Why we use padding for convolution in CNN ?
Explain the types of padding ?
Why we use padding for convolution in CNN
Padding is used in convolutional neural networks (CNNs) for various reasons, primarily to address issues related to spatial dimensions and border effects. Here are some key reasons why padding is employed in convolutional operations in deep learning, along with examples:
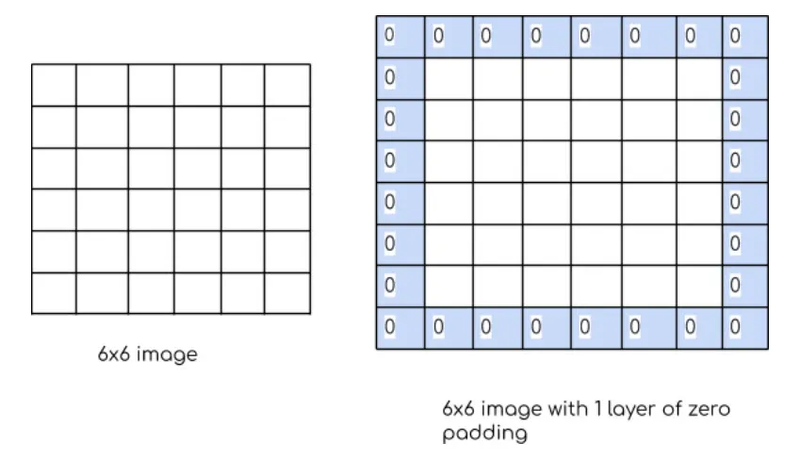
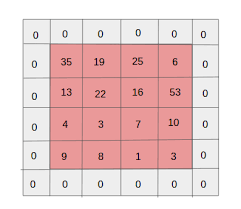
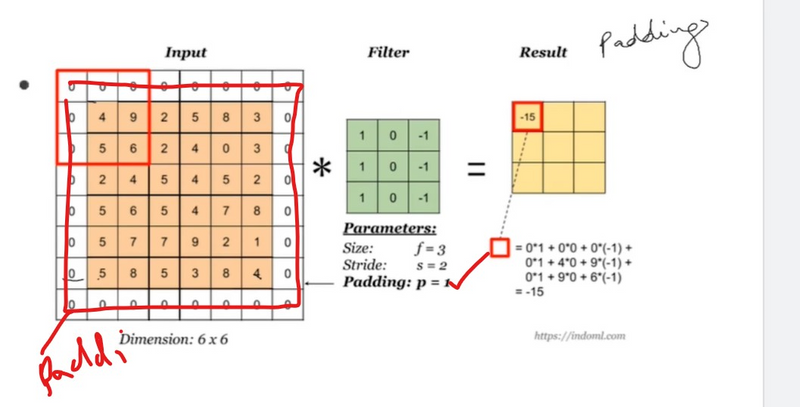
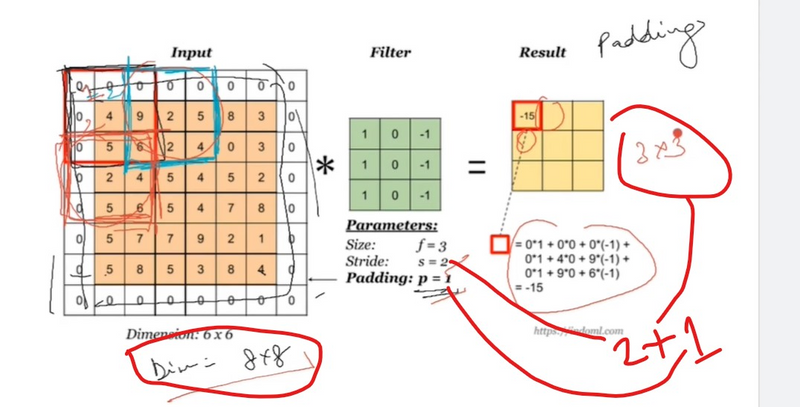
Preserving Spatial Information:
Padding helps preserve the spatial dimensions of the input feature map. Without padding, applying convolutional operations reduces the size of the feature map, potentially leading to a loss of information at the borders.
Example:
model = Sequential()
model.add(Conv2D(64, (3, 3), padding='same', activation='relu', input_shape=(64, 64, 3)))
Avoiding Border Effects:
Convolutional filters are applied by sliding over the input feature map. Without padding, the filter may not cover the edges of the input fully, resulting in border effects. Padding ensures that the filter is applied uniformly across the entire input.
