GENERAL COMMANDS
Read the CSV file into a DataFrame
df = pd.read_csv(file_path)
df
Check Total no row and colunm
df.shape
print(f"The rows and columns in the dataset: {df.shape}")
print("shapes are:",x.shape)
print("shapes are:",y.shape)
Display First 10 rows
df.head(10)
Add new col in existing
df['new_column'] = df['column1'] + df['column2']
Display last 5rows
df.tail()
Display all colunm name
print(f"\nThe column headers in the dataset: {df.columns}")
print(f"\nThe column list in the dataset: {df.columns.tolist()}")
df.columns.tolist()
Display all colunm name
list(x.columns)
list(df.columns)
"Filtering a Pandas DataFrame in Python to Select Rows with Prices Between $1000 and $2500
df=df[df['price'] > 1000]
df=df[df['price'] < 2500]
drop Unnamed colunm from existing dataset
df=df.drop('Unnamed: 0', axis=1)
Display particular range of row
row_data = df.iloc[859:888]
row_data
df.iloc[10,:] ==> select particular row all columns
display colunm data type
df.info() or df.dtypes
Find minimum value and maximum value of particular colunms
print("Min. Date:", df["Date"].min())==>find minimum value of particular colunms
print("Max. Date:", df["Date"].max())===>find maximum value of particular colunms
Fill null value through mean,median and mode
df["totalcharges"].fillna(df["totalcharges"].mean())
mean_A = df['A'].mean()
df['A'].fillna(mean_A, inplace=True)
# Fill missing values in column 'B' using median
median_B = df['B'].median()
df['B'].fillna(median_B, inplace=True)
# Fill missing values in column 'C' using mode
mode_C = df['C'].mode()[0] # Using [0] to get the first mode (in case there are multiple modes)
df['C'].fillna(mode_C, inplace=True)
Find particular colunms minimum,maximum and average values
df["fixed acidity"].min()
df["fixed acidity"].max()
df["fixed acidity"].avg()
Display or filter rows in a DataFrame (df) where the value in the 'TotalCharges' column is an empty string (" ")
df.loc[df['TotalCharges']==" "] is used to filter rows in a DataFrame (df) where the value in the 'TotalCharges' column is an empty string (" ").
Replacing Empty Spaces in 'TotalCharges' Column with NaN in Pandas DataFrame
df['TotalCharges']=df['TotalCharges'].replace(" ",np.nan)
Calculating the Mean of 'TotalCharges' in a Pandas DataFrame
mean_total_charges = np.mean(df['TotalCharges'])
Identifying and Counting Missing Values in Each Column of a Pandas DataFrame
df.isnull().sum()
sns.heatmap(df.isnull())
df[column_name].isnull().sum()
df['Age'].isnull().sum()
Determining the Number of Unique Values in the 'quality' Column of a Pandas DataFrame
df['quality'].nunique() ==single col how many unique value
Counting the Occurrences of Each Unique Value in the 'quality' Column of a Pandas DataFrame
df['quality'].value_counts() ===each value of col how many unique value
column_name = '0.00.1'
value_counts = df[column_name].value_counts()
Counting the Number of Unique Values in Each Column of a Pandas DataFrame and Creating a 'No of Unique Frame
df.nunique().to_frame("no of unique frame") all col how many unique value
Summary Analysis of a Pandas DataFrame
df.describe() == to show mean,median,std dev
set_index() to Set the Date Column as the Index in a Pandas DataFrame"
df.set_index('Date', inplace=True)==> set date as index value
The set_index() function is used to set the DataFrame index using existing columns.
