AI Agent using Keras (High-level, user-friendly)
AI Agent using TensorFlow (Low-level, more control)
Simple NLP AI Agent (Intent Classification Example)
Steps to Integrate Your AI Agent into a RAG System
Building and Integrating the AI Agent with Keras/TensorFlow NLP
Build AI agent for software developer
AI Agent using Keras (High-level, user-friendly)
Goal: Text Sentiment Classification Agent (positive/negative)
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
# Example: Fake tiny dataset
texts = ["I love Traccar!", "This is bad", "I am happy", "Terrible experience"]
labels = [1, 0, 1, 0] # 1=positive, 0=negative
# Text vectorization (real job: use Tokenizer; here, just one-hot for illustration)
tokenizer = keras.preprocessing.text.Tokenizer(num_words=1000)
tokenizer.fit_on_texts(texts)
X = tokenizer.texts_to_matrix(texts, mode='binary')
# Build Model
model = keras.Sequential([
layers.Dense(16, activation='relu', input_shape=(X.shape[1],)),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train
model.fit(X, np.array(labels), epochs=10)
# Inference as "AI Agent"
def ai_agent_keras(text):
vec = tokenizer.texts_to_matrix([text], mode='binary')
pred = model.predict(vec)
print("Positive" if pred[0,0] > 0.5 else "Negative")
ai_agent_keras("I love this!") # Should print Positive
ai_agent_keras("Awful product") # Should print Negative
================ANOTHER EXAMPLE============================
Steps to Create an AI Agent Using Keras, TensorFlow, and NLP
Text Preprocessing: Tokenize the input text and prepare it for modeling.
Model Training: Train a model (such as an LSTM or Transformer) to process the input text and make predictions or decisions.
Response Generation: Use the trained model to generate responses based on the input.
Text Preprocessing with TensorFlow and Keras
Before we can train the model, we need to process the text data (tokenization, padding, etc.).
Code Example: Text Preprocessing
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# Sample text data (queries)
texts = [
"How can I reset my password?",
"What is the weather today?",
"Tell me about the latest news.",
"How do I fix error X in my software?"
]
# Step 1: Tokenize the text data
tokenizer = Tokenizer()
tokenizer.fit_on_texts(texts)
# Convert texts to sequences (integer representations of words)
sequences = tokenizer.texts_to_sequences(texts)
# Step 2: Padding the sequences to ensure uniform input size
max_len = max([len(seq) for seq in sequences]) # Find the longest sequence length
X = pad_sequences(sequences, maxlen=max_len, padding='post')
print("Tokenized Sequences:", sequences)
print("Padded Sequences:", X)
Explanation:
Tokenizer: Converts text into integer sequences, where each word is mapped to an integer.
pad_sequences: Ensures all sequences are of the same length, padding shorter sequences with zeros.
Model Training with TensorFlow and Keras (LSTM Example)
Next, we will define a simple model using an LSTM (Long Short-Term Memory) layer, a common choice for sequence-based problems in NLP.
Code Example: Model Training (LSTM)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
# Step 1: Define the model
model = Sequential()
# Embedding layer: Converts input words (integer sequences) to dense vectors
model.add(Embedding(input_dim=len(tokenizer.word_index) + 1, output_dim=64, input_length=X.shape[1]))
# LSTM layer: Processes the sequence data
model.add(LSTM(64, return_sequences=False))
# Dense layer: Outputs the final predictions (e.g., for classification or regression)
model.add(Dense(1, activation='sigmoid')) # For binary classification (0 or 1)
# Step 2: Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Step 3: Train the model (for simplicity, let's assume labels are binary)
y = [0, 1, 1, 0] # Sample binary labels for classification (e.g., intent classification)
model.fit(X, y, epochs=5)
# Step 4: Evaluate the model (optional)
loss, accuracy = model.evaluate(X, y)
print(f"Loss: {loss}, Accuracy: {accuracy}")
Explanation:
Embedding Layer: Turns words into fixed-length dense vectors.
