In deep learning, the stride is a parameter used in convolutional layers to control the step size of the convolutional filter as it slides or moves across the input data. The stride determines how much the filter shifts or moves between successive applications during the convolution operation. The use of stride offers several advantages and impacts the spatial dimensions of the output feature maps. Here's why strides are used in convolution in deep learning:
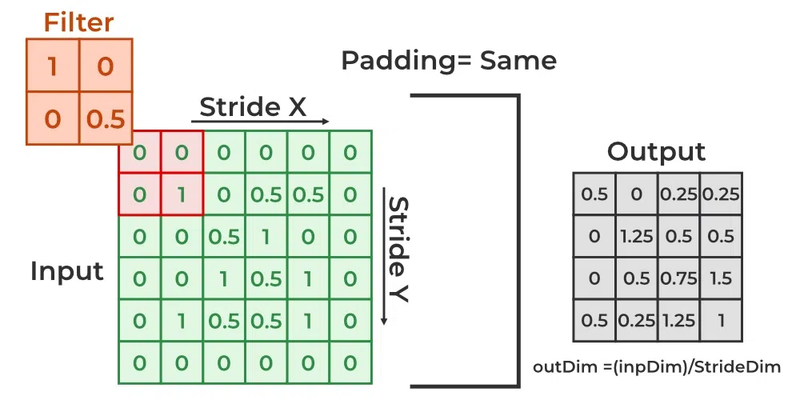
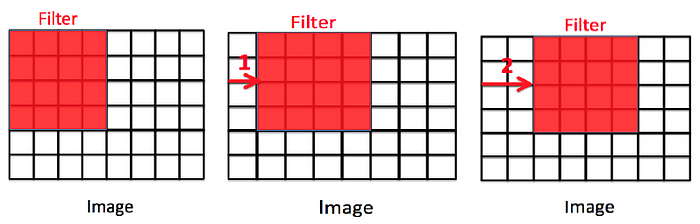
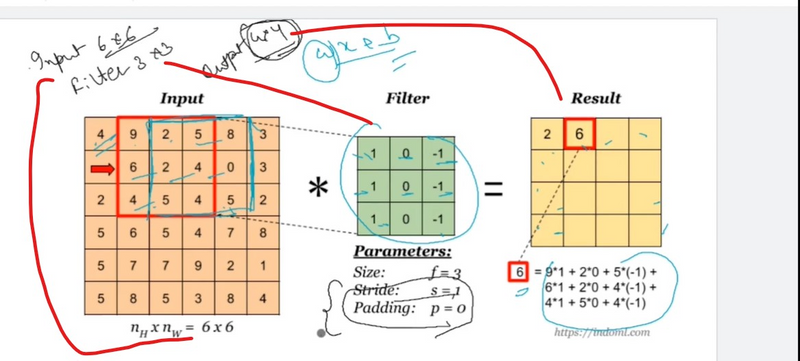
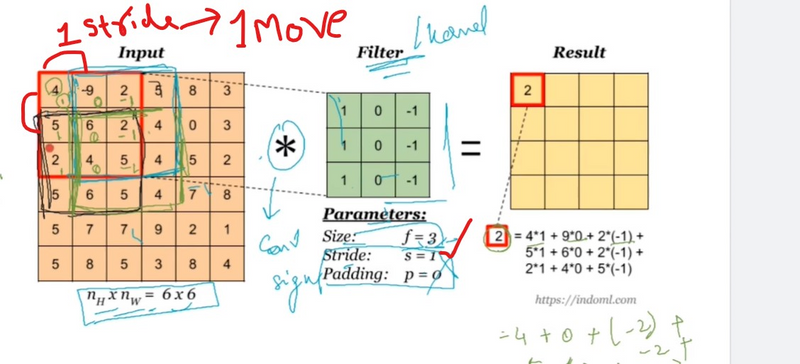
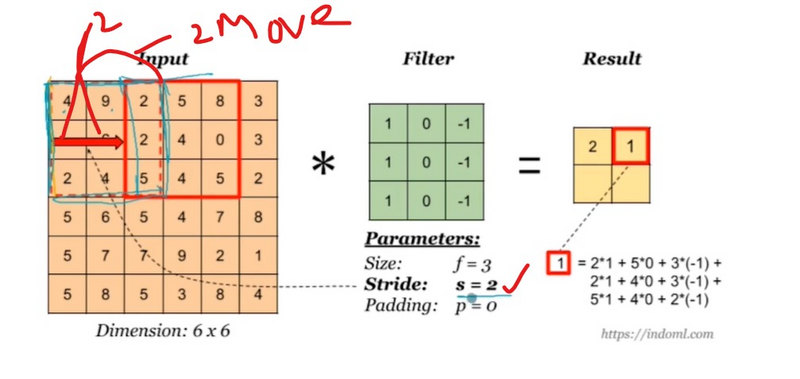
Downsampling and Spatial Reduction:
Stride greater than 1 results in downsampling or spatial reduction of the feature map. It reduces the spatial dimensions of the output feature map compared to the input. This downsampling is often used to reduce computational complexity and memory requirements, especially in deeper layers of the network.
Example:
model = Sequential()
model.add(Conv2D(64, (3, 3), strides=(2, 2), padding='same', activation='relu', input_shape=(64, 64, 3)))
Increased Receptive Field:
Larger strides increase the receptive field of the convolutional filter. A larger receptive field allows the filter to capture information from a larger region of the input, potentially capturing more complex patterns and relationships.
Example:
model = Sequential()
model.add(Conv2D(64, (3, 3), strides=(2, 2), padding='same', activation='relu', input_shape=(64, 64, 3)))
Computational Efficiency:
Using strides reduces the number of operations performed during the convolution, making the computation more efficient. This is particularly important in large-scale neural networks where computational resources are a concern.
Example:
model = Sequential()
model.add(Conv2D(64, (3, 3), strides=(2, 2), padding='same', activation='relu', input_shape=(64, 64, 3)))
Feature Reduction:
Strides can be used to reduce the spatial dimensions of the feature map when transitioning from one layer to another. This reduction can be intentional, emphasizing important features while discarding less relevant spatial information.
Example:
model = Sequential()
model.add(Conv2D(64, (3, 3), strides=(2, 2), padding='same', activation='relu', input_shape=(64, 64, 3)))
Translation Invariance:
Larger strides can contribute to achieving translation invariance, making the network less sensitive to the exact position of features in the input. This can be beneficial in tasks where the precise location of features is not critical.
Example:
model = Sequential()
model.add(Conv2D(64, (3, 3), strides=(2, 2), padding='same', activation='relu', input_shape=(64, 64, 3)))

Top comments (0)