Building tangible applications represents the single most effective way to solidify your coding knowledge. Theoretical learning provides the foundational framework, but practical implementation exposes you to authentic runtime errors, architectural challenges, and debugging cycles. Aspiring developers often struggle to find comprehensive platforms that bridge this gap between raw code and deployable software. When you study core software engineering principles at Debug.school, the primary focus shifts from passive reading to active, project-driven learning. This educational methodology forces you to think like a seasoned engineer, guiding you through real-world deployment pipelines and complex system design.
Understanding the mechanics of web systems requires moving beyond simple static templates. Modern software delivery relies on a blend of responsive frontend styling, secure backend state management, and reliable deployment configurations. Therefore, selecting the right portfolio items will define your readiness for the competitive software market. By focusing on multi-tier applications, you learn how database schemas interact with client-side state managers. The curricula at this platform emphasize these precise intersections, ensuring you write robust, clean, and testable code.
Key Operational Concepts You Must Know
Before deploying any complex application, you need to understand how data moves through a system. Operational competency begins with stateless architecture and distributed systems. When you build software, individual web application servers should not rely on local file storage to maintain session states. Consequently, you must configure external memory caches or centralized databases to track user authentication tokens. This structural approach ensures you can scale application instances horizontally without dropping user connection data.
Understanding Stateless Architecture and Horizontal Scaling
Stateless services process each client request as an independent transaction, completely isolated from previous interactions. Consequently, your backend infrastructure can distribute traffic across multiple active servers using a network load balancer. If an individual server instance crashes due to a memory leak, the remaining cluster handles the incoming traffic seamlessly. Furthermore, this architectural pattern simplifies containerized deployments, enabling engineering teams to spin up new application nodes within seconds during sudden traffic surges.
To achieve true horizontal scalability, you must decouple your persistent storage layers from your compute resources. For example, user-uploaded profile pictures should reside in centralized cloud object storage buckets rather than a local server directory. Similarly, session variables belong in high-speed, in-memory data structures like Redis. By implementing these practices early in your project development, you eliminate single points of failure and establish a production-grade software environment.
Data Persistence and Schema Migrations
Managing the lifecycle of your database requires strict version control and automated migration scripts. As your application evolves, your underlying relational database tables will inevitably need new columns, indexes, or altered data types. Writing raw SQL updates directly in a production database environment invites catastrophic data loss and mismatched environments. Instead, you should utilize programmatic database migration tools within your web frameworks to track structural modifications systematically.
+-----------------------+ +-----------------------+ +-----------------------+
| Migration File 001 | ---> | Migration File 002 | ---> | Migration File 003 |
| (Create Users Table) | | (Add Profile Columns) | | (Create Orders Table) |
+-----------------------+ +-----------------------+ +-----------------------+
Every database migration file should contain both an "up" script to apply modifications and a corresponding "down" script to roll back changes safely. This dual approach allows engineering teams to synchronize schema layouts across local development environments, staging platforms, and live production clusters. Ultimately, maintaining atomic, ordered migration histories protects system data integrity during rapid feature deployments.
API Versioning and contract management
When you modify backend services, you must prevent breaking changes from disabling active frontend interfaces or external client applications. Sound operational design mandates strict API versioning strategies, typically managed through specific URL paths or custom request headers. By routing traffic to distinct versioned endpoints, you allow older client applications to function correctly while rolling out enhanced features for newer builds.
[Client Application]
│
├─── (GET /api/v1/products) ────> [Legacy Service Node]
│
└─── (GET /api/v2/products) ────> [Enhanced Service Node]
Contract management involves establishing explicit JSON schemas that define precisely what properties an endpoint requires and returns. Utilizing API validation tools guarantees that incoming request payloads adhere to expected data types before hitting your core business logic. Consequently, your systems reject malformed data automatically at the boundary layer, preserving backend security and reducing unexpected operational exceptions.
Continuous Integration and Automated Verification
Modern development workflows discard manual code building and ad-hoc FTP server transfers entirely. Continuous integration loops automatically compile your application code, run automated test suites, and audit security vulnerabilities whenever a developer pushes a new branch. This immediate feedback loop allows you to catch syntax regressions, broken dependencies, and logical anomalies before code reaches a shared repository branch.
