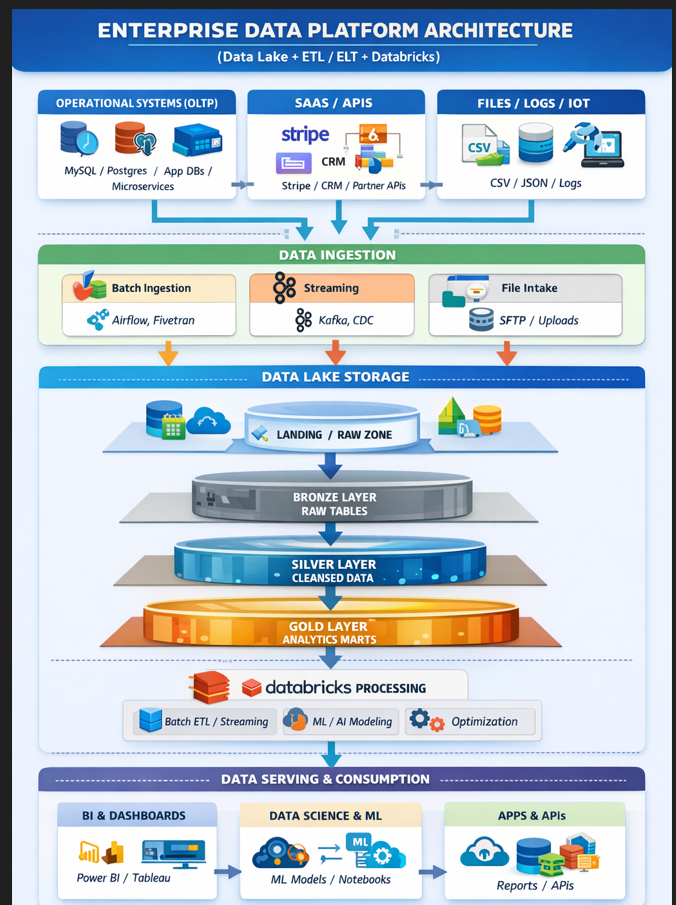
ENTERPRISE DATA PLATFORM ARCHITECTURE
End-to-End Flow Summary
What is the Ingestion Layer?
What are Data Lake Layers (Raw/Bronze/Silver/Gold)?
Where They Connect
Simple Real Example
Why We Need Both
Full Flow Visual (Conceptual)
End-to-End Steps (How It Works in Real Life)
Full Coding Example (Shows the Difference Clearly)
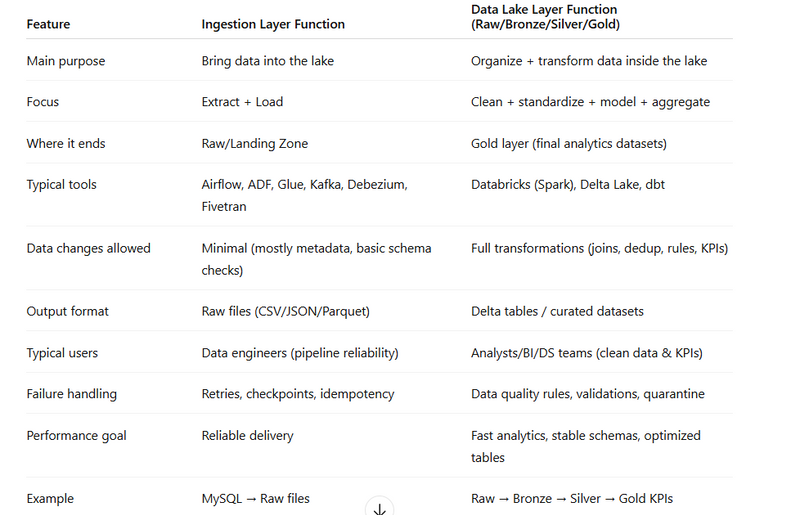
Tabular Comparison: Ingestion Layer vs Data Lake Layer Functions
Modern data platforms usually show two “layer concepts” in architecture diagrams:
Ingestion layer (Batch/Streaming/File intake)
Data Lake layers (Landing/Raw → Bronze → Silver → Gold)
People often confuse them because both look like “layers.” But they are different

ENTERPRISE DATA PLATFORM ARCHITECTURE
┌────────────────────────────────────────────────────────────────────────────┐
│ ENTERPRISE DATA PLATFORM │
│ (Data Lake + ETL / ELT + Databricks) │
└────────────────────────────────────────────────────────────────────────────┘
DATA SOURCES (OLTP / SaaS / Files)
┌───────────────────────────┐
│ OPERATIONAL SYSTEMS (OLTP)│
│ - MySQL / Postgres │
│ - App Databases │
│ - Microservices │
└───────────────┬───────────┘
│
▼
┌───────────────────────────┐
│ SAAS / APIs │
│ - Stripe │
│ - CRM │
│ - Partner APIs │
└───────────────┬───────────┘
│
▼
┌───────────────────────────┐
│ FILES / LOGS / IoT │
│ - CSV / JSON / Logs │
│ - Clickstream │
│ - Images / PDFs │
└───────────────────────────┘
DATA INGESTION LAYER
┌────────────────────────────────────────────────────────────┐
│ DATA INGESTION │
└────────────────────────────────────────────────────────────┘
┌──────────────────────┐
│ Batch Ingestion │
│ - Airflow │
│ - Fivetran │
│ - ADF / Glue │
└───────────┬──────────┘
│
▼
┌──────────────────────┐
│ Streaming Ingestion │
│ - Kafka │
│ - EventHub │
│ - CDC (Debezium) │
└───────────┬──────────┘
│
▼
┌──────────────────────┐
│ File Intake │
│ - SFTP │
│ - Upload jobs │
│ - Log shippers │
└──────────────────────┘
DATA LAKE STORAGE (Lakehouse Layers)
┌────────────────────────────────────────────────────────────┐
│ DATA LAKE STORAGE │
│ (S3 / ADLS / GCS + Delta Lake Format) │
└────────────────────────────────────────────────────────────┘
Landing / Raw Zone
