How inception module improving the performance of deep neural networks
Difference between inception v1 and inception v2 architecture in deep learning
Explain Google net inception V1 architecture
Explain different Architectural Changes in Inception V2
Pros and cons of inception module
How inception module improving the performance of deep neural networks
Before the Inception network came research tries how to make deeper models because the most straightforward way of improving the performance of deep neural networks is by increasing their size but some of the problems researchers faces are :
The problem of vanishing gradient arises as the model gets deeper because of which deeper layers not able to train properly and gradient update in deeper layers is not effective. Also, very deep networks are prone to overfitting.
Higher-dimensional filters in convolution layers are computation expensive than the one with a lower dimension.
Let’s understand with this example we have an image of dimension n*n*c and we apply Conv layer with 3*3 filter, the total number of multiplication will be taken place in one stride will be 3*3*c, whereas in 5*5 filter convolution layer total number of multiplication will be 5*5*c, i.e. 5*5 filter is 2.78 times(25/9) more computation expensive than 3*3 filter.
It is always difficult to choose filter size in convolution layers because of this huge variation in the location of the information, choosing the right kernel size for the convolution operation becomes tough. A larger kernel is preferred for information that is distributed more globally, and a smaller kernel is preferred for information that is distributed more locally
Difference between inception v1 and inception v2 architecture in deep learning
Inception v1
This is where it all started. Let us analyze what problem it was purported to solve, and how it solved it. (Paper)
The Premise:
