A Convolutional Neural Network (CNN, or ConvNet) are a special kind of multi-layer neural networks, designed to recognize visual patterns directly from pixel images with minimal preprocessing.. The ImageNet project is a large visual database designed for use in visual object recognition software research
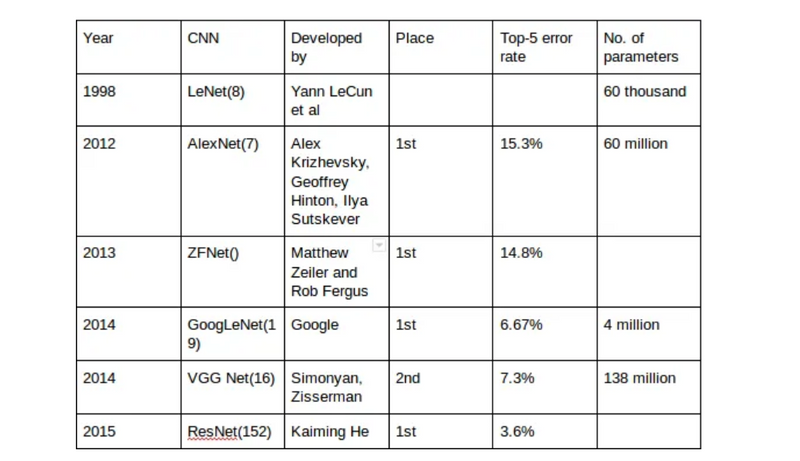
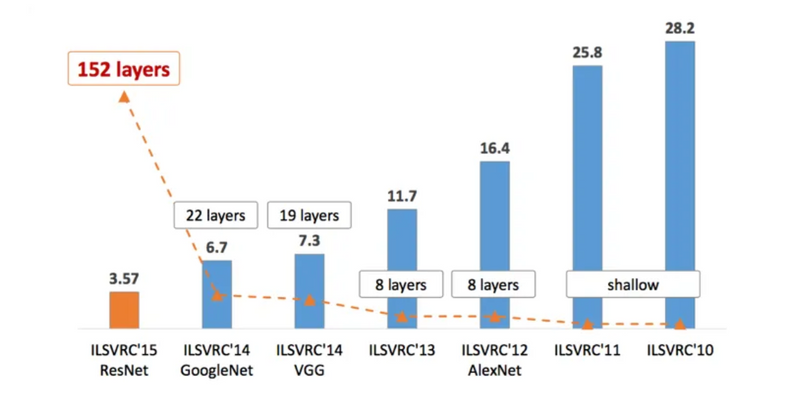
The ImageNet CNN architecture, often referred to in the context of deep learning models like AlexNet, VGGNet, GoogLeNet, and ResNet, gained prominence due to its success in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC). The ImageNet dataset is a large-scale image classification dataset that contains millions of labeled images across thousands of categories. The challenge is to train models to accurately classify these images into their respective classes.
Here are several reasons why the ImageNet CNN architecture, as demonstrated by models like AlexNet, is significant:
Complexity of Image Data:
ImageNet is a diverse dataset with a wide range of object categories and variations in scale, pose, lighting, and background. Traditional computer vision approaches struggled with the complexity of this dataset. CNNs, with their ability to automatically learn hierarchical features, proved effective in capturing complex patterns and representations from image data.
End-to-End Learning:
CNNs enable end-to-end learning, meaning that the model learns hierarchical representations directly from raw input data (images in this case). This eliminates the need for hand-crafted feature engineering, which was common in traditional computer vision systems. The model learns to extract relevant features during the training process.
Transfer Learning:
The success of ImageNet CNNs paved the way for transfer learning. Pre-trained models on ImageNet can be used as a starting point for various computer vision tasks, even if the specific target task has a different dataset. The lower layers of the network, which capture basic features, can be reused and fine-tuned for a new task, saving computational resources and time.
Improved Generalization:
ImageNet CNN architectures demonstrated improved generalization to new and unseen data. The hierarchical feature learning enables the models to capture both low-level and high-level features, making them robust to variations and complexities present in real-world images.
Benchmark for Comparison:
The ILSVRC provided a standardized benchmark for evaluating the performance of different models. The competition spurred innovation in the design of deep learning architectures, leading to the development of increasingly sophisticated models.
Real-World Applications:
The success of ImageNet CNNs in image classification tasks has extended to various real-world applications. These applications include object detection, image segmentation, facial recognition, medical image analysis, and more.
Example:
Consider the task of classifying an image containing various objects, such as a cat, a dog, and a car, into their respective categories. The ImageNet CNN architecture, like AlexNet, can automatically learn features such as edges, textures, and object parts in the lower layers. As you move up in the network, the features become more complex and abstract, eventually leading to the activation of neurons that represent high-level object categories like "cat," "dog," and "car." This hierarchical feature learning allows the model to make accurate predictions on diverse and complex images.
Why image is randomly cropped in CNN architecture
Randomly cropping images is a data augmentation technique commonly used in Convolutional Neural Network (CNN) architectures, especially for tasks like image classification. Data augmentation involves applying various transformations to the training images to artificially increase the size of the training dataset. This helps improve the generalization ability of the model by exposing it to a broader range of variations and reducing overfitting. Random cropping is one such technique, and here's why it is used along with examples:
Increased Variability:
Random cropping introduces variability in the training data by extracting random regions from the original images. This forces the model to learn features and patterns in different spatial locations. It helps the model become more robust to translations and changes in object position within the image.
Translation Invariance:
CNNs are designed to be translation invariant, meaning that they should be able to recognize objects regardless of their position in the image. Random cropping helps reinforce this property by presenting the model with images where the target object can appear at different locations.
Mitigating Overfitting:
Augmentation techniques like random cropping act as a form of regularization. They help prevent overfitting by discouraging the model from memorizing specific details of the training images. Instead, the model learns to recognize the essential features that are invariant to changes in position.
Handling Varying Image Sizes:
In real-world scenarios, images may have different aspect ratios or sizes. Random cropping helps the model adapt to these variations during training, improving its ability to handle images of different dimensions.
Example:
Let's consider an image classification task where the goal is to classify images of dogs. Random cropping involves taking random crops of different sizes from the original images during training. For example, if you have a picture of a dog with the dog centered, random cropping might extract parts of the image where the dog is off-center, partially occluded, or at a different scale. This ensures that the model learns to recognize the dog regardless of its position or size in the image.

Top comments (0)