What is ETL? (Deep Explanation)
Step 1: Extract (Data Collection Phase)
Step 2: Transform (Data Cleaning & Processing Phase)
Step 3: Load (Storage Phase)
ETL Architecture (How It Is Structured)
Detailed ETL Architecture Components
ETL Tools (Layer-wise)
Where ETL Fits in Enterprise Data Flow Architecture
Where ETl fits in datalake and datbricks
Standard ETL Architecture (Layer-by-Layer)
Coding Example of ETL layer
Objective MCQs on Detailed ETL Architecture Components,
Advanced Scenario-Based ETL Coding MCQs
Basic Coding Example of ETL Layer
What is ETL? (Deep Explanation)
Step 1: Extract (Data Collection Phase)
Step 2: Transform (Data Cleaning & Processing Phase)
Step 3: Load (Storage Phase)
ETL Architecture (How It Is Structured)
Detailed ETL Architecture Components
ETL Tools (Layer-wise)
Where ETL Fits in Enterprise Data Flow Architecture
Coding Example of ETL Layer (Conceptual)
What is ETL? (Deep Explanation)
ETL stands for:
Extract → Transform → Load
It is a structured process used to move data from different sources into a centralized system (usually a Data Warehouse or Data Lake) for analysis and reporting.
It solves one core problem:
How do we convert messy, scattered data into clean, usable business intelligence?
🔍
Step 1: Extract (Data Collection Phase)
This is the first stage.
What Happens Here?
Data is pulled from:
Relational databases (MySQL, PostgreSQL)
NoSQL databases
APIs
CSV / Excel files
Logs
IoT streams
Types of Extraction
Full Extraction
Entire dataset copied every time
Incremental Extraction
Only new or changed records are extracted
Uses timestamps or change tracking
Challenges
Different formats
Inconsistent schemas
Missing values
Network failures
Goal:
Safely collect raw data without altering it.
🔄
Step 2: Transform (Data Cleaning & Processing Phase)
This is the most important stage.
Raw data is not analytics-ready.
What Happens Here?
Data cleaning
Removing duplicates
Standardizing formats
Joining tables
Aggregation
Validation
Applying business rules
Types of Transformations
Structural
Change column names, data types
Data Cleaning
Remove nulls, fix inconsistencies
Enrichment
Add new calculated columns
Aggregation
Summaries like:
Total revenue per day
Active users per month
Goal:
Convert raw data into meaningful, consistent, high-quality data.
📦
Step 3: Load (Storage Phase)
This is where transformed data is loaded into:
Data Warehouse
Data Lake
Analytical database
Loading Strategies
Full Load
Replace entire table
Incremental Load
Append only new data
Merge / Upsert
Update existing + insert new records
Goal:
Store clean data for fast analytics and reporting.
🏗️
ETL Architecture (How It Is Structured)
Below is a clean architecture flow:
Data Sources
↓
Extraction Engine
↓
Staging Area
↓
Transformation Engine
↓
Target Storage (Warehouse / Lake)
Detailed ETL Architecture Components
1️⃣ Source Systems
Apps
Databases
APIs
2️⃣ Staging Area
Temporary storage before transformation.
Used for:
Backup
Debugging
Data validation
3️⃣ Transformation Layer
Business logic
Cleansing
Aggregation
Standardization
4️⃣ Target System
Data Warehouse