LSTM Layer: Processes sequential data, capturing temporal dependencies.
Dense Layer: Outputs the final prediction (binary classification in this case).
Response Generation with the Trained Model
Once the model is trained, we can use it to generate or classify responses. For a more sophisticated agent, you could use a Transformer model (like BERT or GPT) for response generation, but for simplicity, let’s keep it with our LSTM model, which can classify user queries into predefined categories (e.g., "password reset", "weather", etc.).
Code Example: Response Generation
# Define a simple function to classify new inputs (queries)
def classify_query(query):
# Tokenize and pad the input text just like we did with training data
seq = tokenizer.texts_to_sequences([query])
padded_seq = pad_sequences(seq, maxlen=max_len, padding='post')
# Get the prediction from the model
prediction = model.predict(padded_seq)
# Return the response based on the prediction
if prediction > 0.5:
return "This query is related to software issues."
else:
return "This query is related to account management."
**Test the AI Agent with new queries**
query = "How can I reset my password?"
response = classify_query(query)
print("Query:", query)
print("Response:", response)
Explanation:
classify_query(): Tokenizes and pads the new input query, then uses the trained model to predict the category of the query.
The response is based on the output of the model (in this case, binary classification: software issues vs. account management).
Full Working Example: AI Agent for FAQ
You can combine these steps to create an AI agent capable of answering questions based on predefined knowledge (FAQs).
Full Example:
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# Sample FAQs
texts = [
"How can I reset my password?",
"What is the weather today?",
"Tell me about the latest news.",
"How do I fix error X in my software?"
]
# Labels (0 = Account Management, 1 = Software Issues)
labels = [0, 1, 1, 0] # Example labels
# Preprocess the text data
tokenizer = Tokenizer()
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
X = pad_sequences(sequences, padding='post')
# Build the model
model = Sequential()
model.add(Embedding(input_dim=len(tokenizer.word_index) + 1, output_dim=64, input_length=X.shape[1]))
model.add(LSTM(64, return_sequences=False))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
model.fit(X, np.array(labels), epochs=5)
# Query classifier function
def classify_query(query):
seq = tokenizer.texts_to_sequences([query])
padded_seq = pad_sequences(seq, maxlen=X.shape[1], padding='post')
prediction = model.predict(padded_seq)
if prediction > 0.5:
return "Software Issue"
else:
return "Account Management"
# Test the AI agent
new_query = "How do I reset my password?"
response = classify_query(new_query)
print(f"Query: {new_query}")
print(f"Response: {response}")
CONCLUSION
Text Preprocessing: We preprocess the text data using Keras' Tokenizer and pad_sequences.
Model Training: We built a simple LSTM model with Keras/TensorFlow to classify queries.
Response Generation: The AI agent uses the trained model to predict the class of new queries and generate appropriate responses.
AI Agent using TensorFlow (Low-level, more control)
Goal: Simple neural net text classifier (manual graph building)
import tensorflow as tf
import numpy as np
# One-hot encode fake data for simplicity
X = np.array([[1,0,0,0],[0,1,0,0],[1,0,0,0],[0,1,0,0]]) # 4 samples, 4 fake features
y = np.array([[1],[0],[1],[0]]) # labels: positive/negative
# Build model (lower-level API)
inputs = tf.keras.Input(shape=(4,))
x = tf.keras.layers.Dense(8, activation='relu')(inputs)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train
model.fit(X, y, epochs=10)
# "Agent" function: single prediction
def ai_agent_tf(x):
x = np.array([x])
prob = model.predict(x)[0,0]
print("Positive" if prob > 0.5 else "Negative")
# Example usage
ai_agent_tf([0,1,0,0]) # Should print Negative.
ai_agent_tf([1,0,0,0]) # Should print Positive.
