Feature extraction techniques is used to to analyse the similarities between pieces of text.NLP is the ability of computers to understand human language. Need of feature extraction techniques Machine Learning algorithms learn from a pre-defined set of features from the training data to produce output for the test data. But the main problem in working with language processing is that machine learning algorithms cannot work on the raw text directly. So, we need some feature extraction techniques to convert text into a matrix(or vector) of features. Some of the most popular methods of feature extraction are :
the main task=sentence-->tokens--->no/vectors
Bag-of-Words
TF-IDF
Bag of Words:
Bag of Words is a matrix that contain frequency of words in a document
The bag of words model is used for text representation and feature extraction in natural language processing and information retrieval tasks. It represents a text document as a multiset of its words, disregarding grammar and word order, but keeping the frequency of words. This representation is useful for tasks such as text classification, document similarity, and text clustering.
Bag-of-Words is one of the most fundamental methods to transform tokens into a set of features. The BoW model is used in document classification, where each word is used as a feature for training the classifier. For example, in a task of review based sentiment analysis, the presence of words like ‘fabulous’, ‘excellent’ indicates a positive review, while words like ‘annoying’, ‘poor’ point to a negative review . There are 3 steps while creating a
BoW model
:
The first step is text-preprocessing which involves:
converting the entire text into lower case characters.
removing all punctuations and unnecessary symbols.
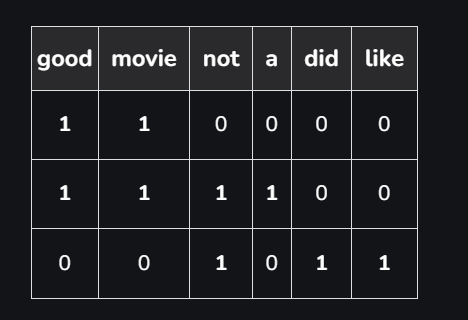
The second step is to create a vocabulary of all unique words from the corpus. Let’s suppose, we have a hotel review text. Let’s consider 3 of these reviews, which are as follows :
good movie
not a good movie
did not like
Now, we consider all the unique words from the above set of reviews to create a vocabulary, which is going to be as follows :
{good, movie, not, a, did, like}
In the third step, we create a matrix of features by assigning a separate column for each word, while each row corresponds to a review. This process is known as Text Vectorization. Each entry in the matrix signifies the presence(or absence) of the word in the review. We put 1 if the word is present in the review, and 0 if it is not present.
For the above example, the matrix of features will be as follows :
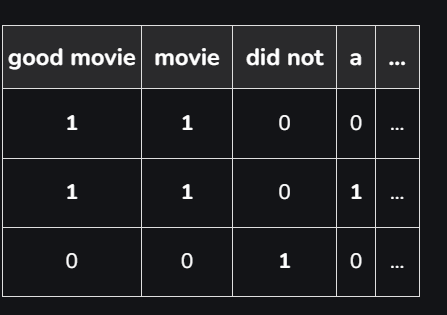
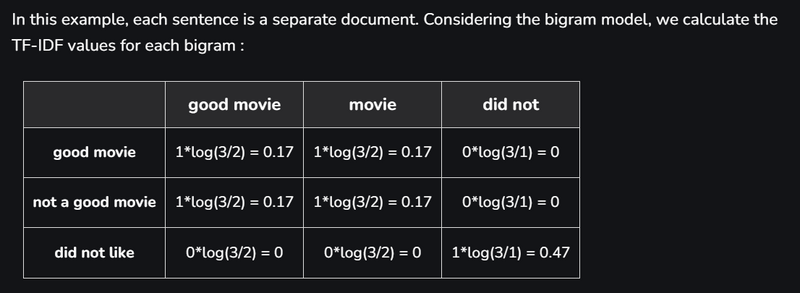
A major drawback in using this model is that the order of occurrence of words is lost, as we create a vector of tokens in randomised order.However, we can solve this problem by considering N-grams(mostly bigrams) instead of individual words(i.e. unigrams). This can preserve local ordering of words. If we consider all possible bigrams from the given reviews, the above table would look like:
However, this table will come out to be very large, as there can be a lot of possible bigrams by considering all possible consecutive word pairs. Also, using N-grams can result in a huge sparse(has a lot of 0’s) matrix, if the size of the vocabulary is large, making the computation really complex!! Thus, we have to remove a few N-grams based on their frequency. Like, we can always remove high-frequency N-grams, because they appear in almost all documents. These high-frequency N-grams are generally articles, determiners, etc. most commonly called as StopWords. Similarly, we can also remove low frequency N-grams because these are really rare(i.e. generally appear in 1 or 2 reviews)!! These types of N-grams are generally typos(or typing mistakes). Generally, medium frequency N-grams are considered as the most ideal. However, there are some N-grams which are really rare in our corpus but can highlight a specific issue. Let’s suppose, there is a review that says – “Wi-Fi breaks often”. Here, the N-gram ‘Wi-Fi breaks can’t be too frequent, but it highlights a major problem that needs to be looked upon. Our BoW model would not capture such N-grams since its frequency is really low. To solve this type of problem, we need another model i.e. TF-IDF Vectorizer, which we will study next. Code : Python code for creating a BoW model is:
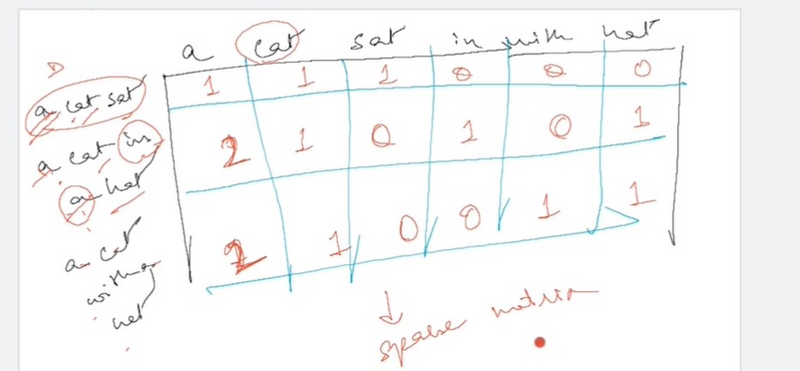
Another example
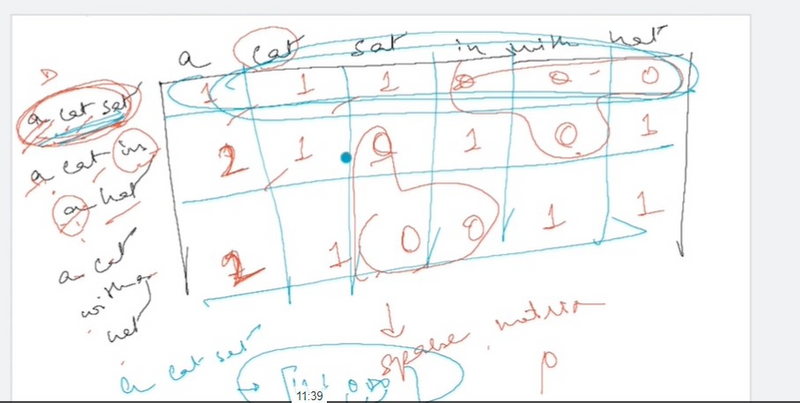

Issues of Bag of Words
The following are some of the issues with the Bag of Words model for text representation and analysis:
High dimensionality: The resulting feature space can be very high dimensional, which may lead to issues with overfitting and computational efficiency.
Lack of context information: The bag of words model only considers the frequency of words in a document, disregarding grammar, word order, and context.
Insensitivity to word associations: The bag of words model doesn’t consider the associations between words, and the semantic relationships between words in a document.
Lack of semantic information: As the bag of words model only considers individual words, it does not capture semantic relationships or the meaning of words in context.
Importance of stop words: Stop words, such as “the”, “and”, “a”, etc., can have a large impact on the bag of words representation of a document, even though they may not carry much meaning.
Sparsity: For many applications, the bag of words representation of a document can be very sparse, meaning that most entries in the resulting feature vector will be zero. This can lead to issues with computational efficiency and difficulty in interpretability.
TF-IDF Vectorizer
:
TF-IDF (Term Frequency-Inverse Document Frequency) is a statistical measure used for information retrieval and natural language processing tasks. It reflects the importance of a word in a document relative to an entire corpus. The basic idea is that a word that occurs frequently in a document but rarely in the entire corpus is more informative than a word that occurs frequently in both the document and the corpus.
TF-IDF is used for:
- Text retrieval and information retrieval systems
- Document classification and text categorization
- Text summarization
- Feature extraction for text data in machine learning algorithms.
