Difference between convolution and pooling
stride and padding
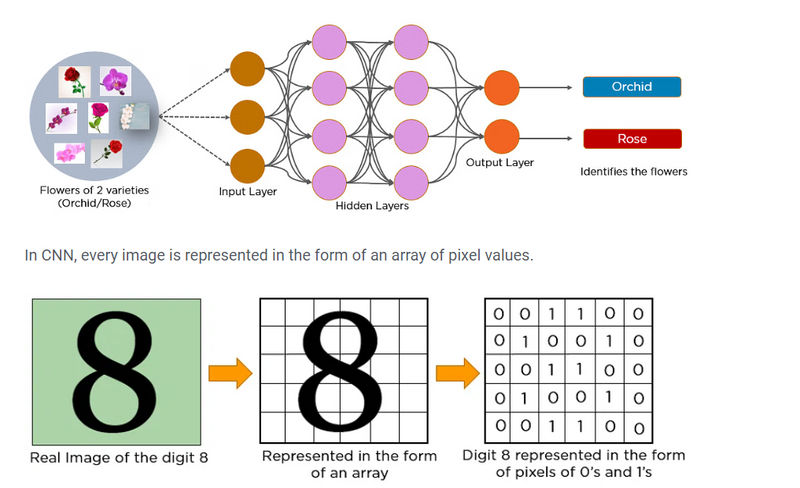
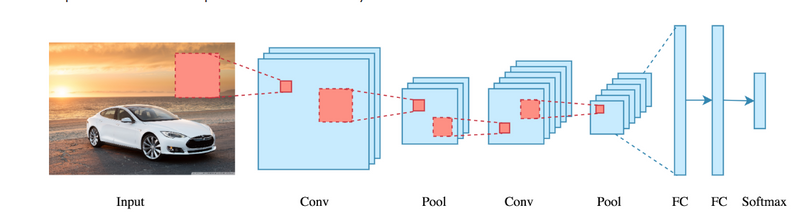
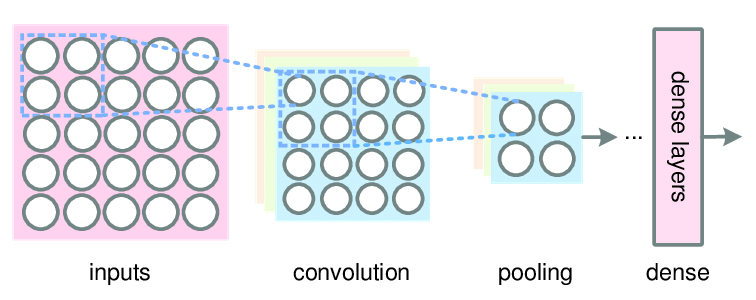
A convolutional neural network is a feed-forward neural network that is generally used to analyze visual images by processing data with grid-like topology. It’s also known as a ConvNet. A convolutional neural network is used to detect and classify objects in an image.
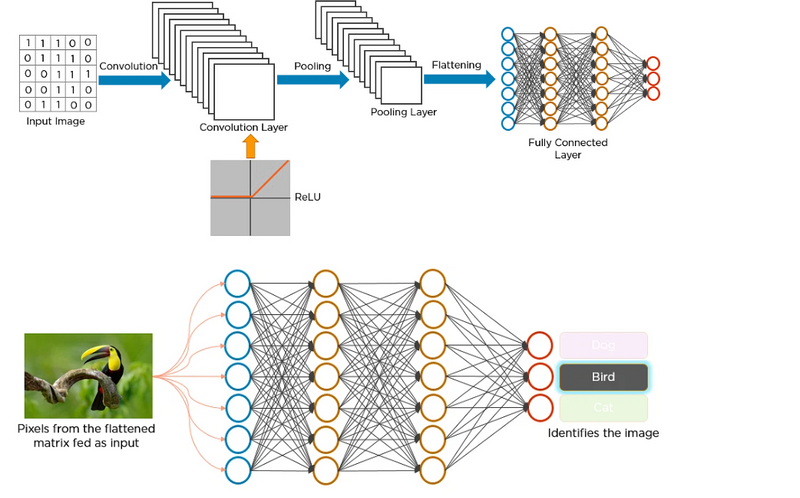
Below is a neural network that identifies two types of flowers: Orchid and Rose.