Simple NLP AI Agent (Intent Classification Example)
With TensorFlow/Keras + NLP Preprocessing:
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras import layers, Sequential
import numpy as np
# Example: Intents - "greet" vs "bye"
sentences = ["hi there", "hello", "goodbye", "bye now"]
labels = [0, 0, 1, 1] # 0=greet, 1=bye
# Tokenize/Vectorize text
tokenizer = Tokenizer(num_words=50, oov_token="<OOV>")
tokenizer.fit_on_texts(sentences)
sequences = tokenizer.texts_to_sequences(sentences)
X = pad_sequences(sequences, maxlen=4)
y = np.array(labels)
# Build intent classifier
model = Sequential([
layers.Embedding(input_dim=50, output_dim=8, input_length=4),
layers.Flatten(),
layers.Dense(8, activation='relu'),
layers.Dense(2, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(X, y, epochs=20, verbose=0)
# Inference as intent agent
def nlp_ai_agent(text):
seq = tokenizer.texts_to_sequences([text])
padded = pad_sequences(seq, maxlen=4)
intent = np.argmax(model.predict(padded), axis=1)[0]
if intent == 0:
print("Recognized intent: GREET")
else:
print("Recognized intent: BYE")
nlp_ai_agent("hello") # Recognized intent: GREET
nlp_ai_agent("goodbye") # Recognized intent: BYE
Summary
Keras Example: Build SSO-ready text classifier “agent” with high-level code and simple API.
TensorFlow Example: Same task, but with more manual (low-level) model setup.
NLP Agent Example: How to recognize intents ("greet" vs "bye") from user input.
Steps to Integrate Your AI Agent into a RAG System
Here’s how you can create and integrate an AI agent using Keras and TensorFlow into a RAG system:
Create a Retrieval System: Use a system like FAISS, Elasticsearch, or a simple database query system to fetch relevant information based on the user's query.
Use the AI Agent (Your LSTM Model): Your AI agent can act as the generator that takes the retrieved data and the query as input to produce a response.
Integrate the Components: Combine the retrieval and generation steps to build a complete RAG-based AI Agent.
Set Up the Retrieval System (Using FAISS for simplicity)
We will use a vector store (FAISS in this case) to retrieve relevant information based on the query.
Install FAISS and Langchain:
pip install faiss-cpu
pip install langchain
Create FAISS Index: Here, we will index a list of documents, and then we will retrieve relevant ones based on the query.
import faiss
import numpy as np
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
import openai
# Example knowledge base (documents)
docs = [
"How to reset my password?",
"What are the steps to fix error X?",
"Tell me about the latest news in tech.",
"How do I delete my account in the software?"
]
# Preprocess documents with Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(docs)
sequences = tokenizer.texts_to_sequences(docs)
X = pad_sequences(sequences, padding='post')
# Initialize FAISS and embeddings
embeddings = OpenAIEmbeddings() # You could use OpenAI embeddings or your own
faiss_index = FAISS.from_documents(docs, embeddings)
# Define LSTM Model (Simple for demonstration)
model = Sequential()
model.add(Embedding(input_dim=len(tokenizer.word_index) + 1, output_dim=64, input_length=X.shape[1]))
model.add(LSTM(64, return_sequences=False))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
LLM Model (Your AI Agent)
We can integrate the trained AI agent (the LSTM model) as a generator that processes the query along with the retrieved documents. The LSTM model here could generate a more accurate and context-aware response based on the retrieved information.
# Train the LSTM model on predefined queries
labels = [0, 1, 1, 0] # Example labels (you can use your own dataset)
model.fit(X, np.array(labels), epochs=5)
# Query function to classify and generate response
def generate_response(query):
# Tokenize and pad query similar to the training data
seq = tokenizer.texts_to_sequences([query])
padded_seq = pad_sequences(seq, maxlen=X.shape[1], padding='post')
# Get the prediction from the model
prediction = model.predict(padded_seq)
if prediction > 0.5:
return "This query is related to software issues."
else:
return "This query is related to account management."