Removing 'Close' and 'Customer_id' Columns for Train-Test Split in a Pandas DataFrame
df.drop(['Close'], axis=1, inplace=True)
df.drop(['Customer_id'], axis=1, inplace=True)
Removing spacechar
df1 = df[df.TotalCharges != ' ']
Identifying Rows Without Spaces
df[df.TotalCharges != ' '].shape
(7032, 20)
checking single rows of particular column
df.iloc[488].TotalCharges
conversion of string to numeric
df[pd.to_numeric(df.TotalCharges,errors='coerce').isnull()]
reference
Exploring Duplicate Rows in a Pandas DataFrame
df.duplicated().sum()
print("shapes are:",x.shape)
print("shapes are:",y.shape)
duplicate_rows = df[df.duplicated()]
print(duplicate_rows)
# Assuming df is your DataFrame
all_duplicate_rows = df[df.duplicated(keep=False)]
print(all_duplicate_rows)
df.drop_duplicates(inplace=True)
The df.corr() function computes the correlation matrix, providing insights into relationships between variables
df_corr=df.corr()
df_corr
# Calculate the correlation between columns
correlation = df['YearsOld'].corr(df['Income'])
write a code to print occurance of particular value in particular colunm
column_name = '0.00.1'
value_counts = df[column_name].value_counts()
# Print the count of occurrences of value 6
if 0.00 in value_counts.index:
count_of_6 = value_counts.loc[0.00]
print(f"Count of value 6 in {column_name}: {count_of_6}")
else:
print(f"Value 6 not found in {column_name}")
# Convert the DataFrame to a NumPy array
numpy_array = df.to_numpy()
Counting the Unique Values in Each Column of a Pandas DataFrame"
for i in df.columns:
print(df[i].value_counts())
print("\n")
Calculating Column-wise Sums in a Pandas DataFrame
for i in df.columns:
print(df[i].sum())
print("\n")
Summing Values and Listing Them Column-wise in a Pandas DataFrame
column_sums_list = []
for i in df.columns:
print(df[i].sum())
print("\n")
column_sum = df[i].sum()
column_sums_list.append(column_sum)
print("List of Column Sums:")
print(column_sums_list)
Creating Key-Value Pairs for Summed Values in Each Column of a Pandas DataFrame"
column_sums_list = []
for i in df.columns:
print(df[i].value_counts())
print("\n")
column_sum = df[i].sum()
column_sums_list.append({'Column': i, 'Sum': column_sum})
column_sums_list
Summing Values, Creating Key-Value Pairs, and Listing Them in a Pandas DataFrame
column_sums_list = []
for i in df.columns:
print(df[i].sum())
print("\n")
column_sum = df[i].sum()
column_sums_list.append({'Column': i, 'Sum': column_sum})
print("List of Column Sums:")
print(column_sums_list)
Creating a New Dataset with Sum and Max Values for Each Column
column_sums_list = []
for i in df.columns:
print(df[i].value_counts())
print("\n")
column_sum = df[i].sum()
column_sums_list.append({'Column': i, 'Sum': column_sum})
column_sums_list
data = {
'A': [1, 2, 3, 4],
'B': [5, 6, 7, 8],
'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)
column_max_list = []
for i in df.columns:
print(df[i].value_counts())
print("\n")
column_sum = df[i].max()
column_max_list.append({'Column': i, 'max': column_sum})
column_max_list
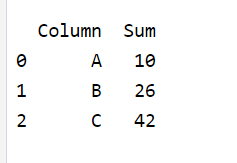
column_sums_df = pd.DataFrame(column_sums_list)
# Display the DataFrame
print(column_sums_df)
Exploring Different Join Operations on Pandas DataFrames
different-method-to-combine-the-dataframe-in-pandas
df_sums = pd.DataFrame(column_sums_list)
df_max = pd.DataFrame(column_max_list)
df_result = pd.merge(df_sums, df_max, on='Column')
df_result
Creating and Renaming Columns in a Pandas DataFrame
# Create a new column by combining existing columns
df['FullName'] = df['Name'] + ' (' + df['Department'] + ')'
# Rename columns in the DataFrame
df.rename(columns={'Age': 'YearsOld', 'Salary': 'Income'}, inplace=True)
Calculating Mean and Median in a Pandas DataFrame
mean_age = data['Age'].mean()
median_salary = data['Salary'].median()
Merging and Concatenating DataFrames:
different-method-to-combine-the-dataframe-in-pandas
df_new=pd.concat([df,df_max],axis=1)
df_new
x=df.drop(['diagnosis'], axis=1)
list(x.columns)
df_colunms=pd.DataFrame(x.columns)
df_scores=pd.DataFrame(fit.scores)//selecy k feature in KNN folder
feature_score=pd.concat([df_columns,df_scores],axis=1)
df_new
Grouping and Aggregating Data in a Pandas DataFrame
df = pd.DataFrame({'A': ['foo', 'bar', 'foo', 'bar', 'foo', 'bar'],
'B': [1, 2, 3, 4, 5, 6]})
grouped = df.groupby('A').sum()
print(grouped)
Combining Columns and Calculating Scores in a Pandas DataFrame
to conncatenate more than one colunm
result = df1.join(df2)
df_new = pd.concat([df_new, df_columns1, df_columns2, df_columns3, df_scores1, df_scores2, df_scores3], axis=1)
Conditional Column Summation: Using If-Else Conditions in Pandas DataFrame
DataFrame Column Sum Analysis with Threshold
you can apply if-else condition also
column_sums_list = []
for i in df.columns:
print(df[i].value_counts())
print("\n")
column_sum = df[i].sum()
if column_sum > 4000:
column_sums_list.append({'Column': i, 'Sum': column_sum})
column_sums_list