An optimal validation pipeline enforces code quality standards uniformly across your entire engineering team. For example, your configuration should require all unit test suites to maintain a high level of code coverage before permitting a branch merge. Additionally, automated linters inspect your files to ensure adherence to standard styling guides, reducing formatting disputes during code reviews.
[Code Push] ──> [Run Linters] ──> [Execute Unit Tests] ──> [Security Scan] ──> [Build Artifact]
Monitoring, Metrics, and Log Aggregation
Once an application functions live on a network, you cannot rely on manual terminal inspections to diagnose hidden system bugs. Log aggregation pipelines compile standard output streams from every running application container into a centralized searchable dashboard. This setup allows you to trace user request journeys across multiple distributed microservices using unique correlation identifiers.
- Application Latency Metrics: Tracks the exact millisecond duration of server responses to detect database query bottlenecks.
- HTTP Error Distribution: Monitors the ratio of 5xx server errors relative to total inbound traffic volume.
- System Resource Utilization: Measures real-time central processing unit utilization and physical memory consumption across server clusters.
- Database Connection Pooling: Observes the volume of active versus idle database connections to prevent pool starvation.
Platform Implementation vs. Culture — What's the Real Difference?
Engineering teams often conflate specific automation platforms with foundational operational philosophies. To build truly resilient applications, you must recognize that software tooling merely serves as an extension of structural workflows. Adopting advanced container orchestration frameworks yields minimal performance improvements if your development team continues to operate within isolated technical silos.
| Operational Facet | Tooling and Platform Implementation | Cultural and Philosophical Alignment |
|---|---|---|
| Primary Objective | Deploying specific infrastructure software, scripts, and monitoring agents. | Establishing shared accountability, open feedback loops, and collective ownership. |
| Problem Solving | Writing automation routines, tuning configurations, and fixing hardware bottlenecks. | Conducting blameless post-mortems, analyzing systemic root causes, and iterating workflows. |
| Scaling Strategy | Adding computational hardware resources and provisioning automated cloud infrastructure. | Training engineers, documenting system patterns, and lowering cognitive operational friction. |
| Risk Management | Setting strict security policies, access control lists, and automated backups. | Encouraging small, iterative software releases to minimize blast radiuses during updates. |
The Pitfalls of Tooling Centric Mindsets
Focusing exclusively on acquiring proficiency with hot technical platforms creates fragile engineering ecosystems. When a team prioritizes a specific cloud provider's proprietary services over fundamental networking logic, migrating applications becomes incredibly complex. Software systems become difficult to debug because engineers understand the graphical dashboard settings but lack fundamental knowledge of underlying protocol handshakes.
True operational maturity requires treating software platforms as highly disposable commodities. Your primary architecture should remain independent of specific vendor implementations whenever possible. By focusing on open standards and universal web protocols, you build applications that transition effortlessly between local development setups and any cloud computing environment.
Fostering Shared Engineering Responsibility
A healthy development environment eliminates the traditional divide between feature developers and infrastructure operators. When frontend and backend engineers take active responsibility for how their systems execute in production environments, software quality improves. Developers write more efficient code, optimize database queries, and handle exceptions cleanly when they are tasked with monitoring their own applications.
+-----------------------------------------------------------+
| Shared Responsibility Loop |
| |
| [Plan] ──> [Code] ──> [Test] ──> [Deploy] ──> [Monitor] |
| ^ │ |
| └─────────────── [Analyze Feedback] <──────────┘ |
+-----------------------------------------------------------+
This cultural shift relies heavily on accessible operational data across the entire organization. When telemetry dashboards and log search tools are open to all team members, everyone gains insight into system health. Consequently, resolving service anomalies becomes a collaborative effort rather than a finger-pointing exercise between disparate technical groups.
Real-World Use Cases of Modern Operations
Applying architectural theories to practical software development clarifies how modern businesses maintain high availability. When you construct real-world systems, you quickly realize that clean code must be paired with structured runtime strategies. Examining specific industry challenges illustrates how sophisticated infrastructure operations directly safeguard system stability.