Combine Retrieval and Generation (RAG)
Now, we combine both the retrieval and generation steps to create a RAG-based system. The user query will be processed by the retrieval system first, and then the generative AI agent (your LSTM model) will generate a response based on the query and retrieved documents.
from langchain.chains import RetrievalQA
# Create RetrievalQA chain with the FAISS index and LSTM model for response generation
qa_chain = RetrievalQA.from_chain_type(llm=model, chain_type="stuff", retriever=faiss_index.as_retriever())
# Define the full RAG system
def rag_system(query):
# Retrieve relevant documents
relevant_docs = faiss_index.similarity_search(query, k=1) # Top 1 relevant document
# Generate a response based on the retrieved document and query
response = generate_response(query + " " + relevant_docs[0].page_content)
return response
# Test the RAG system with a query
user_query = "How do I reset my password?"
response = rag_system(user_query)
print("Response:", response)
Explanation of the RAG Integration:
FAISS Index: The vector store (FAISS) is used to retrieve the most relevant document(s) from a pre-existing knowledge base based on the user's query.
AI Agent (LSTM): Your AI agent (the LSTM model) processes the query and the retrieved documents to generate an accurate response.
RAG System: The RetrievalQA chain handles the flow of retrieving documents and generating the response, integrating both the retrieval and generation parts to form a complete RAG-based system.
+-------------------------+
| User Query |
| (e.g., "How to reset |
| my password?") |
+-------------------------+
|
v
+-------------------------+
| FAISS Retrieval System |
| (Retrieve Relevant Docs)|
+-------------------------+
|
v
+-------------------------+
| LSTM Model (AI Agent) |
| (Generate Contextual |
| Response) |
+-------------------------+
|
v
+-------------------------+
| Generated Response |
| (e.g., "Here is how |
| you reset your password.") |
+-------------------------+
Building and Integrating the AI Agent with Keras/TensorFlow NLP
Step 1: Preprocessing Text Data
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# Sample dataset (user queries)
texts = [
"How do I reset my password?",
"Tell me about the weather today",
"What is the latest news on technology?",
"How do I troubleshoot error code X?"
]
# Tokenizing the texts
tokenizer = Tokenizer()
tokenizer.fit_on_texts(texts)
# Convert texts to sequences of integers
sequences = tokenizer.texts_to_sequences(texts)
# Padding sequences to make them the same length
X = pad_sequences(sequences, padding='post')
print("Tokenized Sequences:", sequences)
print("Padded Sequences:", X)
Step 2: Building the Transformer Model
For an advanced model, we can use a Transformer architecture. A simple Transformer-based model with attention layers can process sequential data like user queries.
from tensorflow.keras.layers import Input, Dense, Embedding, MultiHeadAttention, LayerNormalization, Dropout
from tensorflow.keras.models import Model
def transformer_encoder(input_seq, embedding_size=64, num_heads=2, ff_dim=128):
# Multi-Head Attention layer
attention = MultiHeadAttention(num_heads=num_heads, key_dim=embedding_size)(input_seq, input_seq)
attention = LayerNormalization()(attention)
# Feed Forward Neural Network layer
ff = Dense(ff_dim, activation='relu')(attention)
ff = Dropout(0.1)(ff)
ff = Dense(embedding_size)(ff)
return ff
# Build the model
input_seq = Input(shape=(X.shape[1],))
embedding = Embedding(input_dim=len(tokenizer.word_index)+1, output_dim=64)(input_seq)
encoded = transformer_encoder(embedding)
output = Dense(1, activation='sigmoid')(encoded)
model = Model(inputs=input_seq, outputs=output)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model (assuming binary labels)
y = [0, 1, 1, 0] # Sample binary labels (0 = password, 1 = tech issue)
model.fit(X, y, epochs=5)
Explanation:
Tokenizer: We convert text into integer sequences for input into the model.