Salient parts in the image can have extremely large variation in size. For instance, an image with a dog can be either of the following, as shown below. The area occupied by the dog is different in each image.

Because of this huge variation in the location of the information, choosing the right kernel size for the convolution operation becomes tough. A larger kernel is preferred for information that is distributed more globally, and a smaller kernel is preferred for information that is distributed more locally.
Very deep networks are prone to overfitting. It also hard to pass gradient updates through the entire network.
Naively stacking large convolution operations is computationally expensive.
The Solution:
Why not have filters with multiple sizes operate on the same level? The network essentially would get a bit “wider” rather than “deeper”. The authors designed the inception module to reflect the same.
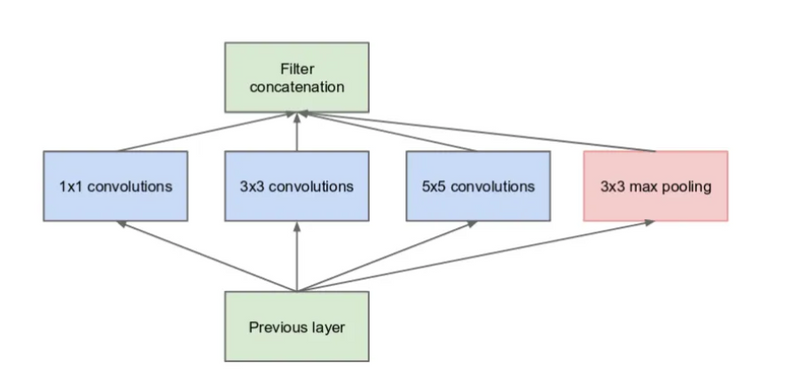
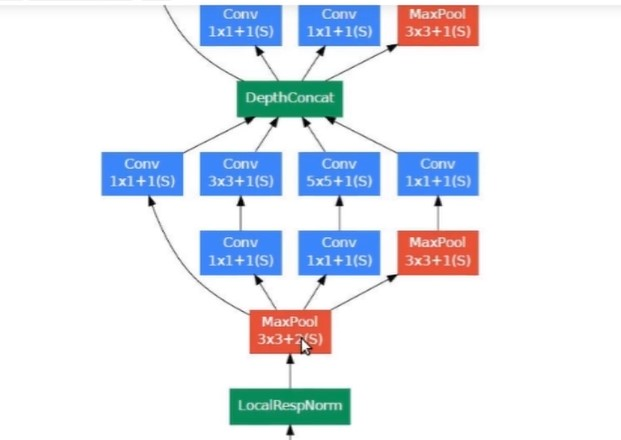
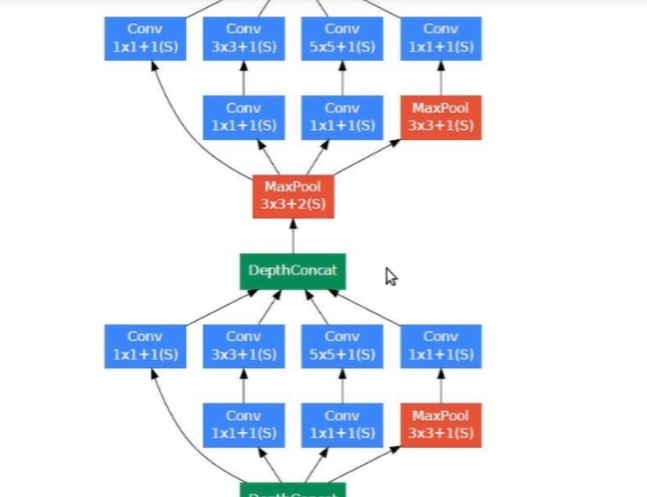
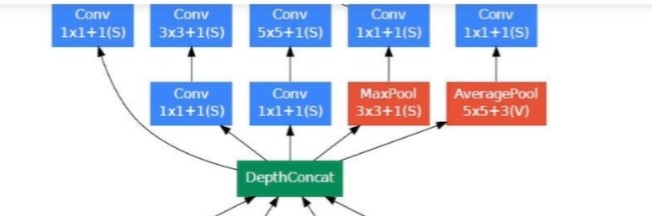
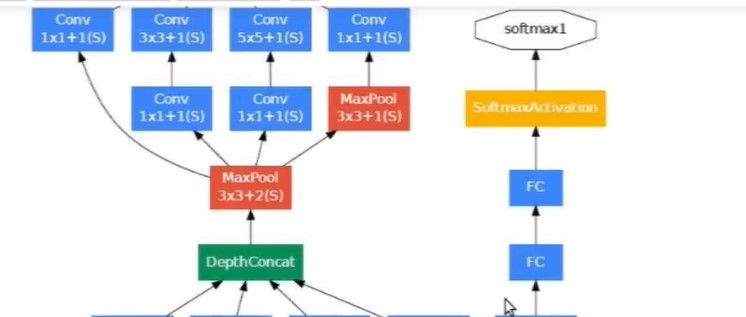
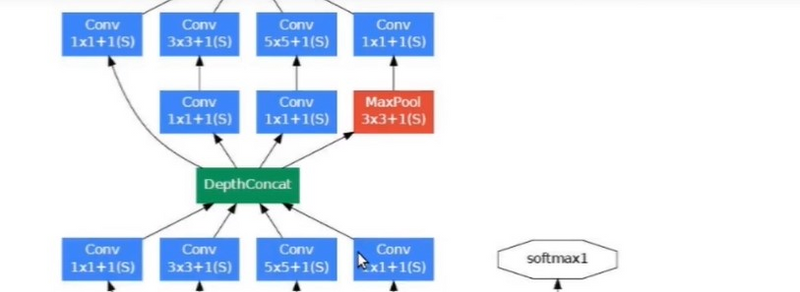
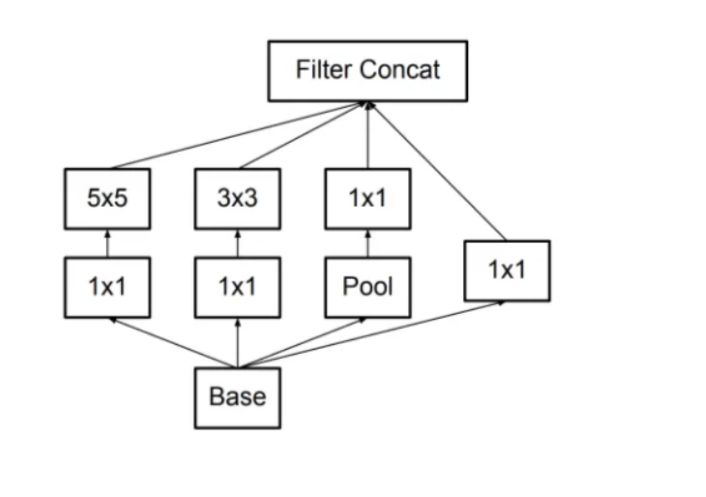
The below image is the “naive” inception module. It performs convolution on an input, with 3 different sizes of filters (1x1, 3x3, 5x5). Additionally, max pooling is also performed. The outputs are concatenated and sent to the next inception module.
It applies convolutions with 3 different filters size ( 1*1, 3*3, 5*5 ) and max pooling on previous layer output in parallel then concatenate it and sent to the next inception module. Result in concatenating features from different convolutions and max pool in one layer without using separate layers each for different operations.
Do note that, concatenation is only done with the same height and width dimensions, that why padding is applied in each layer to make all with the same dimension.
