Theory
Why Enterprises Need It
Step-by-Step Breakdown of Enterprise Data Flow Architecture
Key Characteristics of a Good Enterprise Data Architecture
Real-World Example
Coding and tools for each layer
20 Frequently Asked MCQs
Theory
Enterprise Data Flow Architecture is a structured framework that defines how data moves inside an organization — from creation to consumption.

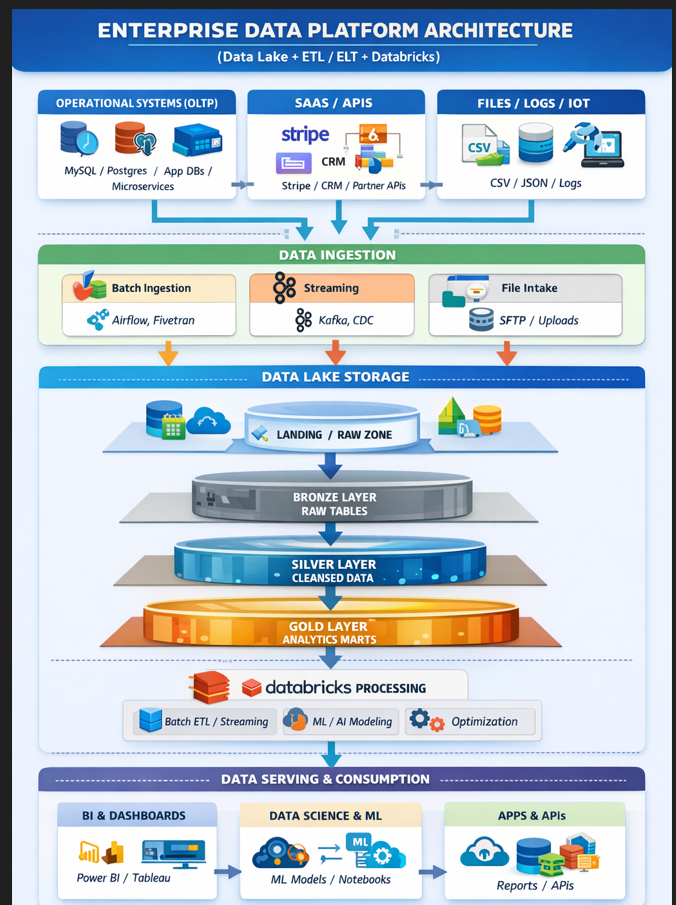
ENTERPRISE DATA PLATFORM ARCHITECTURE
┌────────────────────────────────────────────────────────────────────────────┐
│ ENTERPRISE DATA PLATFORM │
│ (Data Lake + ETL / ELT + Databricks) │
└────────────────────────────────────────────────────────────────────────────┘
DATA SOURCES (OLTP / SaaS / Files)
┌───────────────────────────┐
│ OPERATIONAL SYSTEMS (OLTP)│
│ - MySQL / Postgres │
│ - App Databases │
│ - Microservices │
└───────────────┬───────────┘
│
▼
┌───────────────────────────┐
│ SAAS / APIs │
│ - Stripe │
│ - CRM │
│ - Partner APIs │
└───────────────┬───────────┘
│
▼
┌───────────────────────────┐
│ FILES / LOGS / IoT │
│ - CSV / JSON / Logs │
│ - Clickstream │
│ - Images / PDFs │
└───────────────────────────┘
DATA INGESTION LAYER
┌────────────────────────────────────────────────────────────┐
│ DATA INGESTION │
└────────────────────────────────────────────────────────────┘
┌──────────────────────┐
│ Batch Ingestion │
│ - Airflow │
│ - Fivetran │
│ - ADF / Glue │
└───────────┬──────────┘
│
▼
┌──────────────────────┐
│ Streaming Ingestion │
│ - Kafka │
│ - EventHub │
│ - CDC (Debezium) │
└───────────┬──────────┘
│
▼
┌──────────────────────┐
│ File Intake │
│ - SFTP │
│ - Upload jobs │
│ - Log shippers │
└──────────────────────┘
DATA LAKE STORAGE (Lakehouse Layers)
┌────────────────────────────────────────────────────────────┐
│ DATA LAKE STORAGE │
│ (S3 / ADLS / GCS + Delta Lake Format) │
└────────────────────────────────────────────────────────────┘
Landing / Raw Zone
┌─────────────────────────────────────┐
│ LANDING / RAW ZONE │
│ - Immutable raw data │
│ - Exact source copy │
│ - Partitioned by date/source │
│ - Schema-on-read │
└───────────────┬─────────────────────┘
│
▼
Bronze Layer
┌─────────────────────────────────────┐
│ BRONZE LAYER (Raw Tables) │
│ - Parsed data │
│ - Standardized format │
│ - Minimal cleaning │
└───────────────┬─────────────────────┘
│
▼
Silver Layer
┌─────────────────────────────────────┐
│ SILVER LAYER (Cleansed Data) │
│ - Deduplication │
│ - Null handling │
│ - Joins across sources │