The typical structure of a CNN consists of three basic layers
Convolutional layer: These layers generate a feature map by sliding a filter over the input image and recognizing patterns in images.
Pooling layers: These layers downsample the feature map to introduce Translation invariance, which reduces the overfitting of the CNN model.
Fully Connected Dense Layer: This layer contains the same number of units as the number of classes and the output activation function such as “softmax” or “sigmoid”
The convolution operation forms the basis of any convolutional neural network. Let’s understand the convolution operation using two matrices, a and b, of 1 dimension.
a = [5,3,7,5,9,7]
b = [1,2,3]
In convolution operation, the arrays are multiplied element-wise, and the product is summed to create a new array, which represents a*b.
The first three elements of the matrix a are multiplied with the elements of matrix b. The product is summed to get the result

This process continues until the convolution operation is complete.
How Does CNN Recognize Images?
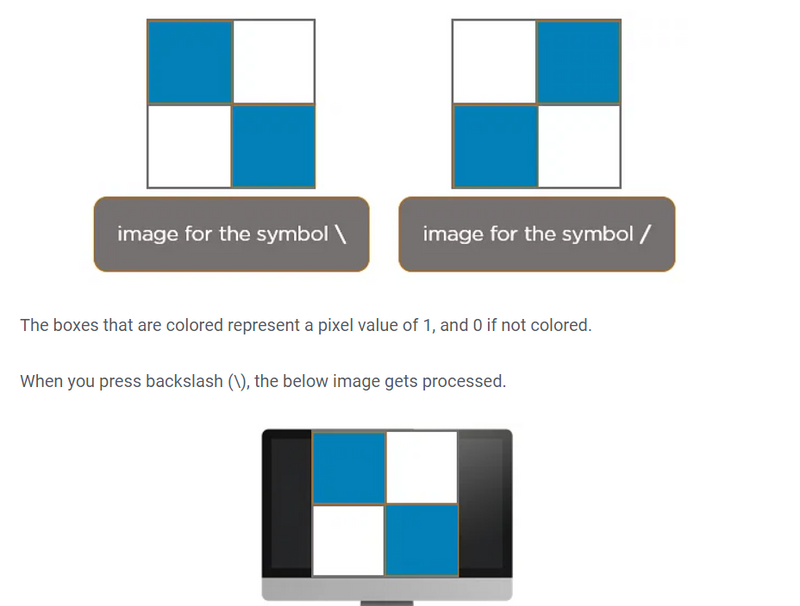

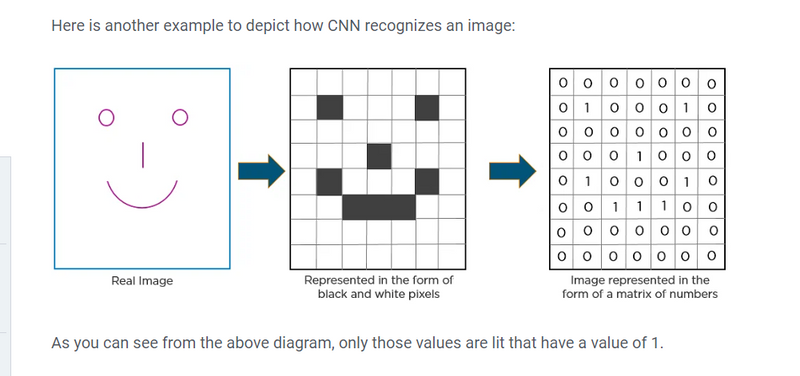
Layers in a Convolutional Neural Network
A convolution neural network has multiple hidden layers that help in extracting information from an image. The four important layers in CNN are:
Convolution layer
ReLU layer
Pooling layer
Fully connected layer
Convolution Layer
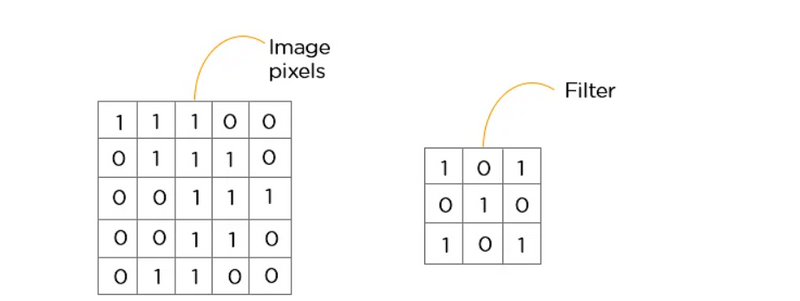
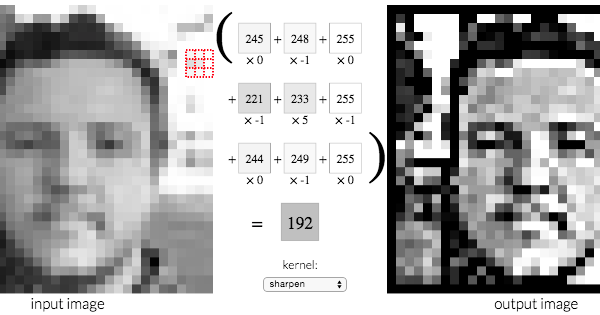
This is the first step in the process of extracting valuable features from an image. A convolution layer has several filters that perform the convolution operation. Every image is considered as a matrix of pixel values.
