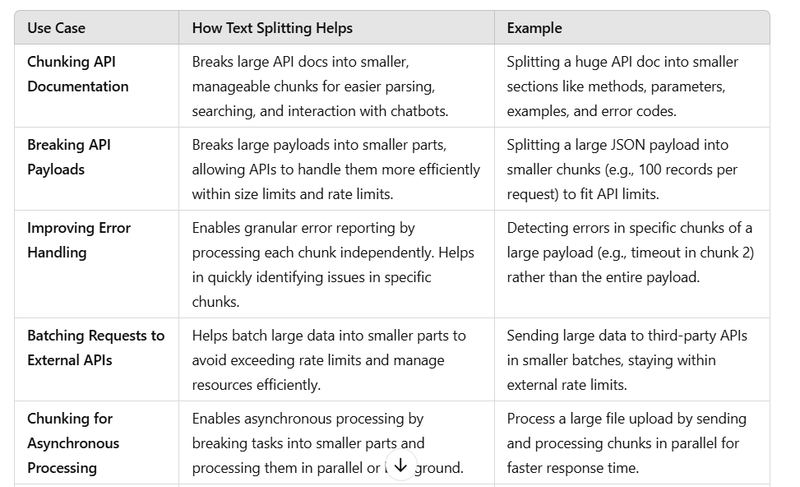
Text splitting using LangChain can be very useful for API developers, especially when dealing with large API documentation or payloads that need to be processed efficiently. Here are a few key ways that LangChain's text splitting can help chunk and break API docs or API payloads:
- Chunking API Documentation API documentation can be extensive, with multiple sections, examples, and complex descriptions. By using LangChain’s text splitter, API docs can be chunked into manageable pieces for various use cases:
Efficient Parsing: Large docs can be split into smaller chunks, making it easier to parse, search, and index specific sections (like methods, parameters, or example responses).
Search Optimization: API documentation can be searched by chunks rather than processing the entire document, leading to faster query results and a better search experience for developers using the docs.
Interactive Chatbots: Split docs can be fed to an AI-based chatbot that assists developers by answering questions about specific sections, rather than querying the entire document at once. This allows for more focused and faster responses.
Example:
Before Chunking: A massive API documentation file with descriptions, examples, error codes, etc.
After Chunking: Smaller, targeted pieces (e.g., "POST method for user authentication", "Response format for GET /users", etc.) that can be retrieved and displayed when needed.
- Breaking API Payloads APIs often deal with large payloads, especially when sending or receiving data from clients. These payloads may exceed size limits, making it difficult to process them in a single request. LangChain’s text splitting can help by breaking down these payloads into smaller, manageable chunks.
Handling Large Payloads: For APIs that deal with large data, payloads can be chunked into smaller parts to meet the API size constraints (e.g., max request body size in a REST API).
Optimized Processing: By breaking large payloads into smaller chunks, APIs can process each chunk individually, making it easier to handle, store, or validate specific parts of the data.
API Rate Limiting and Throttling: Large payloads can be split to ensure they don't exceed API limits or rate limits, reducing the likelihood of timeouts or errors.
Example:
Before Chunking: A large payload containing multiple entries, such as a list of user data.
After Chunking: The payload is split into smaller chunks (e.g., 100 records per request), making it easier to send and process.
- Improving Error Handling API developers can use LangChain’s text splitting for more granular error handling:
Specific Error Reporting: If an API fails due to a large payload, the developer can analyze each chunk to isolate the cause of the failure and fix issues more quickly.
Log Management: In cases of failed requests, logs can be split into chunks and analyzed independently, allowing the system to generate targeted error reports based on specific chunks, rather than generating errors for the entire payload.
- Batching Requests to External APIs When APIs need to send data to external services (like third-party APIs), the payload may be too large to be processed in a single call. Text splitting helps break large payloads into smaller parts for batch processing:
API Rate Limiting: By splitting payloads into chunks, API calls can be made in batches to stay within external service rate limits.
