Batch Processing
Stream Processing
Comparision between Hadoop and Apache Spark with respect to stream processing and batch processing
Batch Processing
Definition: Processing a large amount of data collected over a period of time, all at once.
How it works: Data is gathered (in a “batch”), processed together in scheduled jobs, and results are delivered after processing finishes.
Real-world Example
Bank Statements:
Banks collect all transactions that happened during a day. Overnight, they process them in bulk, and generate your daily account statement.
Payroll:
Employee hours are recorded over weeks; at the end of the month, payroll software processes everyone’s data in one batch to calculate salaries.
Data Analytics:
A website stores all click logs for a week. On Sunday, a batch job summarizes last week’s website usage.
Stream Processing
Definition: Processing data instantly, as it arrives.
How it works: Each piece of data (event) is handled in real time, updating results immediately.
Real-world Example
Credit Card Fraud Detection:
When a transaction is made, the bank analyzes it immediately for possible fraud (not hours later).
Live Web Analytics:
A dashboard shows exactly how many people are on a site right now, updating every second as new visits happen.
Social Media Feeds:
Twitter, Facebook, etc., update your feed instantly as new posts/tweets/videos are published.

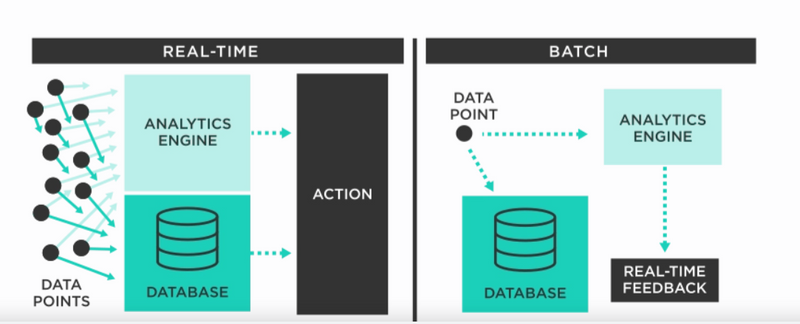
Batch Processing: Data is processed together at set times.
Stream Processing: Data is processed instantly as it comes in
Comparision between Hadoop and Apache Spark with respect to stream processing and batch processing
Hadoop and Apache Spark
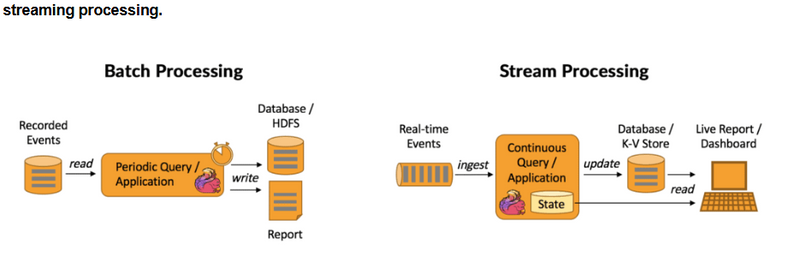
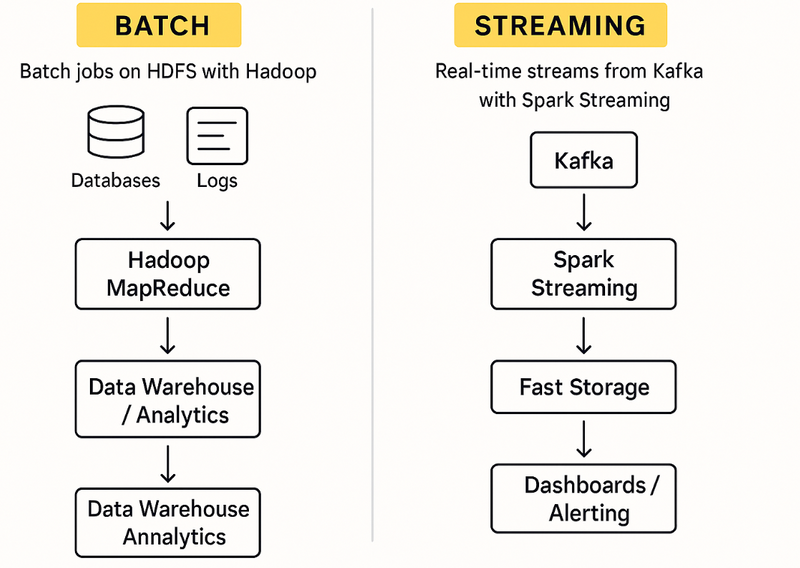
Batch Processing (Hadoop MapReduce and Spark Batch)
How It Works:
Data Sources: Data (such as logs, transactions, files) is first collected and stored—often in a distributed storage system like HDFS (Hadoop Distributed File System).
Processing Engine:
Hadoop MapReduce: Processes all the accumulated data as a “batch”—reads from HDFS, runs jobs, then writes results back to HDFS or another storage.
Apache Spark (Batch): Can also operate in batch mode, loading data from storage (HDFS, S3, databases), processing it (often much faster, in memory), then saving the summarized/processed results.
Output: The final output is available only after the whole batch job finishes.
Real Example:
Nightly Report: Every night, all sales data from the day is processed with MapReduce (or with Spark), producing a daily report the next morning.
Stream Processing (Apache Spark Streaming)
How It Works:
Data Sources: Data arrives continuously (as a “stream”), such as web server logs, financial transactions, or messages from real-time feeds (e.g., via Kafka).
Processing Engine:
Apache Spark Structured Streaming: Listens to live data streams (like Kafka topics), processes data in real time (as soon as it arrives), and updates outputs without waiting for a “batch” to finish.
Hadoop MapReduce: Does not support streaming; designed only for batch.
Output: Results are available immediately (or with very little delay), and can update dashboards, trigger alerts, or feed into other live systems.
Real Example:
Fraud Detection: As each credit card transaction arrives, Spark Streaming checks it for anomalies instantly—flagging suspicious activity in real time.


batch-processing-vs-stream-processing
what-is-the-difference-between-batch-processing-and-stream-processing
batch-processing-vs-stream-processing

Top comments (0)