Difference betweeen word embedding and OHE
real time application of feature of word embedding and word2vec with example
Different methods of wordembeding
How Word embedding using keras embedding layer
Word embedding and One-Hot Encoding (OHE) are both techniques used to represent words in a format that can be understood by machine learning algorithms, particularly in natural language processing (NLP). However, they serve different purposes and have distinct advantages and disadvantages. Here's a breakdown of why we use word embeddings even when we have One-Hot Encoding for sequential layers.
One-Hot Encoding (OHE)
What is One-Hot Encoding?
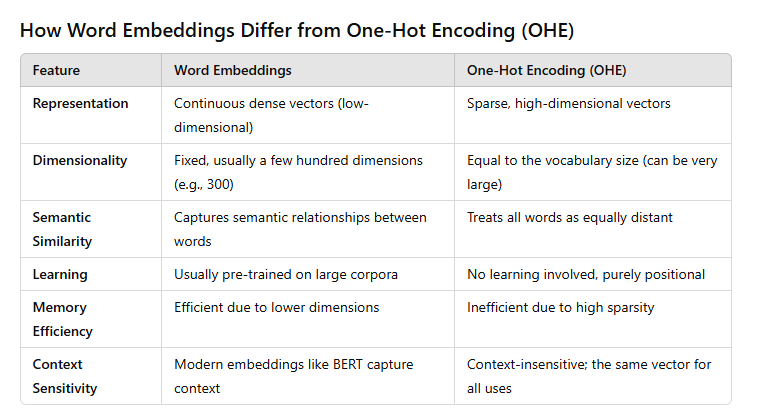
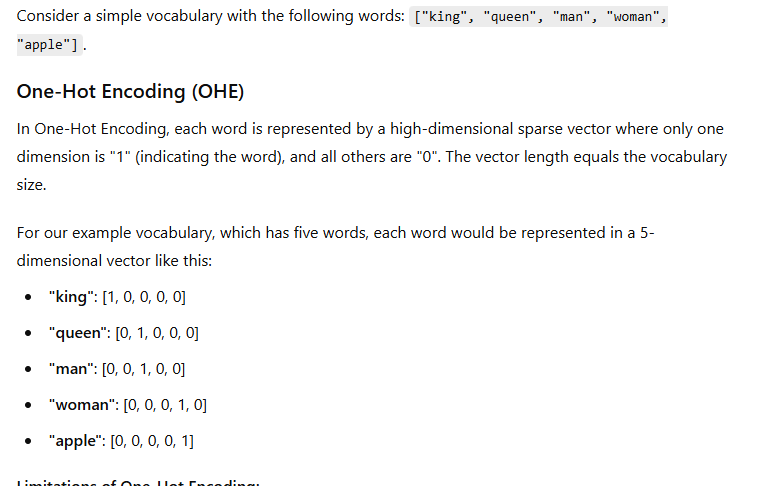
Definition: One-Hot Encoding is a technique where each word in the vocabulary is represented as a binary vector. The length of the vector is equal to the size of the vocabulary, and for each word, only the index corresponding to that word is set to 1, while all other indices are set to 0.

Limitations of One-Hot Encoding
High Dimensionality: If the vocabulary is large, the resulting vectors become very high-dimensional, leading to inefficiency and increased computational costs.
Sparsity: OHE vectors are sparse (most values are 0), which can lead to wasted memory and less efficient computation.
No Semantic Information: OHE does not capture any semantic relationships between words. For example, "king" and "queen" would be equally distant from each other as "king" and "apple," which is not reflective of their meanings.
Word Embedding
What are Word Embeddings?
Definition: Word embeddings are dense vector representations of words that capture semantic relationships and meaning. Each word is represented as a continuous-valued vector in a lower-dimensional space compared to One-Hot Encoding.
Example
Using word embeddings, the words "king" and "queen" might have vectors that are close together in the vector space, reflecting their semantic similarity:

