Define Region proposal
Difference between region and feature map
How selective search is used to generate region proposal
why Warping is used to Consistent Input Size in rcnn
what is the task of BBox regressor and SVM
Pros and cons of Rcnn
Since Convolution Neural Network (CNN) with a fully connected layer is not able to deal with the frequency of occurrence and multi objects. So, one way could be that we use a sliding window brute force search to select a region and apply the CNN model to that, but the problem with this approach is that the same object can be represented in an image with different sizes and different aspect ratios. While considering these factors we have a lot of region proposals and if we apply deep learning (CNN) to all those regions that would computationally very expensive.
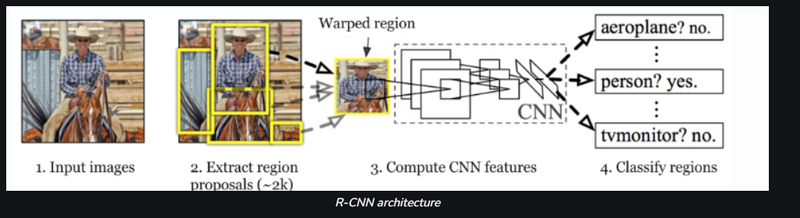
Ross Girshick et al in 2013 proposed an architecture called R-CNN (Region-based CNN) to deal with this challenge of object detection. This R-CNN architecture uses the selective search algorithm that generates approximately 2000 region proposals. These 2000 region proposals are then provided to CNN architecture that computes CNN features. These features are then passed in an SVM model to classify the object present in the region proposal. An extra step is to perform a bounding box regressor to localize the objects present in the image more precisely.
Let's dive deeper into how R-CNN works, step by step.
Region Proposal
R-CNN, which stands for Region-based Convolutional Neural Network, is a computer vision technique used for object detection and localization in images. It operates in several stages, with the first step being the generation of "region proposals" or "region candidates." These regions are essentially subregions of the input image that are likely to contain objects of interest. R-CNN does not create these region proposals itself; instead, it relies on external methods like Selective Search or EdgeBoxes to perform this task.

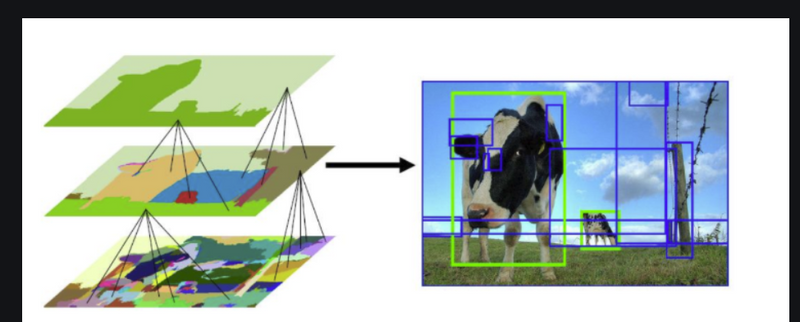
Region proposals are simply the smaller regions of the image that possibly contains the objects we are searching for in the input image. To reduce the region proposals in the R-CNN uses a greedy algorithm called selective search.
Let's delve deeper into how Selective Search works as an example of a method for generating region proposals:
Selective Search
How selective search is used to generate region proposal
is a greedy algorithm that combines smaller segmented regions to generate region proposals.
Input Image: The process starts with an input image, which could be any photograph or frame from a video.
Segmentation: Selective Search divides the input image into multiple smaller segments or regions. These segments are created by merging or separating image areas based on various visual cues such as color, texture, and shape. This segmentation step results in a large number of smaller image segments.
Diverse Proposals: The key idea behind Selective Search is to provide a diverse set of region proposals. Instead of relying on a fixed grid or random sampling, Selective Search intelligently combines and refines the initially segmented regions to generate a wide range of potential object-containing regions. This diversity is crucial because it ensures that a variety of object scales, shapes, and appearances are considered.
Reduced Proposals: After generating a multitude of region proposals, Selective Search applies a filtering process. Some proposals are eliminated if they are too small or too similar to others, reducing the number of candidate regions. This step helps in improving computational efficiency and focusing on more relevant proposals.
Final Proposals: The remaining region proposals are then used as inputs to the subsequent stages of the R-CNN pipeline. These proposals are treated as potential locations where objects might be present, and R-CNN applies object detection techniques to classify and localize objects within these regions.