Example:
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
Centering the Kernel:
Padding helps center the convolutional kernel on each element of the input. This is important for maintaining symmetry and consistency in the convolutional operation.
Example:
model = Sequential()
model.add(Conv2D(128, (5, 5), padding='same', activation='relu', input_shape=(128, 128, 3)))
Mitigating Spatial Shrinkage:
Convolutional layers, especially those with a stride greater than 1, can cause spatial shrinkage in the feature map. Padding helps mitigate this issue, allowing the network to learn features at various spatial resolutions.
Example:
model = Sequential()
model.add(Conv2D(64, (3, 3), strides=(2, 2), padding='same', activation='relu', input_shape=(64, 64, 3)))
Compatibility with Different Architectures:
Padding ensures that convolutional layers are compatible with various architectures and configurations. It provides flexibility in designing networks without worrying about the size of the input or the output feature maps.
Example:
model = Sequential()
model.add(Conv2D(256, (3, 3), padding='same', activation='relu', input_shape=(256, 256, 3)))
Enabling Translation Invariance:
Padding contributes to achieving translation invariance, making the network less sensitive to the exact position of features in the input.
Example:
model = Sequential()
model.add(Conv2D(64, (3, 3), padding='same', activation='relu', input_shape=(64, 64, 3)))
In these examples, the padding parameter is set to 'same' to indicate that padding should be used to keep the output feature map dimensions the same as the input. This is a common choice to address the issues mentioned above. However, other padding options, such as 'valid' (no padding) or custom padding values, can be used depending on the specific requirements of the model architecture and the desired behavior of the convolutional layers.
Types of padding for convolution
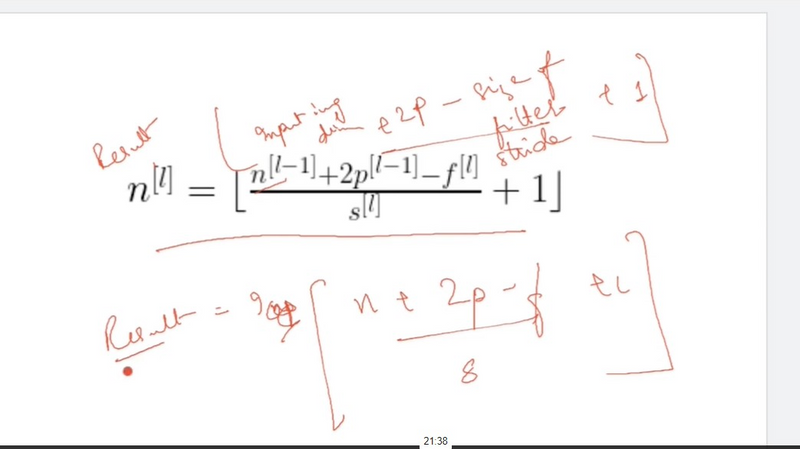
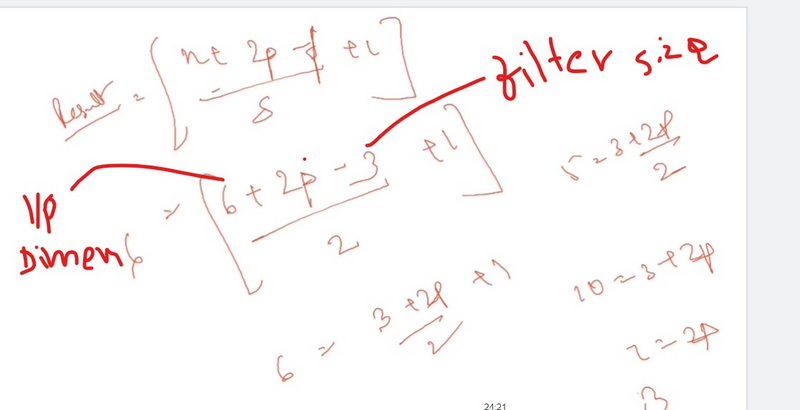
In convolutional neural networks (CNNs), padding is a technique used to preserve spatial information in the input feature maps when applying convolutional operations. There are different types of padding, and each has its implications for the spatial dimensions of the output feature maps. The two main types of padding are:
valid padding---no padding
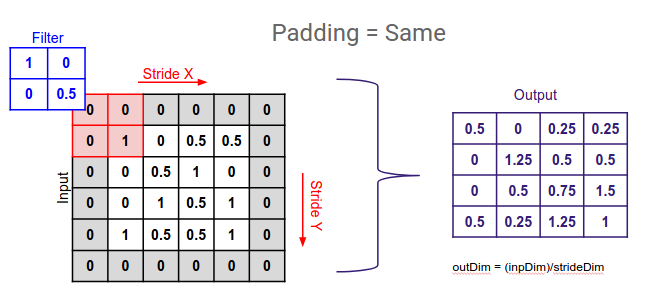
same paddin--padding enable
