Introduction
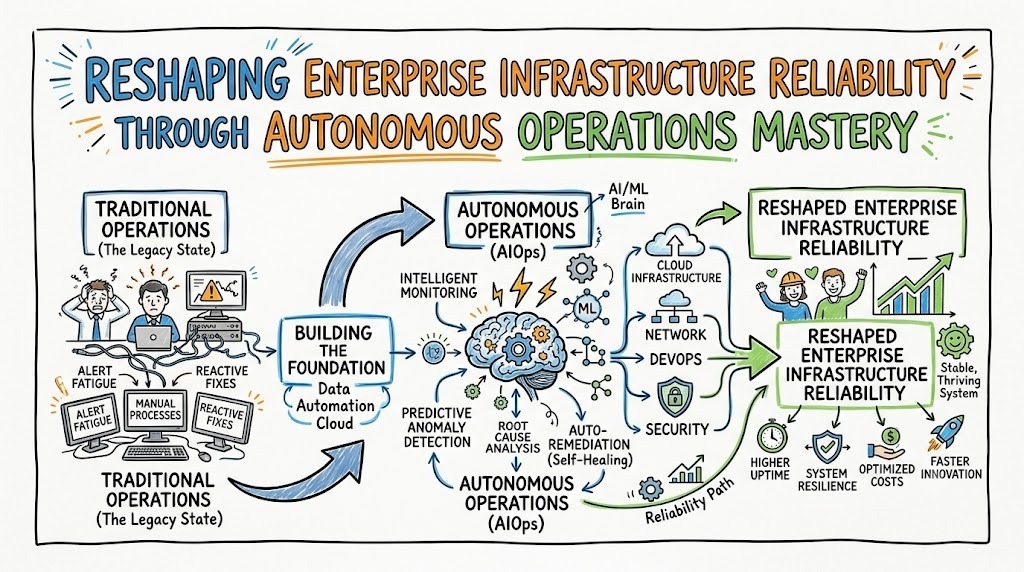
Distributed cloud systems generate a relentless wave of telemetry data that easily overwhelms traditional engineering setups. Consequently, operational teams endure constant alert fatigue as thousands of repetitive notifications flood their dashboards every single day. When critical outages hit production, tracking down the root architectural failure turns into a slow, frustrating search through disconnected monitoring apps. Fortunately, specialized educational hubs address these complex ecosystem headaches by delivering comprehensive AIOps Training.
By injecting machine learning directly into infrastructure layers, modern companies systematically filter out background operational noise. Engineers quickly realize that standard legacy tools cannot scale alongside ephemeral container networks and dynamic microservices. Therefore, building practical expertise via AiOpsSchool empowers technology professionals to transform passive system monitoring into predictive, self-healing runtime administration.
Demystifying the Foundation of Autonomous Systems
To grasp this operational shift, technology teams must evaluate the core mechanics behind What is AIOps. Put simply, artificial intelligence for IT operations merges big data architectures with machine learning algorithms to upgrade infrastructure management. Instead of relying on rigid, human-defined alerting thresholds, this strategy applies mathematical models to uncover hidden behavioral anomalies across complex software stacks.
Subsequently, the central platform screens live performance data to catch infrastructure deviations before end users notice any application lag. This methodology removes the need for slow trial-and-error debugging during active, high-priority system outages. Ultimately, this modern approach converts basic infrastructure administration into an automated, highly intelligent ecosystem that supports fast corporate expansion.
Key Operational Concepts You Must Know
Navigating modern cloud topologies requires deep familiarity with real-time computation and data ingestion pipelines. Therefore, technical professionals must prioritize building deep expertise in AIOps in IT operations to remain competitive in the market. The entire operational framework relies on five fundamental pillars that transform raw infrastructure metrics into clear system context.
- Full-Stack Observability: Assembling structured logs, real-time metrics, and distributed traces from every layer of the enterprise software application.
- Unified Telemetry Collection: Funneling separate infrastructure data streams into a single analytical engine for continuous algorithm evaluation.
- Intelligent Event Correlation: Grouping thousands of duplicate downstream alerts into one clear incident ticket based on timing.
- Dynamic Baseline Mapping: Analyzing historical performance records to establish normal behavior models during peak user traffic hours.
- Automated Remediation Workflows: Launching immediate recovery scripts or server adjustments the moment the system identifies known failure signatures. Mastering these basic building blocks enables engineers to move past simple metric visualization into engineering resilient, self-correcting environments. Consequently, understanding these architectural details allows teams to build sustainable maintenance patterns that reduce human errors. ## Elevating Skills Through AIOps for Beginners Launching a career in automated infrastructure can initially feel daunting because of the advanced technical concepts involved. However, spending dedicated time to master AIOps for beginners offers a structured, accessible path into high-scale system management. Aspiring platform specialists should keep several essential factors in mind when starting their educational path.