Analytics DB
Reporting system
ETL Tools (Layer-wise)
Extraction Tools
Fivetran
Stitch
Hevo
Talend
Debezium (CDC)
Transformation Tools
dbt
Apache Spark
SQL Engines
Python (pandas)
PySpark
Orchestration Tools
Apache Airflow
Prefect
Dagster
Streaming ETL
Kafka
Flink
Spark Streaming
Cloud Services
AWS:
AWS Glue
AWS DMS
Redshift
Azure:
Azure Data Factory
Synapse
GCP:
Dataflow
BigQuery
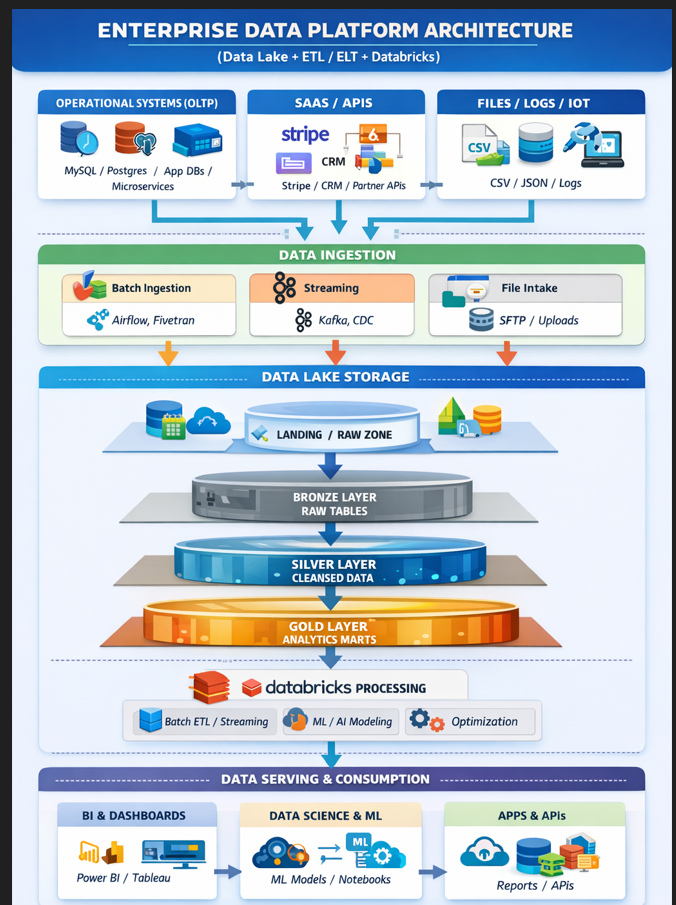
Where ETL Fits in Enterprise Data Flow Architecture
It belongs mainly in:
✔ Ingestion Layer
✔ Partly in Processing Layer (for ELT)
It connects:
Data Sources → Storage Layer
Without ETL, storage becomes messy and unusable.
Standard ETL Architecture (Layer-by-Layer)

Where ETl fits in datalake and datbricks
Full Architecture (Simple View)
App / Database / Logs / APIs
↓
ETL
↓
Data Lake (raw data)
↓
Databricks (process & analyze)
↓
Reports / AI / Dashboards
🌊 Where ETL Fits in Data Lake?
There are actually two patterns:
1️⃣ **Traditional ETL (Old Style)**
Database → ETL → Data Warehouse
Data is transformed first, then loaded.
But this is not ideal for Data Lakes.
2️⃣ Modern ELT (Used with Data Lake + Databricks)
Database → Load Raw → Data Lake → Transform using Databricks
Here:
Data Lake stores raw data first
Databricks performs transformation later
This is more scalable and modern.
🧠 So Where Exactly Does ETL Run?
Option A: ETL Before Data Lake
Example:
Use Airflow / Talend / Informatica
Clean data
Then store in Data Lake
Less common in modern big data systems.
Option B: ETL Inside Databricks (Most Common Today)
Databricks:
Reads raw data from Data Lake
Cleans & transforms it
Writes clean version back to Data Lake (Delta tables)
This is called:
ELT instead of ETL
🏢 Real Example (Hospital Platform)
Let’s say:
You collect:
User activity logs
Payments
Booking data
App click events
Step 1 — Extract
Pull data from:
MySQL
APIs
CSV files
App logs
Step 2 — Load
Dump all raw data into Data Lake (AWS S3 / Azure)
Step 3 — Transform (Databricks)
Remove duplicates
Standardize date formats
Join tables
Calculate KPIs
Create analytics-ready tables
Step 4 — Output
Dashboards
AI models
Reports
Coding Example of ETL layer
ETL Step 0: Setup (Config + DB connection)
What this does
Keeps credentials/config separate
Creates DB connection
Prepares a simple logger
import os
import pandas as pd
import sqlalchemy as sa
from datetime import datetime
DB_URL = os.getenv("DB_URL", "postgresql://user:pass@localhost:5432/mydb")
engine = sa.create_engine(DB_URL)
def log(msg):
print(f"[{datetime.now().isoformat(timespec='seconds')}] {msg}")
✅ Step 1: EXTRACT (Get data from source)
A) Extract from a database (incremental)
Goal: only pull “new/updated” records, not everything.
def extract_orders_incremental(last_run_ts: str) -> pd.DataFrame:
query = sa.text("""
SELECT
order_id,
user_id,
amount,
currency,
status,
created_at,
updated_at
FROM orders
WHERE updated_at > :last_run
ORDER BY updated_at ASC
""")
with engine.connect() as conn:
df = pd.read_sql(query, conn, params={"last_run": last_run_ts})
log(f"Extracted rows: {len(df)}")
return df
Where does last_run_ts come from?