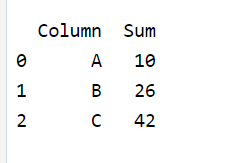
column_sums_df = pd.DataFrame(column_sums_list)
# Display the DataFrame
print(column_sums_df)
output
Identifying Categorical and Numerical Columns in a Pandas DataFrame
categorical_col = []
for i in df.dtypes.index:
if df.dtypes[i] == "object":
categorical_col.append(i)
print("Categorical Columns: ", categorical_col)
print("\n")
#Checking for Numerical columns
numerical_col = []
for i in df.dtypes.index:
if df.dtypes[i]!="object":
numerical_col.append(i)
print("Numerical Columns:", numerical_col)
Utilizing the StandardScaler to Standardize Features in a Pandas
Applying Standard Scaling to Ensure Standardized Mean and Deviation for Each Feature
from sklearn.preprocessing import StandardScaler
# Create an instance of the StandardScaler
scaler = StandardScaler()
x=pd.DataFrame(scaler.fit_transform(x),columns=x.columns)
x
Calculating VIF to Assess Multicollinearity Among Features"
"Utilizing Statsmodels and Scikit-Learn for VIF Computation in Regression Analysis
vif = pd.DataFrame()
# Iterate through each column index in x
for i in range(len(x.columns)):
# Calculate VIF for each feature
vif_value = variance_inflation_factor(x.values, i)
# Append VIF value and feature name to the DataFrame
vif = vif.append({'VIF': vif_value, 'Features': x.columns[i]}, ignore_index=True)
# Display the resulting DataFrame
print(vif)
from statsmodels.stats.outliers_influence import variance_inflation_factor
from sklearn.linear_model import LinearRegression
vif = pd.DataFrame()
vif['VIF'] = [variance_inflation_factor(x.values, i) for i in range(len(x.columns))]
vif['Features'] = x.columns
vif
Applying Z-Score Method to Identify and Filter Outliers in Feature Columns"
"Eliminating Data Points with Z-Score Greater than 3 for Improved Data Quality
out_features=df[['fixed acidity', 'volatile acidity', 'citric acid', 'residual sugar',
'chlorides', 'free sulfur dioxide', 'total sulfur dioxide', 'density',
'pH', 'sulphates', 'alcohol']]
z = np.abs(zscore(out_features))
z
np.where(z>3)
df1 = df[(z < 3).all(axis=1)]
df1.shape
Utilizing Interquartile Range (IQR) to Identify and Remove Outliers"
"Applying IQR Method to Enhance Data Quality by Filtering Unusual Data Points"
Q1 = out_features.quantile(0.25)
Q3 = out_features.quantile(0.75)
IQR = Q3 - Q1
# Identify and remove outliers using IQR
df2 =df[~((df < (Q1 - 1.5 * IQR)) | (df > (Q3 + 1.5 * IQR))).any(axis=1)]
Q1
Q3
Assessing the Percentage of Data Loss After Outlier Handling"
"Quantifying Impact on Data Size Following Outlier Treatment
data_loss_percentage = ((df.shape[0] - df1.shape[0]) / df.shape[0]) * 100
data_loss_percentage
Cheatsheet
df=df[df['price'] > 1000]
df=df[df['price'] < 2500]
df=df.drop('Unnamed: 0', axis=1)
row_data = df.iloc[859:888]
df.iloc[10,:]
df.loc[df['TotalCharges']==" "] is used to filter rows in a DataFrame (df) where the value in the 'TotalCharges' column is an empty string (" ").
df['TotalCharges']=df['TotalCharges'].replace(" ",np.nan)
mean_total_charges = np.mean(df['TotalCharges'])
df.isnull().sum()
df['Age'].isnull().sum()
df['quality'].nunique()
df['quality'].value_counts()
df[i].sum()
column_sums_list.append({'Column': i, 'Sum': column_sum})
df_result = pd.merge(df_sums, df_max, on='Column')
median_salary = data['Salary'].median()
grouped = df.groupby('A').sum()
df.rename(columns={'Age': 'YearsOld', 'Salary': 'Income'}, inplace=True)
Summary
Check Total no row and colunm
Display First 10 rows
Add new col in existing
Display last 5rows
Display all colunm name
Filtering a Pandas DataFrame in Python to Select Rows with Prices Between $1000 and $2500
drop Unnamed colunm from existing dataset
Display particular range of row
select particular row all columns
display colunm data type
Fill null value through mean,median and mode
Display or filter rows in a DataFrame (df) where the value in the 'TotalCharges' column is an empty string (" ")
Replacing Empty Spaces in 'TotalCharges' Column with NaN in Pandas DataFrame
Calculating the Mean of 'TotalCharges' in a Pandas DataFrame
Identifying and Counting Missing Values in Each Column of a Pandas DataFrame
Identifying and Counting Missing Values in particular Column of a Pandas DataFrame
Determining the Number of Unique Values in the 'quality' Column of a Pandas DataFrame
Counting the Occurrences of Each Unique Value in the 'quality' Column of a Pandas DataFrame
Summary Analysis of a Pandas DataFrame
set_index() to Set the Date Column as the Index in a Pandas DataFrame"
Removing 'Close' and 'Customer_id' Columns for Train-Test Split in a Pandas DataFrame
print occurance of particular value in particular colunm
Counting the Unique Values in Each Column of a Pandas DataFrame
Creating a New Dataset with Sum and Max Values for Each Column
=========================or===========================
Creating a New Dataset with mean and median Values for Each Column
DataFrame Column Sum Analysis with Threshold

Top comments (0)