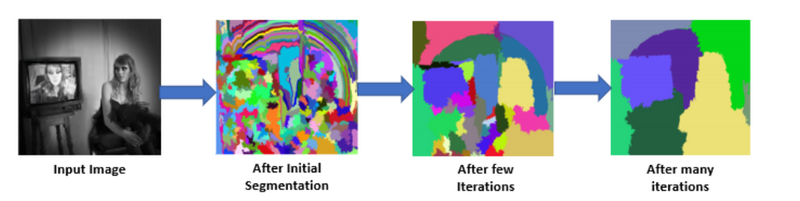
Example of the Selective Search algorithm applied to an image.
Feature Extraction
Feature extraction is a crucial step in computer vision tasks, particularly in the context of object detection or recognition. In this process, the goal is to capture meaningful information from images to enable further analysis and decision-making. Let's break down the process described in your text:
Region Proposal Generation: Initially, the system generates region proposals within the image. These proposals are areas or regions within the image that are likely to contain objects of interest. This step typically uses algorithms like Selective Search or Region Proposal Networks (RPNs) to identify potential regions.
Warping to Consistent Input Size: After generating these region proposals, approximately 2,000 of them are selected for further processing. However, these regions may vary in size and aspect ratio. To ensure that they are compatible with a Convolutional Neural Network (CNN), they are anisotropically warped. This means they are transformed into a consistent input size that the CNN expects, which is often something like 224x224 pixels. During this warping process, an additional 16 pixels of context are added around the region. This context helps the CNN understand the spatial relationships and features within the region better.
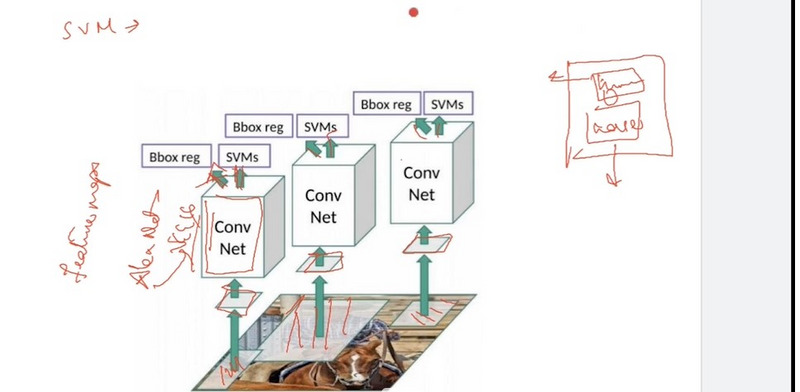
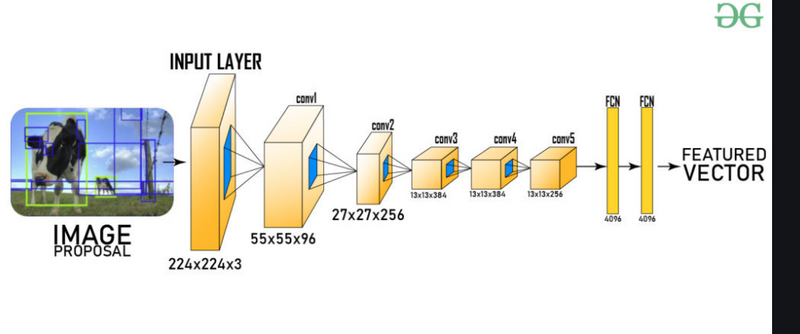
Convolutional Neural Network (CNN): The anisotropically warped regions are then fed into a CNN. In this specific case, AlexNet, a well-known CNN architecture, is utilized. CNNs are particularly effective in computer vision tasks because they can automatically learn hierarchical features from the input data. These networks are known for their ability to extract complex features from images, making them suitable for tasks like object detection.
Fine-tuning on ImageNet: Before using the CNN for the specific task at hand, such as object detection, it is common practice to pre-train the CNN on a large dataset like ImageNet. ImageNet contains a vast variety of images with thousands of object categories. Fine-tuning involves taking the pre-trained CNN and further training it on a smaller dataset related to the specific task, which can help the network adapt to the nuances of the target task.
High-Dimensional Feature Vector: Finally, the output of the CNN for each region proposal is a high-dimensional feature vector. This vector encodes the essential information about the content of the region, including texture, color, and shape features. These feature vectors can be used for various purposes, such as object classification, localization, or further processing in the context of object detection.
An example of how warping works in R-CNN. Note the addition of 16 pixels of context in the middle image.