Consider the following 5x5 image whose pixel values are either 0 or 1. There’s also a filter matrix with a dimension of 3x3. Slide the filter matrix over the image and compute the dot product to get the convolved feature matrix.
ReLU layer
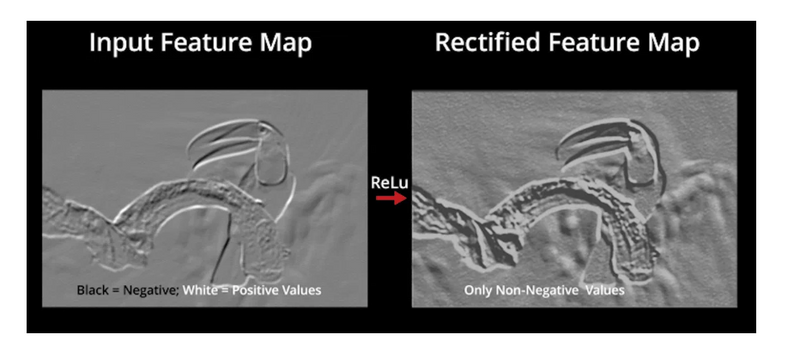
ReLU stands for the rectified linear unit. Once the feature maps are extracted, the next step is to move them to a ReLU layer.
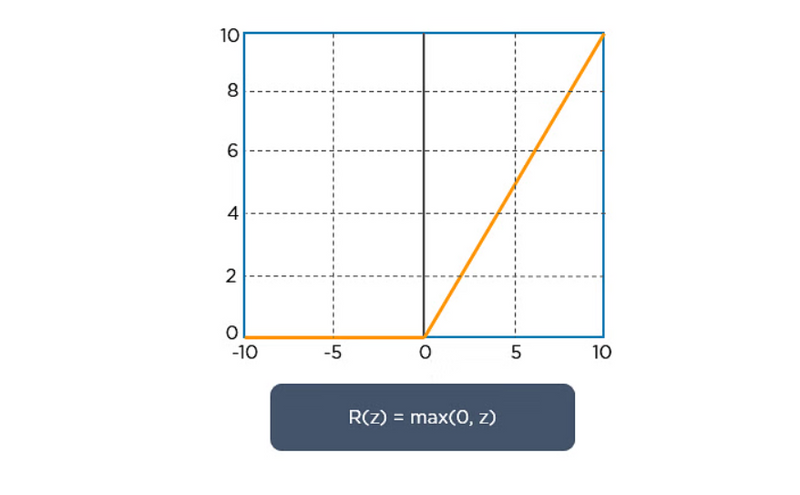
ReLU performs an element-wise operation and sets all the negative pixels to 0. It introduces non-linearity to the network, and the generated output is a rectified feature map. Below is the graph of a ReLU function:
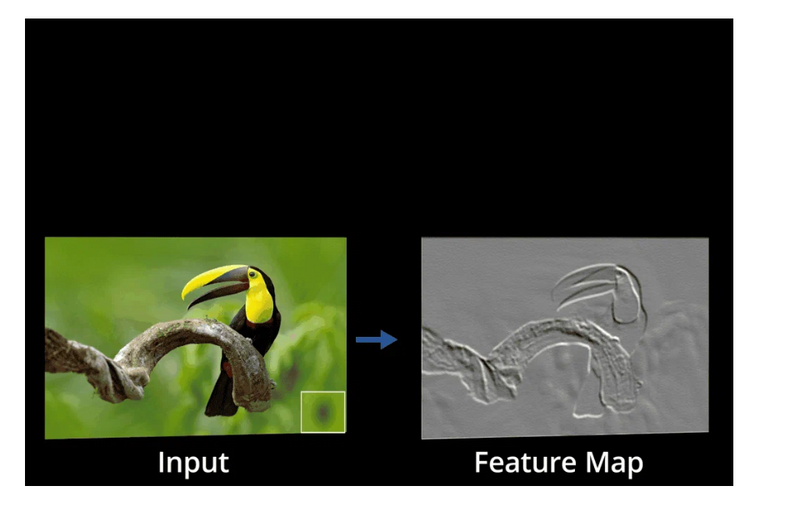
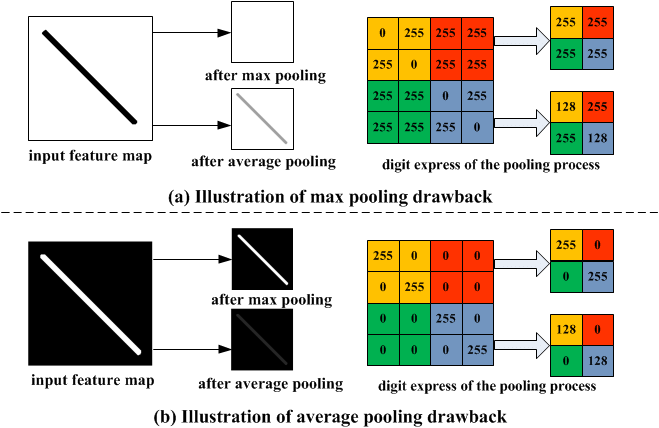
Pooling Layer
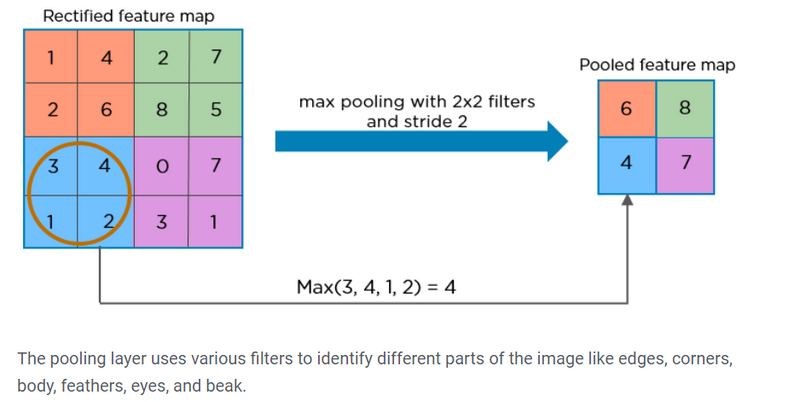
Pooling is a down-sampling operation that reduces the dimensionality of the feature map. The rectified feature map now goes through a pooling layer to generate a pooled feature map.
