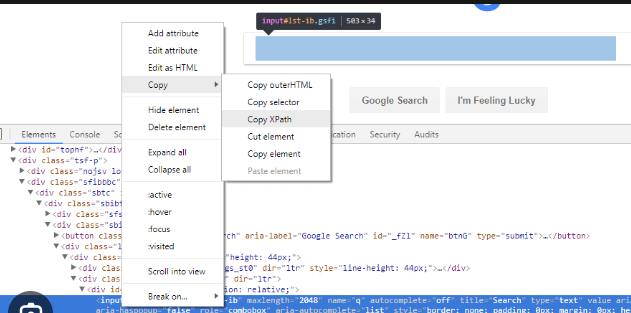
How to copy xpath,fullxpath,source code
How to copy source code
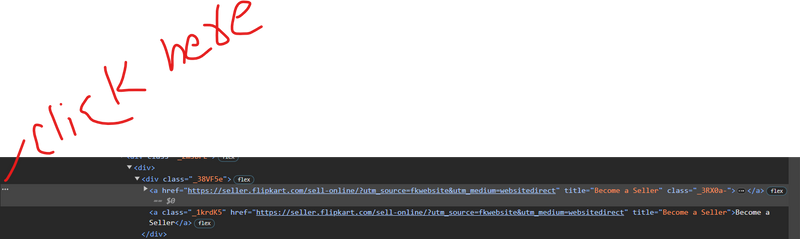
<a href="https://seller.flipkart.com/sell-online/?utm_source=fkwebsite&utm_medium=websitedirect" title="Become a Seller" class="_3RX0a-"><img src="https://static-assets-web.flixcart.com/batman-returns/batman-returns/p/images/Store-9eeae2.svg" alt="Become a Seller" class="_1XmrCc _1FTDbN"></a>
How to copy xpath
//*[@id="container"]/div/div[1]/div/div/div/div/div[1]/div/div[1]/div/div[1]/header/div[2]/div[1]/div/a[1]
How to copy full xpath
/html/body/div[1]/div/div[1]/div/div/div/div/div[1]/div/div[1]/div/div[1]/header/div[2]/div[1]/div/a[1]
how to get xpath
step 1: first inspect then click right on 3 dots
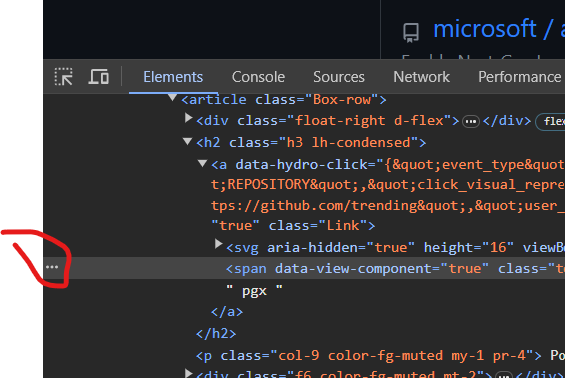
step2: take first header xpath
/html/body/div[1]/div[4]/main/div[3]/div/div[2]/article[1]/h2/a/span
step3 take second header xpath
/html/body/div[1]/div[4]/main/div[3]/div/div[2]/article[2]/h2/a/span
step4: which is not common between two xpath
article[1] and article[2] are not common
step 5 take common things to get final xpath
article
/html/body/div[1]/div[4]/main/div[3]/div/div[2]/article/h2/a/span
Absolute XPath
:
element = driver.find_element_by_xpath("/html/body/div[1]/input")
Relative XPath by Tag and Attribute
:
element = driver.find_element_by_xpath("//input[@id='username']")
from selenium import webdriver
# Start a new instance of the Firefox driver
driver = webdriver.Firefox()
# Navigate to a sample webpage
driver.get("https://example.com")
try:
# Find the input element by its ID using a relative XPath
element = driver.find_element_by_xpath("//input[@id='username']")
# Perform some action on the found element (e.g., send keys)
element.send_keys("my_username")
# Print the value of the input element
print("Input element value:", element.get_attribute("value"))
except Exception as e:
print("An error occurred:", str(e))
finally:
# Close the browser window
driver.quit()
output
Input element value: my_username
In this example:
1.We import the webdriver module from Selenium and start a new instance of the Firefox driver.
2.We navigate to a sample webpage (https://example.com).
3.Using a relative XPath //input[@id='username'], we find the input element with the id attribute equal to 'username'.
4.We perform an action on the found element (in this case, sending the keys "my_username" to the input field).
5.We print the value of the input element using element.get_attribute("value").
6.We wrap the code in a try-except block to handle any exceptions that may occur during execution.
7.Finally, we close the browser window using driver.quit().
The expected output will be the value that you set in the input element, in this case, "my_username".
Selecting Elements by Text
:
element = driver.find_element_by_xpath("//a[text()='Click Here']")
Explanation
I'll provide you with a full Python code example that includes both the HTML source code and the Selenium code using the command
element = driver.find_element_by_xpath("//input[contains(@class,'search')]")
, along with the expected output.
HTML Source Code
Python Selenium Code:
from selenium import webdriver
# Start a WebDriver instance (e.g., Firefox) and navigate to a webpage
driver = webdriver.Firefox()
driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file
try:
# Find the first input element with a class containing 'search'
element = driver.find_element_by_xpath("//input[contains(@class,'search')]")
# Print the placeholder attribute of the found input element
print("Input Placeholder:", element.get_attribute("placeholder"))
except Exception as e:
# Handle any exceptions that may occur during execution
print("An error occurred:", str(e))
finally:
# Close the browser window
driver.quit()
Import Selenium and Set Up the WebDriver:
from selenium import webdriver
Start a WebDriver instance (e.g., Firefox) and navigate to a webpage:
driver = webdriver.Firefox()
driver.get("https://example.com")
Find the Element Using XPath
:
element = driver.find_element_by_xpath("//a[text()='Click Here']")
driver.find_element_by_xpath() is a Selenium method for locating an element on the web page using XPath.
// in the XPath expression means to start the search from the root of the document.
a specifies that we are looking for anchor () elements.
[text()='Click Here'] is a condition that specifies we want to find an anchor element with exactly the text content "Click Here."