Usually from an ETL metadata table (shown below).
B) Extract from a CSV file
def extract_from_csv(path: str) -> pd.DataFrame:
df = pd.read_csv(path)
log(f"Extracted from CSV rows: {len(df)}")
return df
✅ Step 2: STAGE (Store raw data safely)
Staging helps because:
You can reprocess if transform fails
You keep a raw snapshot
Debugging becomes easy
def stage_raw(df: pd.DataFrame, table_name: str = "stg_orders_raw"):
# Store raw snapshot (append)
df.to_sql(table_name, engine, if_exists="append", index=False)
log(f"Staged into {table_name}: {len(df)} rows")
Tip: In big systems staging is usually:
S3/ADLS (files)
or staging tables in a DB
✅ Step 3: TRANSFORM (Clean + validate + apply business rules)
This is where most ETL logic lives.
Common transformations:
Remove duplicates
Fix nulls
Standardize format
Convert datatypes
Enrich fields
Validate rules
def transform_orders(df: pd.DataFrame) -> pd.DataFrame:
if df.empty:
return df
# 1) Drop duplicates based on unique key
df = df.drop_duplicates(subset=["order_id"], keep="last")
# 2) Convert datatypes
df["created_at"] = pd.to_datetime(df["created_at"], errors="coerce")
df["updated_at"] = pd.to_datetime(df["updated_at"], errors="coerce")
# 3) Basic cleaning
df["currency"] = df["currency"].astype(str).str.upper().str.strip()
df["status"] = df["status"].astype(str).str.lower().str.strip()
# 4) Validate (remove invalid)
# Example rules:
# - order_id must exist
# - amount must be > 0
# - currency should not be empty
df = df[df["order_id"].notna()]
df = df[df["amount"].fillna(0) > 0]
df = df[df["currency"].str.len() > 0]
# 5) Add derived fields (enrichment)
df["amount_inr"] = df.apply(
lambda r: r["amount"] if r["currency"] == "INR" else None,
axis=1
)
log(f"Transformed rows: {len(df)}")
return df
✅ Step 4: LOAD (Write clean data into target)
Target could be:
Data Warehouse table
Reporting table
Analytics DB table
Option A: Simple append (only for pure inserts)
def load_append(df: pd.DataFrame, table_name: str = "dw_orders"):
if df.empty:
log("No rows to load.")
return
df.to_sql(table_name, engine, if_exists="append", index=False)
log(f"Loaded into {table_name}: {len(df)} rows")
Option B: Upsert (insert + update) — Real enterprise pattern
PostgreSQL upsert using SQL:
def load_upsert_postgres(df: pd.DataFrame, target_table: str =
"dw_orders"):
if df.empty:
log("No rows to upsert.")
return
# Load into a temp table first
temp_table = "tmp_orders_upsert"
df.to_sql(temp_table, engine, if_exists="replace", index=False)
upsert_sql = f"""
INSERT INTO {target_table} (order_id, user_id, amount, currency, status, created_at, updated_at, amount_inr)
SELECT order_id, user_id, amount, currency, status, created_at, updated_at, amount_inr
FROM {temp_table}
ON CONFLICT (order_id) DO UPDATE SET
user_id = EXCLUDED.user_id,
amount = EXCLUDED.amount,
currency = EXCLUDED.currency,
status = EXCLUDED.status,
created_at = EXCLUDED.created_at,
updated_at = EXCLUDED.updated_at,
amount_inr = EXCLUDED.amount_inr;
"""
with engine.begin() as conn:
conn.execute(sa.text(upsert_sql))
conn.execute(sa.text(f"DROP TABLE IF EXISTS {temp_table};"))
log(f"Upserted into {target_table}: {len(df)} rows")
This is the best practice when your data can be updated later.
✅ Step 5: Update ETL Metadata (save last-run timestamp)
This is how incremental ETL works reliably.