│ - Business-ready datasets │
└───────────────┬─────────────────────┘
│
▼
Gold Layer
┌─────────────────────────────────────┐
│ GOLD LAYER (Analytics Marts) │
│ - KPIs │
│ - Aggregations │
│ - Star schemas │
│ - ML feature tables │
└─────────────────────────────────────┘
DATABRICKS PROCESSING LAYER
┌────────────────────────────────────────────────────────────┐
│ DATABRICKS PROCESSING │
└────────────────────────────────────────────────────────────┘
- Batch ETL / ELT Jobs
- Streaming Transformations
- Data Quality Rules
- ML / AI Model Training
- Optimization (Z-order, compaction)
↓
Spark Clusters / Serverless Compute
↓
Writes Back to Bronze / Silver / Gold
GOVERNANCE & SECURITY (Applies Everywhere)
┌────────────────────────────────────────────────────────────┐
│ GOVERNANCE & SECURITY │
└────────────────────────────────────────────────────────────┘
- Unity Catalog / Metadata
- Schema lineage
- IAM / RBAC
- Row / Column-level security
- Logs & Observability
DATA SERVING & CONSUMPTION
┌────────────────────────────────────────────────────────────┐
│ DATA SERVING & CONSUMPTION │
└────────────────────────────────────────────────────────────┘
┌────────────────────────┐
│ BI & Dashboards │
│ - Power BI │
│ - Tableau │
└────────────┬───────────┘
│
▼
┌────────────────────────┐
│ Data Science & ML │
│ - Notebooks │
│ - Feature Store │
│ - Model Registry │
└────────────┬───────────┘
│
▼
┌────────────────────────┐
│ Apps & APIs │
│ - Reverse ETL │
│ - Reports │
│ - Search / Elastic │
└────────────────────────┘
End-to-End Flow Summary
SOURCES
↓
INGESTION (Batch / Streaming / File)
↓
RAW ZONE
↓
BRONZE
↓
SILVER
↓
GOLD
↓
BI / ML / APPS
It explains:
Where data originates
How it is collected
Where it is stored
How it is processed
How it is delivered to users or systems
In simple words:
It is the blueprint that shows how raw data becomes meaningful business insight.
🏢
Why Enterprises Need It
Modern companies generate data from:
Web applications
Mobile apps
IoT devices
Logs
APIs
Third-party systems
Without a proper architecture:
Data becomes inconsistent
Reports become inaccurate
Systems slow down
Decisions become unreliable
Enterprise Data Flow Architecture ensures:
Data reliability
Scalability
Performance
Security
Governance
🧠 Core Concept
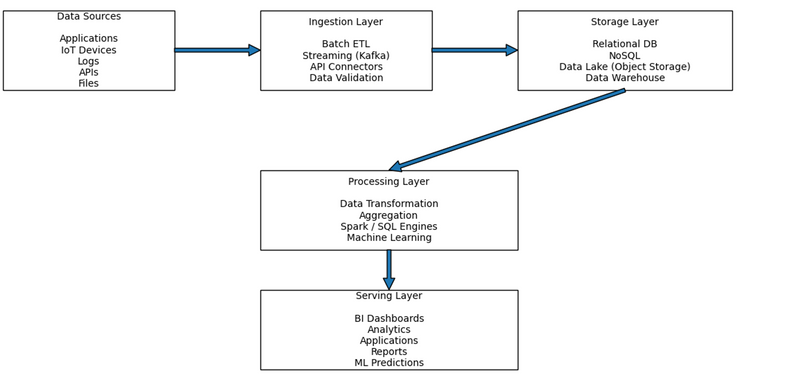
An enterprise data flow architecture follows a logical pipeline:
Data Creation → Data Movement → Data Storage → Data Processing → Data Consumption
Each stage has a clear responsibility.