Interact with the Found Element (Optional):
You can interact with the found element if needed. For example, you can click on it:
element.click()
Here's a complete example that demonstrates finding an anchor element with the text "Click Here" and clicking on it:
from selenium import webdriver
# Start a WebDriver instance (e.g., Firefox) and navigate to a webpage
driver = webdriver.Firefox()
driver.get("https://example.com")
try:
# Find the anchor element with the text "Click Here"
element = driver.find_element_by_xpath("//a[text()='Click Here']")
# Click on the found anchor element
element.click()
# Print a message indicating that the click was successful
print("Clicked on the 'Click Here' link.")
except Exception as e:
# Handle any exceptions that may occur during execution
print("An error occurred:", str(e))
finally:
# Close the browser window
driver.quit()
In this example, if there is a link with the text "Click Here" on the webpage, the code will find it and click on it. The output will indicate that the link was clicked if successful.
Selecting Elements by Partial Text
:
element = driver.find_element_by_xpath("//a[contains(text(),'Partial Link')]")
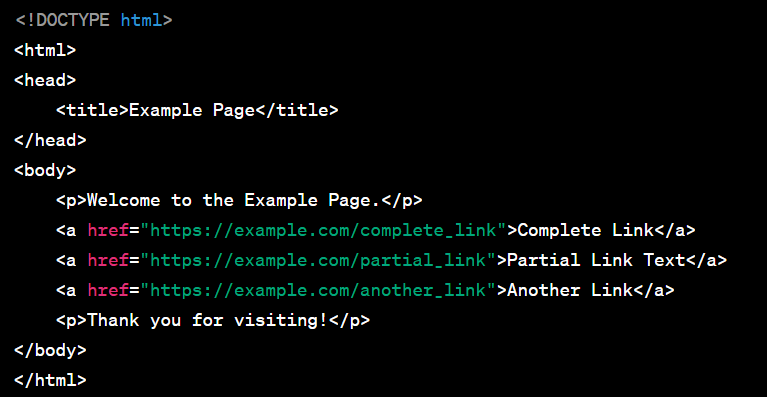

Selecting Elements by Index (First element with the tag 'div')
:
element = driver.find_element_by_xpath("//div[1]")
Explanation
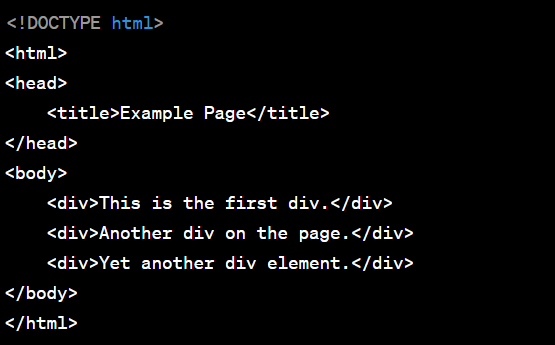

Selecting Elements by Index (Last element with the tag 'div')
:
element = driver.find_element_by_xpath("(//div)[last()]")
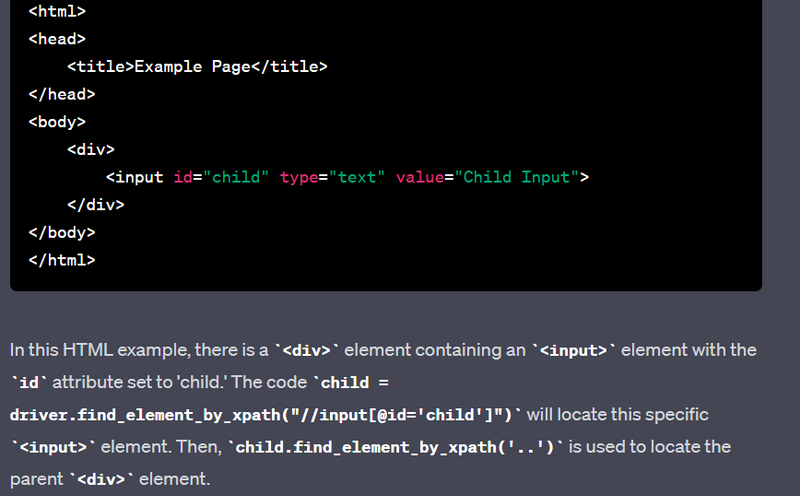
Selecting Parent Element
:
child = driver.find_element_by_xpath("//input[@id='child']")
parent = child.find_element_by_xpath('..')
Selecting Sibling Elements
:
element = driver.find_element_by_xpath("//input[@id='username']/following-sibling::button")
Explanation
I'll provide you with a full Python code example that includes both the HTML source code and the Selenium code using the command
element = driver.find_element_by_xpath("//input[@id='username']/following-sibling::button"),
along with the expected output.
HTML Source Code:
html
Copy code
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<input id="username" type="text" placeholder="Username">
<button>Submit</button>
</body>
</html>
Python Selenium Code:
from selenium import webdriver
# Start a WebDriver instance (e.g., Firefox) and navigate to a webpage
driver = webdriver.Firefox()
driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file
try:
# Find the button element that follows the input element with id 'username'
element = driver.find_element_by_xpath("//input[@id='username']/following-sibling::button")
# Print the text content of the button element
print("Button Text:", element.text)
except Exception as e:
# Handle any exceptions that may occur during execution
print("An error occurred:", str(e))
finally:
# Close the browser window
driver.quit()
In this example:
We have the HTML source code provided, which includes an element with the id attribute set to 'username' and a element that follows it as a sibling.
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We then use the driver.find_element_by_xpath method to locate the element that follows the element with the id attribute 'username' using the given XPath expression.
We print the text content of the located element.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Button Text: Submit
This output indicates that the text content of the element has been successfully retrieved and printed.