┌─────────────────────────────────────┐
│ LANDING / RAW ZONE │
│ - Immutable raw data │
│ - Exact source copy │
│ - Partitioned by date/source │
│ - Schema-on-read │
└───────────────┬─────────────────────┘
│
▼
Bronze Layer
┌─────────────────────────────────────┐
│ BRONZE LAYER (Raw Tables) │
│ - Parsed data │
│ - Standardized format │
│ - Minimal cleaning │
└───────────────┬─────────────────────┘
│
▼
Silver Layer
┌─────────────────────────────────────┐
│ SILVER LAYER (Cleansed Data) │
│ - Deduplication │
│ - Null handling │
│ - Joins across sources │
│ - Business-ready datasets │
└───────────────┬─────────────────────┘
│
▼
Gold Layer
┌─────────────────────────────────────┐
│ GOLD LAYER (Analytics Marts) │
│ - KPIs │
│ - Aggregations │
│ - Star schemas │
│ - ML feature tables │
└─────────────────────────────────────┘
DATABRICKS PROCESSING LAYER
┌────────────────────────────────────────────────────────────┐
│ DATABRICKS PROCESSING │
└────────────────────────────────────────────────────────────┘
- Batch ETL / ELT Jobs
- Streaming Transformations
- Data Quality Rules
- ML / AI Model Training
- Optimization (Z-order, compaction)
↓
Spark Clusters / Serverless Compute
↓
Writes Back to Bronze / Silver / Gold
GOVERNANCE & SECURITY (Applies Everywhere)
┌────────────────────────────────────────────────────────────┐
│ GOVERNANCE & SECURITY │
└────────────────────────────────────────────────────────────┘
- Unity Catalog / Metadata
- Schema lineage
- IAM / RBAC
- Row / Column-level security
- Logs & Observability
DATA SERVING & CONSUMPTION
┌────────────────────────────────────────────────────────────┐
│ DATA SERVING & CONSUMPTION │
└────────────────────────────────────────────────────────────┘
┌────────────────────────┐
│ BI & Dashboards │
│ - Power BI │
│ - Tableau │
└────────────┬───────────┘
│
▼
┌────────────────────────┐
│ Data Science & ML │
│ - Notebooks │
│ - Feature Store │
│ - Model Registry │
└────────────┬───────────┘
│
▼
┌────────────────────────┐
│ Apps & APIs │
│ - Reverse ETL │
│ - Reports │
│ - Search / Elastic │
└────────────────────────┘
End-to-End Flow Summary
SOURCES
↓
INGESTION (Batch / Streaming / File)
↓
RAW ZONE
↓
BRONZE
↓
SILVER
↓
GOLD
↓
BI / ML / APPS
What is the Ingestion Layer?