Blue-Green Deployment Strategies for Zero-Downtime Releases
Upgrading production software often introduces brief connection interruptions if you overwrite existing application binaries in place. To prevent this issue, modern engineering teams utilize blue-green deployment methodologies to transition live production traffic seamlessly between versions. This technique involves maintaining two identical hosting environments, where one environment handles production users while the other sits idle.
[Inbound Traffic]
│
▼
[Load Balancer]
│
┌──────────────────┴──────────────────┐
▼ ▼
[Environment Blue] [Environment Green]
Active Production V1.0 Idle Stage/New V1.1
When you prepare a new software update, you deploy the code to the inactive environment for isolated verification testing. Once you validate that the system functions correctly under simulated conditions, you configure the load balancer to route all incoming requests to the updated environment. If unexpected errors surface post-launch, you can instantly re-route your traffic back to the original cluster, eliminating extended service outages.
Circuit Breaking Patterns in Distributed Services
In distributed microservice networks, a slowdown or failure in one backend component can trigger a cascading system failure across your entire cluster. For example, if a third-party payment processing API experiences severe latency, your order processing servers might consume all available worker threads waiting for responses. To isolate these failures, you should integrate circuit breaker state patterns within your service communication layers.
+-------------------------+
| Client Request Stream |
+-------------------------+
│
▼
[Circuit Breaker Component]
/ \
(State: Closed) (State: Open)
/ \
▼ ▼
[Primary Live Service] [Fallback Default Logic]
(Processes Normally) (Returns Cached Data Fast)
The circuit breaker monitors the failure rates of outgoing requests to external dependencies. Under normal operating conditions, the circuit remains closed, allowing communications to flow freely. If the target service's failure rate crosses a specific threshold, the circuit trips open, immediately rejecting subsequent requests and returning graceful fallback messages to the user without exhausting internal system memory.
Automated Horizontal Pod Autoscaling
E-commerce networks often experience unpredictable spikes in user traffic during seasonal flash sales or promotional campaigns. Manually monitoring server loads and provisioning additional virtual instances during a live traffic surge is too slow to prevent service slowdowns. Instead, operations teams leverage automated scaling configurations tied directly to internal performance metrics.
- Metric Evaluation: The cluster orchestrator checks application container utilization metrics every fifteen seconds.
- Threshold Breaches: If collective internal resource utilization exceeds sixty-five percent, scaling rules trigger automatically.
- Replica Calculation: The system computes the precise number of additional worker pods required to stabilize system load.
- Graceful Integration: New containers boot up, pass health check verifications, and register with the load balancer inside a minute.
Database Read-Write Splitting for Performance
High-traffic content platforms typically process substantially more data read requests than structural data write requests. When a single database instance attempts to process complex search queries while simultaneously handling transactional updates, database locking contentions arise. To resolve this performance obstacle, engineers separate their database operations across distinct read and write infrastructure channels.
[Application Logic]
/ \
(Write Queries) (Read Queries)
/ \
▼ ▼
[Primary Database] ----> [Replica Database]
(Master Source) (Async) (Read-Only Copy)
In this setup, your application routes all data modifications, such as user creation or payment records, exclusively to a primary master database. This master node asynchronously replicates its state changes to one or more read-only replica instances. Your application directs heavy search operations and user dashboard lookups directly to these replica systems, keeping your primary write engine responsive.
Common Mistakes in Operations Engineering
Building scalable software requires learning how to identify and avoid anti-patterns that degrade application availability. Even highly skilled application developers regularly commit foundational infrastructure mistakes when transitioning code to production systems. Recognizing these common engineering pitfalls allows you to proactively design robust, resilient deployment pipelines.
Hardcoding Infrastructure Secrets and Configuration Values
One of the most dangerous security oversights involves embedding environment-specific parameters, third-party API keys, or database passwords directly within application source code repositories. This bad habit introduces critical security vulnerabilities, as anyone with access to the code history can compromise production resources. Furthermore, it prevents you from moving the compiled software across different development and staging environments smoothly.
