List out terminology definition for object detection
Explain confidence value for object detection
How to calculate boundary box and confidence value for object detection
List out terminology definition for object detection
When dealing with object detection in computer vision, there are several key terms and concepts. Here's a checklist of terminology commonly associated with object detection, along with brief explanations and examples:
Object Detection:
Definition: The task of identifying and localizing objects in an image or video.
Example: Detecting and locating multiple cars, pedestrians, and traffic signs in a street scene.
Bounding Box:
Definition: A rectangular box that outlines the spatial extent of an object in an image.
Example: A bounding box around a detected car in an image.
Class Label:
Definition: A category or label assigned to an object.
Example: "Car," "Person," or "Dog" as class labels.
Anchor Boxes (or Priors):
Definition: Reference bounding boxes of different sizes and aspect ratios used for object localization.
Example: In the anchor-based methods like Faster R-CNN, a set of anchor boxes is defined for predicting object locations.
Region Proposal Network (RPN):
Definition: A neural network that proposes candidate object regions for further consideration by the detection network.
Example: Faster R-CNN uses an RPN to generate region proposals.
Non-Maximum Suppression (NMS):
Definition: A technique for removing redundant bounding boxes by selecting the one with the highest confidence score.
Example: After object detection, NMS eliminates overlapping bounding boxes, keeping only the most confident ones.
Intersection over Union (IoU):
Definition: A metric that measures the overlap between two bounding boxes.
Example: IoU is used in NMS to determine how much two bounding boxes overlap.
Backbone Network:
Definition: The base network architecture used for feature extraction in object detection models.
Example: ResNet, VGG, or MobileNet can serve as backbone networks.
Feature Pyramid Network (FPN):
Definition: A network that builds a feature pyramid from the backbone network to capture features at multiple scales.
Example: FPN enhances the ability to detect objects of various sizes.
Single Shot MultiBox Detector (SSD):
Definition: An object detection framework that performs detection at multiple scales using predefined anchor boxes.
Example: SSD is used for real-time object detection in a single pass through the network.
You Only Look Once (YOLO):
Definition: An object detection algorithm that divides an image into a grid and predicts bounding boxes and class probabilities directly from grid cells.
Example: YOLO is known for its real-time detection capabilities.
Mean Average Precision (mAP):
Definition: A metric that combines precision and recall to evaluate the overall performance of an object detection model.
Example: A high mAP indicates a good balance between precision and recall in object detection.
Fine-Tuning:
Definition: The process of further training a pre-trained model on a specific dataset to adapt it to a new task.
Example: Fine-tuning a pre-trained model for detecting custom objects in a specific domain.
These terms provide a foundation for understanding and discussing object detection in the context of computer vision. The field continues to evolve, and new approaches and terminology may emerge over time.
Explain confidence value for object detection
The confidence value in object detection plays a crucial role in determining the reliability of a detected object within a bounding box. It represents the model's confidence or probability that the detected object belongs to a certain class and that the predicted bounding box accurately encompasses the object. Understanding the confidence value helps in making decisions about whether to trust the detection results and how to handle them, especially in scenarios with multiple object classes.
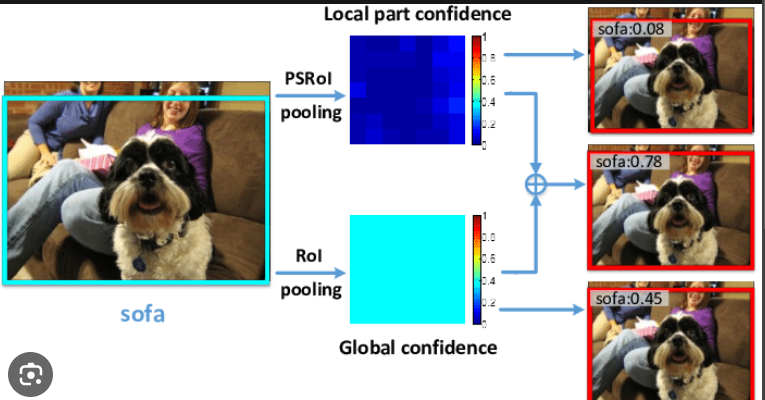
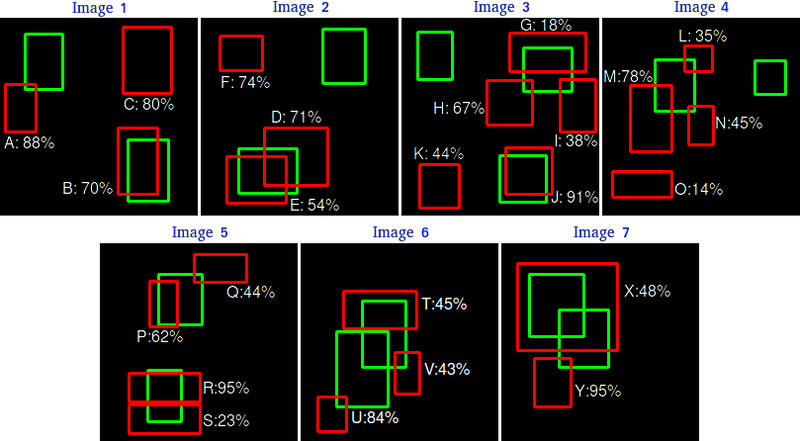

Here's an explanation of the role of the confidence value with examples:
Thresholding:
Confidence values are often used to filter out detections below a certain threshold
. A threshold is set to determine the minimum confidence required for a detection to be considered valid.
Example: If the threshold is set at 0.5, all detections with a confidence value below 0.5 may be discarded.
Decision Making:
The confidence value aids in decision-making processes, especially in applications where accurate object detection is critical.
