_='parent-class')
child_element = parent_element.find('span')
Find the First Table on the Page:
table = soup.find('table')
Find the First Row in a Table:
table = soup.find('table')
first_row = table.find('tr')
Navigate the HTML Tree (Parent):
parent_element = element.parent
Navigate the HTML Tree (Children):
children = element.find_all('div')
Get Text Inside an Element:
text = element.get_text()
Extract Attribute Value:
value = element['attribute-name']
Find Next Sibling Element:
next_sibling = element.find_next_sibling()
Find Previous Sibling Element:
prev_sibling = element.find_previous_sibling()
Find Element by CSS Selector:
element = soup.select_one('.example-class')
Find All Elements by CSS Selector:
elements = soup.select('.example-class')
Loop Through Elements and Extract Data:
for element in elements:
print(element.text)
Extract Links (Hrefs):
links = [a['href'] for a in soup.find_all('a', href=True)]
Extract Images (Srcs):
image_srcs = [img['src'] for img in soup.find_all('img', src=True)]
Extract Table Data:
table = soup.find('table')
rows = table.find_all('tr')
for row in rows:
cells = row.find_all('td')
for cell in cells:
print(cell.text)
Extract Data from Nested Elements:
parent_element = soup.find('div', class_='parent-class')
child_element = parent_element.find('p', class_='child-class')
BeautifulSoup Prettify (for formatting HTML):
pretty_html = soup.prettify()
Please note that in each example, you need to replace 'example-id', 'example-class', 'attribute-name', 'data-type', and other placeholders with actual values from the HTML content you are working with. These commands will help you scrape data from websites effectively by leveraging BeautifulSoup's capabilities.
Difference between find and find_all commands in webscarpping
In web scraping using BeautifulSoup, both the find and find_all methods are used to search for and extract elements from an HTML document. However, they have different behaviors and use cases:
find Method:
The find method is used to find and return the first occurrence of an element that matches the specified criteria.
If a match is found, it returns the element as a BeautifulSoup object.
If no match is found, it returns None.
It's commonly used when you expect only one matching element or when you're interested in the first match.
Example:
first_div = soup.find('div')
find_all Method:
The find_all method is used to find and return all occurrences of elements that match the specified criteria.
It returns the matching elements as a list of BeautifulSoup objects.
If no matches are found, it returns an empty list ([]).
It's used when you want to extract multiple elements that match a particular pattern or condition.
Example:
all_divs = soup.find_all('div')
Example to Illustrate the Difference:
Suppose you have the following HTML code:
<html>
<body>
<div class="post">Post 1</div>
<div class="post">Post 2</div>
</body>
</html>
Using the find and find_all methods:
# Import BeautifulSoup and parse the HTML
from bs4 import BeautifulSoup
html = '''
<html>
<body>
<div class="post">Post 1</div>
<div class="post">Post 2</div>
</body>
</html>
'''
soup = BeautifulSoup(html, 'html.parser')
# Using find to get the first matching div element
first_div = soup.find('div', class_='post')
print(first_div.text) # Output: "Post 1"
# Using find_all to get all matching div elements
all_divs = soup.find_all('div', class_='post')
for div in all_divs:
print(div.text)
# Output:
# "Post 1"
# "Post 2"
In this example, find returns the first div element with the class "post," which is "Post 1." find_all returns both div elements with the same class, "Post 1" and "Post 2."
Use find when you want to extract the first matching element, and use find_all when you want to extract all matching elements from the HTML document.
print html content in formatted way
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# check status code for response received
# success code - 200
print(r)
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
print(soup.prettify())
Output:
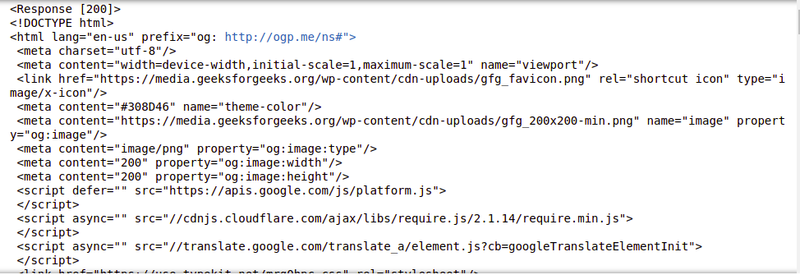
print content of request/request object/status code
import requests
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# check status code for response received
# success code - 200
print(r)
# print content of request
print(r.content)
Output
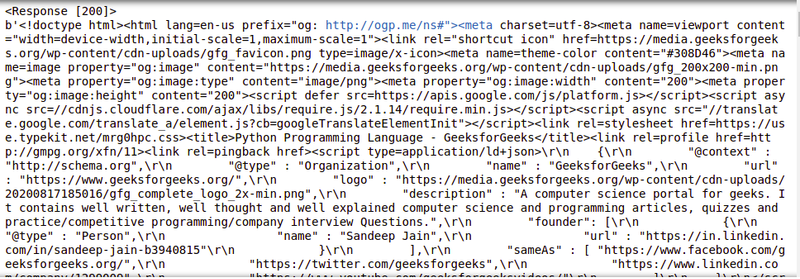
import requests
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# print request object
print(r.url)
# print status code
print(r.status_code)
print html title tag/Getting the name of the tag/parent of tag
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
# Getting the title tag
print(soup.title)
# Getting the name of the tag
print(soup.title.name)
# Getting the name of parent tag
print(soup.title.parent.name)
# use the child attribute to get
# the name of the child tag
Output:
<title>Python Programming Language - GeeksforGeeks</title>
title
html
Extracting Text from the tags
Removing the tags from the content of the page
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
s = soup.find('div', class_='entry-content')
lines = s.find_all('p')
for line in lines:
print(line.text)
Output