Create a simple metadata table (one time)
CREATE TABLE IF NOT EXISTS etl_metadata (
job_name TEXT PRIMARY KEY,
last_run TIMESTAMP NOT NULL
);
Read last run
def get_last_run(job_name: str) -> str:
q = sa.text("SELECT last_run FROM etl_metadata WHERE job_name = :job")
with engine.connect() as conn:
row = conn.execute(q, {"job": job_name}).fetchone()
return row[0].isoformat() if row else "1970-01-01T00:00:00"
Save last run
def set_last_run(job_name: str, last_run_ts: str):
q = sa.text("""
INSERT INTO etl_metadata (job_name, last_run)
VALUES (:job, :ts)
ON CONFLICT (job_name) DO UPDATE SET last_run = EXCLUDED.last_run
""")
with engine.begin() as conn:
conn.execute(q, {"job": job_name, "ts": last_run_ts})
log(f"Updated metadata: {job_name} last_run={last_run_ts}")
✅ Full ETL Pipeline Runner (End-to-End)
def run_etl_orders():
job_name = "orders_etl"
last_run = get_last_run(job_name)
log(f"Starting ETL. last_run={last_run}")
# Extract
raw_df = extract_orders_incremental(last_run)
# Stage
if not raw_df.empty:
stage_raw(raw_df)
# Transform
clean_df = transform_orders(raw_df)
# Load (upsert)
load_upsert_postgres(clean_df)
# Update last run safely (use max updated_at)
if not raw_df.empty:
new_last_run = raw_df["updated_at"].max().isoformat()
set_last_run(job_name, new_last_run)
log("ETL completed successfully.")
Tools commonly used around this code
Orchestration (runs ETL on schedule)
Airflow / Prefect / Dagster
Data validation
Great Expectations / dbt tests
Logging & monitoring
ELK / Datadog / CloudWatch
Storage targets
Data Warehouse (Snowflake/BigQuery/Redshift)
Data Lake (S3/ADLS/GCS)
Objective MCQs on Detailed ETL Architecture Components,
In ETL architecture, the staging layer is mainly used for:
A) Final reporting
B) Temporary storage of extracted raw data
C) Machine learning training
D) UI rendering
✅ Answer: B
Staging temporarily stores raw data before transformation.
2️⃣ The transformation engine in ETL is responsible for:
A) Extracting data from APIs
B) Cleaning and applying business rules
C) Displaying dashboards
D) Encrypting passwords
✅ Answer: B
Transformation applies cleansing, enrichment, and business logic.
3️⃣ Which component ensures ETL jobs run in correct order and schedule?
A) Database engine
B) Orchestration layer
C) Front-end layer
D) Cache system
✅ Answer: B
Orchestration tools (like Airflow) manage scheduling and dependencies.
4️⃣ Metadata repository in ETL architecture stores:
A) Raw customer data
B) Server logs
C) Information about ETL processes and job history
D) Dashboard layouts
✅ Answer: C
Metadata tracks job status, schemas, and last-run timestamps.
5️⃣** Which component handles failure alerts and job monitoring**?
A) Presentation layer
B) Monitoring and logging system
C) Data warehouse
D) Transformation engine
✅ Answer: B
Monitoring tracks ETL execution and sends alerts.
6️⃣ In ETL architecture, Change Data Capture (CDC) belongs to:
A) Serving layer
B) Extraction component
C) Dashboard layer
D) Data visualization
✅ Answer: B
CDC detects incremental changes during extraction.
7️⃣** Which ETL component improves reliability by separating extraction from transformation**?
A) Target storage
B) Staging layer
C) Serving layer
D) Cache system
✅ Answer: B
Staging isolates raw data before processing.
8️⃣ The target layer in ETL architecture typically contains:
A) Source application code
B) Cleaned and transformed data
C) Raw unprocessed logs
D) API gateway
✅ Answer: B
Target storage contains structured, analytics-ready data.
9️⃣ Which of the following is NOT a core ETL architecture component?
A) Source system
B) Staging area
C) Orchestration engine
D) CSS stylesheet
✅ Answer: D
CSS is unrelated to ETL architecture.
🔟** Which architectural principle ensures ETL pipelines are fault-tolerant**?
A) Hardcoding values
B) Transaction management and retry logic
C) Deleting logs
D) Manual execution
✅ Answer: B
Transactions and retry mechanisms prevent partial data loads.
10 Advanced Scenario-Based ETL Coding MCQs
- Your ETL job is loading duplicate records into the warehouse. What is the best solution?
A) Use GROUP BY
B) Add DISTINCT in SELECT
C) Implement UPSERT with primary key
D) Delete table daily
✅ Answer: C
UPSERT prevents duplicate primary keys during load.
- ETL job takes too long when loading 10M records. What should you optimize first?
A) Increase CPU blindly
B) Use bulk insert instead of row-by-row insert
C) Rewrite dashboard
D) Reduce memory
✅ Answer: B
Bulk loading significantly improves performance.
- Incremental ETL is missing some updated records. What is likely the issue?