The Ingestion Layer is the entry gate of your data platform.
Ingestion is the pipeline that brings data from source systems into the Data Lake.
It answers:
How does data come from MySQL, APIs, logs into storage?
Example:
Your app database → Airflow job → S3 bucket
Your logs → Kafka → S3 bucket
It focuses on:
Collecting data from sources (DB, APIs, files, streams)
Moving it into the Data Lake
Doing minimal checks (schema/format/basic validation)
Ensuring data arrives reliably (retries, checkpoints)
Ingestion Steps Can Include:
Extract from OLTP
API call
CDC (change data capture)
File pickup
Streaming event read
Schema validation
Write to raw storage
👉 Ingestion = Data movement + intake
✅
What are Data Lake Layers (Raw/Bronze/Silver/Gold)?
Once data is inside the lake, you need to organize and refine it.
Once data reaches storage (S3 / ADLS / GCS),
we organize it into structured zones:
Landing → Bronze → Silver → Gold
These are storage & transformation layers
Data Lake layers focus on:
Storing raw data safely (audit + replay)
Cleaning and standardizing it
Joining data across sources
Building business-ready and analytics-ready datasets
👉 Data Lake layers = Data organization + transformation
Where They Connect
Ingestion ends here:
Write into Landing / Raw Zone
Then Databricks starts:
Raw → Bronze → Silver → Gold
So:
Source → Ingestion → Raw Zone → Bronze → Silver → Gold
🎯
Simple Real Example
Imagine e-commerce company:
Ingestion
Airflow extracts orders from MySQL
Writes CSV into S3/raw/orders/2026-02-25/
That’s ingestion.
Data Lake Processing
Bronze: Convert CSV to Delta table
Silver: Remove duplicates, fix nulls
Gold: Create daily_sales_summary table
That’s Data Lake layering.
🧩
Why We Need Both
If you only have ingestion:
Data enters
But becomes messy
If you only have Data Lake layers:
No data enters
So:
| Without Ingestion | No data |
| Without Lake Layers | Data chaos |
🏗
Full Flow Visual (Conceptual)
[ OLTP / APIs / Logs ]
↓
INGESTION
(Airflow / Kafka / CDC)
↓
RAW ZONE (Landing)
↓
BRONZE (Parsed)
↓
SILVER (Cleaned)
↓
GOLD (Analytics)
💡 One-Line Memory Trick
👉 Ingestion = "Bring data"
👉 Lake Layers = "Organize data"
End-to-End Steps (How It Works in Real Life)
Step 1: Sources (OLTP/APIs/Files/Logs)
Example sources:
MySQL/Postgres (bookings, users)
APIs (Stripe payments)
Logs (clickstream)
Files (CSV/JSON)
Step 2: Ingestion Layer (Extract + Load to Raw)
Tools (examples):
Airflow / ADF / Glue (batch)
Kafka / EventHub (streaming)
SFTP / Upload jobs (files)
Debezium (CDC)
Output:
✅ Data lands into Landing/Raw Zone
Step 3: Data Lake Layering (Raw → Bronze → Silver → Gold)
Raw/Landing: exact copy, immutable
Bronze: parsed, basic typing, minimal cleaning
Silver: cleaned, deduped, joined, conformed
Gold: aggregates, KPIs, marts, ML features
Full Coding Example (Shows the Difference Clearly)
Use-case:
MySQL bookings table → Raw Zone (Ingestion) → Bronze/Silver/Gold (Lake Layers)
Assumptions:
MySQL table bookings has:
id, user_id, amount, status, created_at
Databricks uses:
Spark + Delta
✅ A) Ingestion Layer Code (MySQL → Raw Zone)
This code ONLY brings data into the lake (no real transformations).