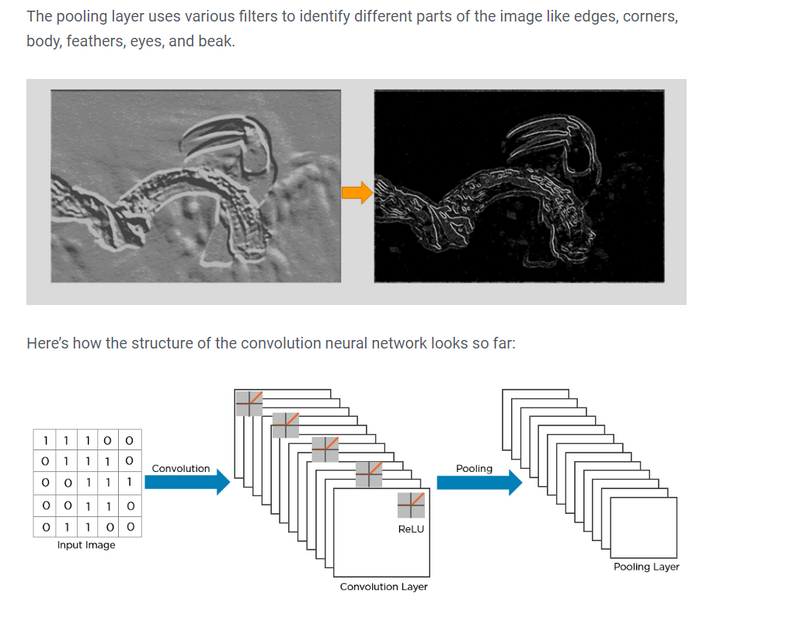
Here’s how exactly CNN recognizes a bird:
- The pixels from the image are fed to the convolutional layer that performs the convolution operation
- It results in a convolved map
- The convolved map is applied to a ReLU function to generate a rectified feature map
- The image is processed with multiple convolutions and ReLU layers for locating the features
- Different pooling layers with various filters are used to identify specific parts of the image
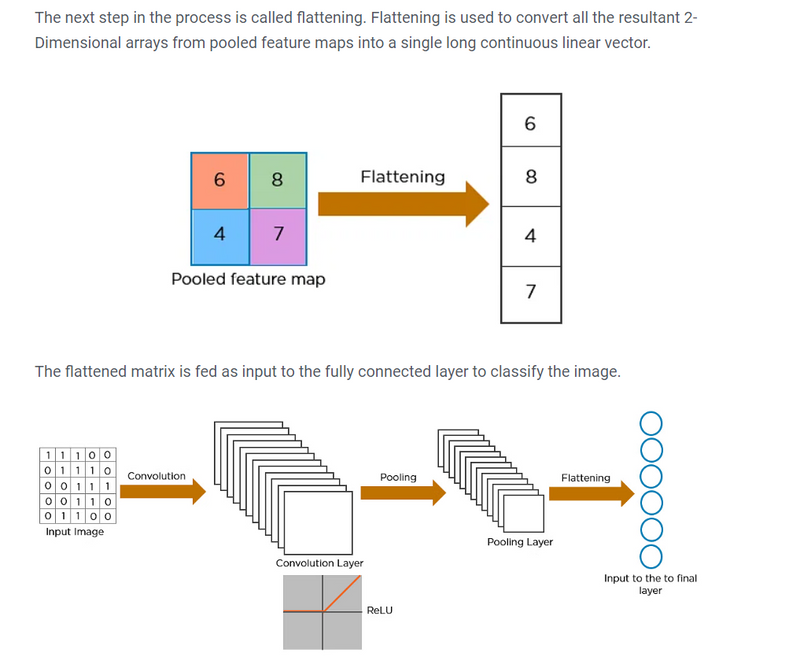
- The pooled feature map is flattened and fed to a fully connected layer to get the final output
Difference between convolution and pooling
Convolution and pooling are two fundamental operations in Convolutional Neural Networks (CNNs) used for feature extraction and dimensionality reduction in image processing tasks. Here's a brief explanation of each, along with an example:
Convolution:
Convolution is a mathematical operation that applies a filter (also known as a kernel) to an input image. It is used to extract features from the input image by sliding the filter over the image and performing element-wise multiplications and summations at each position. Convolution helps detect patterns and local features in the image.
Example: Let's say you have a grayscale image with pixel values represented as a matrix:
Example: Let's say you have a grayscale image with pixel values represented as a matrix:
Input Image:
[1, 2, 1]
[0, 1, 0]
[2, 3, 2]
You can apply a 3x3 filter, such as an edge detection filter:
Filter:
[1, 0, -1]
[0, 0, 0]
[-1, 0, 1]
Applying convolution, you slide the filter over the input image, perform element-wise multiplications, and sum the results at each position to obtain a feature map:
Feature Map:
[2, -3, 2]
[3, -6, 3]
[4, -6, 4]
Pooling:
Pooling is a down-sampling operation that reduces the spatial dimensions of the feature maps while retaining essential information. The most common pooling operation is max-pooling, which extracts the maximum value from a group of neighboring pixels in the feature map.