Step-by-Step Breakdown of Enterprise Data Flow Architecture
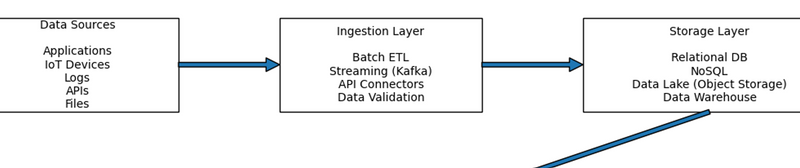
Step 1: Data Sources (Where Data Is Created)
This is the starting point.
Examples:
Customer orders
Payment transactions
Website clicks
Sensor readings
CRM updates
Characteristics:
Raw
Often messy
Different formats (JSON, CSV, logs, SQL tables)
Goal:
Collect everything without losing information.

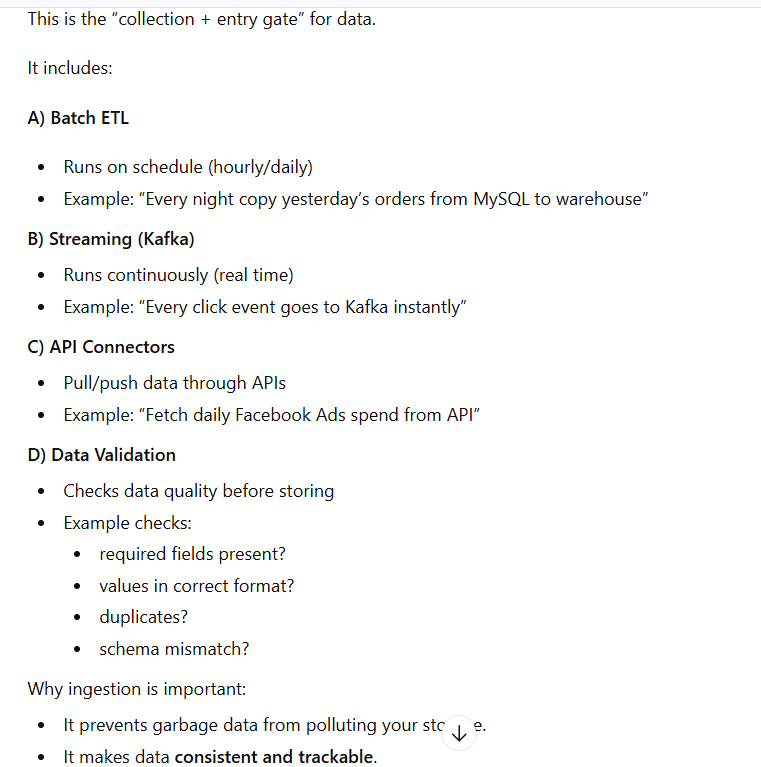
Step 2: Ingestion Layer (How Data Enters the System)
This layer moves data from sources into storage.
It can happen in two ways:
Batch Ingestion
Runs on schedule
Example:
nightly database export
Real-Time Streaming
Continuous data flow
Example: every click event goes instantly to Kafka
Additional tasks:
Data validation
Schema checking
Duplicate removal
Goal:
Move data safely and reliably.
Step 3: Storage Layer (Where Data Lives)
Once ingested, data needs a home.
Enterprises use different storage systems depending on use case:
Relational Databases (structured transactional data)
NoSQL Databases (flexible, scalable apps)
Data Lake (raw + unstructured storage)
Data Warehouse (cleaned analytics storage)
Goal:
Store data efficiently for future access and analysis.