Efficient Resource Management: Splitting the payload allows for better use of system resources, enabling API servers to process smaller requests more efficiently and avoid system overload.
- Chunking for Asynchronous Processing For APIs that handle long-running tasks (such as large data analysis or file uploads), chunking can help in making the process asynchronous:
Real-time Feedback: As chunks are processed, developers and users can receive real-time feedback, such as "Chunk 1/10 processed", allowing them to track progress.
Background Processing: API servers can use chunking to break down large tasks and process them in the background, keeping the API responsive for other requests.
- Improved Security and Privacy Splitting large documents or payloads can help improve the security and privacy of sensitive data:
Data Segmentation: Sensitive data can be isolated into chunks, which can then be processed individually. This allows for selective sharing of specific data without exposing the entire payload.
Data Encryption: Each chunk of a sensitive payload can be encrypted separately, allowing for more granular security controls.
- Efficient Streaming of Large Data APIs that stream data, like video streaming APIs or large file downloads, benefit from chunking:
Streaming Large Files: By splitting files into chunks, APIs can stream data incrementally rather than in one large block, which reduces latency and allows for real-time streaming.
Download and Upload Speed: Streaming chunks can be handled simultaneously in parallel, increasing the download and upload speed when handling large files.
- Simplifying Client-Side API Handling On the client-side, handling large API responses can be a challenge. By splitting the response into smaller chunks, the client can display the data incrementally, improving performance:
Progressive Rendering: For APIs that return large responses (like data-heavy applications), splitting the response into chunks enables progressive rendering, displaying parts of the data while the rest is still being processed.
Error Recovery: If a request fails, only the chunk related to that specific error needs to be retried, rather than the entire response.


Example Huge API Payload (for API documentation input)
{
"api_version": "v2.1",
"base_url": "https://api.example.com/v2.1/",
"authentication": {
"auth_method": "Bearer Token",
"token": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c",
"auth_required": true
},
"rate_limiting": {
"limit": 1000,
"time_window": "minute",
"remaining_requests": 950
},
"request": {
"method": "POST",
"endpoint": "/tasks",
"headers": {
"Content-Type": "application/json",
"Authorization": "Bearer token"
},
"parameters": {
"status": "active",
"limit": 50,
"page": 2
},
"body": {
"tasks": [
{
"title": "Complete API Documentation",
"description": "Documenting all endpoints with usage examples, responses, error codes, and status codes.",
"due_date": "2025-03-15T23:59:59Z",
"priority": "high",
"assigned_to": "johndoe@example.com"
},
{
"title": "Implement User Authentication",
"description": "Implement user authentication mechanism using JWT tokens.",
"due_date": "2025-04-01T23:59:59Z",
"priority": "medium",
"assigned_to": "janedoe@example.com"
}
]
}
},
"response_example": {
"status": "200 OK",
"message": "Request successfully processed",
"data": {
"tasks": [
{
"id": 101,
"title": "Complete API Documentation",
"description": "Documenting all endpoints with usage examples, responses, error codes, and status codes.",
"status": "completed",
"due_date": "2025-03-15T23:59:59Z",
"assigned_to": "johndoe@example.com",
"created_at": "2025-02-20T09:00:00Z"
},
{
"id": 102,
"title": "Implement User Authentication",
"description": "Implement user authentication mechanism using JWT tokens.",
"status": "in-progress",
"due_date": "2025-04-01T23:59:59Z",
"assigned_to": "janedoe@example.com",
"created_at": "2025-02-25T10:30:00Z"
}
]
}
},
"status_codes": [
{
"code": "200",
"description": "OK - Request was successful."
},
{
"code": "400",
"description": "Bad Request - The server could not understand the request due to invalid syntax."
},
{
"code": "404",
"description": "Not Found - The server can not find the requested resource."
},
{
"code": "500",
"description": "Internal Server Error - The server has encountered a situation it doesn't know how to handle."
}
],
"error_codes": [
{
"error_code": "ERR001",
"description": "Missing required parameter in the request."