Example: Taking the feature map from the previous example, you can perform max-pooling with a 2x2 window:
Feature Map:
[2, -3, 2]
[3, -6, 3]
[4, -6, 4]
Max-pooling with a 2x2 window (non-overlapping) would produce the following pooled feature map:
Pooled Feature Map:
[3, 3]
[4, 4]
In this example, convolution helps detect edges and local patterns in the input image, and pooling reduces the spatial dimensions and retains the most prominent features. These operations are essential for building deep learning models that can automatically extract hierarchical features from images, making CNNs effective in various computer vision tasks, such as image classification, object detection, and segmentation.
stride and padding
Stride and padding are two important parameters used in Convolutional Neural Networks (CNNs) to control the spatial dimensions of feature maps and influence the behavior of convolutional layers. Here's an explanation of their uses:
Stride:
- Stride is a hyperparameter that determines the step size at which the convolutional filter (or kernel) moves across the input data during the convolution operation.
- A stride of 1 means the filter moves one pixel at a time, covering the entire input.
- A larger stride (e.g., 2 or more) results in the filter skipping pixels during the convolution, which reduces the spatial dimensions of the output feature map.
- Larger stride values can be used to down-sample the feature maps and reduce computational complexity, especially in deeper layers of the network . Example: If you have a 5x5 input and apply a 3x3 convolution with a stride of 2, the output feature map will be smaller, and the filter will move in steps of 2 pixels.
Padding:
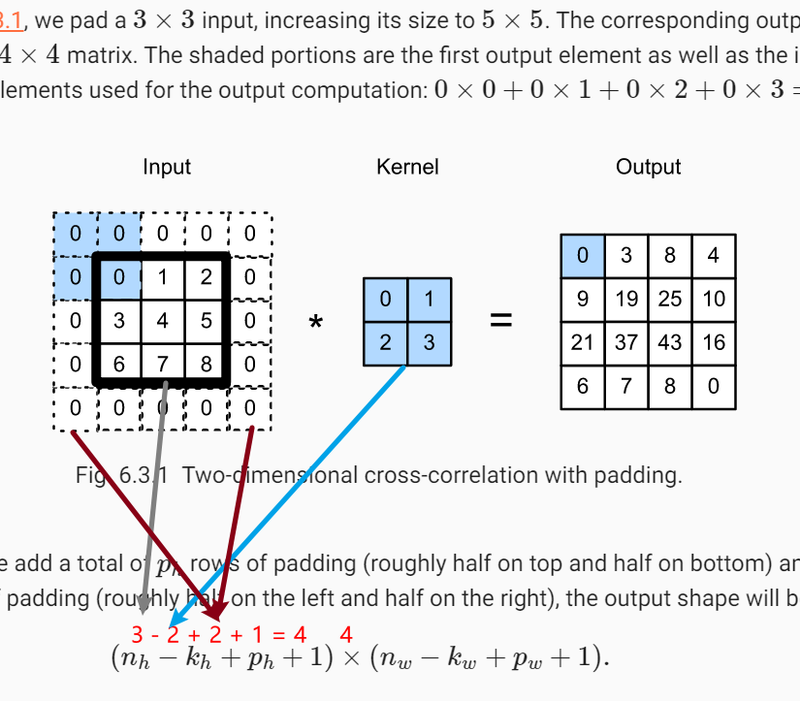
- Padding is another hyperparameter that determines how the input data is padded with zeros around its borders before applying the convolution operation.
- Padding is used to control the spatial dimensions of the output feature map and to preserve information at the edges of the input.
- Two common types of padding are "valid" (no padding) and "same" (zero-padding is added so that the output feature map has the same spatial dimensions as the input when using a stride of 1 ). Example: If you have a 5x5 input and apply a 3x3 convolution with "valid" padding, the output feature map will be smaller. If you use "same" padding, the output feature map will be of the same spatial dimensions as the input.
Uses:
- Stride and padding are often used to control the size of feature maps in a CNN.