Advantages of Word Embeddings
Lower Dimensionality: Word embeddings typically have a much lower dimensionality (e.g., 100-300 dimensions) compared to the high dimensionality of OHE, making them more efficient for computation and storage.
Dense Representations: Word embeddings are dense vectors, which helps reduce the sparsity of the representation and improves the efficiency of the model.
Semantic Relationships: Word embeddings capture semantic meanings and relationships between words. For example, in a well-trained embedding space, the vector for "king" - "man" + "woman" may result in a vector close to "queen".
Generalization: Embeddings allow models to generalize better, as they can understand that words with similar meanings can have similar representations.
Why Use Word Embeddings for Sequential Models?
Efficiency: In sequential models like RNNs or LSTMs, word embeddings reduce the input dimensionality, leading to faster training and inference times.
Rich Information: Word embeddings provide rich information about word meanings and relationships, which can enhance the model's performance in tasks such as sentiment analysis, machine translation, and more.
Improved Performance: Many state-of-the-art NLP models rely on embeddings for better performance, as they can effectively capture the context and nuances of language.
Word embeddings and One-Hot Encoding (OHE) are two methods used to represent words as vectors in natural language processing, but they differ significantly in how they capture relationships and information about words.
Why We Use Word Embeddings
Word embeddings are a type of word representation that map words into continuous vector spaces. Key reasons for using word embeddings include:
Capturing Semantic Relationships: Word embeddings are designed to capture the meanings and relationships between words. For example, words like "king" and "queen" or "apple" and "orange" tend to be closer to each other in embedding space, capturing their semantic similarity.
Reducing Dimensionality: Word embeddings significantly reduce the dimensionality of word representation compared to OHE, as each word is represented by a fixed-length, dense vector (e.g., 300 dimensions) rather than a very high-dimensional sparse vector.
Improving Generalization: Since word embeddings capture semantic information, models using them can generalize better to new contexts and understand relationships between words that were not explicitly in the training data.
Contextual Representation: Modern embeddings (e.g., word2vec, GloVe, or contextual embeddings like BERT) take into account word context, which helps with words that have multiple meanings (e.g., "bank" as in a river vs. "bank" as in finance).