},
{
"error_code": "ERR002",
"description": "Invalid authentication token provided."
},
{
"error_code": "ERR003",
"description": "Insufficient permissions to access the resource."
}
],
"pagination": {
"current_page": 2,
"total_pages": 10,
"items_per_page": 50,
"total_items": 500
},
"pagination_example": {
"page": 2,
"items": [
{
"id": 101,
"title": "Complete API Documentation"
},
{
"id": 102,
"title": "Implement User Authentication"
}
]
},
"webhooks": {
"task_updated": {
"event": "task_updated",
"url": "https://example.com/webhooks/task_updated",
"payload": {
"task_id": 101,
"status": "completed"
}
},
"task_assigned": {
"event": "task_assigned",
"url": "https://example.com/webhooks/task_assigned",
"payload": {
"task_id": 102,
"assigned_to": "janedoe@example.com"
}
}
},
"examples": {
"request_example": {
"method": "POST",
"url": "https://api.example.com/v1/tasks",
"body": {
"title": "New Task",
"description": "Description of the new task",
"due_date": "2025-03-01",
"assigned_to": "john@example.com"
}
},
"response_example": {
"status": "200 OK",
"body": {
"id": 103,
"title": "New Task",
"description": "Description of the new task",
"status": "pending",
"assigned_to": "john@example.com"
}
}
},
"versioning": {
"current_version": "v2.1",
"previous_versions": ["v1.0", "v1.1", "v2.0"],
"deprecated_versions": ["v1.0"]
},
"glossary": {
"task": "A unit of work to be completed, can have various states like 'pending', 'completed', etc.",
"due_date": "The date by which the task should be completed."
}
}
PROMPT for efficient processing api payload for api developers
write a code for Splitting a huge API doc into smaller sections like methods, parameters, examples, and error codes.
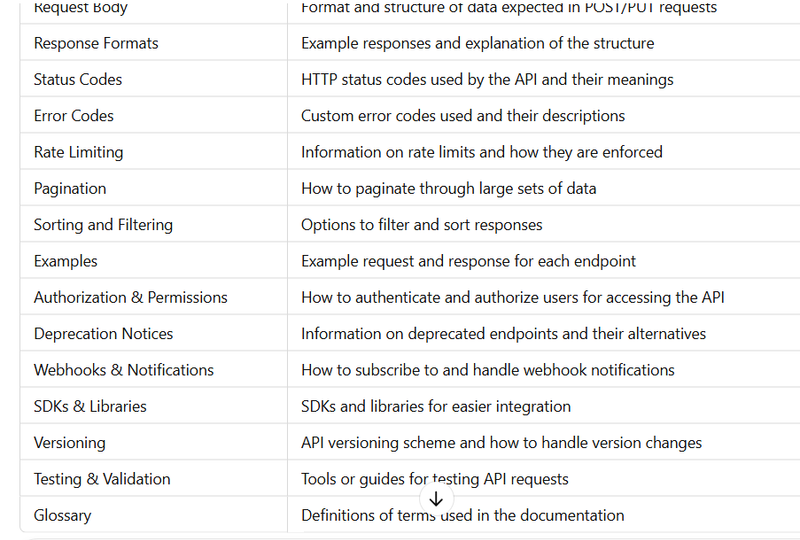
Admin Section: You can dynamically add sections like methods, parameters, examples,api_version, base_url, authentication, rate_limiting, request, response_example, status_codes, error_codes, pagination, pagination_example, webhooks, examples, versioning, glossary and error codes, status,message and another text field for format like json list,dictionary,array
User Section: The user can:
Select section Based on the admin added it should be multiselect.