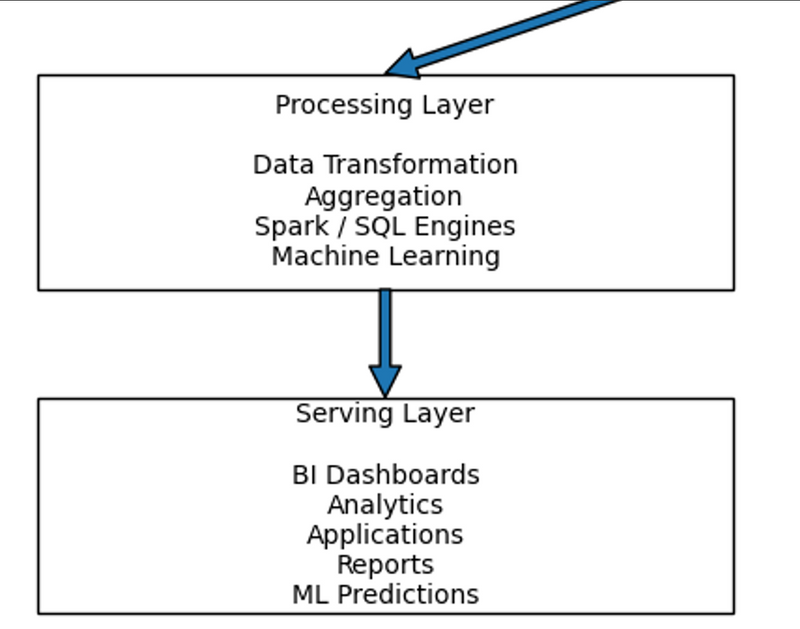
Step 4: Processing Layer (Where Data Becomes Useful)
Raw data is not immediately useful.
Processing includes:
Cleaning
Transforming
Joining multiple datasets
Aggregating metrics
Running machine learning models
Technologies here include:
SQL engines
Spark
ML frameworks
Goal:
Turn raw data into meaningful information.

Step 5: Serving Layer (Where Data Is Used)
This is the final layer.
Processed data is delivered to:
BI dashboards
Analytics reports
Business applications
APIs
Machine learning predictions
Goal:
Support decision-making and product intelligence.

Visual Flow Summary
Data is created
Data is ingested
Data is stored
Data is processed
Data is served
Key Characteristics of a Good Enterprise Data Architecture
A strong architecture should be:
Scalable (handle growing data)
Reliable (no data loss)
Secure (access control)
Governed (auditable and compliant)
Flexible (support batch + streaming)
Cost-efficient
Real-World Example
Imagine an e-commerce company:
Customer places order →
Order event captured →
Sent to Kafka →
Stored in Data Lake →
Transformed in Spark →
Aggregated revenue stored in Warehouse →
Shown on CEO dashboard →
ML model predicts next purchase.
That entire journey is enterprise data flow architecture in action.
Coding and tools for each layer
Data Sources Layer
Coding
Application events: Java, Python, Node.js, Go, .NET
Logging/telemetry: OpenTelemetry SDKs, custom log format
IoT device payloads: C/C++, Python, MQTT payload builders
API producers: REST/GraphQL backends
Tools
App logs: ELK/EFK (Elasticsearch, Logstash/Fluentd, Kibana), Splunk
Event tracking: Segment, RudderStack
IoT messaging: MQTT brokers (Mosquitto), AWS IoT Core, Azure IoT Hub
Source databases: MySQL, PostgreSQL, Oracle, SQL Server
SaaS sources: Salesforce, Google Ads, Stripe APIs
2) Ingestion Layer (ETL / Streaming / Connectors / Validation)
Coding
Batch ETL scripts: Python, SQL, Shell
Stream producers/consumers: Java/Scala, Python, Node.js
Data validation rules: Python, SQL, schema definitions (Avro/JSON Schema)
Tools
Orchestration: Apache Airflow, Prefect, Dagster
Data integration/ELT: Fivetran, Stitch, Hevo, Talend
Streaming: Kafka, Kafka Connect, AWS Kinesis, Azure Event Hubs
Validation/quality: Great Expectations, Deequ, dbt tests
CDC (change data capture): Debezium, AWS DMS
3) Storage Layer (DB / Lake / Warehouse)
Coding
Schema + tables: SQL
Data modeling: dbt (SQL + Jinja templating)
File format handling: Python (pandas/pyarrow), Spark, SQL
Partitioning & lifecycle rules: Infra config (YAML/Terraform), SQL where applicable
Tools
Relational DB: PostgreSQL, MySQL, SQL Server
NoSQL: MongoDB, Cassandra, DynamoDB
Data Lake (object storage): AWS S3, Azure Data Lake/Blob, GCS
Warehouse: Snowflake, BigQuery, Redshift, Synapse
Lakehouse formats: Delta Lake, Apache Iceberg, Apache Hudi
Catalog/metadata: AWS Glue Data Catalog, Unity Catalog, Hive Metastore
4) Processing Layer (Transformations / Aggregations / Spark / ML)
Coding
Transformations: SQL, Python, PySpark/Scala Spark
Aggregations: SQL, Spark
ML pipelines: Python (scikit-learn, XGBoost, TensorFlow, PyTorch)
Tools
Big compute: Apache Spark, Databricks
SQL engines: Trino (Presto), Athena, BigQuery engine, Snowflake SQL
Data build (analytics engineering): dbt
Stream processing: Flink, Spark Structured Streaming, Kafka Streams