Transformer Encoder: A Transformer encoder layer that applies multi-head attention followed by a feed-forward network for processing the sequence.
Model Output: The model outputs a binary classification for simplicity (e.g., password issue or tech issue).
Set Up the Retrieval System
We'll use FAISS (Facebook AI Similarity Search), which is a vector database, to store and retrieve relevant documents based on user queries.
pip install faiss-cpu langchain
Step 3: Initialize FAISS for Document Retrieval
We need to store documents and use FAISS to find the most relevant documents.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
# Example knowledge base (documents)
docs = [
"How to reset my password?",
"Troubleshoot error X by checking the log files.",
"Tech news: New breakthroughs in AI.",
"How to fix database connection issues."
]
# Create FAISS index with OpenAI Embeddings
embeddings = OpenAIEmbeddings()
faiss_index = FAISS.from_documents(docs, embeddings)
# Setup Langchain's RetrievalQA system
qa_chain = RetrievalQA.from_chain_type(llm=model, chain_type="stuff", retriever=faiss_index.as_retriever())
Explanation:
FAISS is used to convert documents into embeddings (dense vector representations).
OpenAIEmbeddings converts documents into vectors.
RetrievalQA is used to handle the retrieval of documents and pass them to the generative model for response generation.
Combine the Retrieval System with LLM (Language Model)
Now, we'll combine the retrieval system with the Transformer-based AI Agent to create an advanced AI that can both retrieve relevant data and generate responses.
Step 4: Integrate the Retrieval and LLM Systems
The retrieval system pulls relevant documents, and then the AI model generates responses based on both the query and the retrieved documents.
# Define the RAG system
def rag_system(query):
# Retrieve relevant documents
relevant_docs = faiss_index.similarity_search(query, k=1) # Retrieve top 1 document
# Generate a response using the AI model with retrieved docs as context
response = generate_response(query + " " + relevant_docs[0].page_content)
return response
# Example query
user_query = "How do I reset my password?"
response = rag_system(user_query)
print("Response:", response)
Explanation:
FAISS Retrieval: We retrieve the most relevant document(s) using the FAISS index.
Generate Response: The retrieved document is concatenated with the query, and passed to the AI agent (e.g., Transformer or LSTM model) to generate the final response.
Architecture Diagram for the Complete RAG/LLM AI Agent
+-------------------------+
| User Query |
| (e.g., "How to reset |
| my password?") |
+-------------------------+
|
v
+-------------------------+
| FAISS Retrieval System |
| (Retrieve Relevant Docs)|
+-------------------------+
|
v
+-------------------------+
| Transformer Model (AI |
| Agent) |
| (Generate Response) |
+-------------------------+
|
v
+-------------------------+
| Generated Response |
| (e.g., "Here is how |
| you reset your password.") |
+-------------------------+
Conclusion
Text Preprocessing: Tokenize and pad the input data.
Transformer Model: We use an advanced Transformer-based model for generating responses based on queries and retrieved documents.
FAISS Retrieval: A vector database like FAISS is used for fast document retrieval.
RAG System: The RAG architecture combines retrieval and generation to build powerful AI agents that can process and generate responses based on real-time data.
Integration: The retrieved data and query are passed together to a Transformer model for context-aware response generation.
-------------------------Another Example-----------------------
Preprocessing User Queries
Before feeding user queries into the model, you need to preprocess the input (tokenize, pad the sequences).
# Sample user queries
user_queries = [
"How do I reset my password?",
"How can I fix error X?",
"What is the weather like today?"
]
# Preprocessing the input queries like we did during model training
tokenizer = Tokenizer()
tokenizer.fit_on_texts(user_queries) # Fit the tokenizer to the user queries
# Convert text to sequences
user_sequences = tokenizer.texts_to_sequences(user_queries)
# Pad the sequences to make sure all are of the same length
user_padded_sequences = pad_sequences(user_sequences, maxlen=X.shape[1], padding='post')
Predict User Query Labels Using the Trained Model
Once you have the model trained and the user query preprocessed, you can use the trained LSTM model to predict the query label.