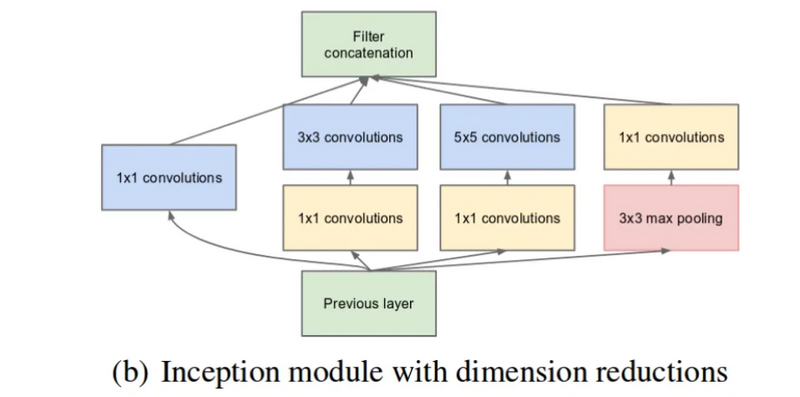
As stated before, deep neural networks are computationally expensive. To make it cheaper, the authors limit the number of input channels by adding an extra 1x1 convolution before the 3x3 and 5x5 convolutions. Though adding an extra operation may seem counterintuitive, 1x1 convolutions are far more cheaper than 5x5 convolutions, and the reduced number of input channels also help. Do note that however, the 1x1 convolution is introduced after the max pooling layer, rather than before.
1*1 Conv filter is used before the 3*3 and 5*5 convolution. 1*1 convolutions help in reducing the number of input channels, so when 3*3 and 5*5 convolutions are applied number of multiplication that taken place is now very less so, it helps in making less computational expensive operations.
Do note that however, the 1x1 convolution is also introduced after the max-pooling layer, rather than before. The reason is being the same to reduce the number the channels in output concatenation
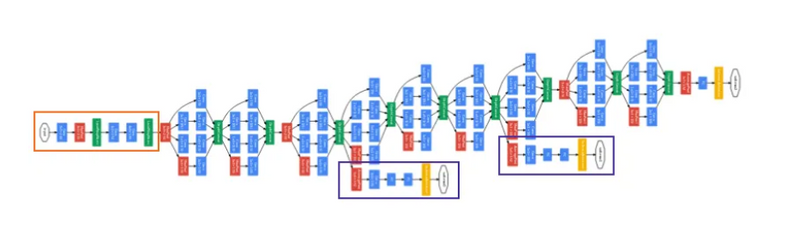
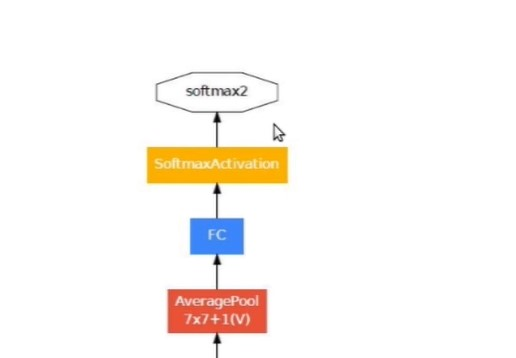
Inception is a deep network, to prevent the middle part of the network from “dying out”(vanishing gradient problem), the authors introduced two auxiliary classifiers. Softmax is applied in each of them and then Auxilary loss is calculated on the same labels of the output classifier.
The total loss function is a weighted sum of the auxiliary loss and the real loss. The weight value used in the paper was 0.3 for each auxiliary loss.
Total loss = real loss + (0.3 * auxiliary loss1) + (0.3 * auxiliary loss2)
Google net inception V1 architecture
Researchers always try to make it better than before which leads to several versions of Inception and the most common ones are Inception-v1, Inception-v2, Inceptio-v3, Inception-v4, Inception-Resnet-v2.
