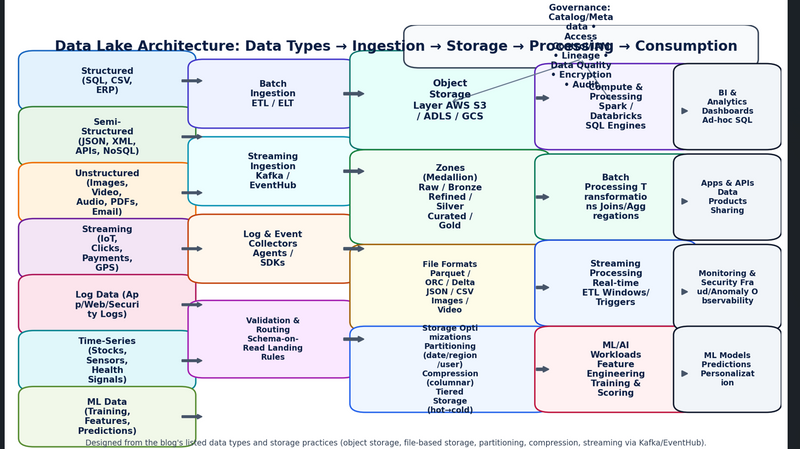
Different Types of Data Handled by a Data Lake
Structured Data
Semi-Structured Data
Unstructured Data
Streaming Data
Log Data
Time-Series Data
Machine Learning Data
How data lake storage huge data
Practical way how data stores in datalake
Objective and MCQ QUESTION
1️⃣ Structured Data
This is highly organized data in rows and columns.
Examples:
SQL tables (MySQL, PostgreSQL)
Excel sheets
CSV files
ERP transaction records
Booking tables
Payment records
Characteristics:
Fixed schema
Columns and data types defined
Easy to query using SQL
2️⃣ Semi-Structured Data
Data that doesn’t follow strict table structure but still has some organization.
Examples:
JSON files
XML
API responses
NoSQL data (MongoDB)
Event logs (clickstream)
Characteristics:
Flexible schema
Nested fields
Schema can change over time
Very common in:
Web applications
Mobile apps
Microservices
3️⃣ Unstructured Data
Data with no predefined format.
Examples:
Images (JPG, PNG)
Videos (MP4)
Audio files
PDFs
Medical reports
Emails
Chat transcripts
Social media posts
Characteristics:
Cannot be stored in traditional tables easily
Used in AI / ML / NLP systems
This is where Data Lakes shine compared to databases.
4️⃣ Streaming Data
Real-time continuously generated data.
Examples:
IoT sensor data
App click events
Payment gateway events
GPS tracking
Server logs
Characteristics:
High velocity
Time-based
Needs real-time processing
Stored in:
Kafka → Data Lake
EventHub → Data Lake
5️⃣ Log Data
System-generated operational data.
Examples:
Web server logs
Error logs
Application logs
Security logs
Very useful for:
Monitoring
Fraud detection
Performance analysis
6️⃣ Time-Series Data
Data indexed by timestamp.
Examples:
Stock prices
Temperature records
Health monitoring signals
User activity over time
Often used in:
Forecasting
Trend analysis
7️⃣ Machine Learning Data
Used specifically for AI.
Examples:
Training datasets
Feature tables
Model output
Predictions
Historical behavioral data
Data Lake is ideal for storing large ML datasets.
How data lake storgae huge data
Data Lake Does NOT Store Data Like a Traditional Database
A Data Lake usually sits on top of:
AWS S3
Azure Data Lake Storage (ADLS)
Google Cloud Storage
These are distributed object storage systems, not single machines.
That means:
👉 Data is stored across thousands of physical servers.
2️⃣ Horizontal Scaling (Unlimited Expansion)
Traditional database:
Limited by server disk size
Needs vertical scaling (bigger machine)
Data Lake:
Adds more storage nodes automatically
Scales horizontally
No practical upper limit (petabytes or exabytes)
If you upload 10 TB more data:
It simply distributes it across more storage blocks.