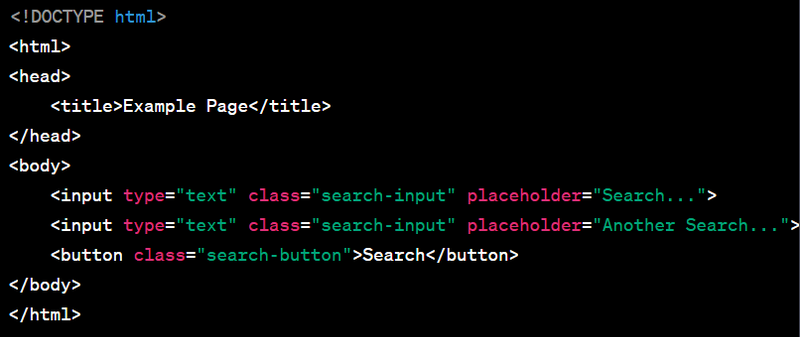
Selecting Elements by Attribute Value (Contains)
element = driver.find_element_by_xpath("//input[contains(@class,'search')]")
Explanation
HTML Source Code:
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<input type="text" class="search-input" placeholder="Search...">
<input type="text" class="search-input" placeholder="Another Search...">
<button class="search-button">Search</button>
</body>
</html>
Python Selenium Code:
from selenium import webdriver
# Start a WebDriver instance (e.g., Firefox) and navigate to a webpage
driver = webdriver.Firefox()
driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file
try:
# Find the first input element with a class containing 'search'
element = driver.find_element_by_xpath("//input[contains(@class,'search')]")
# Print the placeholder attribute of the found input element
print("Input Placeholder:", element.get_attribute("placeholder"))
except Exception as e:
# Handle any exceptions that may occur during execution
print("An error occurred:", str(e))
finally:
# Close the browser window
driver.quit()
In this example:
We have the HTML source code provided, which includes two elements with different class attributes. One of them has a class containing 'search,' and the other has a different class.
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We then use the driver.find_element_by_xpath method to locate the first element with a class attribute containing 'search' using the given XPath expression.
We print the placeholder attribute of the located element.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Input Placeholder: Search...
This output indicates that the placeholder attribute of the first element with a class containing 'search' has been successfully retrieved and printed.
Selecting Elements by Attribute Value (Starts with)
element = driver.find_element_by_xpath("//input[starts-with(@name,'user')]")
Explanation
HTML Source Code:
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<input type="text" name="username" placeholder="Enter your username">
<input type="text" name="user_id" placeholder="Enter your user ID">
<input type="text" name="email" placeholder="Enter your email">
</body>
</html>
Python Selenium Code:
from selenium import webdriver
# Start a WebDriver instance (e.g., Firefox) and navigate to a webpage
driver = webdriver.Firefox()
driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file
try:
# Find the first input element with a name attribute starting with 'user'
element = driver.find_element_by_xpath("//input[starts-with(@name,'user')]")
# Print the placeholder attribute of the found input element
print("Input Placeholder:", element.get_attribute("placeholder"))
except Exception as e:
# Handle any exceptions that may occur during execution
print("An error occurred:", str(e))
finally:
# Close the browser window
driver.quit()
In this example:
We have the HTML source code provided, which includes three elements with different name attributes. Two of them have name attributes starting with 'user,' while the third has a different name attribute.
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We then use the driver.find_element_by_xpath method to locate the first element with a name attribute starting with 'user' using the given XPath expression.
We print the placeholder attribute of the located element.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Input Placeholder: Enter your username
This output indicates that the placeholder attribute of the first element with a name attribute starting with 'user' has been successfully retrieved and printed.
Selecting Elements by Attribute Value (Ends with)
element = driver.find_element_by_xpath("//input[ends-with(@id,'name')]")
Explanation
HTML Source Code:
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<input type="text" id="first_name" placeholder="First Name">
<input type="text" id="last_name" placeholder="Last Name">
<input type="text" id="email_name" placeholder="Email">
</body>
</html>
Python Selenium Code:
from selenium import webdriver
# Start a WebDriver instance (e.g., Firefox) and navigate to a webpage
driver = webdriver.Firefox()
driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file
try:
# Find the input element with an id attribute ending with 'name'
element = driver.find_element_by_xpath("//input[substring(@id, string-length(@id) - string-length('name') + 1) = 'name']")
# Print the placeholder attribute of the found input element
print("Input Placeholder:", element.get_attribute("placeholder"))
except Exception as e:
# Handle any exceptions that may occur during execution
print("An error occurred:", str(e))
finally:
# Close the browser window
driver.quit()
In this example:
We have the HTML source code provided, which includes three elements with different id attributes. Two of them have id attributes ending with 'name,' while the third has a different id attribute.
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the driver.find_element_by_xpath method to locate the element with an id attribute ending with 'name' using the given XPath expression that simulates an ends-with condition.
We print the placeholder attribute of the located element.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Input Placeholder: Last Name
This output indicates that the placeholder attribute of the element with an id attribute ending with 'name' has been successfully retrieved and printed.
Selecting Elements by Multiple Conditions (AND)
:
element = driver.find_element_by_xpath("//input[@name='username' and @id='user_id']")
Explanation
HTML Source Code:
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<input type="text" name="username" id="user_id" placeholder="Enter your username">
<input type="text" name="password" id="password_id" placeholder="Enter your password">
<input type="text" name="email" id="email_id" placeholder="Enter your email">
</body>
</html>
Python Selenium Code:
from selenium import webdriver
# Start a WebDriver instance (e.g., Firefox) and navigate to a webpage
driver = webdriver.Firefox()
driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file
try:
# Find the input element with specific name and id attributes
element = driver.find_element_by_xpath("//input[@name='username' and @id='user_id']")
# Print the placeholder attribute of the found input element
print("Input Placeholder:", element.get_attribute("placeholder"))
except Exception as e:
# Handle any exceptions that may occur during execution
print("An error occurred:", str(e))
finally:
# Close the browser window
driver.quit()
In this example:
We have the HTML source code provided, which includes three elements with different combinations of name and id attributes. The element we are targeting has both name and id attributes set to 'username' and 'user_id,' respectively.
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the driver.find_element_by_xpath method to locate the element with specific name and id attributes using the given XPath expression.
We print the placeholder attribute of the located element.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Input Placeholder: Enter your username
This output indicates that the placeholder attribute of the element with the specified name and id attributes has been successfully retrieved and printed.
Selecting Elements by Multiple Conditions (OR)
:
element = driver.find_element_by_xpath("//input[@name='username' or @name='password']")
Selecting Elements by Text of Parent Element
:
element = driver.find_element_by_xpath("//a[text()='Click Here']/..")