# ================================
# INGESTION LAYER (Extract + Load)
# Source: MySQL (OLTP)
# Target: Data Lake Raw Zone
# ================================
from pyspark.sql import functions as F
jdbc_url = "jdbc:mysql://YOUR_HOST:3306/YOUR_DB"
props = {
"user": "YOUR_USER",
"password": "YOUR_PASSWORD",
"driver": "com.mysql.cj.jdbc.Driver"
}
# 1) EXTRACT (read from OLTP)
src = spark.read.jdbc(jdbc_url, "bookings", properties=props)
# 2) Minimal ingestion metadata (recommended)
raw_df = (src
.withColumn("ingestion_time", F.current_timestamp())
.withColumn("source_system", F.lit("mysql_bookings"))
)
# 3) LOAD to Raw Zone (store as-is)
raw_path = "dbfs:/mnt/datalake/raw/bookings/"
(raw_df.write
.format("parquet") # raw can be parquet/json/csv as received
.mode("append")
.save(raw_path)
)
print("✅ INGESTION DONE -> Raw saved at:", raw_path)
✅ Output: Raw files stored for audit/replay.
This is ingestion layer function.
PART A — INGESTION CODE (Source → Raw Zone)
Goal:
Bring data from MySQL and store it as-is in Raw Zone.
This code is ingestion because it moves data from OLTP to Data Lake.
# Databricks Notebook: INGESTION (MySQL -> Data Lake Raw)
from pyspark.sql import functions as F
jdbc_url = "jdbc:mysql://YOUR_MYSQL_HOST:3306/YOUR_DB"
properties = {
"user": "YOUR_USER",
"password": "YOUR_PASSWORD",
"driver": "com.mysql.cj.jdbc.Driver"
}
# 1) EXTRACT from OLTP (MySQL)
bookings_src = (spark.read
.jdbc(url=jdbc_url, table="bookings", properties=properties)
)
# 2) Add ingestion metadata (optional but recommended)
ingested = (bookings_src
.withColumn("ingestion_time", F.current_timestamp())
.withColumn("source_system", F.lit("mysql_bookings"))
)
# 3) LOAD to Data Lake Raw Zone (no transformations)
raw_path = "dbfs:/mnt/datalake/raw/bookings/"
(ingested.write
.format("parquet")
.mode("append")
.save(raw_path)
)
print("✅ Ingestion completed. Raw data stored at:", raw_path)
✅ Output of ingestion
Raw files stored like:
/raw/bookings/part-0000.parquet
/raw/bookings/part-0001.parquet
✅ B) Bronze Layer Code (Raw → Bronze Delta)
Bronze = parsed + basic typing + standardized structure.
# ================================
# DATA LAKE LAYER: BRONZE
# Raw files -> Bronze Delta tables
# ================================
from pyspark.sql import functions as F
raw_path = "dbfs:/mnt/datalake/raw/bookings/"
bronze_path = "dbfs:/mnt/datalake/bronze/bookings_delta/"
raw = spark.read.parquet(raw_path)
bronze = (raw
.withColumn("created_at", F.to_timestamp("created_at"))
.withColumn("amount", F.col("amount").cast("double"))
.withColumn("status", F.lower(F.trim(F.col("status"))))
)
(bronze.write
.format("delta")
.mode("overwrite")
.save(bronze_path)
)
spark.sql(f"CREATE TABLE IF NOT EXISTS bronze.bookings USING DELTA LOCATION '{bronze_path}'")
print("✅ BRONZE READY:", bronze_path)
✅ C) Silver Layer Code (Bronze → Silver Clean & Dedup)
Silver = cleaned + deduped + trustworthy for analytics.
# ================================
# DATA LAKE LAYER: SILVER
# Clean + Deduplicate
# ================================
from pyspark.sql import functions as F
from pyspark.sql.window import Window
silver_path = "dbfs:/mnt/datalake/silver/bookings_clean/"
bronze = spark.read.format("delta").table("bronze.bookings")
# Remove invalid rows
clean = bronze.filter(F.col("user_id").isNotNull())
# Deduplicate: keep latest record per booking id
w = Window.partitionBy("id").orderBy(F.col("ingestion_time").desc())
silver = (clean
.withColumn("rn", F.row_number().over(w))
.filter(F.col("rn") == 1)
.drop("rn")
)
(silver.write
.format("delta")
.mode("overwrite")
.save(silver_path)
)
spark.sql(f"CREATE TABLE IF NOT EXISTS silver.bookings USING DELTA LOCATION '{silver_path}'")
print("✅ SILVER READY:", silver_path)
✅ D) Gold Layer Code (Silver → Gold KPI Table)
Gold = final business outputs (dashboards, KPIs).