3️⃣ Data is Stored as Files (Not Tables)
Instead of storing rows in a database engine, Data Lake stores:
Parquet files
ORC files
Delta files
JSON / CSV
Images / Videos
Example:
/datalake/bookings/2026/02/21/part-0001.parquet
Data is split into many small files, not one huge file.
This makes:
Faster parallel reading
Better distribution
Efficient storage
4️⃣ Data Compression
Modern formats like Parquet / ORC / Delta:
Compress data automatically
Store column-wise (columnar storage)
Reduce storage cost significantly
Example:
1 TB raw data → may become 200–300 GB after compression.
5️⃣ Separation of Storage and Compute
In traditional systems:
Storage + compute are tied together.
In Data Lake architecture:
Storage is separate.
Compute (Databricks, Spark) reads data when needed.
So:
Storage can grow independently.
Compute can scale only when required.
This makes it cost-efficient.
6️⃣ Data Partitioning
Data is partitioned by:
Date
Region
User ID
Category
Example:
/bookings/year=2026/month=02/day=21/
So system does not scan entire dataset — only relevant partition.
That’s how performance stays high even with huge data.
7️⃣ Tiered Storage (Cost Optimization)
Cloud storage automatically moves old data to cheaper storage tiers:
Hot (frequent access)
Warm
Cold / Archive
So even petabytes remain affordable.
🔥 Why It Can Handle Huge Data
Because it is:
Distributed
Parallel
Compressed
Partitioned
Cloud-native
Decoupled from compute
Practical way how data stores in datalake
Imagine AWS S3 or Azure Data Lake like this:
datalake/
bookings/
year=2026/
month=01/
part-0001.parquet
part-0002.parquet
month=02/
part-0001.parquet
users/
part-0001.parquet
logs/
2026-02-20.json
2026-02-21.json
👉 It stores files, not database rows.
👉 Each file may contain millions of records.
👉 Files are distributed across thousands of servers.
🔹 Step 2: How It Stores Huge Data (Distributed Storage)
When you upload a file to S3:
It is automatically split internally into blocks.
Those blocks are stored across multiple data centers.
If one server fails → data is still safe.
You don’t manage servers — cloud handles it.
Example:
Upload 5 TB of data →
S3 automatically spreads it across many storage nodes.
That’s why it can scale to petabytes.
🔹 Step 3: Practical Example – Writing Large Data Using Spark
Let’s simulate large data in Databricks or Spark.
Create 10 million records
from pyspark.sql import functions as F
df = spark.range(0, 10_000_000) \
.withColumn("user_id", F.col("id")) \
.withColumn("amount", F.rand()*1000) \
.withColumn("year", F.lit(2026)) \
.withColumn("month", (F.col("id") % 12) + 1)
df.write \
.partitionBy("year","month") \
.format("parquet") \
.mode("overwrite") \
.save("/mnt/datalake/bookings")
Now check storage.
You’ll see something like:
/bookings/year=2026/month=1/part-00000.parquet
/bookings/year=2026/month=2/part-00001.parquet
...
Instead of 1 huge file,
Spark created many small distributed files.
That’s scalability.
🔹 Step 4: See Compression in Action
If you store as CSV:
df.write.mode("overwrite").csv("/mnt/datalake/csv_test")
Now compare with Parquet:
df.write.mode("overwrite").parquet("/mnt/datalake/parquet_test")
You’ll notice:
Parquet size << CSV size
Because:
Parquet stores column-wise
Uses compression (Snappy)
Avoids repetition
Huge savings at TB scale.
🔹 Step 5: How Partitioning Prevents Full Scans
If you query:
spark.read.parquet("/mnt/datalake/bookings") \
.filter("year=2026 AND month=2") \
.count()
Spark only reads:
/year=2026/month=2/
Not entire dataset.
This is how it handles huge data efficiently.
🔹 Step 6: Storage & Compute Separation (Very Important)
Storage:
Cheap (S3 / ADLS)
Scales infinitely
Compute:
Spark cluster
Only runs when needed
Scales up/down automatically
So even if you store 5 PB data,
you only pay compute when analyzing.