Paste api payloads into a textarea and then 3rd dropdown is for after splitting convert into json,arry,list ir dictionary
in backend splitting api pay load beased on selected section by frontend after splitting convert into form by frontend request
Frontend Code (React):
import React, { useState, useEffect } from 'react';
const UserSection = () => {
const [sections, setSections] = useState([]);
const [selectedSections, setSelectedSections] = useState([]);
const [payload, setPayload] = useState('');
const [format, setFormat] = useState('');
useEffect(() => {
// Fetch available sections from the backend (these are dynamic)
fetch('/fetch_sections')
.then((response) => response.json())
.then((data) => {
setSections(data);
})
.catch((error) => console.error('Error fetching sections:', error));
}, []);
const handleSubmit = () => {
if (!selectedSections.length || !payload || !format) {
alert('Please select sections, provide the payload, and choose a format.');
return;
}
const data = {
sections: selectedSections,
payload: payload,
format: format,
};
fetch('/process_api_payload', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(data),
})
.then((response) => response.json())
.then((data) => {
console.log('Processed Data:', data);
alert('Payload processed successfully.');
})
.catch((error) => {
console.error('Error processing payload:', error);
alert('Error processing payload.');
});
};
return (
<div>
<h3>User Section: Process API Payload</h3>
<h4>Select Sections:</h4>
<select multiple onChange={(e) => setSelectedSections([...e.target.selectedOptions].map(option => option.value))}>
{sections.map((section, index) => (
<option key={index} value={section}>
{section}
</option>
))}
</select>
<h4>API Payload:</h4>
<textarea
value={payload}
onChange={(e) => setPayload(e.target.value)}
placeholder="Paste API payload here"
rows="10"
cols="50"
></textarea>
<h4>Select Format:</h4>
<select onChange={(e) => setFormat(e.target.value)} value={format}>
<option value="">Select Format</option>
<option value="json">JSON</option>
<option value="list">List</option>
<option value="dictionary">Dictionary</option>
<option value="array">Array</option>
</select>
<button onClick={handleSubmit}>Submit</button>
</div>
);
};
export default UserSection;
Define the Section Model
Assuming you have a Section model that will store each section's details:
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
class Section(db.Model):
__tablename__ = 'sections' # Name of the table in your database
id = db.Column(db.Integer, primary_key=True)
section_name = db.Column(db.String(255), unique=True, nullable=False)
chunk_size = db.Column(db.Integer, default=500) # Default chunk size
chunk_overlap = db.Column(db.Integer, default=50) # Default chunk overlap
def __repr__(self):
return f"<Section {self.section_name}>"
Step 2: Create a Route to Fetch Sections
Create a route to retrieve all sections from the database:
@app.route("/fetch_sections", methods=["GET"])
def fetch_sections():
try:
# Fetch all sections from the database
sections_from_db = Section.query.all()
# Format the data in a list of dictionaries
sections_data = [
{
"section_name": section.section_name,
"chunk_size": section.chunk_size,
"chunk_overlap": section.chunk_overlap
}
for section in sections_from_db
]
return jsonify(sections_data), 200
except Exception as e:
return jsonify({"error": str(e)}), 500
Step 3: Update /process_api_payload to Use Database Sections
Modify the /process_api_payload route to retrieve the section data from the database instead of using an in-memory dictionary.