Object Classification
Object classification is a crucial step in the process of detecting and identifying objects within images or videos. It involves determining which category or class an object belongs to within a given image. One common approach to object classification is used in the context of Region-based Convolutional Neural Networks (R-CNN), which can be broken down into several steps, one of which is the classification of objects within proposed regions of an image. Let's elaborate on this process:
Feature Extraction: The process begins by extracting feature vectors from various region proposals within an image. Region proposals are bounding boxes or regions of interest that are likely to contain objects. These regions are typically generated by algorithms like Selective Search or Region Proposal Networks (RPNs).
Machine Learning Classifier: The extracted feature vectors are then passed into a machine learning classifier. In the case of R-CNN, a separate classifier is used for each object class of interest. These classes can represent different types of objects or entities you want to detect within the image, such as cars, dogs, or people.
Support Vector Machines (SVMs): R-CNN often employs Support Vector Machines (SVMs) as the classifier for object classification. SVMs are a type of supervised learning algorithm that is commonly used for binary classification tasks. In the context of object classification, each SVM is trained to answer a binary question for a specific class: "Does this region proposal contain an instance of the class or not?"
Training: During the training phase of the classifier, a dataset is prepared with labeled examples. Positive samples consist of region proposals that genuinely contain an instance of the class being trained for. These regions are annotated as belonging to the class. Negative samples, on the other hand, are region proposals that do not contain an instance of the class and are labeled as not belonging to that class.
Here's a simplified example to illustrate the training process:
Positive Sample (Car): An image containing a car with a bounding box around it. This bounding box is labeled as a positive sample for the "car" class.
Negative Sample (Car): An image containing no car, or an image with a bounding box around a non-car object. This bounding box is labeled as a negative sample for the "car" class.
The SVM for the "car" class is trained using these positive and negative samples, and it learns to distinguish between regions that contain cars and regions that do not. This process is repeated for each object class of interest, resulting in a set of trained classifiers, each specializing in recognizing a particular class of objects.
Bounding Box Regression
Bounding box regression is a crucial component of object detection models like R-CNN (Region-based Convolutional Neural Network) that enhances the accuracy of object localization. Object detection tasks involve not only classifying objects within an image but also precisely determining their positions and sizes. Bounding box regression addresses the latter aspect by refining the initial bounding box proposals generated during the detection process.
Here's a more detailed explanation of bounding box regression:
Initial Bounding Box Proposals: In the initial stages of object detection, the model generates a set of bounding box proposals across the input image. These proposals are essentially candidate regions that might contain objects of interest.
Classification: After generating these proposals, the model classifies each region to determine whether it contains an object and, if so, what class that object belongs to (e.g., person, car, cat).
Bounding Box Regression: Once the model has identified the object's class within a proposal, it performs bounding box regression. For each object class, a separate regression model is trained. The purpose of this regression model is to adjust the coordinates and dimensions of the initially proposed bounding box to better align with the actual boundaries of the detected object.
Refining the Bounding Box: The bounding box regression model essentially learns to predict corrections or offsets for the coordinates (x, y) of the box's center and its width and height. These corrections are applied to the initial bounding box proposal to obtain a more accurate and tightly fitting bounding box around the object.
Improving Localization: The key benefit of bounding box regression is that it refines the object's localization. By adjusting the bounding box to better match the object's actual position and size, the model becomes more precise in localizing objects in the image. This leads to improved object detection accuracy.
End Result: The final output of the object detection model includes not only the predicted class labels but also the refined bounding boxes for each detected object. These refined bounding boxes provide more accurate information about the object's location and size, making it easier for downstream applications to work with the detected objects, such as tracking or further analysis.
Non-Maximum Suppression (NMS)
Non-Maximum Suppression (NMS) is a critical post-processing step in object detection algorithms like R-CNN (Region-based Convolutional Neural Network). Its primary purpose is to refine the set of bounding boxes generated by the initial object detection process by eliminating redundant or highly overlapping boxes, ensuring that only the most confident and non-overlapping bounding boxes are retained as the final object detections. Let's elaborate on how NMS works and why it is essential:
Initial Detection: In the object detection process, a large number of region proposals are generated by a region proposal network (RPN) or a similar mechanism. These region proposals are potential bounding boxes that may contain objects of interest.
Classification and Regression: Each region proposal is then processed by a classifier to determine whether it contains an object and, if so, to classify the object's category. Additionally, a regression step is performed to refine the coordinates of the bounding box, making it more accurate.