HTML Source Code:
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<p><a href="https://example.com">Click Here</a> to visit the website.</p>
</body>
</html>
Python Selenium Code:
from selenium import webdriver
# Start a WebDriver instance (e.g., Firefox) and navigate to a webpage
driver = webdriver.Firefox()
driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file
try:
# Find the anchor element with the text "Click Here"
anchor_element = driver.find_element_by_xpath("//a[text()='Click Here']")
# Navigate to the parent element of the anchor element
parent_element = anchor_element.find_element_by_xpath('..')
# Print the tag name of the parent element
print("Parent Element Tag Name:", parent_element.tag_name)
except Exception as e:
# Handle any exceptions that may occur during execution
print("An error occurred:", str(e))
finally:
# Close the browser window
driver.quit()
In this example:
We have the HTML source code provided, which includes a
element containing an (anchor) element with the text "Click Here."
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the driver.find_element_by_xpath method to locate the element with the text "Click Here" using the given XPath expression.
Once we have located the anchor element, we use anchor_element.find_element_by_xpath('..') to navigate to its parent element.
We print the tag name of the parent element.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Parent Element Tag Name: p
This output indicates that the parent element of the anchor element with the text "Click Here" is a
element, and its tag name is 'p.'
Selecting Elements by Following Elements
element = driver.find_element_by_xpath("//h2[contains(text(),'Title')]/following::p")
Explanation
HTML Source Code:
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<h2>This is the Title</h2>
<p>This is a paragraph following the title.</p>
</body>
</html>
Python Selenium Code:
from selenium import webdriver
# Start a WebDriver instance (e.g., Firefox) and navigate to a webpage
driver = webdriver.Firefox()
driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file
try:
# Find the <h2> element containing the text "Title"
h2_element = driver.find_element_by_xpath("//h2[contains(text(),'Title')]")
# Find the following <p> element after the <h2> element
p_element = h2_element.find_element_by_xpath('following::p')
# Print the text content of the <p> element
print("Paragraph Text:", p_element.text)
except Exception as e:
# Handle any exceptions that may occur during execution
print("An error occurred:", str(e))
finally:
# Close the browser window
driver.quit()
In this example:
We have the HTML source code provided, which includes an
element containing the text "Title" and a
element following it.
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the driver.find_element_by_xpath method to locate the
element containing the text "Title" using the given XPath expression.
Once we have located the
element, we use h2_element.find_element_by_xpath('following::p') to find the following
element after the
element.
We print the text content of the
element.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Paragraph Text: This is a paragraph following the title.
This output indicates that the text content of the following
element has been successfully retrieved and printed.
Selecting Elements by Ancestor
:
element = driver.find_element_by_xpath("//p[contains(text(),'Text')]/ancestor::div")
Explanation
HTML Source Code:
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<div>
<p>This is some Text content.</p>
</div>
</body>
</html>
Python Selenium Code:
from selenium import webdriver
# Start a WebDriver instance (e.g., Firefox) and navigate to a webpage
driver = webdriver.Firefox()
driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file
try:
# Find the <p> element containing the text "Text" and navigate to its ancestor <div> element
element = driver.find_element_by_xpath("//p[contains(text(),'Text')]/ancestor::div")
# Print the tag name of the <div> element
print("Ancestor <div> Tag Name:", element.tag_name)
except Exception as e:
# Handle any exceptions that may occur during execution
print("An error occurred:", str(e))
finally:
# Close the browser window
driver.quit()
In this example:
We have the HTML source code provided, which includes a
element containing aelement with the text "Text."
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the driver.find_element_by_xpath method to locate the
element containing the text "Text" using the given XPath expression that uses ancestor::div to navigate to its ancestor
element.We print the tag name of the located
element.Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Ancestor <div> Tag Name: div
Selecting Elements by Attribute Value Not Equal
element = driver.find_element_by_xpath("//input[@type!='text']")
Explanation
HTML Source Code:
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<input type="checkbox" id="checkbox1" name="checkbox">
<input type="radio" id="radio1" name="radio">
<input type="number" id="number1" name="number">
<input type="text" id="text1" name="text">
</body>
</html>
Python Selenium Code:
from selenium import webdriver
# Start a WebDriver instance (e.g., Firefox) and navigate to a webpage
driver = webdriver.Firefox()
driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file
try:
# Find the <input> element with a 'type' attribute not equal to 'text'
element = driver.find_element_by_xpath("//input[@type!='text']")
# Print the 'id' attribute of the found <input> element
print("Input ID:", element.get_attribute("id"))
except Exception as e:
# Handle any exceptions that may occur during execution
print("An error occurred:", str(e))
finally:
# Close the browser window
driver.quit()
In this example:
We have the HTML source code provided, which includes four elements with different type attributes, including 'checkbox,' 'radio,' 'number,' and 'text.'
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the driver.find_element_by_xpath method to locate the element with a type attribute not equal to 'text' using the given XPath expression (//input[@type!='text']).
We print the id attribute of the located element.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Input ID: checkbox1
This output indicates that the id attribute of the first element with a type attribute not equal to 'text' (in this case, the checkbox input) has been successfully retrieved and printed.
Selecting Elements with Null Attribute
element = driver.find_element_by_xpath("//input[@type='text' and not(@id)]")
Explanation
HTML Source Code:
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<input type="text" placeholder="Enter your name">
<input type="text" id="username" placeholder="Enter your username">
<input type="text" placeholder="Enter your email">
</body>
</html>
Python Selenium Code:
from selenium import webdriver
# Start a WebDriver instance (e.g., Firefox) and navigate to a webpage
driver = webdriver.Firefox()
driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file
try:
# Find the <input> element with a 'type' attribute equal to 'text' and no 'id' attribute
element = driver.find_element_by_xpath("//input[@type='text' and not(@id)]")
# Print the 'placeholder' attribute of the found <input> element
print("Input Placeholder:", element.get_attribute("placeholder"))
except Exception as e:
# Handle any exceptions that may occur during execution
print("An error occurred:", str(e))
finally:
# Close the browser window
driver.quit()
In this example:
We have the HTML source code provided, which includes three elements with different combinations of type and id attributes. The element we are targeting has a type attribute equal to 'text' and no id attribute.
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the driver.find_element_by_xpath method to locate the element with a type attribute equal to 'text' and no id attribute using the given XPath expression (//input[@type='text' and not(@id)]).
We print the placeholder attribute of the located element.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Input Placeholder: Enter your name
This output indicates that the placeholder attribute of the element with a type attribute equal to 'text' and no id attribute has been successfully retrieved and printed.