// CRITICAL ERROR: Hardcoded credentials commit security violations
const databasePassword = "SuperSecretProductionPassword123";
connectDatabase(databasePassword);
// CORRECT APPROACH: Fetch credentials securely from execution environments
const databasePassword = process.env.DATABASE_PRODUCTION_PASSWORD;
connectDatabase(databasePassword);
To resolve this issue, you must decouple your application configuration parameters from your core executable logic entirely. Use system environment variables or secure, encrypted secret store engines to load keys dynamically at runtime. This keeps your application source code completely clean of credentials, letting you open-source your code repositories safely without exposing underlying servers.
Neglecting Graceful Shutdown Protocols
When scaling down cluster instances or deploying software updates, orchestration layers terminate active application containers regularly. If your background server processes close abruptly, ongoing database transactions can freeze in incomplete states, corrupting user data records. This issue commonly surfaces when web servers discard active network connections immediately upon receiving a termination signal from the operating system host.
[SIGTERM Signal Received] ──> [Stop Accepting New Requests] ──> [Complete Active Requests] ──> [Close DB Connections] ──> [Process Exit]
To implement proper graceful shutdowns, your software must intercept system termination signals like SIGTERM. When notified, the web server should immediately stop accepting new incoming network requests while keeping existing connections active to finish processing ongoing requests. Once all active connections clear out, the application closes its open database pools and exits cleanly, preventing data corruption.
Relying on Manual Server Configurations
Configuring production servers manually via direct secure shell terminal connections creates unpredictable runtime environments. Over time, ad-hoc software updates, manual configuration tweaks, and unrecorded software packages cause the server's state to drift significantly from local development boxes. This configuration drift makes debugging application errors incredibly difficult because the target environment becomes impossible to replicate accurately.
- Lack of Audit Trails: Manual modifications leave no version history tracking who changed specific configurations or why.
- Replication Failure: Rebuilding a crashed server from scratch requires hours of troubleshooting to match previous undocumented dependencies.
- Deployment Inconsistencies: Applications function perfectly in local staging builds but fail unexpectedly in production due to minor library variations.
- Security Vulnerabilities: Manual changes often skip standardized security testing protocols, exposing open network ports.
Absence of Health Checks and Liveness Probes
Deploying an application container without configuring automated health verification checks poses a serious operational risk. A web server might boot up successfully and register with a load balancer, yet remain completely incapable of processing user transactions due to an unhandled internal database connection failure. Without active liveness probes, your load balancers continue routing traffic to this dead instance indefinitely.
[Load Balancer]
/ \
(Passes Health Check) (Fails Health Check)
/ \
▼ ▼
[Healthy Container] [Unhealthy Container]
(Receives Traffic) (Dropped & Restarted)
To fix this, you must build explicit health endpoints, like /healthz, directly into your backend routing architecture. These internal handlers should verify that database connections are responsive, external file systems are writable, and core dependencies are reachable. Network orchestrators check these endpoints continuously, automatically dropping unhealthy instances from routing tables and spinning up fresh replacements.
How to Become an Operations Expert — Career Roadmap
Transitioning from a general web developer to an operations specialist requires a structured approach to learning software infrastructure. You cannot master networking architecture, automated deployment pipelines, and systems design all at once. By following an incremental, structured roadmap, you can systematically build deep technical expertise and establish a highly resilient engineering career.
Phase 1 — Foundations of Networking and Systems
Begin your journey by mastering the fundamental protocols that govern how data moves across the internet. You need to understand how the domain name system resolves human-readable web addresses into destination internet protocol locations. Additionally, gain a deep understanding of transport control protocol handshakes, secure socket layer encryption certificates, and standard HTTP message structures.
Next, focus on developing comfort with command-line terminal environments. Learn how to navigate file structures, manage user file system permissions, and monitor running background processes within Linux operating systems. Understanding how your code interacts with low-level kernel resources allows you to debug performance bottlenecks and resource exhaustion issues confidently.
Phase 2 — Containerization and Local Environment Parity
Once you grasp underlying system frameworks, transition away from installing application languages directly onto your host computer. Learn how to wrap application runtimes, third-party dependencies, and configuration templates cleanly inside isolated container images. Using containers guarantees that your application runs identically across every developer's machine, staging server, and production cluster.