from langchain.text_splitter import RecursiveCharacterTextSplitter
@app.route("/process_api_payload", methods=["POST"])
def process_api_payload():
try:
data = request.get_json()
# Get data from frontend
sections_selected = data.get("sections") # List of sections selected by the user
payload = data.get("payload") # The actual API payload
format_type = data.get("format") # Desired format (json, array, list, dictionary)
if not sections_selected or not payload or not format_type:
return jsonify({"error": "Sections, payload, and format are required."}), 400
# Initialize the result list to store the chunked data
result = []
# Loop through each selected section and apply text splitting
for section in sections_selected:
# Retrieve section details from the database
section_data = Section.query.filter_by(section_name=section).first()
if not section_data:
return jsonify({"error": f"Section '{section}' not found."}), 404
chunk_size = section_data.chunk_size
chunk_overlap = section_data.chunk_overlap
# Initialize the splitter for the specific section
splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
# Split the payload based on the section configuration
chunks = splitter.split_text(payload)
# Append the chunks to the result
result.extend(chunks)
# Convert the result based on the selected format
if format_type == "json":
return jsonify({"message": "Payload processed successfully.", "data": result}), 200
elif format_type == "list":
return jsonify({"message": "Payload processed successfully.", "data": list(result)}), 200
elif format_type == "dictionary":
result_dict = {i: chunk for i, chunk in enumerate(result)}
return jsonify({"message": "Payload processed successfully.", "data": result_dict}), 200
elif format_type == "array":
return jsonify({"message": "Payload processed successfully.", "data": result}), 200
else:
return jsonify({"error": "Invalid format selected."}), 400
except Exception as e:
return jsonify({"error": str(e)}), 500
Step 4: Admin Route to Add New Sections
Add a route to allow admins to add new sections dynamically to the database:
@app.route("/add_section", methods=["POST"])
def add_section():
try:
data = request.get_json()
section_name = data.get("section_name")
chunk_size = data.get("chunk_size", 500)
chunk_overlap = data.get("chunk_overlap", 50)
if not section_name:
return jsonify({"error": "Section name is required."}), 400
# Check if the section already exists
existing_section = Section.query.filter_by(section_name=section_name).first()
if existing_section:
return jsonify({"error": "Section already exists."}), 400
# Add new section to the database
new_section = Section(section_name=section_name, chunk_size=chunk_size, chunk_overlap=chunk_overlap)
db.session.add(new_section)
db.session.commit()
return jsonify({"message": f"Section '{section_name}' added successfully!"}), 200
except Exception as e:
return jsonify({"error": str(e)}), 500
===============================================================
import os
import zipfile
import json
import tempfile
from flask import Flask, request, jsonify
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
from io import BytesIO
from flask_cors import CORS
app = Flask(__name__)
CORS(app)
# Initialize LangChain model (ChatGPT through LangChain)
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.7, openai_api_key="YOUR_OPENAI_API_KEY")
# Function to extract the ZIP file and read its contents
def extract_zip_file(file):
with tempfile.TemporaryDirectory() as tempdir:
# Extract the files into a temporary directory
with zipfile.ZipFile(file, 'r') as zip_ref:
zip_ref.extractall(tempdir)
# Read all the code files
code_files = []
for root, dirs, files in os.walk(tempdir):
for file_name in files:
if file_name.endswith(('.py', '.js', '.dart')): # Adjust based on code file types
with open(os.path.join(root, file_name), 'r') as f:
code_files.append(f.read())
return code_files
# Function to use LangChain to analyze the code and suggest fixes
def analyze_and_fix_code(code):
try:
# Create a LangChain prompt template for code analysis
prompt_template = ChatPromptTemplate.from_template(
"Here is a code snippet:\n{code}\n\nIdentify any bugs or issues, and provide suggested fixes or improvements."
)
# Create a LangChain chain using the LLM and prompt template
chain = LLMChain(llm=llm, prompt=prompt_template)
# Run the chain with the code input
result = chain.run({"code": code})
return result.strip()
except Exception as e:
return f"Error: {str(e)}"
# Endpoint to handle the ZIP file upload and bug fix request
@app.route('/upload_zip_and_analyze', methods=['POST'])
def upload_zip_and_analyze():
if 'file' not in request.files:
return jsonify({'error': 'No file part'}), 400
file = request.files['file']
if file.filename == '':
return jsonify({'error': 'No selected file'}), 400
if file and file.filename.endswith('.zip'):
# Extract code from the ZIP file
code_files = extract_zip_file(file)
# Combine all the code files into one large string
full_code = "\n\n".join(code_files)
# Analyze the code and generate AI suggestions for bug fixes
ai_suggestions = analyze_and_fix_code(full_code)
return jsonify({'success': True, 'ai_suggestions': ai_suggestions}), 200
else:
return jsonify({'error': 'Invalid file format. Please upload a ZIP file.'}), 400
if __name__ == '__main__':
app.run(debug=True)

Top comments (0)