Selecting Elements by Position (Nth Child)
:
element = driver.find_element_by_xpath("//ul/li[3]")
Explanation
HTML Source Code:
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<ul>
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
<li>Item 4</li>
</ul>
</body>
</html>
Python Selenium Code:
from selenium import webdriver
# Start a WebDriver instance (e.g., Firefox) and navigate to a webpage
driver = webdriver.Firefox()
driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file
try:
# Find the third <li> element within the <ul> element
element = driver.find_element_by_xpath("//ul/li[3]")
# Print the text content of the found <li> element
print("Third List Item:", element.text)
except Exception as e:
# Handle any exceptions that may occur during execution
print("An error occurred:", str(e))
finally:
# Close the browser window
driver.quit()
In this example:
We have the HTML source code provided, which includes an
- element containing four
- elements.
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the driver.find_element_by_xpath method to locate the third
- element within the
- element using the given XPath expression (//ul/li[3]).
- element.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Third List Item: Item 3This output indicates that the text content of the third
- element within the
element = driver.find_element_by_xpath("//div[contains(@class,'class1') and contains(@class,'class2')]")Explanation
HTML Source Code:
<html> <head> <title>Example Page</title> </head> <body> <div class="class1">This is a div with class1</div> <div class="class2">This is a div with class2</div> <div class="class1 class2">This is a div with both class1 and class2</div> <div class="class3">This is a div with class3</div> </body> </html>Python Selenium Code:
from selenium import webdriver # Start a WebDriver instance (e.g., Firefox) and navigate to a webpage driver = webdriver.Firefox() driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file try: # Find the <div> element with both 'class' attributes containing 'class1' and 'class2' element = driver.find_element_by_xpath("//div[contains(@class,'class1') and contains(@class,'class2')]") # Print the text content of the found <div> element print("Div Text Content:", element.text) except Exception as e: # Handle any exceptions that may occur during execution print("An error occurred:", str(e)) finally: # Close the browser window driver.quit()In this example:
We have the HTML source code provided, which includes several
elements with different combinations of class attributes.In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the driver.find_element_by_xpath method to locate the
element with both class attributes containing 'class1' and 'class2' using the given XPath expression (//div[contains(@class,'class1') and contains(@class,'class2')]).We print the text content of the located
element.Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Div Text Content: This is a div with both class1 and class2This output indicates that the text content of the
element with both 'class1' and 'class2' has been successfully retrieved and printed.Selecting Elements By Div ID
HTML Source Code:
<!DOCTYPE html> <html> <head> <title>Example Page</title> </head> <body> <div> <p>This is some content.</p> </div> <div id="my_element">This is the element with ID "my_element"</div> </body> </html>Python Selenium Code:
from selenium import webdriver from selenium.webdriver.common.by import By # Start a WebDriver instance (e.g., Firefox) and navigate to a webpage driver = webdriver.Firefox() driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file try: # Find the element with the 'id' attribute set to "my_element" element = driver.find_element(By.ID, "my_element") # Print the text content of the found element print("Element Text:", element.text) except Exception as e: # Handle any exceptions that may occur during execution print("An error occurred:", str(e)) finally: # Close the browser window driver.quit()In this example:
We have the HTML source code provided, which includes two
elements. One of them has the id attribute set to "my_element."In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the find_element method with By.ID to locate the element with the id attribute set to "my_element."
We print the text content of the located element.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Element Text: This is the element with ID "my_element"This output indicates that the text content of the element with the id attribute set to "my_element" has been successfully retrieved and printed.
Selecting Elements By Anchor Tag
HTML Source Code:
<!DOCTYPE html> <html> <head> <title>Example Page</title> </head> <body> <a href="https://example.com">Link 1</a> <a href="https://example.org">Link 2</a> <a href="https://example.net">Link 3</a> </body> </html>Python Selenium Code:
from selenium import webdriver from selenium.webdriver.common.by import By # Start a WebDriver instance (e.g., Firefox) and navigate to a webpage driver = webdriver.Firefox() driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file try: # Find all <a> elements on the webpage elements = driver.find_elements(By.TAG_NAME, "a") # Print the text content and href attribute of each <a> element for element in elements: print("Link Text:", element.text) print("Link Href:", element.get_attribute("href")) except Exception as e: # Handle any exceptions that may occur during execution print("An error occurred:", str(e)) finally: # Close the browser window driver.quit()In this example:
We have the HTML source code provided, which includes three (anchor) elements, each with a different href attribute.
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the find_elements method with By.TAG_NAME to locate all elements on the webpage.
We iterate through the list of located elements and print the text content and href attribute of each element.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Link Text: Link 1 Link Href: https://example.com Link Text: Link 2 Link Href: https://example.org Link Text: Link 3 Link Href: https://example.netThis output indicates that all three elements on the webpage have been successfully located, and their text content and href attributes have been printed.
Selecting Elements By ID of button to open alert type
HTML Source Code:
<!DOCTYPE html> <html> <head> <title>Example Page</title> </head> <body> <button id="my_button" onclick="alert('Button Clicked!')">Click Me</button> </body> </html>Python Selenium Code:
from selenium import webdriver from selenium.webdriver.common.by import By # Start a WebDriver instance (e.g., Firefox) and navigate to a webpage driver = webdriver.Firefox() driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file try: # Find the button element with the 'id' attribute set to "my_button" element = driver.find_element(By.ID, "my_button") # Click on the located button element element.click() # Wait for the alert to appear (this is not the recommended way to handle alerts) alert = driver.switch_to.alert # Print the text of the alert print("Alert Text:", alert.text) # Accept the alert (dismiss() can be used to dismiss it) alert.accept() except Exception as e: # Handle any exceptions that may occur during execution print("An error occurred:", str(e)) finally: # Close the browser window driver.quit()In this example:
We have the HTML source code provided, which includes a element with the id attribute set to "my_button" and an onclick attribute that triggers an alert when clicked.
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the find_element method with By.ID to locate the button element with the id attribute set to "my_button."
We use the click method on the located button element to simulate a click action.
We use driver.switch_to.alert to switch to the alert that appears when the button is clicked.
We print the text of the alert and then accept the alert using alert.accept().