+-------------------------------------------------------+
| Standard Container Image |
| |
| [App Executable Code] ──> [Runtime Dependencies] |
| [System Libraries] ──> [Environment Configs] |
+-------------------------------------------------------+
After mastering single-container configurations, practice orchestrating multi-tier applications locally. Use multi-container definitions to spin up your backend server, database instance, and memory cache clusters simultaneously with a single terminal command. This setup helps you understand network isolated links, volumes for data persistence, and how containers communicate over private virtual networks.
Phase 3 — Infrastructure as Code and Automation
Now that you can containerize your applications, you should focus on automating how your hosting infrastructure is provisioned. Stop clicking through cloud web dashboards manually to configure server instances, networks, and firewalls. Instead, learn to write declarations that define your desired cloud layout in clear, version-controlled text files.
[Infrastructure Code Files] ──> [Automation Tool Engine] ──> [Cloud API Provider] ──> [Live Cloud Resources]
Adopting infrastructure automation allows you to treat your entire server network as predictable, repeatable code assets. You can track your hardware configurations inside Git repositories, run reviews on architectural updates, and spin up identical environments instantly. This method eliminates manual setup mistakes and forms the baseline for modern cloud infrastructure management.
Phase 4 — Advanced Orchestration and Production Scale
The final phase of your roadmap involves learning how to manage complex, multi-container applications across large server networks. When applications scale out to handle massive traffic volumes, managing individual instances manually becomes impossible. You need to study advanced orchestration systems that automate deployment scheduling, network routing, and resource tracking across clusters.
[Cluster Master Node]
(Monitors Core State)
│
┌────────────────────────┼────────────────────────┐
▼ ▼ ▼
[Worker Server A] [Worker Server B] [Worker Server C]
(Runs Pods 1 & 2) (Runs Pods 3 & 4) (Runs Pods 5 & 6)
At this level, you focus on designing high-availability storage configurations, setting up auto-scaling boundaries, and building solid cross-region failover pipelines. You learn how to manage complex microservice communications using advanced service meshes, protect data at rest and in transit, and optimize infrastructure spend. Mastering these skills positions you at the top tier of technical systems architecture.
Web Projects to Build for Real Skill Growth
Developing technical competency requires building applications that mirror the complex architectural challenges encountered in real enterprise environments. Simple tutorial apps fail to prepare you for production edge-cases, system bottlenecks, and live debugging scenarios. The projects outlined below are designed to stretch your software engineering capabilities, forcing you to think about data flows, system isolation, and operational efficiency.
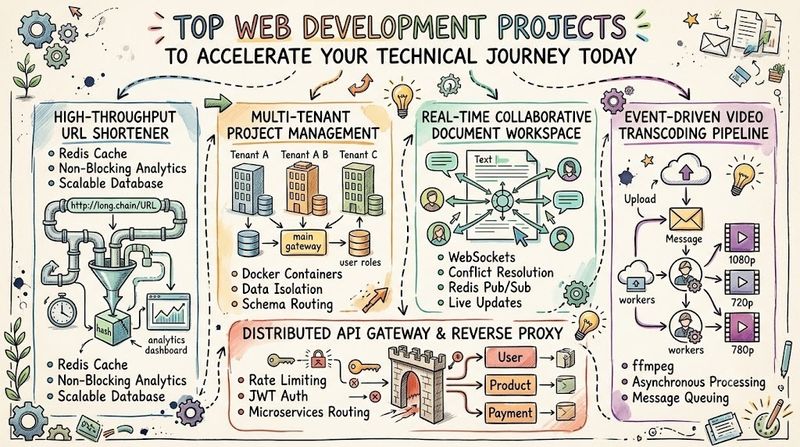
1. High-Throughput URL Shortener with Analytics
A URL shortener seems simple on the surface, but scaling it to handle millions of redirects requires deep optimization. This project forces you to balance fast data reads against heavy analytics writes. You will design a system that takes long links, generates unique short hashes, and routes incoming traffic with minimal latency.
[User Hits Short URL] ──> [Check Redis Cache] ──> (Hit) ──> [Instantly Redirect User]
│
(Miss)
│
▼
[Query Primary SQL DB]
│
[Populate Cache & Redirect]
To maximize performance, you will place a high-speed caching tier in front of your persistent database. When a user visits a shortened link, the application checks the cache first, keeping response times under ten milliseconds. Concurrently, you will route background analytics tracking data through an asynchronous message queue, protecting the core redirection engine from database lock delays.