TF-IDF stands for term frequency-inverse document frequency. It highlights a specific issue which might not be too frequent in our corpus but holds great importance. The TF–IFD value increases proportionally to the number of times a word appears in the document and decreases with the number of documents in the corpus that contain the word. It is composed of 2 sub-parts, which are :
Term Frequency (TF)
Inverse Document Frequency (IDF)
Term Frequency(TF) : Term frequency specifies how frequently a term appears in the entire document.It can be thought of as the probability of finding a word within the document.It calculates the number of times a word w_i occurs in a review r_j , with respect to the total number of words in the review r_j .It is formulated as:
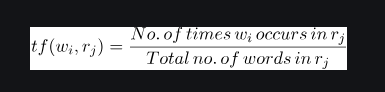
A different scheme for calculating tf is log normalization. And it is formulated as:
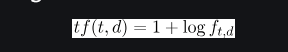
where,
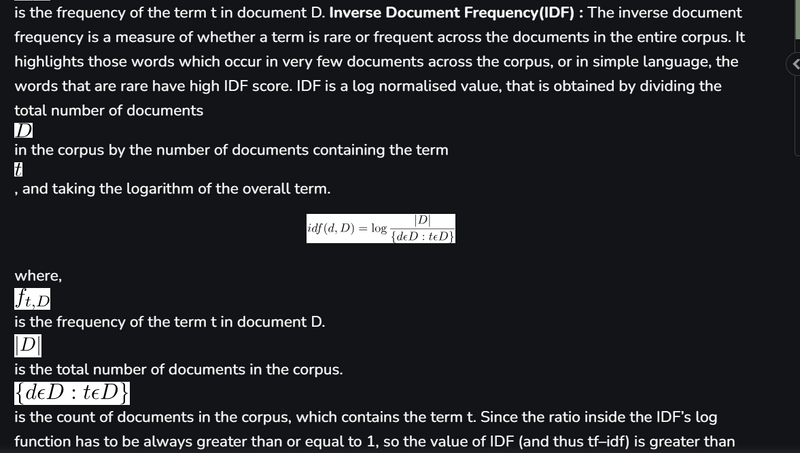




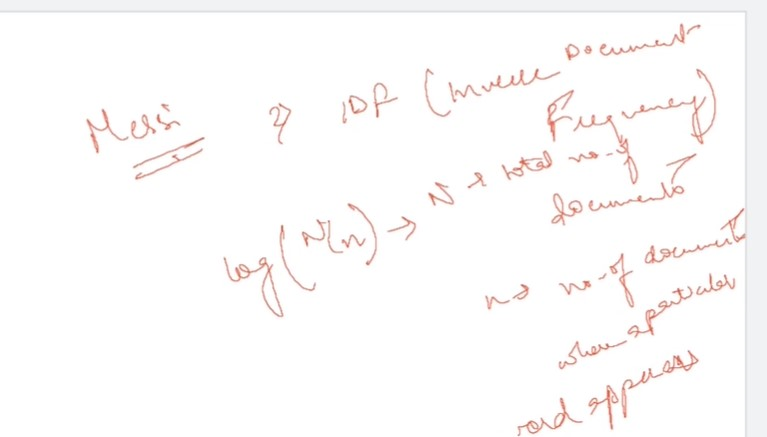

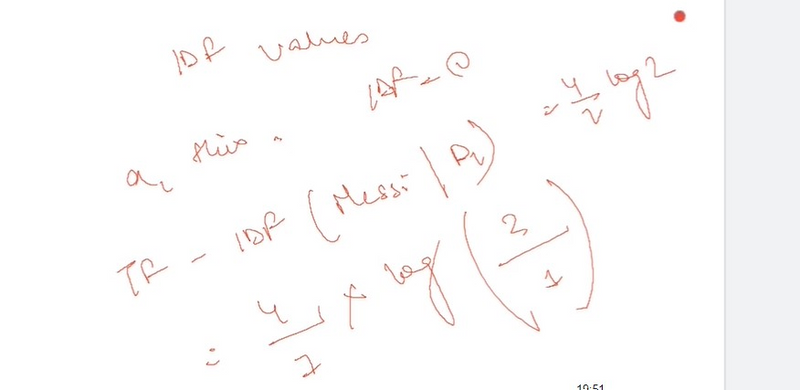
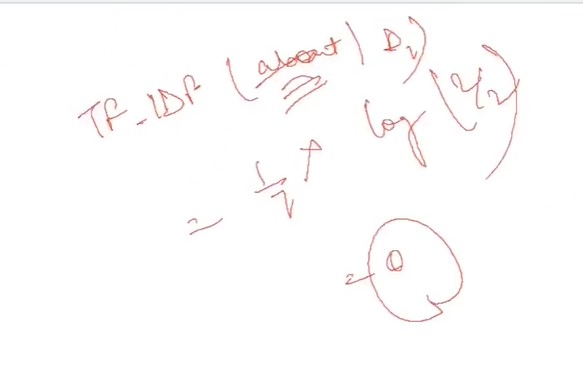
Another Example
good movie
not a good movie
did not like


Top comments (0)