# Predict the label of a new query
def classify_user_query(query):
# Tokenize and pad the user query just like we did with training data
user_seq = tokenizer.texts_to_sequences([query])
user_padded_seq = pad_sequences(user_seq, maxlen=X.shape[1], padding='post')
# Get the prediction from the trained model
prediction = model.predict(user_padded_seq)
# Classify based on the output
if prediction > 0.5:
return "This query is related to tech issues."
else:
return "This query is related to account management."
# Test the model with new queries
for query in user_queries:
response = classify_user_query(query)
print(f"Query: {query}")
print(f"Response: {response}")
Integration with the RAG (Retrieval-Augmented Generation) System
Now, you can integrate the query classification process with the RAG (Retrieval-Augmented Generation) system. The retrieval system can pull the relevant information based on the query type (determined by the AI agent) and then generate a response using the retrieved data.
Example Integration with RAG:
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
# FAISS index (the knowledge base) for document retrieval
docs = [
"Reset password by clicking the 'Forgot Password' link on the login page.",
"For error X, try restarting the system or reinstalling the software.",
"Latest news: AI is changing the tech industry.",
"Account deletion is available in the 'Account Settings' section."
]
# Initialize embeddings and FAISS index
embeddings = OpenAIEmbeddings()
faiss_index = FAISS.from_documents(docs, embeddings)
# Create a function to handle the retrieval and generation process
def rag_system(query):
# Classify the query
response_type = classify_user_query(query)
# Retrieve relevant document(s) based on the query classification
relevant_docs = faiss_index.similarity_search(query, k=1) # Retrieve top 1 document
# Generate a response using the AI model with the retrieved data as context
response = f"Response Type: {response_type} - Based on the query, I suggest the following: {relevant_docs[0].page_content}"
return response
# Test the RAG system with a user query
user_query = "How can I fix error X?"
response = rag_system(user_query)
print("Final Response:", response)
----------full code-----------------
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
# Step 1: Sample Training Data (text queries and labels)
texts = ["How do I reset my password?", "How do I fix error X?", "What is the weather today?", "How to delete my account?"]
labels = [0, 1, 0, 0] # 0 = Account management, 1 = Tech issue
# Tokenize the texts
tokenizer = Tokenizer()
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
X = pad_sequences(sequences, padding='post')
# Step 2: Build the LSTM Model (Simple for demonstration)
model = Sequential()
model.add(Embedding(input_dim=len(tokenizer.word_index)+1, output_dim=64, input_length=X.shape[1]))
model.add(LSTM(64, return_sequences=False))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
model.fit(X, np.array(labels), epochs=5)
# Step 3: Preprocess the User Queries
user_queries = ["How do I reset my password?", "How can I fix error X?", "Tell me the weather."]
def classify_user_query(query):
user_seq = tokenizer.texts_to_sequences([query])
user_padded_seq = pad_sequences(user_seq, maxlen=X.shape[1], padding='post')
prediction = model.predict(user_padded_seq)
return "Tech issue" if prediction > 0.5 else "Account management"
# Step 4: Initialize the Retrieval System (FAISS)
docs = [
"Reset your password by going to the password reset page.",
"For error X, try uninstalling and reinstalling the software.",
"Check the weather today through our weather app.",
"To delete your account, go to Account Settings > Delete Account."