# ================================
# DATA LAKE LAYER: GOLD
# KPIs / Analytics marts
# ================================
from pyspark.sql import functions as F
gold_path = "dbfs:/mnt/datalake/gold/daily_revenue/"
silver = spark.read.format("delta").table("silver.bookings")
gold = (silver
.filter(F.col("status") == "completed")
.withColumn("day", F.to_date("created_at"))
.groupBy("day")
.agg(
F.count("*").alias("completed_bookings"),
F.sum("amount").alias("total_revenue"),
F.avg("amount").alias("avg_booking_value")
)
.orderBy("day")
)
(gold.write
.format("delta")
.mode("overwrite")
.save(gold_path)
)
spark.sql(f"CREATE TABLE IF NOT EXISTS gold.daily_revenue USING DELTA LOCATION '{gold_path}'")
print("✅ GOLD READY:", gold_path)
Tabular Comparison: Ingestion Layer vs Data Lake Layer Functions
20 Objective MCQs (Code + Concept Focused)
1.
Which layer is responsible for only moving raw data into the Data Lake?
A) Silver
B) Ingestion
C) Gold
D) Business Layer
Answer: B
2.
In the ingestion pipeline, which tool is typically used for streaming ingestion?
A) Airflow
B) Kafka
C) Tableau
D) Power BI
Answer: B
3.
What is the primary output format of the Ingestion Layer before transformation?
A) Delta Tables
B) Normalized Tables
C) Raw files (Parquet/JSON)
D) Analytics marts
Answer: C
4.
In the code example, raw_df.write.format("parquet") is part of which layer?
A) Silver
B) Bronze
C) Gold
D) Ingestion
Answer: D
5.
What Spark format is commonly used for optimized lakehouse tables?
A) CSV
B) ORC
C) Delta
D) TXT
Answer: C
6.
In which layer do you perform deduplication and basic cleaning?
A) Raw
B) Bronze
C) Gold
D) Presentation
Answer: B
7.
The command F.to_timestamp("created_at") is used to:
A) Clean data types
B) Run analytics
C) Write dashboards
D) Consume APIs
Answer: A
8.
Which layer produces tables ready for analytics and BI consumption?
A) Raw
B) Bronze
C) Silver
D) Gold
Answer: D
9.
Where would you compute daily revenue KPIs?
A) Raw Zone
B) Bronze Tables
C) Silver Clean Data
D) Gold Analytics Marts
Answer: D
10.
Which function best represents ingestion metadata in code?
A) withColumn("status", lower(...))
B) withColumn("ingestion_time", current_timestamp())
C) groupBy("day")
D) write.format("delta")
Answer: B
11.
**What does the silver layer primarily represent?
**A) Immutable raw files
B) Refined and cleaned tables
C) Analytics dashboards
D) Data ingestion tools
Answer: B
12.
Which tool is NOT typically used for batch ingestion?
A) Airflow
B) Glue
C) Fivetran
D) Postman
Answer: D
13.
The statement .mode("overwrite") when writing Delta means:
A) Append to the table
B) Replace existing data
C) Save to CSV
D) Change file format
Answer: B
14.
Using Delta Lake provides what key feature over raw Parquet?
A) ACID transactions
B) Less storage
C) No schema
D) No querying support
Answer: A
15.
Which layer typically contains raw and unmodified data?
A) Bronze
B) Silver
C) Landing / Raw Zone
D) Gold
Answer: C
16.
In a Databricks notebook, what module helps build workflows?
A) HTML
B) Spark
C) CSS
D) Tableau
Answer: B
17.
The command create table silver.bookings using delta belongs to which step?
A) Ingestion
B) Bronze layer
C) Silver layer
D) Data Consumption
Answer: C
18.
What is the key purpose of the Gold layer?
A) Logging
B) Final business-ready datasets
C) Ingestion checkpoints
D) Temporary storage
Answer: B
19.
Which statement belongs to Ingestion code?
A) .groupBy("day").agg(...)
B) .write.format("parquet")
C) .withColumn("rn", row_number().over(...))
D) .lower(trim(status))
Answer: B
20.
Which layer is MOST likely to involve Spark transformations and dedup logic?
A) Landing
B) Bronze
C) Silver
D) Raw Metadata
Answer: C

Top comments (0)