Removing li tags
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
# Finding by id
s = soup.find('div', id= 'main')
# Getting the leftbar
leftbar = s.find('ul', class_='leftBarList')
# All the li under the above ul
lines = leftbar.find_all('li')
for line in lines:
print(line.text)
Output:
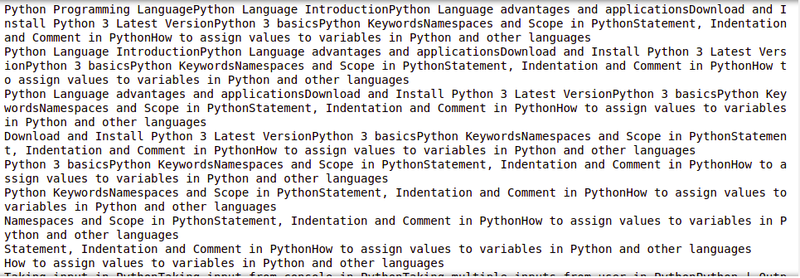
Extracting Links
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
# find all the anchor tags with "href"
for link in soup.find_all('a'):
print(link.get('href'))
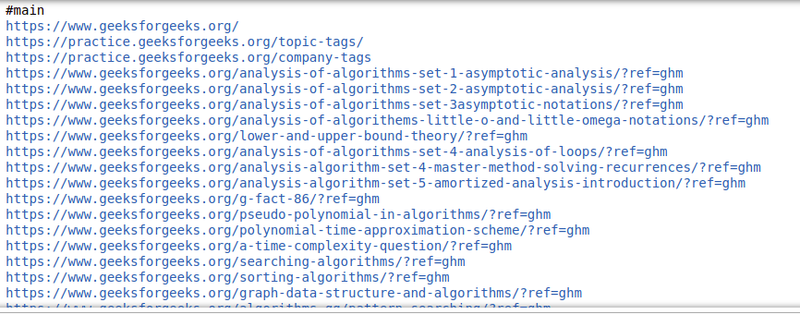
Extracting Image Information

import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
images_list = []
images = soup.select('img')
for image in images:
src = image.get('src')
alt = image.get('alt')
images_list.append({"src": src, "alt": alt})
for image in images_list:
print(image)
Output
Scraping multiple Pages
Example 1: Looping through the page numbers

page numbers at the bottom of the GeeksforGeeks website
Most websites have pages labeled from 1 to N. This makes it really simple for us to loop through these pages and extract data from them as these pages have similar structures. For example:
page numbers at the bottom of the GeeksforGeeks website
Here, we can see the page details at the end of the URL. Using this information we can easily create a for loop iterating over as many pages as we want (by putting page/(i)/ in the URL string and iterating “i” till N) and scrape all the useful data from them. The following code will give you more clarity over how to scrape data by using a For Loop in Python.
import requests
from bs4 import BeautifulSoup as bs
URL = 'https://www.geeksforgeeks.org/page/1/'
req = requests.get(URL)
soup = bs(req.text, 'html.parser')
titles = soup.find_all('div',attrs = {'class','head'})
print(titles[4].text)
Output:
7 Most Common Time Wastes During Software Development
Now, using the above code, we can get the titles of all the articles by just sandwiching those lines with a loop.
import requests
from bs4 import BeautifulSoup as bs
URL = 'https://www.geeksforgeeks.org/page/'
for page in range(1, 10):
req = requests.get(URL + str(page) + '/')
soup = bs(req.text, 'html.parser')
titles = soup.find_all('div', attrs={'class', 'head'})
for i in range(4, 19):
if page > 1:
print(f"{(i-3)+page*15}" + titles[i].text)
else:
print(f"{i-3}" + titles[i].text)
Output:

Example 2: Looping through a list of different URLs
The above technique is absolutely wonderful, but what if you need to scrape different pages, and you don’t know their page numbers? You’ll need to scrape those different URLs one by one and manually code a script for every such webpage.
Instead, you could just make a list of these URLs and loop through them. By simply iterating the items in the list i.e. the URLs, we will be able to extract the titles of those pages without having to write code for each page. Here’s an example code of how you can do it.
import requests
from bs4 import BeautifulSoup as bs
URL = ['https://www.geeksforgeeks.org','https://www.geeksforgeeks.org/page/10/']
for url in range(0,2):
req = requests.get(URL[url])
soup = bs(req.text, 'html.parser')
titles = soup.find_all('div',attrs={'class','head'})
for i in range(4, 19):
if url+1 > 1:
print(f"{(i - 3) + url * 15}" + titles[i].text)
else:
print(f"{i - 3}" + titles[i].text)
Output:

Looping through a list of different URLs
For more information, refer to our Python BeautifulSoup Tutorial.
Saving Data to CSV
First we will create a list of dictionaries with the key value pairs that we want to add in the CSV file. Then we will use the csv module to write the output in the CSV file. See the below example for better understanding.
Example: Python BeautifulSoup saving to CSV
import requests
from bs4 import BeautifulSoup as bs
import csv
URL = 'https://www.geeksforgeeks.org/page/'
soup = bs(req.text, 'html.parser')
titles = soup.find_all('div', attrs={'class', 'head'})
titles_list = []
count = 1
for title in titles:
d = {}
d['Title Number'] = f'Title {count}'
d['Title Name'] = title.text
count += 1
titles_list.append(d)
filename = 'titles.csv'
with open(filename, 'w', newline='') as f:
w = csv.DictWriter(f,['Title Number','Title Name'])
w.writeheader()
w.writerows(titles_list)
Output:


Top comments (0)