]
embeddings = OpenAIEmbeddings()
faiss_index = FAISS.from_documents(docs, embeddings)
# Step 5: RAG System to Handle Query and Generate Response
def rag_system(query):
# Classify query type
response_type = classify_user_query(query)
# Retrieve relevant documents using FAISS
relevant_docs = faiss_index.similarity_search(query, k=1)
# Generate a response
return f"Response Type: {response_type} - Here is the information you need: {relevant_docs[0].page_content}"
# Step 6: Test the RAG System
user_query = "How do I fix error X?"
response = rag_system(user_query)
print("Final Response:", response)
-----------------------Another Example------------------------------
#=== STEP 1: Import Required Libraries ===#
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, Flatten
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from flask import Flask, request, jsonify
#=== STEP 2: Prepare Example Data ===#
# We'll use simple intent classification: greeting vs goodbye
texts = [
"hello", "hi", "good morning", "hey",
"bye", "goodbye", "see you", "farewell"
]
labels = [0, 0, 0, 0, 1, 1, 1, 1] # 0: greet, 1: bye
# Tokenize text and convert to sequences
tokenizer = Tokenizer(num_words=100, oov_token="<OOV>")
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
X = pad_sequences(sequences, maxlen=4)
y = np.array(labels)
#=== STEP 3: Build and Train the Keras NLP Model ===#
model = Sequential([
Embedding(input_dim=100, output_dim=8, input_length=4),
Flatten(),
Dense(16, activation='relu'),
Dense(2, activation='softmax') # 2 classes: greet or bye
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(X, y, epochs=30, verbose=0) # silent, but you can set verbose=1
#=== STEP 4: AI Agent Inference Function ===#
def ai_intent_agent(text):
seq = tokenizer.texts_to_sequences([text])
padded = pad_sequences(seq, maxlen=4)
pred = np.argmax(model.predict(padded), axis=1)[0]
# 0 = greet, 1 = bye
return 'greeting' if pred == 0 else 'goodbye'
#=== STEP 5: Dummy RAG Retrieval Function ===#
def rag_retrieve(query):
# Simulate a retrieval from a document knowledge base
# In a real app, use a vector database or search engine
return "No relevant document found (simulated)."
#=== STEP 6: Dummy LLM Reply Function ===#
def llm_generate(context, query):
# In real RAG/LLM, send this to an LLM API (e.g., OpenAI, HuggingFace)
# Here, just echo the information
return f"LLM Response (simulated): Based on your input '{query}', and context '{context}'."
#=== STEP 7: Build a Simple Flask API App ===#
app = Flask(__name__)
@app.route('/ask', methods=['POST'])
def ask():
user_query = request.json.get('query', "")
# 1. Run AI agent to get intent
intent = ai_intent_agent(user_query)
# 2. Route or enrich based on intent
if intent == 'greeting':
return jsonify({'answer': "Hello! How can I help you today?"})
elif intent == 'goodbye':
return jsonify({'answer': "Goodbye! Have a nice day!"})
else:
# 3. RAG: retrieve context, then call LLM to generate answer
context = rag_retrieve(user_query)
answer = llm_generate(context, user_query)
return jsonify({'answer': answer})
#=== STEP 8: To Run the App ===#
# Uncomment the below to run with "python thisfile.py"
# Then send POST requests to http://localhost:5000/ask with JSON {"query": "..."}
#
# if __name__ == '__main__':
# app.run(debug=True)
#=== OPTIONAL: In-process Tests ===#
if __name__ == '__main__':
# Example: manually test agent
print("[Test] Agent intent for 'hello there':", ai_intent_agent('hello there'))
print("[Test] Agent intent for 'bye bye':", ai_intent_agent('bye bye'))
# Manually call ask endpoint logic without webserver
with app.test_client() as c:
# Greeting test
rv = c.post('/ask', json={'query': 'hi'})