- Stride can be used for down-sampling when a network needs to reduce spatial dimensions. It can be applied to the convolutional and pooling layers.
- Padding can be used to preserve spatial information, especially when the goal is to maintain the output dimensions. "Same" padding is often used to ensure the output feature map has the same size as the input
The choice of stride and padding depends on the specific architecture, task, and trade-offs between spatial resolution, computational complexity, and feature extraction.
.
Explain all parameter of Convolutional Layers in deep learning
Convolutional layers are a fundamental building block in convolutional neural networks (CNNs), which are widely used for image recognition, computer vision, and other tasks. These layers are designed to automatically and adaptively learn spatial hierarchies of features from input data. Let's explore the parameters of a typical convolutional layer in deep learning:
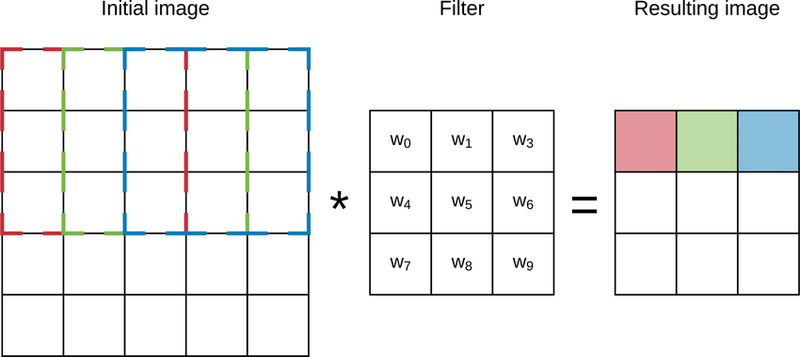
Filters (Kernels):
Definition: Filters are small-sized matrices (usually 3x3 or 5x5) that are used to extract features from the input data. Each filter slides or convolves across the input image, producing feature maps.The number of filters or kernels in the convolutional layer. Each filter produces a different feature in the output
Example: If you have a 3x3 filter, it will scan a 3x3 region of the input image and detect patterns or features like edges or textures.
from tensorflow.keras.layers import Conv2D
model.add(Conv2D(filters=32, kernel_size=(3, 3), input_shape=(64, 64, 3)))
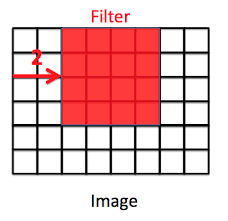
Stride:
Definition: Stride is the step size the filter takes as it slides across the input. A larger stride reduces the spatial dimensions of the output feature map.
Example: If the stride is set to 2, the filter will move two pixels at a time instead of one, resulting in a downsampled feature map.
The step size the filter takes while sliding over the input. It is specified as a tuple representing the stride along the height and width
model.add(Conv2D(filters=128, kernel_size=(3, 3), strides=(2, 2), input_shape=(256, 256, 3)))
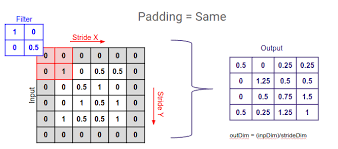
Padding:
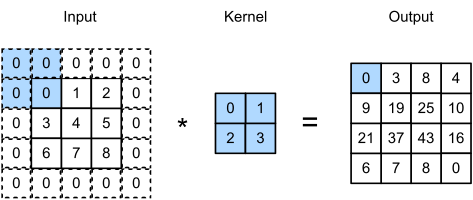
Definition: Padding involves adding extra pixels to the input data to prevent information loss at the edges when applying filters. Padding is useful to maintain spatial dimensions.
Example: If a 5x5 filter is applied to a 7x7 image with padding of 1, extra rows and columns are added, making the input image 9x9. This helps to keep the spatial size the same after convolution.
The type of padding applied to the input. It can be 'valid' (no padding) or 'same' (zero-padding to keep the spatial dimensions).
model.add(Conv2D(filters=256, kernel_size=(3, 3), padding='same', input_shape=(128, 128, 3)))
Activation Function:
Definition: After the convolution operation, an activation function (e.g., ReLU - Rectified Linear Unit) is applied element-wise to introduce non-linearity into the network.