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Alert Text: Button Clicked!This output indicates that the button was successfully located and clicked, resulting in the appearance of an alert with the text "Button Clicked!" The text of the alert is then printed, and the alert is accepted.
Selecting Elements By Name of input type
HTML Source Code:
<html> <head> <title>Example Page</title> </head> <body> <form> <input type="text" name="search" id="search" placeholder="Search..."> <input type="submit" value="Submit"> </form> </body> </html>Python Selenium Code:
from selenium import webdriver from selenium.webdriver.common.by import By # Start a WebDriver instance (e.g., Firefox) and navigate to a webpage driver = webdriver.Firefox() driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file try: # Find the input element with the 'name' attribute set to "search" element = driver.find_element(By.NAME, "search") # Send the keys "Selenium" to the located input element element.send_keys("Selenium") # Sleep for a few seconds to see the entered text (optional) import time time.sleep(3) except Exception as e: # Handle any exceptions that may occur during execution print("An error occurred:", str(e)) finally: # Close the browser window driver.quit()In this example:
We have the HTML source code provided, which includes a
element containing an element with the name attribute set to "search" and a submit button.In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the find_element method with By.NAME to locate the input element with the name attribute set to "search."
We use the send_keys method on the located input element to send the keys "Selenium" to it.
We optionally add a sleep command to pause execution for a few seconds (3 seconds in this case) to visually see the entered text in the input field. You can remove this line if not needed.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, there won't be any visible output on the console. However, the code will successfully locate the input element and send the keys "Selenium" to it, filling in the input field.
Selecting Elements By Name of input type
HTML Source Code:
<!DOCTYPE html> <html> <head> <title>Example Page</title> </head> <body> <input type="text" id="search_input" value="Initial Text"> <button id="clear_button">Clear</button> </body> </html>Python Selenium Code:
from selenium import webdriver from selenium.webdriver.common.by import By # Start a WebDriver instance (e.g., Firefox) and navigate to a webpage driver = webdriver.Firefox() driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file try: # Find the input element with the 'id' attribute set to "search_input" element = driver.find_element(By.ID, "search_input") # Clear the contents of the located input element element.clear() # Sleep for a few seconds to see the cleared input (optional) import time time.sleep(3) except Exception as e: # Handle any exceptions that may occur during execution print("An error occurred:", str(e)) finally: # Close the browser window driver.quit()In this example:
We have the HTML source code provided, which includes an element with the id attribute set to "search_input" and an initial value of "Initial Text."
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the find_element method with By.ID to locate the input element with the id attribute set to "search_input."
We use the clear method on the located input element to clear its contents.
We optionally add a sleep command to pause execution for a few seconds (3 seconds in this case) to visually see the cleared input field. You can remove this line if not needed.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, there won't be any visible output on the console. However, the code will successfully locate the input element and clear its contents.
Selecting Elements By ID of input type search
Selecting Elements By ID of Image type using Xpath
HTML Source Code:
<html> <head> <title>Example Page</title> </head> <body> <div> <img id="logo" src="https://example.com/logo.png" alt="Logo"> </div> </body> </html>Python Selenium Code:
from selenium import webdriver from selenium.webdriver.common.by import By # Start a WebDriver instance (e.g., Firefox) and navigate to a webpage driver = webdriver.Firefox() driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file try: # Find the <img> element with the 'id' attribute set to "logo" element = driver.find_element(By.XPATH, "//img[@id='logo']") # Get the 'src' attribute of the located <img> element src = element.get_attribute("src") # Print the 'src' attribute print("Image Source URL:", src) except Exception as e: # Handle any exceptions that may occur during execution print("An error occurred:", str(e)) finally: # Close the browser window driver.quit()In this example:
We have the HTML source code provided, which includes a
element containing anelement with the id attribute set to "logo" and an src attribute pointing to an image file.
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the find_element method with By.XPATH to locate the
element with the id attribute set to "logo" using the given XPath expression (//img[@id='logo']).
We use the get_attribute method to retrieve the src attribute of the located
element.
We print the src attribute.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Image Source URL: https://example.com/logo.pngThis output indicates that the src attribute of the
element with the id attribute set to "logo" has been successfully retrieved and printed.
Selecting Elements By CSS_SELECTOR
HTML Source Code:
<!DOCTYPE html> <html> <head> <title>Example Page</title> </head> <body> <div class="error-message">This is an error message</div> </body> </html>Python Selenium Code:
from selenium import webdriver from selenium.webdriver.common.by import By # Start a WebDriver instance (e.g., Firefox) and navigate to a webpage driver = webdriver.Firefox() driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file try: # Find the element with the CSS class "error-message" element = driver.find_element(By.CSS_SELECTOR, ".error-message") # Check if the element is displayed if element.is_displayed(): print("Element is visible") else: print("Element is not visible") except Exception as e: # Handle any exceptions that may occur during execution print("An error occurred:", str(e)) finally: # Close the browser window driver.quit()In this example:
We have the HTML source code provided, which includes a
element with the CSS class "error-message."In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the find_element method with By.CSS_SELECTOR to locate the element with the CSS class "error-message."
We use the is_displayed method to check if the located element is displayed on the page.
Based on whether the element is displayed or not, we print the appropriate message.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Element is visibleThis output indicates that the element with the CSS class "error-message" has been successfully located and is visible on the page.
Selecting Elements By NAME of button submit
HTML Source Code:
<html> <head> <title>Example Page</title> </head> <body> <form> <input type="text" name="username" placeholder="Username"> <input type="password" name="password" placeholder="Password"> <button type="submit" name="submit_button" disabled>Submit</button> </form> </body> </html>Python Selenium Code:
from selenium import webdriver from selenium.webdriver.common.by import By # Start a WebDriver instance (e.g., Firefox) and navigate to a webpage driver = webdriver.Firefox() driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file try: # Find the button element with the 'name' attribute set to "submit_button" element = driver.find_element(By.NAME, "submit_button") # Check if the element is enabled if element.is_enabled(): print("Element is enabled") else: print("Element is disabled") except Exception as e: # Handle any exceptions that may occur during execution print("An error occurred:", str(e)) finally: # Close the browser window driver.quit()In this example:
We have the HTML source code provided, which includes a
element containing an element for a username, an element for a password, and a element with the name attribute set to "submit_button" and the disabled attribute to indicate that it's initially disabled.In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the find_element method with By.NAME to locate the button element with the name attribute set to "submit_button."