🔹 Step 7: Real-World Size Example
Let’s say:
1 hospital system generates 5 GB/day logs
1 year = ~1.8 TB
5 years = ~9 TB
Data Lake handles this easily because:
It just keeps adding files
No schema restriction
No performance drop
Database would struggle at this scale.
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
import textwrap, os
# --- Helper functions ---
def add_box(ax, x, y, w, h, text, fc="#E8F0FE", ec="#1A73E8", fontsize=10, lw=1.6, align="center"):
box = FancyBboxPatch(
(x, y), w, h,
boxstyle="round,pad=0.02,rounding_size=0.02",
linewidth=lw, edgecolor=ec, facecolor=fc
)
ax.add_patch(box)
wrapped = "\n".join(textwrap.wrap(text, width=max(12, int(w*30))))
ax.text(x + w/2, y + h/2, wrapped, ha=align, va="center", fontsize=fontsize, color="#0B1F44", fontweight="bold")
return box
def add_arrow(ax, x1, y1, x2, y2, color="#334155", lw=1.6, style="simple", mutation_scale=12):
arr = FancyArrowPatch((x1, y1), (x2, y2), arrowstyle=style, mutation_scale=mutation_scale,
linewidth=lw, color=color, connectionstyle="arc3,rad=0.0")
ax.add_patch(arr)
return arr
# --- Figure ---
fig = plt.figure(figsize=(16, 9), dpi=150)
ax = plt.gca()
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
ax.axis("off")
# Title
ax.text(0.5, 0.965, "Data Lake Architecture: Data Types → Ingestion → Storage → Processing → Consumption",
ha="center", va="top", fontsize=16, fontweight="bold", color="#0B1F44")
# Column anchors
x_sources = 0.03
x_ingest = 0.25
x_store = 0.46
x_process = 0.70
x_consume = 0.88
# Sources (left)
add_box(ax, x_sources, 0.82, 0.19, 0.10, "Structured\n(SQL, CSV, ERP)",
fc="#E3F2FD", ec="#1565C0")
add_box(ax, x_sources, 0.69, 0.19, 0.10, "Semi-Structured\n(JSON, XML, APIs, NoSQL)",
fc="#E8F5E9", ec="#2E7D32")
add_box(ax, x_sources, 0.56, 0.19, 0.10, "Unstructured\n(Images, Video, Audio, PDFs, Email)",
fc="#FFF3E0", ec="#EF6C00")
add_box(ax, x_sources, 0.43, 0.19, 0.10, "Streaming\n(IoT, Clicks, Payments, GPS)",
fc="#F3E5F5", ec="#6A1B9A")
add_box(ax, x_sources, 0.30, 0.19, 0.10, "Log Data\n(App/Web/Security Logs)",
fc="#FCE4EC", ec="#AD1457")
add_box(ax, x_sources, 0.17, 0.19, 0.10, "Time-Series\n(Stocks, Sensors, Health Signals)",
fc="#E0F7FA", ec="#00838F")
add_box(ax, x_sources, 0.04, 0.19, 0.10, "ML Data\n(Training, Features, Predictions)",
fc="#F1F8E9", ec="#558B2F")
# Ingestion (middle-left)
add_box(ax, x_ingest, 0.78, 0.18, 0.12, "Batch Ingestion\nETL / ELT", fc="#EEF2FF", ec="#4338CA")
add_box(ax, x_ingest, 0.60, 0.18, 0.12, "Streaming Ingestion\nKafka / EventHub", fc="#ECFEFF", ec="#0891B2")
add_box(ax, x_ingest, 0.42, 0.18, 0.12, "Log & Event Collectors\nAgents / SDKs", fc="#FFF7ED", ec="#C2410C")
add_box(ax, x_ingest, 0.20, 0.18, 0.14, "Validation & Routing\nSchema-on-Read\nLanding Rules", fc="#FAE8FF", ec="#A21CAF", fontsize=9)
# Storage core (middle)
add_box(ax, x_store, 0.73, 0.22, 0.19, "Object Storage Layer\nAWS S3 / ADLS / GCS",
fc="#E6FFFA", ec="#0F766E", fontsize=11)
add_box(ax, x_store, 0.51, 0.22, 0.18, "Zones (Medallion)\nRaw / Bronze\nRefined / Silver\nCurated / Gold",