- Unique Hash Generation: Create a custom Base62 encoding algorithm to turn sequential database IDs into compact strings.
- Layered Caching Strategy: Use Redis to store active short code mappings in memory, reducing direct database query strain.
- Non-Blocking Analytics: Build an internal background processing system to track clicks, user agents, and geographic data without slowing down redirects.
- Database Partitioning: Learn to split your analytics database tables by date ranges to keep query speeds consistent as your logs grow.
2. Containerized Multi-Tenant Project Management System
Building a multi-tenant SaaS application teaches you how to keep data securely isolated between different client organizations. You will design an issue tracking platform where multiple companies share the same infrastructure without ever seeing each other's private data. This setup requires building clean database schemas and dynamic routing rules.
[Inbound Request]
│
▼ (Inspect Header / Subdomain)
[Tenant Router Layer]
│
┌────────────────────┴────────────────────┐
▼ ▼
[Route to Tenant A Schema] [Route to Tenant B Schema]
You can approach data isolation in two ways: configuring separate database schemas for each tenant, or using a shared schema with strict row-level filtering. Beyond structural data security, you will package this entire application inside Docker containers. This ensures the frontend UI, backend API, and database services boot up cleanly as an integrated stack anywhere.
- Dynamic Subdomain Routing: Resolve tenant identification strings directly from incoming request URLs to isolate data spaces cleanly.
- Secure Schema Isolation: Build a database router that selects the correct tenant database connection pool dynamically per request.
- Docker Compose Orchestration: Write custom configurations to spin up your frontend, backend, and database instances with unified networking.
- Automated Data Seeding: Build automated scripts to run migrations and seed default administrative data whenever a new client tenant joins.
3. Real-Time Collaborative Document Workspace
Building a real-time collaborative workspace introduces you to asynchronous networking and event-driven architectures. Unlike standard REST APIs, a collaborative editor requires bidirectional, open communication channels between your clients and servers. You will implement WebSockets to broadcast user edits instantly across all active document sessions.
[User A Edit Event] ──> [WebSocket Connection] ──> [Central Server Engine]
│
(Broadcast Updates via Redis Pub/Sub)
│
▼
[User B Workspace View]
To prevent users from overwriting each other's changes, you must implement conflict resolution logic using Operational Transformation or Conflict-Free Replicated Data Types. When multiple contributors edit the same paragraph simultaneously, your backend must resolve the inputs and maintain a single source of truth. Additionally, you will connect a Redis Pub/Sub layer to scale out your WebSocket servers across multiple background instances.
- Bidirectional Socket Streams: Establish persistent WebSocket connections to push data changes to clients with minimal network overhead.
- Conflict Resolution Engine: Build algorithms to merge concurrent data inputs cleanly, ensuring document states match for all active users.
- State Broadcasting Layers: Connect Redis Pub/Sub channels to sync real-time events across multiple backend application processes.
- Document Snapshot Ingestion: Save periodic snapshots of your document trees to a persistent database to optimize initial load times.
4. Event-Driven Video Transcoding Pipeline
Handling heavy files like video requires moving away from traditional synchronous request-response loops. If a user uploads a large file directly to your web server, the connection will likely time out while processing. To handle this, you will build an event-driven system that offloads heavy lifting to isolated background workers.
[Video File Upload] ──> [Cloud Object Storage] ──> (Triggers Event) ──> [Message Queue]
│
▼
[Isolated Worker Node]
(Runs ffmpeg Transcode)
Your web server's only job is to accept the upload and store it safely in object storage. Once the upload completes, an event notification routes into a message queue like RabbitMQ or AWS SQS. Isolated background workers pick up the job from the queue, run transcoding tools like FFmpeg to generate multiple video resolutions, and update the database when finished.
- Multipart Stream Uploads: Configure your web servers to accept large video streams directly into chunked cloud storage buckets.
- Decoupled Message Queuing: Use message brokers to queue transcoding jobs safely, insulating backend servers from intense system loads.
- Worker Pool Adjustments: Design your background worker processes to watch queue depths and spin up more instances when jobs pile up.
- Real-Time Status Callbacks: Use WebSockets or webhook listeners to notify user interfaces the second a video finishes processing.