- Modern enterprise environments are moving rapidly away from manual scripting toward designing self-correcting cloud networks.
- Hiring managers aggressively search for operations professionals who know how to deploy algorithmic filters to cure alert fatigue.
- Gaining these foundational skills early shields your technical career from automation trends that phase out routine maintenance work. ## Navigating Modern Paradigms: AIOps vs DevOps vs MLOps Distinguishing between various modern infrastructure models helps technology leaders distribute their engineering talents more effectively. Although these methodologies collaborate closely within an enterprise ecosystem, their core goals and daily workflows remain quite distinct. | Concept | Primary Focus | Core Question It Answers | |---|---|---| | AIOps vs DevOps | Improving environment uptime through automated algorithmic data analysis. | How do we automate root-cause isolation and eliminate systemic alert noise? | | DevOps | Accelerating deployment pipelines using continuous software delivery loops. | How can application developers deliver code changes quickly and safely? | | MLOps | Managing the lifecycle and deployment of live machine learning models. | How do we prevent predictive models from degrading over time? | Spotting these operational boundaries prevents engineering teams from mixing up different technical strategies during digital transformation initiatives. Furthermore, contrasting these differences helps managers design clear, efficient educational roadmaps for their technical staff. ## Platform Implementation vs Culture — What's the Real Difference? Many enterprise organizations mistakenly think that achieving autonomous operations only requires buying a premium software subscription. However, achieving true operational excellence requires a total overhaul of everyday team habits alongside configuring advanced monitoring code. Simply installing an analytics platform without upgrading engineering culture usually leads to teams ignoring automated suggestions entirely. | Aspect | Platform Implementation | Cultural Transformation | |---|---|---| | Core Objective | Installing tracking agents and linking machine learning data ingestion tools. | Establishing team trust in automated script choices and dismantling organizational silos. | | Primary Challenge | Aligning diverse log formats, establishing API connections, and maintaining data lakes. | Overcoming staff anxiety regarding letting automated scripts manage critical server failures. | | Long-term Value | Delivers the raw computational horsepower needed to process massive enterprise telemetry logs. | Ensures lasting adoption, continuous workflow refinement, and healthy operational evolution. | Consequently, focusing heavily on structured AIOps Training bridges the gap between basic tool capabilities and day-to-day human execution. When operations engineers learn how to interpret machine learning outputs properly, they build the confidence needed to authorize automated rollbacks safely. Ultimately, blending robust software platforms with flexible team cultures yields highly successful implementations of AIOps in IT operations. ## Core AIOps Use Cases for Enterprise Efficiency Deploying machine learning algorithms across enterprise infrastructure layers delivers massive performance upgrades for modern engineering groups. Organizations that integrate these analytics systems consistently see major improvements across multiple production vectors.
- Dynamic Anomaly Tracking: Scanning continuous data feeds to catch weird infrastructure shifts without relying on static alert limits.
- Smart Event Bundling: Condensing thousands of identical alert notifications into a single incident report to protect on-call engineers.
- Advanced AIOps root cause analysis: Trailing application dependency trees automatically to pinpoint the exact origin of a system failure.
- Predictive Resource Forecasts: Examining historical infrastructure consumption to predict exactly when database clusters will need upgrades.
- Automated Incident Fixes: Executing preset scripts instantly to resolve recurring software hitches without waking up human developers.
- Optimizing AIOps in IT operations: Improving hybrid cloud environments by using algorithms to distribute compute workloads dynamically. ## Real-World Use Cases of Modern Operations Global companies across diverse market sectors rely on these automated strategies to maintain constant application availability. For instance, a prominent retail website utilized diverse AIOps use cases to catch tiny database slowdowns during massive online sales rushes. The system isolated the struggling database node immediately and rerouted shopper traffic, keeping the digital checkout lane completely open. Similarly, a major financial corporation used these exact methods to shield its banking network against sudden backend hardware glitches. By running continuous algorithmic analysis on their telemetry, the engineering team caught hidden data deviations that standard tools missed. Consequently, this smart implementation of AIOps in IT operations resolved the server bottleneck before consumers experienced mobile app lag. ## AIOps Tools You Should Know for Practical Delivery Building a functional automated operations framework requires choosing compatible software tools designed to process high-velocity data. Technicians should study an expansive AIOps tools list across multiple infrastructure management fields. ### Monitoring and Observability Platforms
- Dynatrace: Combines full-stack observability with a built-in deterministic artificial intelligence engine for instant answers.
- Datadog: Features massive cloud monitoring capabilities alongside highly flexible anomaly detection filters.
- ScienceLogic: Delivers context-rich visibility across legacy hardware and hybrid cloud setups to speed up event fixes. ### Event Correlation and ITSM Platforms
- BigPanda: Condenses hundreds of chaotic technology notifications into clean, chronological incident maps.