Confidence Scores: Each region proposal is assigned a confidence score based on the object's presence and the accuracy of its bounding box coordinates. The higher the confidence score, the more likely it is that the region proposal contains a valid object.
Sorting by Confidence: The region proposals are sorted in descending order of their confidence scores. This means that the region proposals with the highest confidence scores come first.
NMS Algorithm: Non-Maximum Suppression is applied to the sorted list of region proposals. The process involves the following steps for each region proposal:
a. Select the region proposal with the highest confidence score as the first detection and add it to the list of final detections.
b. Compare the IoU (Intersection over Union) between this selected box and all the remaining region proposals (those with lower confidence scores). IoU measures the overlap between two bounding boxes. If the IoU is above a certain threshold (e.g., 0.5), the overlapping region proposals are considered duplicates or highly overlapping.
c. Remove all region proposals with IoU above the threshold, as they are redundant or overlap significantly with the selected box.
Repeat Steps a to c until all region proposals have been processed.
Final Detections: The result of the NMS process is a set of non-overlapping bounding boxes with high confidence scores, representing the final object detections.

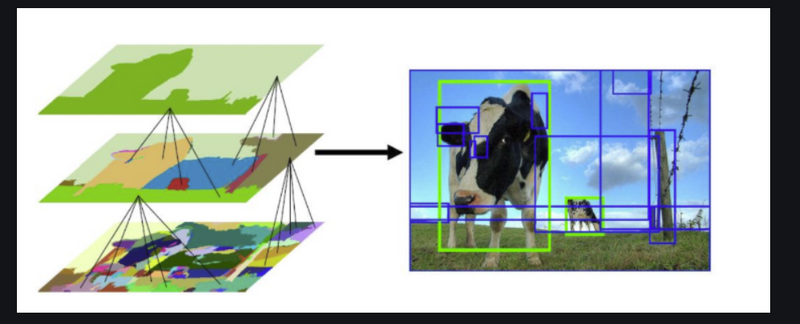
Example of Non-Maximum Suppression.
NMS is crucial for object detection because it helps prevent multiple detections of the same object and reduces false positives. Without NMS, the output could be cluttered with duplicate bounding boxes, making it challenging to obtain accurate object detection results. By selecting the most confident and non-overlapping bounding boxes, NMS improves the precision and reliability of object detection models like R-CNN.
R-CNN Strengths and Disadvantages
Now that we've covered what R-CNN is and how it works, let’s delve into the strengths and weaknesses of this popular object detection framework. Understanding the strengths and disadvantages of R-CNN can help you make an informed decision when choosing an approach for your specific computer vision tasks.
Strengths of R-CNN
Below are a few of the key strengths of the R-CNN architecture.
Accurate Object Detection: R-CNN provides accurate object detection by leveraging region-based convolutional features. It excels in scenarios where precise object localization and recognition are crucial.
Robustness to Object Variations: R-CNN models can handle objects with different sizes, orientations, and scales, making them suitable for real-world scenarios with diverse objects and complex backgrounds.
Flexibility: R-CNN is a versatile framework that can be adapted to various object detection tasks, including instance segmentation and object tracking. By modifying the final layers of the network, you can tailor R-CNN to suit your specific needs.
Disadvantages of R-CNN
Below are a few disadvantages of the R-CNN architecture.
Computational Complexity: R-CNN is computationally intensive. It involves extracting region proposals, applying a CNN to each proposal, and then running the extracted features through a classifier. This multi-stage process can be slow and resource-demanding.
Slow Inference: Due to its sequential processing of region proposals, R-CNN is relatively slow during inference. Real-time applications may find this latency unacceptable.
Overlapping Region Proposals: R-CNN may generate multiple region proposals that overlap significantly, leading to redundant computation and potentially affecting detection performance.
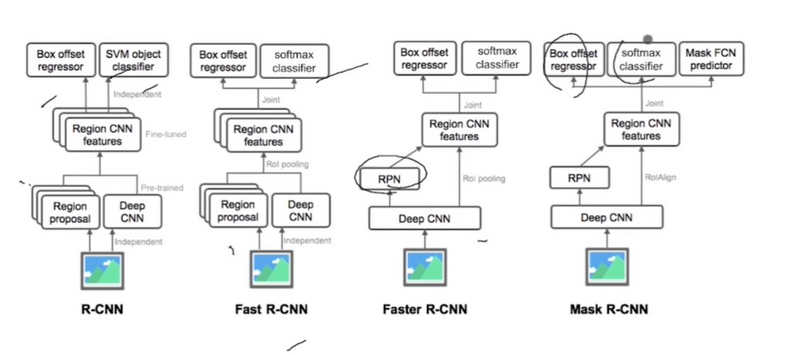
R-CNN is Not End-to-End: Unlike more modern object detection architectures like Faster R-CNN, R-CNN is not an end-to-end model. It involves separate modules for region proposal and classification, which can lead to suboptimal performance compared to models that optimize both tasks jointly.