Example: In an autonomous vehicle system, a high-confidence detection of a pedestrian is more likely to be acted upon than a low-confidence detection.
Handling Uncertainty:
Low-confidence detections may indicate uncertainty or ambiguity in the prediction. In such cases, it's important to handle the results with caution or to seek additional confirmation.
Example: In medical imaging, a low-confidence detection of a potential anomaly might prompt further examination or a second opinion.
Multi-Class Detection:
In scenarios with multiple object classes, the confidence values are often used to determine the predicted class for each detection.
Example: If a model is trained to detect both cars and pedestrians, the confidence value helps decide whether a given detection corresponds to a car or a pedestrian.
Precision-Recall Trade-off:
Adjusting the confidence threshold can affect the trade-off between precision and recall. A higher threshold increases precision but may decrease recall, and vice versa.
Example: In a surveillance system, a higher confidence threshold might be chosen to reduce false positives, even if it means potentially missing some detections.
Non-Maximum Suppression (NMS):
Confidence values are often used in conjunction with non-maximum suppression to merge or eliminate overlapping bounding boxes and select the most confident detection.
Example: When multiple bounding boxes overlap for the same object, NMS considers the confidence values to retain the most accurate and confident detection.
How to calculate boundary box and confidence value for object detection
Object detection involves identifying and locating objects within an image or a video frame. One common approach is to use bounding boxes to represent the location of detected objects along with confidence scores indicating the model's confidence in the accuracy of the detection. The most widely used object detection frameworks, such as YOLO (You Only Look Once) and SSD (Single Shot Multibox Detector), employ these concepts.
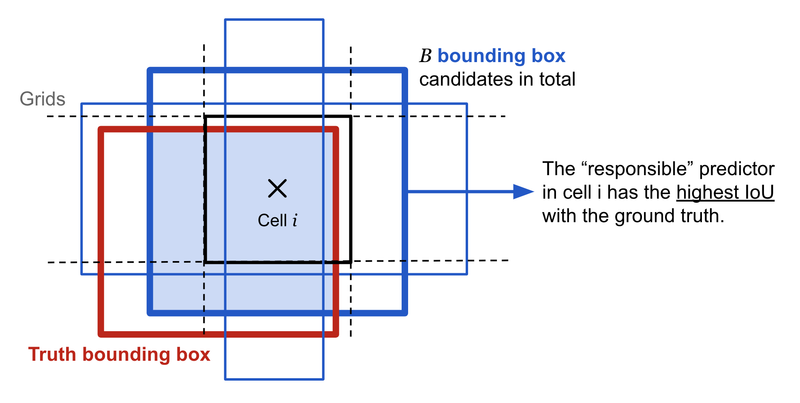
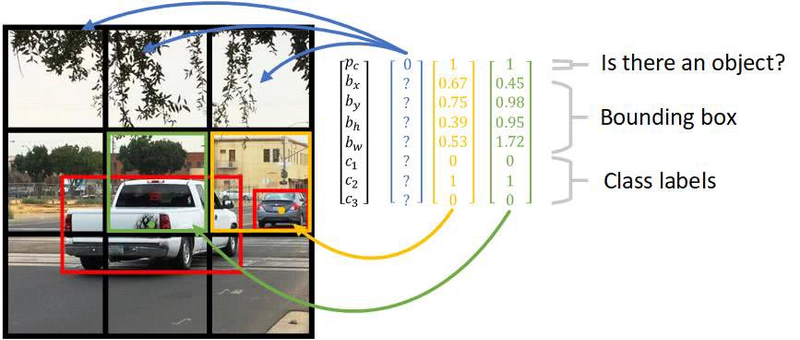
Here's a high-level overview of how bounding boxes and confidence values are calculated:
Bounding Box Calculation:
A bounding box is typically represented by four values: (x, y, w, h), where (x, y) is the coordinate of the top-left corner of the box, and (w, h) are the width and height of the box, respectively.
These values are often predicted as offsets from anchor boxes or default boxes that are defined during the training process.
The predicted bounding box coordinates are usually in the form of offsets, which are applied to anchor box coordinates to obtain the final bounding box.
Confidence Value Calculation:
The confidence value represents the model's belief in the presence of an object within a bounding box.
It is typically a probability score ranging from 0 to 1, where 1 indicates high confidence.
This score is often obtained using a softmax activation function for multiple classes or a sigmoid activation function for binary classification.
Let's look at a simple example using a hypothetical object detection scenario with a single class:
# Example predictions from a neural network
predicted_offsets = [0.2, 0.1, 0.4, 0.3] # x, y, w, h offsets
confidence_score = 0.85 # Range: [0, 1]
# Assuming anchor box coordinates (x_a, y_a, w_a, h_a)
anchor_box = [0.5, 0.5, 1.0, 1.0]
# Calculate bounding box coordinates
x_pred = anchor_box[0] + predicted_offsets[0] * anchor_box[2]
y_pred = anchor_box[1] + predicted_offsets[1] * anchor_box[3]
w_pred = anchor_box[2] * exp(predicted_offsets[2]) # using exponential function for width
h_pred = anchor_box[3] * exp(predicted_offsets[3]) # using exponential function for height
# Calculate confidence value
confidence_value = confidence_score
# Final bounding box representation
predicted_bbox = [x_pred, y_pred, w_pred, h_pred]
print("Predicted Bounding Box:", predicted_bbox)
print("Confidence Value:", confidence_value)
Note: The actual implementation may vary based on the specific object detection framework and its output format.
In practice, object detection frameworks often provide convenient functions to handle these calculations, and they may also include post-processing steps to filter out low-confidence detections or non-maximum suppression to merge overlapping bounding boxes.



Top comments (0)