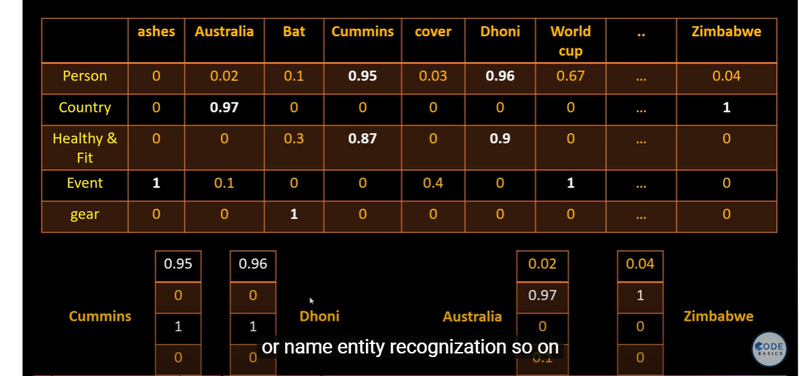


vectors for dhoni and cummins quite similar but austraia is different

Different Method of Word Embedding
Word embeddings are techniques used to transform words into numerical vectors in a way that captures semantic information and contextual relationships. Here are some commonly used methods for generating word embeddings, with explanations on when, how, and why each is used.
Word2Vec
Description: Word2Vec is one of the earliest and most popular word embedding techniques, developed by Google. It comes in two architectures: CBOW (Continuous Bag of Words), which predicts the target word given its context, and Skip-gram, which predicts the context given a target word.
When to Use: When you want to capture semantic similarities between words in a continuous vector space. Works well with large datasets.
How to Use: Typically trained on a large corpus, generating embeddings where similar words have closer vector representations.
Why to Use: Efficient for representing words in low dimensions (e.g., 100–300) and preserves linear relationships (e.g., vector('King') - vector('Man') + vector('Woman') ≈ vector('Queen')).GloVe (Global Vectors for Word Representation)
Description: Developed by Stanford, GloVe creates embeddings based on a word co-occurrence matrix, leveraging global statistical information across the corpus.
When to Use: Effective when using very large datasets, especially when pre-trained embeddings are suitable, as they perform well in transfer learning.
How to Use: GloVe embeddings can be generated from a corpus by calculating the co-occurrence matrix, followed by matrix factorization.
Why to Use: GloVe combines the strengths of local context (like Word2Vec) and global corpus statistics, providing robust embeddings and generally good transferability to various NLP tasks.FastText
Description: Developed by Facebook, FastText builds on Word2Vec by breaking words into subwords (character n-grams), allowing embeddings to capture morphology (i.e., word structure).
When to Use: Particularly useful for languages with complex morphology or in settings where you need to handle out-of-vocabulary (OOV) words better.
How to Use: Trained similarly to Word2Vec but on subword information, allowing it to generalize better to unseen words.
Why to Use: FastText is helpful for morphologically rich languages and can create meaningful embeddings even for rare or misspelled words, as it considers subword information.ELMo (Embeddings from Language Models)
Description: Developed by AllenNLP, ELMo produces contextualized embeddings, meaning the representation of a word is dependent on the sentence it appears in. ELMo uses a deep bi-directional LSTM (Long Short-Term Memory network).
When to Use: Best for tasks that require an understanding of context, such as question-answering, named entity recognition (NER), or sentiment analysis.
How to Use: ELMo embeddings can be pre-trained on large corpora and then fine-tuned or used in downstream tasks as contextual word representations.
Why to Use: ELMo captures polysemy (multiple meanings of words) by dynamically changing embeddings based on context, making it more powerful for complex language understanding tasks.BERT (Bidirectional Encoder Representations from Transformers)
Description: Developed by Google, BERT is a transformer-based model that generates embeddings by pre-training on large text corpora using masked language modeling and next-sentence prediction tasks.
When to Use: Best for NLP tasks requiring contextual embeddings and understanding of complex sentence structure, such as sentence classification, machine translation, and paraphrase detection.
How to Use: BERT models are pre-trained on large corpora and then fine-tuned for specific tasks. It can be used via popular NLP libraries like Hugging Face's Transformers.
Why to Use: BERT’s bidirectional training captures context from both left and right, generating state-of-the-art embeddings for a wide variety of tasks.GPT (Generative Pre-trained Transformer)
Description: Developed by OpenAI, GPT is a transformer model primarily used for text generation tasks. Its embeddings capture rich language patterns and can be fine-tuned for various downstream applications.
When to Use: Effective for applications focused on text generation, completion, or conversation-based models. Also useful for sentiment analysis, summarization, and translation.
How to Use: Like BERT, GPT can be pre-trained on large datasets and fine-tuned for specific tasks.
Why to Use: GPT’s architecture is unidirectional but highly effective for tasks where generating text is the focus, given its ability to predict future words in a sequence based on context.Transformer-based Models like RoBERTa, ALBERT, and T5
Description: Variations and improvements on the BERT model, these transformers introduce innovations for optimized training, faster performance, and contextualized embedding accuracy. For example, RoBERTa is a more robustly optimized BERT, while T5 (Text-To-Text Transfer Transformer) is versatile for tasks where input-output formats vary (e.g., summarization, translation).
When to Use: Use for fine-tuning on specific tasks, as each of these models might offer unique benefits based on the complexity or requirement of the task.
How to Use: These models are available in pre-trained forms and can be fine-tuned for specific downstream tasks using NLP libraries.
Why to Use: Transformer-based models outperform most traditional embeddings for NLP tasks, as they are highly accurate and flexible due to their ability to learn nuanced language patterns.