A) Wrong database engine
B) Incorrect timestamp comparison logic
C) Python version
D) CSV format
✅ Answer: B
Incremental ETL depends heavily on correct updated_at logic.
- Data type mismatch error occurs during load. Best fix?
A) Drop the table
B) Convert datatype during transformation
C) Skip the column
D) Ignore error
✅ Answer: B
- ETL fails midway and leaves partial data loaded. What is best practice?
A) Ignore failure
B) Use database transactions
C) Restart system
D) Increase RAM
✅ Answer: B
- You need near real-time ETL instead of batch. What should you use?
A) Cron job
B) Kafka or streaming engine
C) Excel
D) FTP
✅ Answer: B
- Transformation logic is repeated across multiple pipelines. Best solution?
A) Copy-paste
B) Create reusable transformation functions
C) Hardcode
D) Disable validation
✅ Answer: B
- Warehouse queries are slow after ETL load. What should you implement?
A) Indexing & partitioning
B) Delete records
C) Reduce columns
D) Restart server
✅ Answer: A
- ETL job must handle schema change automatically. What approach helps?
A) Schema-on-read
B) Hardcoded column list
C) Manual updates
D) Disable checks
✅ Answer: A
- ETL pipeline fails silently without alerts. What should be added?
A) More prints
B) Logging + monitoring system
C) Sleep()
D) Random retry
✅ Answer: B
Basic Coding Example of ETL Layer
In a Python ETL script, which library is commonly used for data manipulation?
A) NumPy
B) Pandas
C) Matplotlib
D) Flask
✅ Answer: B
Pandas is widely used for data extraction and transformation in ETL.
2️⃣ Which function is commonly used in Pandas to read a CSV file during the Extract step?
A) read_file()
B) load_csv()
C) read_csv()
D) open_csv()
✅ Answer: C
pd.read_csv() is used to extract data from CSV files.
3️⃣ During transformation, removing duplicate rows in Pandas is done using:
A) remove_duplicates()
B) delete_duplicates()
C) drop_duplicates()
D) unique_rows()
✅ Answer: C
drop_duplicates() removes duplicate records.
4️⃣ Converting a column to datetime format in Pandas is done using:
A) to_time()
B) convert_datetime()
C) pd.to_datetime()
D) parse_time()
✅ Answer: C
pd.to_datetime() converts string to datetime format.
5️⃣ In SQL-based ETL, which statement is commonly used to insert transformed data into a warehouse table?
A) UPDATE
B) INSERT INTO
C) DELETE
D) SELECT ONLY
✅ Answer: B
INSERT INTO loads transformed data into the target table.
6️⃣ What is the purpose of an UPSERT operation in ETL coding?
A) Delete existing data
B) Insert only new data
C) Insert new and update existing records
D) Copy full database
✅ Answer: C
UPSERT handles both insert and update operations efficiently.
7️⃣ In incremental ETL coding, data is extracted based on:
A) File size
B) Updated timestamp
C) Random selection
D) Column count
✅ Answer: B
Incremental ETL extracts records where updated_at > last_run.
8️⃣ Which SQL clause is used to group and aggregate data during transformation?
A) ORDER BY
B) GROUP BY
C) WHERE
D) LIMIT
✅ Answer: B
GROUP BY is used for aggregations like SUM, COUNT.
9️⃣ In ETL code, a staging table is mainly used to:
A) Store final reports
B) Store raw extracted data temporarily
C) Store ML models
D) Replace warehouse
✅ Answer: B
Staging tables hold raw data before transformation.
🔟 Which Python function loads a DataFrame into a database table?
A) df.insert()
B) df.to_sql()
C) df.write_table()
D) df.push_db()
✅ Answer: B
to_sql() loads transformed data into the database.
What is ETL? (Deep Explanation)
ETL stands for:
A) Extract, Test, Load
B) Extract, Transform, Load
C) Evaluate, Transform, Load
D) Execute, Transfer, Loop
✅ Answer: B — ETL means Extract, Transform, Load from multiple sources into a target storage for analysis.
ETL is primarily used for:
A) Database backups
B) Data integration and analytics
C) Front-end UI development
D) Machine configuration
✅ Answer: B — ETL integrates data for BI and analytics.
The main purpose of ETL is to:
A) Delete old data
B) Convert raw data to meaningful insights
C) Increase hardware performance
D) Test software modules
✅ Answer: B — ETL transforms raw data into consistent format and analytic-ready data.
📥
Step 1: Extract (Data Collection Phase)
The extract step is responsible for:
A) Loading data into warehouse
B) Removing duplicates
C) Reading raw data from sources
D) Creating dashboards
✅ Answer: C — Extract reads data from systems like DBs, files, APIs.