fc="#F0FDF4", ec="#15803D", fontsize=10)
add_box(ax, x_store, 0.31, 0.22, 0.16, "File Formats\nParquet / ORC / Delta\nJSON / CSV\nImages / Video",
fc="#FEFCE8", ec="#A16207", fontsize=9)
add_box(ax, x_store, 0.12, 0.22, 0.16, "Storage Optimizations\nPartitioning (date/region/user)\nCompression (columnar)\nTiered Storage (hot→cold)",
fc="#EFF6FF", ec="#2563EB", fontsize=9)
# Governance & metadata (overlay-ish near storage)
add_box(ax, 0.53, 0.92, 0.42, 0.06,
"Governance: Catalog/Metadata • Access Control/IAM • Lineage • Data Quality • Encryption • Audit",
fc="#F8FAFC", ec="#334155", fontsize=10)
# Processing (middle-right)
add_box(ax, x_process, 0.73, 0.17, 0.16, "Compute & Processing\nSpark / Databricks\nSQL Engines", fc="#F5F3FF", ec="#5B21B6")
add_box(ax, x_process, 0.52, 0.17, 0.16, "Batch Processing\nTransformations\nJoins/Aggregations", fc="#ECFDF5", ec="#047857")
add_box(ax, x_process, 0.32, 0.17, 0.16, "Streaming Processing\nReal-time ETL\nWindows/Triggers", fc="#EFF6FF", ec="#1D4ED8")
add_box(ax, x_process, 0.12, 0.17, 0.16, "ML/AI Workloads\nFeature Engineering\nTraining & Scoring", fc="#FFF1F2", ec="#BE123C")
# Consumption (right)
add_box(ax, x_consume, 0.73, 0.10, 0.16, "BI & Analytics\nDashboards\nAd-hoc SQL", fc="#F1F5F9", ec="#0F172A", fontsize=9)
add_box(ax, x_consume, 0.52, 0.10, 0.16, "Apps & APIs\nData Products\nSharing", fc="#F1F5F9", ec="#0F172A", fontsize=9)
add_box(ax, x_consume, 0.31, 0.10, 0.16, "Monitoring & Security\nFraud/Anomaly\nObservability", fc="#F1F5F9", ec="#0F172A", fontsize=9)
add_box(ax, x_consume, 0.12, 0.10, 0.16, "ML Models\nPredictions\nPersonalization", fc="#F1F5F9", ec="#0F172A", fontsize=9)
# Arrows: sources -> ingestion
for y in [0.87, 0.74, 0.61, 0.48, 0.35, 0.22, 0.09]:
add_arrow(ax, x_sources + 0.19, y, x_ingest, y, color="#475569", lw=1.4, mutation_scale=10)
# Arrows: ingestion -> storage
for y in [0.84, 0.66, 0.48, 0.27]:
add_arrow(ax, x_ingest + 0.18, y, x_store, y, color="#475569", lw=1.6, mutation_scale=12)
# Arrows: storage -> processing
for y in [0.83, 0.60, 0.39, 0.20]:
add_arrow(ax, x_store + 0.22, y, x_process, y, color="#475569", lw=1.6, mutation_scale=12)
# Arrows: processing -> consumption
for y in [0.80, 0.59, 0.38, 0.19]:
add_arrow(ax, x_process + 0.17, y, x_consume, y, color="#475569", lw=1.6, mutation_scale=12)
# Governance arrows (down to storage & processing)
add_arrow(ax, 0.74, 0.92, 0.57, 0.82, color="#64748B", lw=1.2, mutation_scale=10, style="->")
add_arrow(ax, 0.74, 0.92, 0.78, 0.82, color="#64748B", lw=1.2, mutation_scale=10, style="->")
# Footer note
ax.text(0.5, 0.02,
"Designed from the blog's listed data types and storage practices (object storage, file-based storage, partitioning, compression, streaming via Kafka/EventHub).",
ha="center", va="bottom", fontsize=9, color="#334155")
out_path = "/mnt/data/data-lake-architecture-diagram.png"
plt.savefig(out_path, bbox_inches="tight")
out_path
20 MCQs on Data Lake Data Types
1️⃣
Which type of data is stored in its original form in a Data Lake?