5. Distributed API Gateway and Reverse Proxy
Building your own API gateway provides deep insights into network routing, security boundaries, and traffic management. You will construct an application that sits in front of multiple microservices, acting as the single entry point for all incoming client requests. This project will teach you how to route traffic dynamically, rewrite URL paths, and handle cross-cutting concerns like authentication.
[Inbound Traffic]
│
▼
[Your API Gateway]
(Checks Auth & Rate Limits)
│
┌─────────────────────┼─────────────────────┐
▼ ▼ ▼
[Identity Service] [Product Service] [Billing Service]
Your gateway will inspect incoming headers, authenticate requests via JSON Web Tokens, and forward payloads to the appropriate backend service. To protect your internal servers from malicious traffic or accidental denial-of-service spikes, you will implement a token-bucket rate-limiting algorithm using Redis. This ensures your systems remain stable even under heavy, unpredictable traffic loads.
- Dynamic Reverse Proxying: Parse incoming URL patterns to proxy client network traffic to distinct backend services seamlessly.
- Token Bucket Rate Limiting: Build a fast rate-limiter in Redis to block abusive IP addresses before they strain internal apps.
- Centralized Auth Checking: Validate encryption tokens at the gateway boundary to keep downstream microservices simple and secure.
- Performance Metrics Collection: Track upstream response times and error rates to monitor the overall health of your service network.
FAQ Section
- What makes project-based learning different from traditional coding tutorials? Traditional tutorials often guide you through predictable code paths in controlled environments, which rarely matches real-world development. Project-based learning forces you to face complex runtime errors, handle edge cases, and think through system architecture from scratch. This practical friction teaches you how to break down complex business requirements into clean, maintainable code structures. By building complete applications, you master the crucial debugging and systems-thinking skills that engineering teams look for.
- Can I deploy all of these advanced portfolio projects using free-tier cloud hosting platforms? Yes, you can deploy these applications using free tiers or low-cost cloud developer configurations. Most modern cloud platforms offer generous free tiers for containerized apps, serverless functions, and managed databases. By optimizing your container configurations and using resource-efficient runtimes, you can host your entire portfolio without spending a fortune. Managing these resource-constrained environments also teaches you valuable skills in performance optimization and cost management.
- Why does this curriculum emphasize containerization so early in the learning roadmap? Containerization eliminates the classic problem of code working on a local machine but failing in production due to environmental differences. By wrapping your application and its dependencies inside containers early on, you guarantee consistent performance across all environments. This foundational skill mirrors modern enterprise workflows and simplifies local development for complex, multi-service applications. Mastering containers early also sets you up for success with advanced orchestration and automated deployment pipelines later.
- How do I choose between a SQL and NoSQL database for my portfolio applications? The choice depends entirely on the structure of your data and your application's specific access patterns. Relational SQL databases excel when your data features complex relationships, requires strict transactional integrity, and benefits from a rigid schema. Conversely, NoSQL databases are ideal for unstructured data, high-speed caching, or situations where your data model needs to evolve rapidly. Evaluating these data design requirements for each project teaches you how to make informed architectural decisions.
- What is the most effective way to showcase these complex engineering projects to potential employers? To impress technical hiring managers, your GitHub repositories need to feature clear, comprehensive documentation rather than just raw source code. Write thorough readme files that explain your architectural choices, database designs, and the specific technical challenges you overcame. Include clean system diagrams to illustrate how data flows through your infrastructure. Finally, provide clear, step-by-step instructions for running the application locally, proving that your software is production-ready, well-organized, and maintainable.
Final Summary
Accelerating your software engineering career requires moving past simple syntax exercises and embracing end-to-end application architecture. Building multi-tier, containerized projects prepares you for the realities of modern development environments. By handling data isolation, asynchronous processing, and API management firsthand, you transform from someone who just writes code into a true technical problem solver.
Ultimately, engineering excellence is achieved by combining clean code with structured, automated operations. Focus on building evergreen skills—like mastering foundational networking protocols, automating your infrastructure, and designing for failure. As you scale up your portfolio applications, you build the practical expertise needed to deploy resilient software and thrive in complex, production-grade environments.

Top comments (0)