Which is a common source in the Extract phase?
A) BI reports
B) Transactional databases
C) Data warehouse
D) Front-end apps
✅ Answer: B — ETL extracts from transactional or operational systems.
Incremental extract means:
A) Extract only changed data since last run
B) Extract all data every time
C) Extract only from specific columns
D) Extract only large files
✅ Answer: A — Incremental helps efficiency and performance.
🛠
Step 2: Transform (Data Cleaning & Processing Phase)
Transform phase typically includes:
A) Storing raw data
B) Data cleaning and formatting
C) Writing dashboards
D) Exporting API docs
✅ Answer: B — Transform includes cleansing, normalization.
Which of the following is NOT a transformation action?
A) Aggregation
B) Data filtering
C) Data deletion from source
D) Standardization
✅ Answer: C — ETL shouldn’t delete source data.
Transform operations often involve:
A) Data enrichment
B) Pie chart design
C) User authentication
D) Memory allocation
✅ Answer: A — Enrichment and cleansing are common transforms.
📦
Step 3: Load (Storage Phase)
The Load step in ETL:
A) Reads raw data
B) Loads transformed data to target
C) Deletes staging data
D) Trains ML models
✅ Answer: B — Load writes data to warehouse or lake.
Loading can be done as:
A) Manual process only
B) Full or incremental load
C) Only for files
D) Only once
✅ Answer: B — Both full and incremental loads are used.
After Load, data is typically used for:
A) BI & analytics
B) Removing duplicates
C) Source data deletion
D) UI design
✅ Answer: A — Loaded data drives business intelligence.
🏗
ETL Architecture (How It Is Structured)
Which layer in ETL architecture temporarily holds raw data?
A) Target storage
B) Staging area
C) Presentation layer
D) User interface
✅ Answer: B — Staging holds data before transformation.
ETL architecture is designed to:
A) Improve code readability
B) Move and convert raw data to final storage
C) Increase CPU speed
D) Run front-end apps
✅ Answer: B — Architecture enables efficient movement and transformation.
In the ETL architectural flow, staging is usually placed:
A) After loading
B) Before transformation
C) After consuming results
D) Inside dashboards
✅ Answer: B — Staging sits between extract and transform.
🔧
Detailed ETL Architecture Components
ETL orchestration and scheduling is managed by:
A) ETL tools only
B) Workflow engines like Airflow/Prefect
C) Excel
D) Reports
✅ Answer: B — Workflow tools manage ETL tasks (schedule & dependencies).
Staging layers primarily help with:
A) UI design
B) Temporary raw data storage
C) API documentation
D) Data backup only
✅ Answer: B — Staging is used to validate & hold raw data.
🧰
ETL Tools (Layer-wise)
Which of the following is an ETL tool?
A) Talend
B) Photoshop
C) Figma
D) After Effects
✅ Answer: A — Talend is a widely used ETL tool.
Cloud ETL services include:
A) AWS Glue
B) Azure Data Factory
C) Google Cloud Dataflow
D) All of the above
✅ Answer: D — All are cloud ETL/ELT services.
📊
Where ETL Fits in Enterprise Data Flow Architecture
ETL’s primary role in enterprise architecture is in the:
A) Serving layer
B) Ingestion layer
C) Presentation layer
D) UI design
✅ Answer: B — ETL is core to ingestion and staging.
🧩 Standard ETL Architecture (Layer-by-Layer)
Which layer comes immediately after Extraction?
A) Load
B) Transform
C) Staging
D) Serving
✅ Answer: C — Staging sits between extraction and transformation.
ELT differs from ETL mainly in:
A) Data visualization
B) Order of transformation and loading
C) Source system types
D) User authentication
✅ Answer: B — ELT loads first then transforms.
💻
Coding Example of ETL Layer (Conceptual)
Python/Pandas is commonly used for:
A) Business reporting
B) ETL scripting
C) UI design
D) Web hosting
✅ Answer: B — Python/Pandas is popular in ETL coding.
SQL skills are most useful in ETL for:
A) Extract & Transform tasks
B) Image formatting
C) Text layout design
D) File compression
✅ Answer: A — SQL commonly extracts and transforms data.
In code-based ETL, data cleansing means:
A) Encrypting data
B) Removing inconsistencies and errors
C) Deleting old files
D) Generating UX templates
✅ Answer: B — Cleansing fixes invalid or inconsistent data

Top comments (0)