- PagerDuty Process Automation: Drives automated incident remediation by triggering recovery scripts straight from active alerts.
- Moogsoft: Uses collaborative machine learning routines to cut out corporate alert noise immediately. ### Open-Source Architectures and Cloud Services
- OpenTelemetry: Standardizes how teams gather distributed traces, metrics, and application logs in modern cloud environments.
- Elastic Stack (ELK): Offers scalable log storage paired with customizable machine learning anomaly tracking features.
- AWS Lookout for Metrics: Spots unexpected changes in operational data pipelines using pre-tuned cloud algorithms. Reviewing a practical AIOps Tutorial teaches engineers how to tie these individual AIOps Tools into a single, highly resilient architecture. Furthermore, mastering these setups prepares technical professionals to manage enterprise system topologies with minimal manual maintenance. ## Common Mistakes in Operations Engineering When technology groups rush their transition to autonomous operations, they often hit predictable architectural roadblocks. For example, feeding messy telemetry streams into the platform causes machine learning models to generate highly inaccurate recommendations. Engineers must actively avoid these system design errors to get the best return from AIOps in IT operations.
- Neglecting Early Noise Filtering: Allowing duplicate alerts to pollute the analytical engine, which spoils the machine learning outputs. The Fix: Clean up your upstream warning rules before training the system models.
- Viewing the Tool as Set-and-Forget: Assuming the software requires zero manual tuning or ongoing algorithmic refinement. The Fix: Set up monthly evaluations to audit and calibrate your analytics engine.
- Skipping Log Standardization: Ingesting chaotic, mismatched text patterns from various application teams without a shared format. The Fix: Standardize your logging patterns using OpenTelemetry frameworks.
- Enabling Auto-Remediation Too Quickly: Switching on automated code fixes before confirming that your alert triggers are highly reliable. The Fix: Mandate manual supervisor check-offs during your first 90 days of live operation.
- Leaving Out Application Developers: Failing to teach software builders how to utilize autonomous diagnostics during code debugging. The Fix: Host shared team workshops to show how AIOps root cause analysis accelerates bug fixes for everyone. ## Streamlining Infrastructure Reliability with AIOps for SRE Site Reliability Engineering teams must maintain tight service uptime targets while pushing out new software features as fast as possible. Consequently, leveraging AIOps for SRE gives these professionals the precise real-time data they need to keep systems rock-solid. Algorithmic software engines protect core environments by continuously evaluating system health trends around the clock. Specifically, these automation tools slash the Mean Time to Detection (MTTD) by flagging unexpected system shifts the moment they happen. At the same time, automatic log collection drastically drops the Mean Time to Resolution (MTTR) during major production crashes. As a result, SRE branches safeguard their operational error budgets while safely increasing feature release speeds. ## Seeing AIOps in Action Review this operational scenario to understand how automated intelligence performs under heavy production pressure. ### The Problem A high-volume cloud application experiences an abrupt drop in successful customer transactions. Simultaneously, traditional monitoring monitors go chaotic, triggering over three hundred separate alert notifications across network, database, and code layers. This sudden wall of data leaves on-call technicians scrambling to find the actual root failure point. ### The AIOps-Driven Resolution Strategy The intelligent operations system catches the wave of alert notifications and compresses them into one clean incident report based on timing. Next, the tool checks the live system topology map, utilizing AIOps root cause analysis to trace the exact line of failure. The software ignores the noisy database warnings and identifies a locked thread pool inside a freshly updated login microservice.
[Raw Telemetry Ingestion]
│
▼
[Event Correlation Layer] ──► (Consolidates 300+ Alerts into 1 Incident)
│
▼
[Topology Dependency Mapping] ──► (Bypasses Downstream Database Noise)
│
▼
[AIOps Root Cause Analysis] ──► (Identifies Authentication Code Defect)
│
▼
[Automated Remediation] ──► (Rolls Back Defective Deployment Instantly)
Immediately, the platform fires an automated rollback script that replaces the broken software version with the previous stable build. This whole troubleshooting sequence runs instantly without needing manual exploration or late-night emergency meetings.
The Measurable Result
The company resolves the entire production glitch in less than three minutes, crushing their old manual fix average of two hours. Consequently, the enterprise saves thousands of dollars in emergency costs while protecting its digital user experience. This live case proves how integrating AIOps in IT operations shifts technical staff from stressful firefighting to proactive system design.
How to Become an Operations Expert — Career Roadmap
Climbing to the top of the modern automation field requires a methodical strategy for mastering cloud telemetry concepts. Sticking to a structured career path ensures that engineers pick up the practical skills required to manage enterprise systems.
- Build Core Technical Foundations: Develop deep familiarity with cloud architectures, container orchestration systems, and Linux command lines.