ML Ops: MLflow, Kubeflow, SageMaker, Vertex AI, Azure ML
Workflow: Airflow/Prefect often coordinates processing jobs too
5) Serving Layer (BI / Apps / Reports / ML Predictions)
Coding
APIs for data products: Python (FastAPI/Django), Node.js, Java Spring
Dashboards queries: SQL
Reporting exports: Python, SQL, scheduled jobs
Model inference services: Python, sometimes Java/Go for high-performance
Tools
BI & dashboards: Power BI, Tableau, Looker, Metabase, Superset
Analytics layers: LookML (Looker), semantic layers (dbt Semantic Layer, Cube)
Serving DBs (fast reads): PostgreSQL, Redis, ElasticSearch, ClickHouse, Druid
API gateway: Kong, NGINX, Apigee
Monitoring: Prometheus + Grafana, Datadog, CloudWatch
Feature store (ML serving): Feast, Databricks Feature Store
20 Frequently Asked MCQs
1.** What does an Enterprise Data Flow Architecture define?**
A) Data storage size
B) How data moves from source to consumption
C) Company hierarchy
D) UI design
✅ Answer: B
Which one is NOT a data source?
A) Web apps
B) Mobile apps
C) IoT devices
D) SQL query engine
✅ Answer: DETL stands for:
A) Extract, Teach, Load
B) Embed, Transform, Log
C) Extract, Transform, Load
D) Entry, Test, Leave
✅ Answer: CIn streaming ingestion, data is processed:
A) Daily
B) Monthly
C) Continuously
D) Never
✅ Answer: CWhich storage type is best for unstructured data?
A) Relational DB
B) Data Warehouse
C) Data Lake
D) In-memory cache
✅ Answer: CA Data Warehouse is primarily used for:
A) Transaction processing
B) Business analytics
C) Web hosting
D) Frontend UI
✅ Answer: BOLTP stands for:
A) Online Large Transecting Process
B) Online Transaction Processing
C) Offline Transaction Process
D) Open Legacy Transaction Protocol
✅ Answer: BSchema-on-read is a feature of:
A) Data Warehouse
B) Data Lake
C) Relational DB
D) None of these
✅ Answer: BWhich programming language is commonly used for ETL scripting?
A) Python
B) HTML
C) CSS
D) Markdown
✅ Answer: AWhich tool is used for orchestration of data jobs?
A) Git
B) Airflow
C) Photoshop
D) Figma
✅ Answer: BWhat is the role of the ingestion layer?
A) Store data permanently
B) Move data from sources to storage
C) Build UI dashboards
D) Serve API requests
✅ Answer: B
12.** Which of these is a real-time messaging system**?
A) SQLite
B) Kafka
C) Excel
D) Notepad
✅ Answer: B
NoSQL databases are best for:
A) Structured tabular data only
B) Unstructured or semi-structured data
C) Word processing
D) Spreadsheet formulas
✅ Answer: BA data lake typically uses:
A) Disk fragmentation
B) Object storage
C) Relational constraints
D) Spreadsheet cells
✅ Answer: BWhich engine is commonly used for big data processing?
A) Adobe Flash
B) Apache Spark
C) Microsoft Word
D) Internet Explorer
✅ Answer: BMachine learning pipelines are part of which layer?
A) Storage
B) Processing
C) Serving
D) None of these
✅ Answer: BDashboards and reports belong to which layer?
A) Data Source
B) Ingestion
C) Storage
D) Serving
✅ Answer: DWhich of the following is NOT a valid storage type?
A) Data Lake
B) Data Warehouse
C) NoSQL DB
D) CSS Stylesheet
✅ Answer: DData validation typically happens in:
A) Serving Layer
B) Processing Layer
C) Ingestion Layer
D) Physical Hardware
✅ Answer: CThe physical storage layer includes:
A) Block storage
B) File storage
C) Object storage
D) All of the above
✅ Answer: D

Top comments (0)