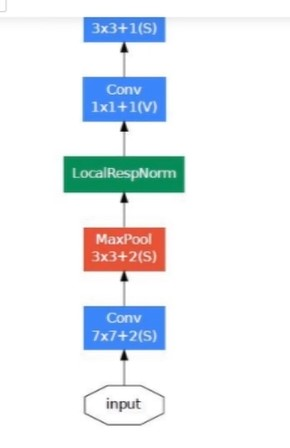
Using the dimension reduced inception module, a neural network architecture was built. This was popularly known as GoogLeNet (Inception v1). The architecture is shown below:
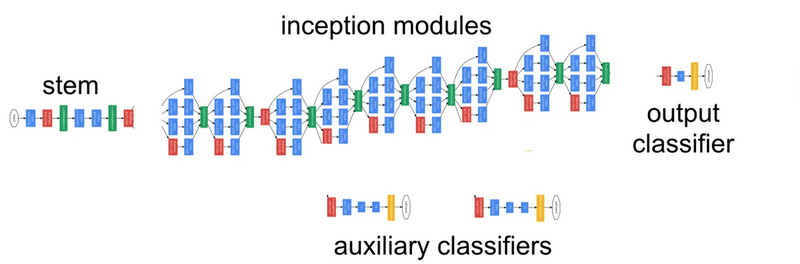
Complete architecture is divided into three-part :
Stem: It is a starting part of the architecture after the input layer, consist of simple max pool layers and convolution layers with Relu activation.
Output classifier: It is the last part of the network after flattening the previous layer, consist of a fully connected layer followed by a softmax function.
Inception module: This is the middle and the most important part of architecture which makes it different from other networks.
Let’s take a deep dive into it.
Here is the ‘naive’ Inception block, Why not have filters with multiple sizes operate on the same level!!


Explain different Architectural Changes in Inception V2
In the Inception V2 architecture. The 5×5 convolution is replaced by the two 3×3 convolutions. This also decreases computational time and thus increases computational speed because a 5×5 convolution is 2.78 more expensive than a 3×3 convolution. So, Using two 3×3 layers instead of 5×5 increases the performance of architecture.
1st architectural changes
5*5 convolutions are replaced with two 3*3 convolutions to make it less computationally expensive, we already described 5*5 convolution is 2.28 times more computation expensive than 3*3 convolution, so stacking two 3*3 Conv leads to boasting in performance
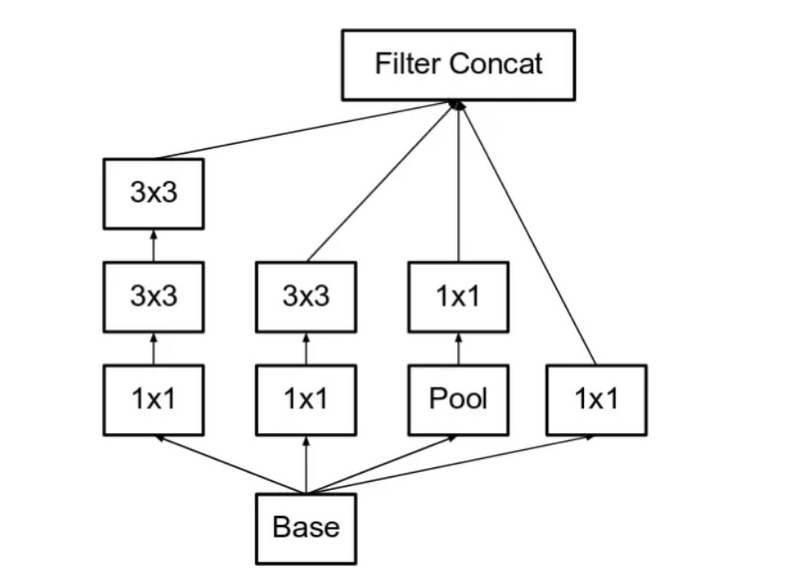
2nd architectural changes
This architecture also converts nXn factorization into 1xn and nx1 factorization. As we discussed above that a 3×3 convolution can be converted into 1×3 then followed by 3×1 convolution which is 33% cheaper in terms of computational complexity as compared to 3×3.
Some 3*3 convolution is replaced with a combination of 1*3 and 3*1 convolutions. It helps in improving speed and computation. Note that both 1*3 and 3*1 must be applied one after the other, the reason being that 1*3 conv only gives horizontal features(one kind of feature) whereas 3*1 Conv gives vertical features of the input. This method was found to be 33% cheaper than the single 3*3 convolution.