- Invest in Structured Education: Enroll in a rigorous AIOps Course to learn the core math behind telemetry analytics and algorithmic monitoring.
- Gain Hands-On Tool Experience: Create custom lab environments to practice setting up observability platforms and event correlation setups.
- Confirm Your Skills Officially: Earn an industry-backed AIOps Certification to showcase your technical talents to global IT employers.
- Choose an Advanced Specialization: Target high-demand professional sectors like site reliability engineering, platform design, or multi-cloud automation. Adopting this roadmap turns traditional system administrators into elite automation architects. Furthermore, constant skill upgrading keeps you indispensable as global corporations shift toward autonomous infrastructure models. ## Why Get an AIOps Certification? Validating your engineering skills through formal testing provides a highly effective method for accelerating your technology career. Earning a professional AIOps Certification proves to enterprise hiring teams that you know how to build self-correcting software networks. Furthermore, completing a structured validation program like an AIOps Foundation Certification helps you organize your technical knowledge into a clear framework. Additionally, certified specialists enjoy a massive advantage when interviewing for modern infrastructure positions. Companies actively hunt for engineers who can confidently direct large-scale migrations toward automated cloud operations. Ultimately, gaining official credentials opens up high-paying career paths in DevOps strategy, SRE management, and enterprise platform architecture. ## Frequently Asked Questions
- What are the primary career benefits of securing a formal AIOps Certification? Earning this professional credential validates your ability to embed machine learning algorithms into enterprise cloud environments. As a result, this badge highlights your profile during corporate recruitment drives and qualifies you for high-level infrastructure roles.
- How does an introductory AIOps Foundation Certification differ from advanced technical engineering credentials? The foundational course teaches core industry terminology, telemetry collection strategies, and baseline machine learning logic. Conversely, advanced engineering programs require students to build functional automation scripts, connect live platforms, and configure complex correlation rules.
- What specific technical prerequisites should I complete before registering for a comprehensive AIOps Course? Applicants need a steady understanding of cloud service patterns, basic container administration, and common command-line controls. Having a working knowledge of traditional DevOps continuous deployment frameworks will also speed up your learning curve.
- Is an AIOps Engineer Certification highly valued by modern enterprise tech employers? Yes, modern technology firms struggle with an intense shortage of technicians who know how to manage high-velocity monitoring data. Holding this specific certificate demonstrates that you can reduce operational overhead and cure systemic alert fatigue effectively.
- What practical technical skills are emphasized during comprehensive AIOps Engineer Training programs? These interactive labs focus on building log data pipelines, setting up live anomaly detection rules, and activating automated remediation code. Students also practice connecting open-source monitoring configurations with major public cloud platforms.
- Can I successfully complete an authorized AIOps Online Training program while working a full-time engineering job? Yes, modern training layouts use highly flexible, self-paced virtual formats designed around the hectic schedules of active tech workers. This setup allows you to master advanced data analytics concepts without disrupting your daily workplace duties.
- How do specialized AIOps Consulting services help large enterprises accelerate their infrastructure updates? Consulting teams audit an enterprise's current system state, find data quality flaws, and select the best monitoring platforms. This professional direction prevents companies from blowing budgets on bad tool choices and poorly designed automation concepts.
- What primary challenges are resolved by professional AIOps Implementation Services? These service engineers make sure your enterprise configures data ingestion lines, cloud metrics trackers, and alert handlers perfectly. This expert support allows company operations teams to migrate safely from old manual setups to highly stable autonomous frameworks. ## Where to Learn AIOps Building modern automation talents requires direct access to high-quality, real-world educational materials. AiOpsSchool provides specialized professional programs built to help technical minds flourish in data-driven environments. Students can choose from multiple paths depending on their near-term professional goals:
- AIOps Training: Immersive programs that explore machine learning mechanics, anomaly tracking, and advanced log pipeline design.
- AIOps Course: Deep technical modules focusing on production tool configurations, metric tracking, and coding automated recovery fixes.
- AIOps Certification: Validation tracks designed to verify your hands-on engineering capabilities before global corporate recruiters.
- AIOps Tutorial: Step-by-step technical blueprints that show you how to link open-source observability frameworks with distributed applications. ## Final Thoughts The rapid growth of distributed cloud systems makes manual, threshold-based infrastructure monitoring completely obsolete. To stay ahead, modern engineering groups must replace old reactive troubleshooting habits with predictive, machine-led automation strategies. Enrolling in a comprehensive program like AIOps Training hands professionals the advanced capabilities needed to engineer resilient, self-healing networks. Validating your technical talents with an official AIOps Certification unlocks premium career options in site reliability engineering and platform architecture. Embracing these advanced algorithms allows you to crush alert fatigue, accelerate root cause identification, and protect application uptime. Check out the learning opportunities at AiOpsSchool.com to start mastering autonomous systems today.

Top comments (0)