Example: If the output of a convolutional operation is x, ReLU activation will set all negative values to 0 and leave positive
The activation function applied to the output of the convolutional layer.
values unchanged: ReLU(x) = max(0, x).
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu', input_shape=(64, 64, 3)))
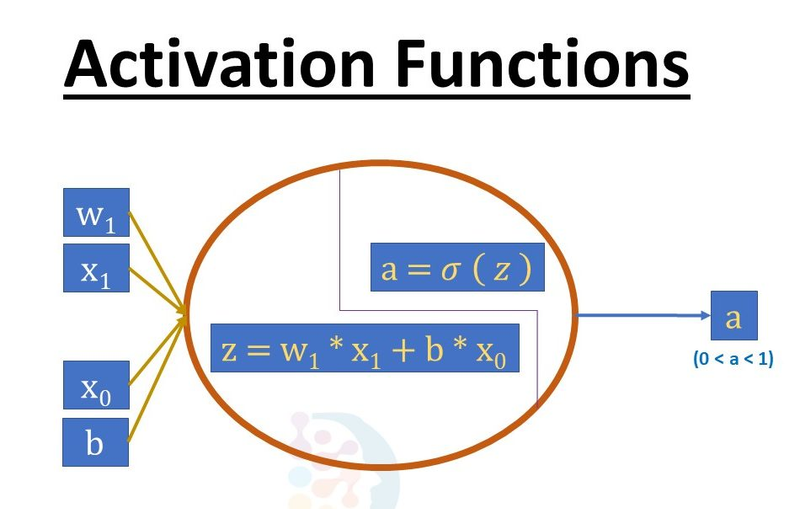
Input Channels (Depth):
Definition: The number of input channels corresponds to the number of color channels in an image (e.g., 3 for RGB). Each channel is convolved with its set of filters.
Example: For a color image, each of the red, green, and blue channels is processed separately.
model.add(Conv2D(filters=32, kernel_size=(3, 3), input_shape=(128, 128, 3)))
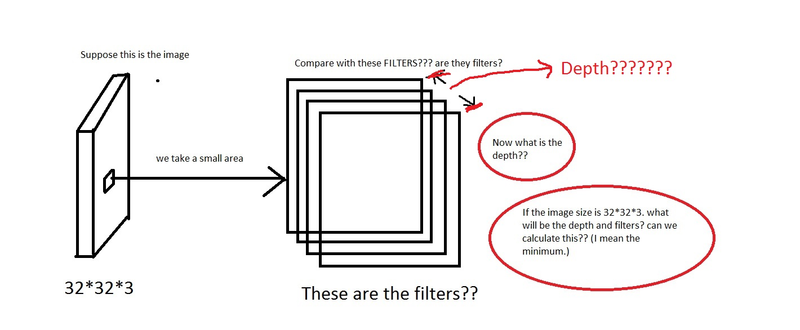
This creates the first convolutional layer with 32 filters, a kernel size of 3x3, and input data of shape (128, 128, 3)
Output Channels:
Definition: The number of filters in the convolutional layer determines the number of output channels. Each filter produces one channel in the output feature map.
Example: If you have 32 filters, the output will have 32 channels, each capturing different features.
Kernel Size (or kernel_size):
Definition: The size of the convolutional filters. It is specified as a tuple representing the height and width of the filters.
model.add(Conv2D(filters=64, kernel_size=(5, 5), input_shape=(128, 128, 3)))
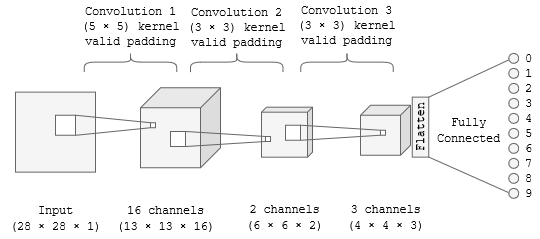
These parameters collectively define the behavior of a convolutional layer and influence the learning and representation of features in a neural network. Adjusting these parameters allows network architects to control the capacity, resolution, and complexity of the learned features.
stride and padding are essential parameters in CNNs that allow you to control the size and behavior of the output feature maps, enabling you to design networks that are effective for various computer vision tasks

Top comments (0)