same padding required when u lost some information
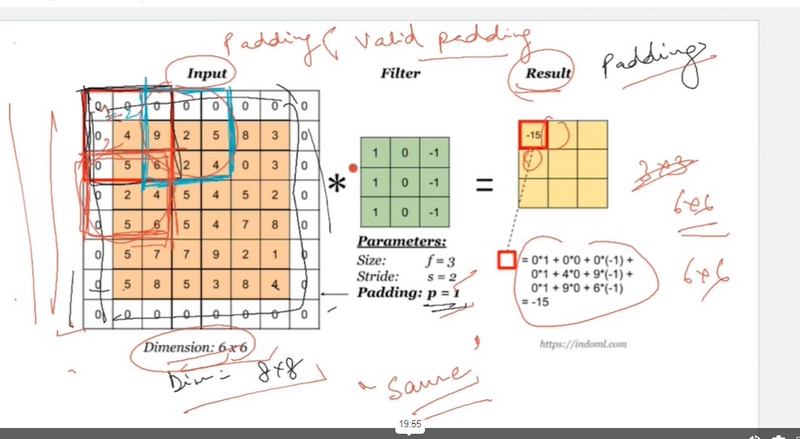
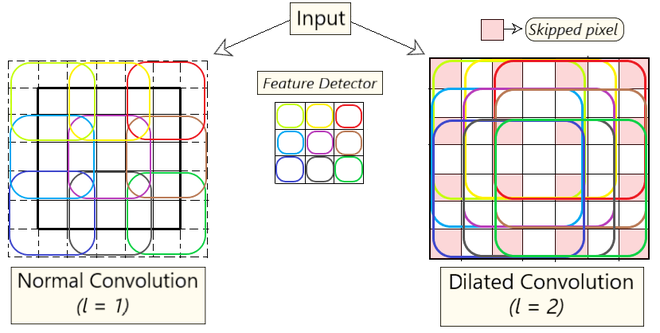
Valid Padding (No Padding):
In valid padding, also known as no padding, the convolutional filter is applied only to the input feature map without adding any extra pixels around it. As a result, the spatial dimensions of the output feature map are reduced.
Example:
model = Sequential()
model.add(Conv2D(64, (3, 3), padding='valid', activation='relu', input_shape=(64, 64, 3)))
Characteristics:
Output spatial dimensions are smaller than the input.
No additional pixels are added around the input feature map.
Commonly used when reducing spatial dimensions is intentional, such as in downsampling layers.
Same Padding:
In same padding, the convolutional filter is applied to the input feature map with additional pixels added to ensure that the output feature map has the same spatial dimensions as the input. The extra pixels are typically filled with zeros.
Example:
model = Sequential()
model.add(Conv2D(64, (3, 3), padding='same', activation='relu', input_shape=(64, 64, 3)))
Characteristics:
Output spatial dimensions are the same as the input.
Extra pixels are added around the input feature map to maintain spatial information.
Commonly used when preserving spatial dimensions is important.
Besides these two main types, there is another less common padding type:
Full Padding (Zero Padding):
In full padding, also known as zero padding, additional pixels are added around the input feature map, but the number of added pixels is such that the spatial dimensions of the output feature map are increased compared to the input.
Example:
model = Sequential()
model.add(Conv2D(64, (3, 3), padding='full', activation='relu', input_shape=(64, 64, 3)))
Characteristics:
- Output spatial dimensions are larger than the input.
- Additional pixels are added around the input feature map to increase spatial dimensions.
- Less common in practice . The choice of padding type depends on the specific requirements of the model architecture and the desired behavior of the convolutional layers. Same padding is often used when preserving spatial dimensions is crucial, especially in tasks where spatial information is important, such as object recognition. Valid padding is commonly used in downsampling layers to reduce spatial dimensions. The choice of padding can impact the overall design and performance of a CNN.

Top comments (0)