R-CNN Performance
In the following segment, we will delve into the performance of R-CNN, accompanied by visual demonstrations showcasing its object detection capabilities using the Pascal VoC 2007 dataset.
Why Warping to Consistent Input Size in rcnn
After generating these region proposals, approximately 2,000 of them are selected for further processing. However, these regions may vary in size and aspect ratio. To ensure that they are compatible with a Convolutional Neural Network (CNN), they are anisotropically warped. This means they are transformed into a consistent input size that the CNN expects, which is often something like 224x224 pixels. During this warping process, an additional 16 pixels of context are added around the region. This context helps the CNN understand the spatial relationships and features within the region better.
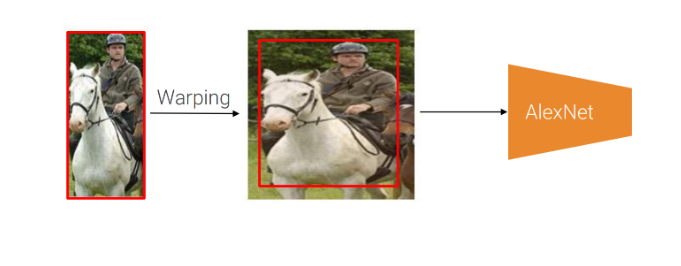
Warping to a consistent input size in Region-based Convolutional Neural Networks (R-CNN) and its variants, such as Fast R-CNN and Faster R-CNN, is crucial for several reasons:
Fixed Input Size Requirement: Many deep learning frameworks and architectures require a fixed input size for efficient processing. This fixed size simplifies the implementation and optimization of the network. By warping regions of interest (ROIs) to a consistent input size, the network can process them uniformly, streamlining the computation.
Standardization of Input: Having a consistent input size ensures that all ROIs are processed in the same manner, regardless of their original size or aspect ratio. This standardization facilitates fair comparison and consistent performance across different regions and images.
Simplification of Downstream Processing: After extracting ROIs from an image, they are typically fed into a CNN for feature extraction and classification. Having ROIs of consistent size simplifies the downstream processing, as the CNN expects inputs of uniform dimensions.
Efficient Batch Processing: During training, batches of ROIs are often processed simultaneously to improve computational efficiency and exploit parallelism. Having ROIs of consistent size allows for efficient batch processing, reducing the need for padding or cropping to match varying dimensions.
Simpler Architecture Design: Using consistent input sizes simplifies the design of the neural network architecture. It allows for fixed-size convolutional filters and pooling operations, streamlining the architecture and reducing the complexity of feature extraction and classification.
What is the task of BBox regressor and SVM
In order to precisely locate the bounding box in the image., we used a scale-invariant linear regression model called bounding box regressor. For training this model we take as predicted and Ground truth pairs of four dimensions of localization. These dimensions are (x, y, w, h) where x and y are the pixel coordinates of the center of the bounding box respectively. w and h represent the width and height of bounding boxes. This method increases the Mean Average precision (mAP) of the result by 3-4%.
Bounding box regression is a crucial component of object detection models like R-CNN (Region-based Convolutional Neural Network) that enhances the accuracy of object localization. Object detection tasks involve not only classifying objects within an image but also precisely determining their positions and sizes. Bounding box regression addresses the latter aspect by refining the initial bounding box proposals generated during the detection process.
Here's a more detailed explanation of bounding box regression:
Initial Bounding Box Proposals: In the initial stages of object detection, the model generates a set of bounding box proposals across the input image. These proposals are essentially candidate regions that might contain objects of interest.
Classification: After generating these proposals, the model classifies each region to determine whether it contains an object and, if so, what class that object belongs to (e.g., person, car, cat).
Bounding Box Regression: Once the model has identified the object's class within a proposal, it performs bounding box regression. For each object class, a separate regression model is trained. The purpose of this regression model is to adjust the coordinates and dimensions of the initially proposed bounding box to better align with the actual boundaries of the detected object.
Refining the Bounding Box: The bounding box regression model essentially learns to predict corrections or offsets for the coordinates (x, y) of the box's center and its width and height. These corrections are applied to the initial bounding box proposal to obtain a more accurate and tightly fitting bounding box around the object.
