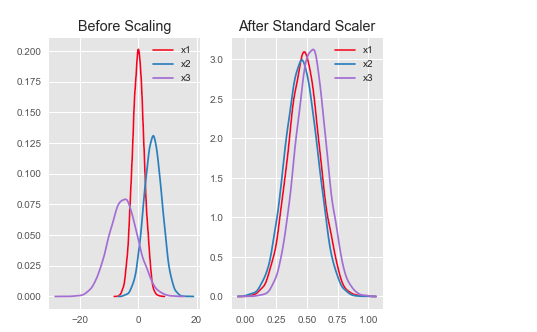
In machine learning, the StandardScaler is a preprocessing technique used to standardize or normalize the features of a dataset. It rescales the features to have zero mean and unit variance, ensuring that the features are on the same scale. This transformation is important for certain algorithms that are sensitive to the scale of the input features.
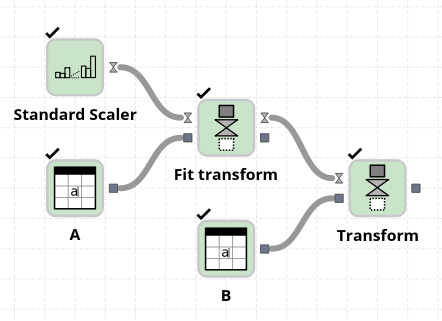
The process of applying the StandardScaler involves two steps: fitting and transforming.
Fitting:
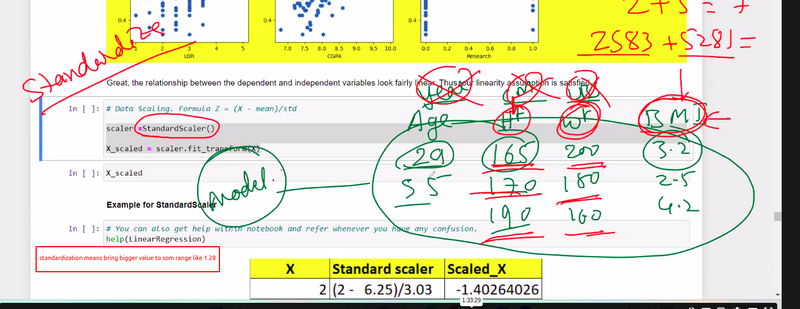
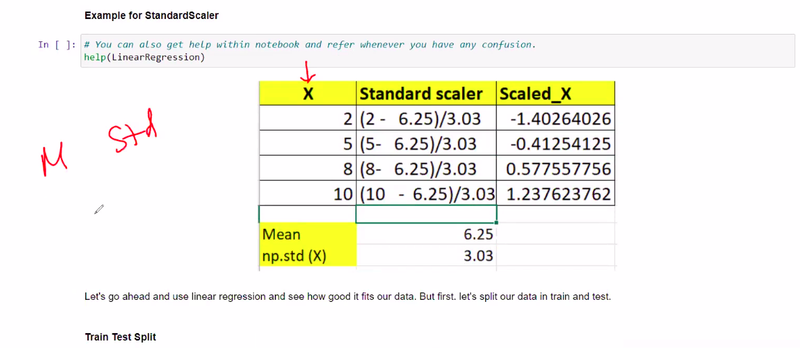
The fitting step involves calculating the mean and standard deviation of each feature in the dataset. These statistics are computed based on the training data and will be used to standardize the features.
Transforming:
The transforming step applies the calculated mean and standard deviation to standardize the features. It subtracts the mean from each feature and divides it by the standard deviation. This rescales the features, resulting in a mean of zero and a standard deviation of one.
The StandardScaler is typically used as follows:
from sklearn.preprocessing import StandardScaler
# Create an instance of the StandardScaler
scaler = StandardScaler()
# Fit the scaler to the training data
scaler.fit(X_train)
# Transform the training and test data using the fitted scaler
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
In the code snippet above, X_train and X_test represent the feature matrices of the training and test data, respectively. First, an instance of the StandardScaler is created. Then, the scaler is fitted to the training data using the fit method, which computes the mean and standard deviation of each feature.
After fitting the scaler, the transform method is used to apply the scaling transformation to both the training and test data. The resulting X_train_scaled and X_test_scaled matrices contain the standardized features.
By standardizing the features, the StandardScaler ensures that each feature contributes equally during the learning process, preventing certain features from dominating others based on their scale. This can improve the performance and convergence of many machine learning algorithms.
It's important to note that the StandardScaler should be fitted only on the training data and then applied to the test data. This ensures that the scaling is consistent and avoids introducing information from the test set into the training process.
Using the StandardScaler is particularly beneficial for algorithms that are sensitive to the scale of the input features, such as logistic regression, support vector machines, and k-nearest neighbors. It is also commonly used in dimensionality reduction techniques like principal component analysis (PCA), where standardizing features helps capture the most significant sources of variation.
Questions
standard scalar is kind of technique
it is used to ----------
standard scalar rescales -------for------------ and ensures-------
why we use fitting and transforming

Top comments (0)