We use the is_enabled method to check if the located element is enabled or disabled.
Based on whether the element is enabled or disabled, we print the appropriate message.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Element is disabledThis output indicates that the button element with the name attribute set to "submit_button" has been successfully located and is initially disabled on the page.
Selecting Elements By XPATH for input type checkbox
HTML Source Code:
<!DOCTYPE html> <html> <head> <title>Example Page</title> </head> <body> <label> <input type="checkbox" name="agree" checked> I agree to the terms and conditions </label> </body> </html>Python Selenium Code:
from selenium import webdriver from selenium.webdriver.common.by import By # Start a WebDriver instance (e.g., Firefox) and navigate to a webpage driver = webdriver.Firefox() driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file try: # Find the checkbox element using XPath element = driver.find_element(By.XPATH, "//input[@type='checkbox']") # Check if the checkbox is selected if element.is_selected(): print("Checkbox is selected") else: print("Checkbox is not selected") except Exception as e: # Handle any exceptions that may occur during execution print("An error occurred:", str(e)) finally: # Close the browser window driver.quit()In this example:
We have the HTML source code provided, which includes a checkbox element inside a element. The checkbox is initially checked (checked attribute).
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the find_element method with By.XPATH to locate the checkbox element using the given XPath expression (//input[@type='checkbox']).
We use the is_selected method to check if the located checkbox element is selected or not.
Based on whether the checkbox is selected or not, we print the appropriate message.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Checkbox is selectedThis output indicates that the checkbox element has been successfully located and is initially selected on the page
Selecting Elements By NAME to submit entire form
HTML Source Code:
<html> <head> <title>Login Page</title> </head> <body> <form name="login_form" action="https://example.com/login" method="post"> <label for="username">Username:</label> <input type="text" id="username" name="username"> <br> <label for="password">Password:</label> <input type="password" id="password" name="password"> <br> <input type="submit" value="Login"> </form> </body> </html>Python Selenium Code:
from selenium import webdriver from selenium.webdriver.common.by import By # Start a WebDriver instance (e.g., Firefox) and navigate to a webpage driver = webdriver.Firefox() driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file try: # Find the form element with the 'name' attribute set to "login_form" form = driver.find_element(By.NAME, "login_form") # Submit the located form form.submit() except Exception as e: # Handle any exceptions that may occur during execution print("An error occurred:", str(e)) finally: # Close the browser window driver.quit()In this example:
We have the HTML source code provided, which includes a
element with the name attribute set to "login_form." Inside the form, there are input fields for a username and password, and a submit button.In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the find_element method with By.NAME to locate the form element with the name attribute set to "login_form."
We use the submit method on the located form element to submit the form.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, there won't be any visible output on the console. However, the code will successfully locate the form element and submit it. The actual behavior might vary if the form is configured to interact with a remote server.
Selecting Elements By XPATH to select particular header tag using class
HTML Source Code:
<!DOCTYPE html> <html> <head> <title>Example Page</title> </head> <body> <h1 class="title">Welcome to the Example Page</h1> </body> </html>Python Selenium Code:
from selenium import webdriver from selenium.webdriver.common.by import By # Start a WebDriver instance (e.g., Firefox) and navigate to a webpage driver = webdriver.Firefox() driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file try: # Find the <h1> element with the class "title" using XPath element = driver.find_element(By.XPATH, "//h1[@class='title']") # Get the text content of the located <h1> element text = element.text # Print the text print("Element Text:", text) except Exception as e: # Handle any exceptions that may occur during execution print("An error occurred:", str(e)) finally: # Close the browser window driver.quit()In this example:
We have the HTML source code provided, which includes an
element with the class "title" and some text content.
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the find_element method with By.XPATH to locate the
element with the class "title" using the given XPath expression (//h1[@class='title']).
We use the text property of the located element to retrieve its text content.
We print the text content.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Element Text: Welcome to the Example PageThis output indicates that the text content of the
element with the class "title" has been successfully retrieved and printed.
Command to write html title, url
HTML Source Code:
<!DOCTYPE html> <html> <head> <title>Example Page - Home</title> </head> <body> <h1>Welcome to the Example Page</h1> <p>This is a sample webpage.</p> </body> </html>Python Selenium Code:
from selenium import webdriver # Start a WebDriver instance (e.g., Firefox) and navigate to a webpage driver = webdriver.Firefox() driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file try: # Get the title of the current webpage title = driver.title # Print the title print("Page Title:", title) except Exception as e: # Handle any exceptions that may occur during execution print("An error occurred:", str(e)) finally: # Close the browser window driver.quit()In this example:
We have the HTML source code provided, which includes a
element with the title "Example Page - Home."In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the driver.title attribute to retrieve the title of the current webpage.
We print the title.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Page Title: Example Page - HomeThis output indicates that the title of the webpage has been successfully retrieved and printed.
==================================================
For Url
HTML Source Code:
<!DOCTYPE html> <html> <head> <title>Example Page</title> </head> <body> <h1>Welcome to the Example Page</h1> <p>This is a sample webpage.</p> </body> </html>Python Selenium Code:
from selenium import webdriver # Start a WebDriver instance (e.g., Firefox) and navigate to a webpage driver = webdriver.Firefox() driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file try: # Get the current URL of the webpage current_url = driver.current_url # Print the current URL print("Current URL:", current_url) except Exception as e: # Handle any exceptions that may occur during execution print("An error occurred:", str(e)) finally: # Close the browser window driver.quit()In this example:
We have the HTML source code provided, which is a simple webpage with a
element.In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the driver.current_url attribute to retrieve the current URL of the webpage.
We print the current URL.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
Current URL: file:///path/to/your/html/file.htmlThis output indicates that the current URL of the webpage has been successfully retrieved and printed.