Real time application of feature of word embedding and word2vec
Here are 20 real-time applications of word embeddings, with examples demonstrating their functionality across different fields:
- Search Engine Query Expansion Example: When a user searches for "buy mobile," embeddings help retrieve results that also include "purchase smartphone" or "get cellphone" by recognizing similar terms.
- Recommendation Systems Example: E-commerce sites use embeddings to recommend products. If a user views "laptop," related products like "mouse" or "laptop stand" might appear based on co-occurrence in past purchases.
- Document Similarity and Clustering Example: News aggregation platforms cluster articles by similarity. Articles about "NBA" and "basketball playoffs" are grouped together, recognizing related topics without explicit keywords.
- Sentiment Analysis Example: Word embeddings help identify sentiment by understanding related words. "Amazing" and "excellent" might be treated as positive, while "bad" or "disappointing" as negative.
- Chatbot Intent Recognition Example: A customer service bot uses embeddings to recognize requests, such as "Where’s my order?" as similar to "Track my package," allowing efficient handling.
- Named Entity Recognition (NER) Example: NER models use embeddings to identify entities in text, like "Apple" as a company or "Paris" as a location, based on context in customer support or news articles.
- Question-Answering Systems Example: A Q&A system leverages embeddings to match user questions with answers, such as recognizing "What is AI?" as similar to "Explain artificial intelligence."
- Plagiarism Detection Example: Academic tools detect paraphrased content by identifying semantically similar phrases or sentences, even when exact words differ, like "climate change" and "global warming."
- Translation and Multilingual Search Example: A translation app uses embeddings to map similar meanings across languages. Searching "cat" in English can retrieve "gato" in Spanish by mapping to the same vector space.
- Smart Document Tagging and Classification Example: Embeddings are used to tag and classify documents. For a legal document, phrases like "contract termination" are tagged as "legal" and "agreement" topics.
- Text Summarization Example: Summarization tools capture the main points of an article, understanding key words and sentences by embedding similarities, to produce concise summaries.
- Personalized News Feed Example: News platforms use embeddings to recommend articles based on reading history, suggesting topics semantically similar to past interests, like "technology" or "climate policy."
- Speech-to-Text Improvement Example: Speech recognition systems leverage embeddings to refine transcriptions. Recognizing that "AI" and "artificial intelligence" are related helps ensure accuracy in transcription.
- Contextual Spell Checking Example: Embedding-based spell checkers identify likely words based on context. Typing "recieve" near "message" could correct to "receive" due to context-based similarity.
- Code Autocomplete and Intent Matching Example: IDEs use embeddings to suggest contextually relevant code. Typing "for" in Python might suggest code snippets that use lists or ranges based on embeddings of previous code.
- Content Recommendation for Streaming Services Example: Streaming platforms recommend content based on embeddings of movie/TV descriptions, suggesting “sci-fi thriller” movies if a user previously watched similar genres.
- Financial Document Analysis Example: Financial institutions use embeddings to analyze reports, grouping similar concepts like "interest rate" and "monetary policy," to inform decision-making.
- Healthcare Text Mining for Diagnosis Example: In clinical notes, embeddings help identify similar symptoms, like "fever" and "high temperature," linking them to diseases for more accurate diagnostics.
- Semantic Content Filtering for Social Media Example: Social platforms use embeddings to detect and filter hate speech by understanding semantic similarity, recognizing patterns even in non-explicit phrases.
- Customer Feedback Analysis Example: E-commerce sites analyze reviews to detect recurring issues, recognizing “late delivery” as related to “delayed shipping,” improving customer service insights.
How Word embedding using keras embedding layer

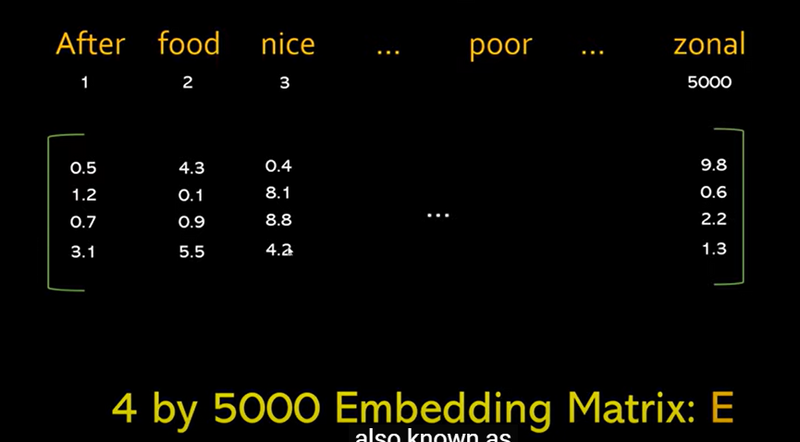
Words and Vocabulary Indexing:

Embedding Matrix E:

Embedding Vector Representation

Embedding Matrix in the Context of Neural Networks:

**Step 1: Define the Vocabulary and Create Word Indices
**First, we need a vocabulary of words and to assign each word an index. In a real-world example, you would have a large vocabulary, but for simplicity, we'll use a small set of words here.
# Define a sample vocabulary
vocabulary = ["After", "food", "nice", "poor", "zonal"]
word_to_index = {word: idx for idx, word in enumerate(vocabulary, start=1)} # Start indexing from 1
# Print word indices
print("Word to index mapping:", word_to_index)
output
Word to index mapping: {'After': 1, 'food': 2, 'nice': 3, 'poor': 4, 'zonal': 5}
Step 2: Initialize the Embedding Layer in Keras
We’ll use Keras’s Embedding layer to create an embedding matrix for these words. Let’s assume an embedding dimension of 4, similar to the image
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding
import numpy as np
# Vocabulary size and embedding dimensions
vocab_size = 6 # Adding 1 for padding (if needed)
embedding_dim = 4 # Number of dimensions for each word vector
# Create the embedding layer
model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=1, name="embedding_layer"))
# Set the model to predict (to initialize the weights)
model.compile('rmsprop', 'mse')
Step 3: Get the Embedding Matrix
The embedding layer in Keras initializes a random embedding matrix, and we can extract this matrix to see the vector representation for each word in our vocabulary.
# Retrieve the embedding matrix
embedding_matrix = model.get_layer("embedding_layer").get_weights()[0]
# Display the embedding matrix
print("Embedding Matrix:")
print(embedding_matrix)
Embedding Matrix:
[[ 0.0024, -0.0154, 0.0352, 0.0233], # Padding (index 0)
[ 0.0055, 0.0234, -0.0483, 0.0112], # "After" (index 1)
[ 0.0103, -0.0225, 0.0362, -0.0315], # "food" (index 2)
[ 0.0245, 0.0094, -0.0182, 0.0413], # "nice" (index 3)
[-0.0018, 0.0043, -0.0065, 0.0342], # "poor" (index 4)
[ 0.0278, -0.0132, 0.0381, -0.0248]] # "zonal" (index 5)
Explanation of the Embedding Matrix