A) Transformed data only
B) Raw data
C) Only structured data
D) Processed data
✅ Answer: B
2️⃣
Structured data refers to:
A) Images and videos
B) Data stored in tables with schema
C) Unlabeled text files
D) Audio files
✅ Answer: B
3️⃣
Which storage format below is commonly used in Data Lakes for analytics?
A) PDF
B) Parquet
C) TXT
D) PPT
✅ Answer: B
4️⃣
Semi-structured data includes:
A) Excel tables
B) JSON and XML
C) Audio files
D) Plain text without organization
✅ Answer: B
5️⃣
Which type of data is NOT structured but contains some organization?
A) Binary logs
B) JSON files
C) Relational tables
D) Excel sheets
✅ Answer: B
6️⃣
Which type of data includes videos, images, and audio?
A) Structured
B) Metadata
C) Unstructured
D) Semi-structured
✅ Answer: C
7️⃣
Log files and event streams are examples of:
A) Structured data
B) Unstructured data
C) Time-series data
D) Meta descriptions
✅ Answer: C
8️⃣
In a Data Lake, data is typically stored in:
A) Rows only
B) Columns only
C) Files and objects
D) Temporary buffers
✅ Answer: C
9️⃣
Which data type is often used for machine learning training?
A) Structured only
B) Unstructured only
C) Any type (structured, unstructured, semi-structured)
D) No data type
✅ Answer: C
🔟
Object Storage in Data Lakes is usually:
A) Limited to text data
B) Used to store blobs of data (images/videos)
C) Only for SQL tables
D) Temporary
✅ Answer: B
1️⃣1️⃣
Which format is most efficient for big data analytics in a Data Lake?
A) CSV
B) Parquet
C) JPG
D) GIF
✅ Answer: B
1️⃣2️⃣
Time-series data is collected continuously from:
A) Books
B) Sensors and logs
C) Photos
D) Emails
✅ Answer: B
1️⃣3️⃣
Which data type would a clinical image like X-ray fall under?
A) Structured
B) Semi-structured
C) Unstructured
D) Meta data
✅ Answer: C
1️⃣4️⃣
Web clickstream data is usually stored as:
A) Excel sheets
B) JSON logs
C) CSV only
D) PDF
✅ Answer: B
1️⃣5️⃣
Which data type can be nested and hierarchical?
A) XML
B) MP3
C) MOV
D) PNG
✅ Answer: A
1️⃣6️⃣
Which type of data is least likely to fit in a traditional relational database?
A) Numeric tables
B) JSON logs
C) ID fields
D) SQL records
✅ Answer: B
1️⃣7️⃣
Data Lakes handle both batch and ____ data.
A) Stream
B) Temporary
C) Processed
D) Calculation
✅ Answer: A
1️⃣8️⃣
Which of the following is NOT a reason Data Lakes store diverse data types?
A) Scalability
B) Cost efficiency
C) Strict schema requirement
D) Flexibility
✅ Answer: C
1️⃣9️⃣
Big data analytics often requires:
A) Only structured data
B) Multiple data types
C) No data storage
D) Only images
✅ Answer: B
2️⃣0️⃣
Which type of data stored in Data Lake is most commonly used for AI and ML training?
A) Audio & text only
B) Only structured tables
C) All types — structured, semi-structured, unstructured
D) Only numeric columns
✅ Answer: C

Top comments (0)