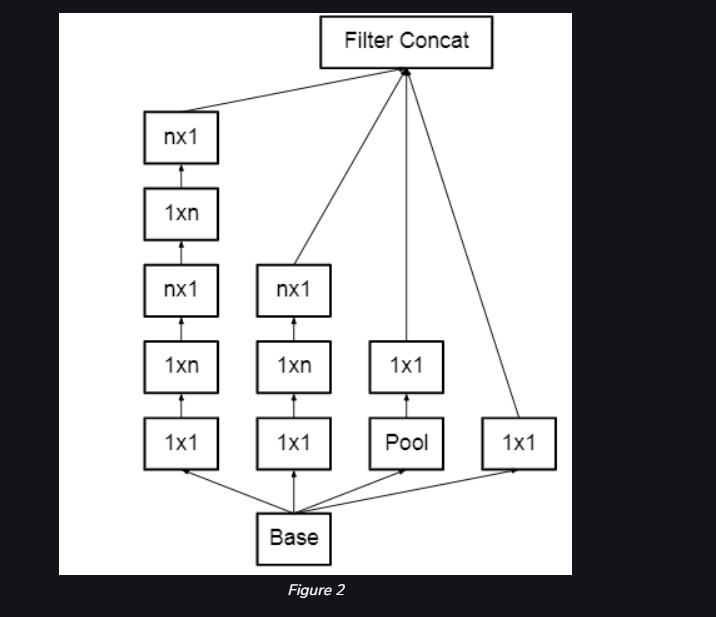
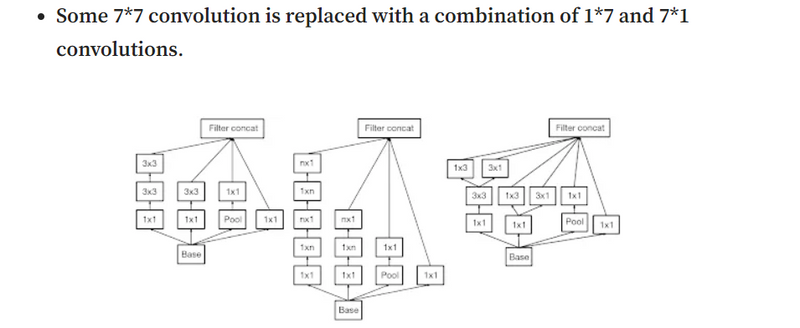
3rd architectural changes
To deal with the problem of the representational bottleneck, the feature banks of the module were expanded instead of making it deeper. This would prevent the loss of information that causes when we make it deeper.
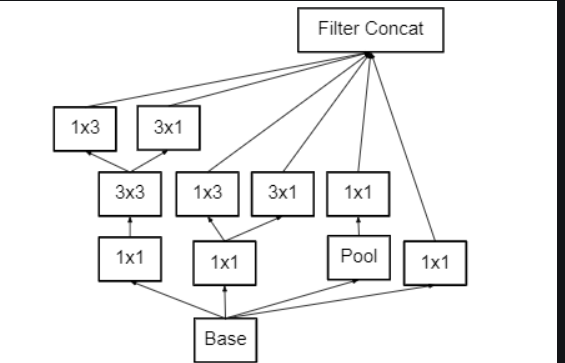

Pros and cons of inception module
Inception modules, popularized by the Inception neural network architecture, have several advantages and disadvantages:
Pros
Feature Diversity: Inception modules allow the network to capture features at multiple spatial scales by employing convolutional filters of different sizes within the same layer. This enables the network to learn diverse features, from fine details to broader patterns, in a single pass.
Computational Efficiency: By using multiple filter sizes in parallel, the network can compute different features simultaneously, which can lead to faster training and inference compared to sequentially processing each filter size.
Parameter Efficiency: Inception modules reduce the number of parameters compared to using only large convolutional filters. This is because the network can capture both local and global features efficiently by combining filters of different sizes, leading to a more compact representation.
Dimensionality Reduction: Inception modules typically include 1x1 convolutions followed by larger convolutions, which helps to reduce the dimensionality of the feature maps before applying more computationally expensive operations, such as larger convolutions. This can help in reducing the computational cost of the network.
Cons
Increased Computational Complexity: While Inception modules offer computational advantages in terms of feature diversity and efficiency, they also introduce increased computational complexity compared to simpler architectures like plain convolutional neural networks (CNNs). This can result in longer training times and higher resource requirements.
Potential Overfitting: Inception modules, especially those with a large number of parallel convolutional paths, can increase the risk of overfitting, especially when the network has limited training data. Managing the model complexity and incorporating regularization techniques becomes crucial to mitigate this risk.
Design Complexity: Designing an effective Inception module requires careful consideration of the number and size of convolutional filters in each parallel path, as well as the architecture's overall depth and width. This complexity can make it more challenging to tune and optimize the network for specific tasks.
Gradient Vanishing/Exploding: The use of deep networks with multiple layers, including Inception modules, can exacerbate the problem of vanishing or exploding gradients during training. Techniques such as batch normalization and careful weight initialization are often necessary to address these issues and ensure stable training.

Top comments (0)