Step 4: Converting Words to Embedding Vectors
To convert a word into its corresponding embedding vector, use the word index to look it up in the embedding matrix.
# Example: Converting words "After" and "nice" to their embedding vectors
word_indices = [word_to_index["After"], word_to_index["nice"]] # Indices for "After" and "nice"
word_vectors = embedding_matrix[word_indices]
# Display the embedding vectors for "After" and "nice"
print("Embedding vector for 'After':", word_vectors[0])
print("Embedding vector for 'nice':", word_vectors[1])
Embedding vector for 'After': [0.0055, 0.0234, -0.0483, 0.0112]
Embedding vector for 'nice': [0.0245, 0.0094, -0.0182, 0.0413]
Summary
Embedding Matrix: This matrix stores dense vector representations for each word in the vocabulary. Each row represents a word's vector, mapping it to a dense space.
Word to Embedding Vector: By indexing into the embedding matrix, we retrieve the vector for any given word, allowing us to use these vectors as input for deep learning models.
Another Coding Example
import numpy as np
from tensorflow.keras.preprocessing.text import one_hot
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Embedding
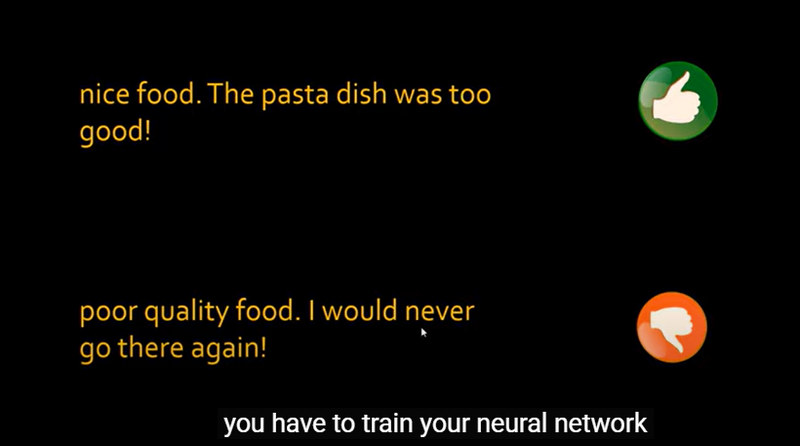
reviews = ['nice food',
'amazing restaurant',
'too good',
'just loved it!',
'will go again',
'horrible food',
'never go there',
'poor service',
'poor quality',
'needs improvement']
sentiment = np.array([1,1,1,1,1,0,0,0,0,0])
one_hot("amazing restaurant",30)
Steps for Using Word Embedding Layers in Keras
Define the Vocabulary and Encode Sentences
First, a list of sample reviews is created, along with a sentiment array indicating the sentiment (positive or negative).
The one_hot function encodes each word into a unique integer ID within a fixed vocabulary size. Here, each review is tokenized and represented as a sequence of word indices.
vocab_size = 30
encoded_reviews = [one_hot(d, vocab_size) for d in reviews]
[[13, 21], [4, 23], [14, 17], ...]
Padding Sequences to Ensure Uniform Length
Since each review has a different length, we use pad_sequences to standardize the length of all sequences. The max_length parameter specifies the length to pad to, and padding is applied at the end (padding='post').
max_length = 4
padded_reviews = pad_sequences(encoded_reviews, maxlen=max_length, padding='post')
Output Example:
[[13, 21, 0, 0], [4, 23, 0, 0], ...]
Define the Embedding Layer in Keras
The Embedding layer in Keras is used to map each word index to a dense vector of fixed size (embeded_vector_size). This layer transforms each word index in the sequence into a dense vector, enabling the model to learn relationships between words.
embeded_vector_size = 5
model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=embeded_vector_size, input_length=m

Flatten and Add Dense Layer
After embedding, the sequence of embeddings is flattened into a single vector using Flatten(), preparing it for further dense layers.
A final Dense layer with a sigmoid activation function is added to output a binary sentiment classification (positive or negative).
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
Compile and Train the Model
The model is compiled with binary cross-entropy loss (suitable for binary classification) and an optimizer (Adam in this case).
X represents the padded reviews, and y is the sentiment array.
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X, y, epochs=10, verbose=1)
Evaluate the Model
After training, the model can be evaluated on test data. In the provided image, the model achieves an accuracy of 1.0 on the sample data, indicating perfect classification for this simple example.
loss, accuracy = model.evaluate(X, y)
Accessing the Embedding Layer Weights
The weights of the embedding layer (the word vectors) can be retrieved for inspection. This is done using
model.get_layer('embedding').get_weights(), which returns the learned
word embeddings.
embedding_weights = model.get_layer('embedding').get_weights()[0]
Explanation of the Visuals
The visuals depict the process of embedding:
- Each word in the vocabulary (e.g., "nice", "food") is represented by a unique index and mapped to a dense vector.
- The embedding layer learns these dense representations during training.
- After embedding, the sequences are flattened and passed through a dense layer for final classification.
- This process enables Keras models to convert discrete word indices into continuous vector representations, allowing for meaningful learning from text data .


Top comments (0)