Improving Localization: The key benefit of bounding box regression is that it refines the object's localization. By adjusting the bounding box to better match the object's actual position and size, the model becomes more precise in localizing objects in the image. This leads to improved object detection accuracy.
End Result: The final output of the object detection model includes not only the predicted class labels but also the refined bounding boxes for each detected object. These refined bounding boxes provide more accurate information about the object's location and size, making it easier for downstream applications to work with the detected objects, such as tracking or further analysis.
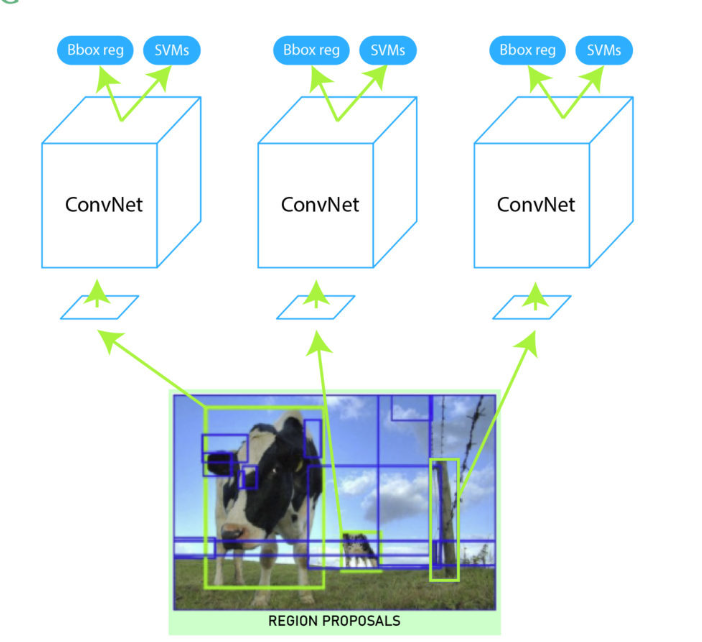
Task of SVM
the SVM classifier assigns class labels to the ROIs based on their visual content, enabling the detection of objects within the image
In Region-based Convolutional Neural Networks (R-CNN) and its variants like Fast R-CNN and Faster R-CNN, the tasks of the Bounding Box (BBox) regressor and the Support Vector Machine (SVM) classifier are crucial components of the object detection pipeline:
BBox Regressor:
The BBox regressor is responsible for refining the bounding box coordinates of the proposed regions of interest (ROIs) to more accurately localize objects within those regions.
After the initial ROIs are generated, typically through a region proposal mechanism such as Selective Search or Region Proposal Networks (RPN) in Faster R-CNN, the BBox regressor adjusts these bounding box coordinates to better align with the object boundaries.
The BBox regressor learns to predict corrections to the coordinates of the initial bounding boxes, typically in terms of offsets for the top-left and bottom-right corners.
This regression is often framed as a regression problem, where the network learns to predict the offsets necessary to adjust the bounding box coordinates towards ground truth annotations.
SVM Classifier:
The SVM classifier is responsible for classifying the proposed ROIs into different object categories or background.
After the ROIs are extracted from the image, each ROI is represented as a feature vector using a CNN.
These feature vectors are then fed into the SVM classifier, which assigns a class label to each ROI based on its visual content.
The SVM classifier is typically trained in a one-vs-rest fashion, where separate binary SVM classifiers are trained for each object category against a background class.
During inference, the SVM classifier scores the ROIs based on their likelihood of containing objects of interest, and the highest scoring ROIs are retained as detections.
In summary, while the BBox regressor refines the bounding box coordinates of the proposed ROIs to better localize objects, the SVM classifier assigns class labels to the ROIs based on their visual content, enabling the detection of objects within the image. These components work together within the R-CNN framework to achieve accurate and robust object detection and localization.
Pros and cons of Rcnn
Challenges of R-CNN
The selective Search algorithm is very rigid and there is no learning happening in that. This sometimes leads to bad region proposal generation for object detection.
Since there are approximately 2000 candidate proposals. It takes a lot of time to train the network. Also, we need to train multiple steps separately (CNN architecture, SVM model, bounding box regressor). So, This makes it very slow to implement.
R-CNN can not be used in real-time because it takes approximately 50 sec to test an image with a bounding box regressor.
Since we need to save feature maps of all the region proposals. It also increases the amount of disk memory required during training.




Top comments (0)