Command to locate iframe element by switch_to.frame
HTML Source Code:
<!DOCTYPE html> <html> <head> <title>Example Page</title> </head> <body> <h1>Welcome to the Example Page</h1> <iframe id="my_frame" src="https://www.example.com"></iframe> </body> </html>Python Selenium Code:
from selenium import webdriver from selenium.webdriver.common.by import By # Start a WebDriver instance (e.g., Firefox) and navigate to a webpage driver = webdriver.Firefox() driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file try: # Find the <iframe> element with the 'id' attribute set to "my_frame" iframe = driver.find_element(By.ID, "my_frame") # Switch to the located iframe driver.switch_to.frame(iframe) # Perform actions inside the iframe (e.g., interact with its content) # For this example, we'll just retrieve the iframe's current URL iframe_url = driver.current_url # Print the iframe's current URL print("URL inside iframe:", iframe_url) # Switch back to the main content (outside the iframe) driver.switch_to.default_content() except Exception as e: # Handle any exceptions that may occur during execution print("An error occurred:", str(e)) finally: # Close the browser window driver.quit()In this example:
We have the HTML source code provided, which includes an element with the id attribute set to "my_frame" and a src attribute pointing to "https://www.example.com." Inside the , you can have content from another website or any other content.
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to a local HTML file using file:/// followed by the actual path to your HTML file.
We use the find_element method with By.ID to locate the element with the id attribute set to "my_frame."
We use driver.switch_to.frame(iframe) to switch the WebDriver's focus to the located . Now, any subsequent actions will be performed within the iframe.
Inside the iframe, we retrieve the iframe's current URL using driver.current_url and print it.
We then switch back to the main content (outside the iframe) using driver.switch_to.default_content().
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, the expected output will be:
URL inside iframe: https://www.example.com/Selecting Elements By LINK_TEXT to go back/forward or next page click text embed with anchor tag
Go back
HTML Source Code:
<!DOCTYPE html> <html> <head> <title>Page 1</title> </head> <body> <h1>Page 1</h1> <a href="page2.html">Go to Page 2</a> </body> </html>HTML Source Code (page2.html):
<!DOCTYPE html> <html> <head> <title>Page 2</title> </head> <body> <h1>Page 2</h1> <a href="page1.html">Go back to Page 1</a> </body> </html>Python Selenium Code:
from selenium import webdriver # Start a WebDriver instance (e.g., Firefox) and navigate to the first page driver = webdriver.Firefox() driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file try: # Click a link to navigate to the second page (page2.html) link = driver.find_element_by_link_text("Go to Page 2") link.click() # Wait for a moment to simulate interaction on the second page driver.implicitly_wait(2) # Use the 'driver.back()' method to navigate back to the first page driver.back() except Exception as e: # Handle any exceptions that may occur during execution print("An error occurred:", str(e)) finally: # Close the browser window driver.quit()In this example:
We have two HTML pages: "page1.html" and "page2.html." The first page (page1.html) contains a link that allows navigation to the second page (page2.html).
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to the first page (page1.html) using file:/// followed by the actual path to your HTML file.
We locate and click a link with the text "Go to Page 2" to navigate to the second page (page2.html).
We simulate interaction on the second page (e.g., waiting for 2 seconds to represent actions on the page).
We use driver.back() to navigate back to the first page. This action is equivalent to clicking the browser's back button.
Assuming the HTML files are located at the specified path and the Selenium code is correctly configured, there won't be any visible output on the console. However, the code will successfully navigate between the two pages as described in the example.
Command to refresh page using driver.refresh
HTML Source Code:
<!DOCTYPE html> <html> <head> <title>Refresh Example</title> </head> <body> <h1>Welcome to the Refresh Example Page</h1> <p>This is some content that may change.</p> <button onclick="changeContent()">Change Content</button> <script> // JavaScript function to change the content function changeContent() { document.querySelector("p").textContent = "Content has been updated."; } </script> </body> </html>Python Selenium Code:
from selenium import webdriver # Start a WebDriver instance (e.g., Firefox) and navigate to the webpage driver = webdriver.Firefox() driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file try: # Simulate interaction with the webpage (e.g., click a button to change content) button = driver.find_element_by_tag_name("button") button.click() # Wait for a moment to ensure that the content changes driver.implicitly_wait(2) # Use the 'driver.refresh()' method to refresh the webpage driver.refresh() except Exception as e: # Handle any exceptions that may occur during execution print("An error occurred:", str(e)) finally: # Close the browser window driver.quit()In this example:
We have the HTML source code provided, which includes a button that, when clicked, changes the content of a
element on the page.
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to the local HTML file using file:/// followed by the actual path to your HTML file.
We simulate interaction with the webpage by locating the button and clicking it. This action triggers a JavaScript function that changes the content of the
element.
We wait for a moment using driver.implicitly_wait(2) to ensure that the content changes.
We use driver.refresh() to refresh the current webpage, causing it to reload its content.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, there won't be any visible output on the console. However, the code will successfully simulate interaction with the webpage, change its content, and then refresh the page, which will reset the content to its original state as described in the example.
Command to execute script to scroll to the bottom of the page
HTML Source Code:
<!DOCTYPE html> <html> <head> <title>Scroll Example</title> <style> body { height: 2000px; } </style> </head> <body> <h1>Welcome to the Scroll Example Page</h1> <p>This is some content at the top of the page.</p> <div style="height: 1500px;"> </div> <p>This is some content at the bottom of the page.</p> </body> </html>Python Selenium Code:
from selenium import webdriver # Start a WebDriver instance (e.g., Firefox) and navigate to the webpage driver = webdriver.Firefox() driver.get("file:///path/to/your/html/file.html") # Replace with the actual path to your HTML file try: # Use 'driver.execute_script' to scroll to the bottom of the page driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # Wait for a moment to allow time for scrolling driver.implicitly_wait(2) except Exception as e: # Handle any exceptions that may occur during execution print("An error occurred:", str(e)) finally: # Close the browser window driver.quit()In this example:
We have the HTML source code provided, which includes a webpage with a long vertical scroll. The page contains content at the top and bottom, and we've added CSS to make the page taller to enable scrolling.
In the Python Selenium code, we start a WebDriver instance (Firefox) and navigate to the local HTML file using file:/// followed by the actual path to your HTML file.
We use driver.execute_script to execute JavaScript code that scrolls the webpage to the bottom of the page. The script uses window.scrollTo(0, document.body.scrollHeight); to scroll to the maximum scroll height.
We wait for a moment using driver.implicitly_wait(2) to allow time for the scrolling to occur.
Assuming the HTML file is located at the specified path and the Selenium code is correctly configured, there won't be any visible output on the console. However, the code will successfully scroll the webpage to the bottom as described in the example.
We print the text content of the located third
- element.

Top comments (0)