print("[API] /ask 'hi' =>", rv.json)
# Bye test
rv = c.post('/ask', json={'query': 'goodbye'})
print("[API] /ask 'goodbye' =>", rv.json)
# Unrecognized/test = fallback to RAG+LLM
rv = c.post('/ask', json={'query': 'what is Traccar?'})
print("[API] /ask 'what is Traccar?' =>", rv.json)
#=== END OF FILE ===#
Build AI agent for software developer
create ai agent or agentic ai where i can detect unused variable or duplicate code of given function using LangChain + OpenAI function calling
create ai agent or agentic ai where i can optimize long function by creating multiple seprate object of function using LangChain + OpenAI function calling
create ai agent or agentic ai where i can optimize function by checking sql query using LangChain + OpenAI function calling
create ai agent or agentic ai where i can detect unused variable or duplicate code of given php file using crew ai



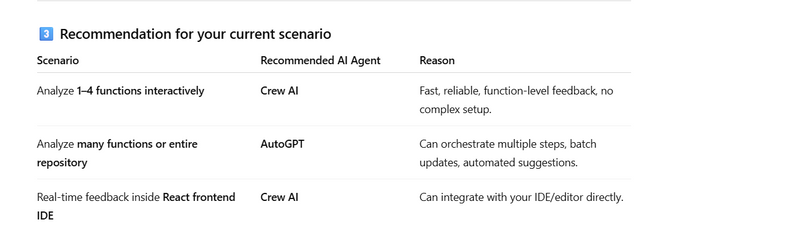

Different Approach
First Approch
# pip install langchain community-code-tools openai
from langchain_community.tools import CodeAnalysisTool # Hypothetical tool
from langchain.llms import OpenAI
from langchain.agents import initialize_agent, AgentType
# Initialize the LLM
llm = OpenAI(model="gpt-4") # Substitute with actual model/provider
# Code analysis/refactoring tool (e.g., static analysis, lint, duplicate finder)
code_tool = CodeAnalysisTool() # Hypothetical; use available community or in-house tool
# Agent setup
agent = initialize_agent(
tools=[code_tool],
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION
)
# Sample code (could be from a file or API)
code_input = """
def add(x, y):
return x + y
def sum(x, y):
return x + y
print(add(2,3))
print(sum(2,3))
"""
# Ask the agent for optimization and deduplication
result = agent.invoke(f"Optimize this Python code for performance and remove any duplicate functions:\n{code_input}")
print(result.get('output'))
Second Approach
import { CrewAI } from "crew-ai"; // Make sure you installed crew-ai SDK
import fs from "fs";
// 1️⃣ Initialize Crew AI
const crew = new CrewAI({
apiKey: process.env.CREW_API_KEY, // Set your API key in environment
});
// 2️⃣ Load PHP function(s) from a file
const phpFunction = fs.readFileSync("./confirm_booking.php", "utf-8");
// 3️⃣ Define the prompt for Crew AI
const prompt = `
You are an AI code assistant specialized in PHP and Laravel.
Task: Analyze the following function and detect:
1. Variables that are declared but never used.
2. Variables that are assigned multiple times unnecessarily (duplicate assignments).
3. Duplicate code blocks or repeated logic that can be refactored.
4. Opportunities to simplify the code or make it more efficient.
5. Highlight any potential bugs related to variables or data usage.
Function to analyze:
\`\`\`php
${phpFunction}
\`\`\`
Instructions:
- List all unused variables.
- List all duplicate assignments or code blocks.
- Suggest a refactored version of the function with clean and optimized code.
- Explain why each change is suggested.
- Output should be structured as:
1. Unused Variables: [list]
2. Duplicate Variables / Code Blocks: [list]
3. Refactoring Suggestions: [list]
4. Refactored Function Code: [full code]
Focus only on the code within the function.
`;
// 4️⃣ Send prompt to Crew AI
async function analyzeFunction() {
try {
const response = await crew.generate({
prompt,
model: "gpt-5-mini", // Or gpt-5 if you have access
temperature: 0, // deterministic output for code
});
console.log("🚀 Analysis Result:\n", response.text);
} catch (error) {
console.error("Error analyzing function:", error);
}
}
// 5️⃣ Run the agent
analyzeFunction();

Top comments (0)