In machine learning and natural language processing (NLP), regular expressions are sometimes used for text preprocessing and pattern matching. Here are 20 different types of examples where you might use re.findall() in machine learning:
Email Extraction:
URL Extraction:
Hashtag Extraction:
Mention Extraction:
Date Extraction:
Phone Number Extraction:
Numeric Value Extraction:
Acronym Extraction:
Entity Extraction:
Code Snippet Extraction:
Emoji Extraction:
HTML Tag Extraction:
Keyword Extraction:
IP Address Extraction:
Version Number Extraction:
License Key Extraction:
Product Code Extraction:
ISBN Extraction:
Scientific Notation Extraction:
Custom Pattern Matching:
Matching specific word using findall
Matching multiple specific word using findall
Matching single specific word and ignore special char and case sensitive using findall
Extracting digits within text using findall
Extracting non digits within text using findall
Extracting specific digits within text using findall
Extracting specific range digits 0 to 10 within text using findall
Extracting specific range digits 20 to 49 within text using findall
Extracting digits from list of string using findall
Extracting 5 letters of word from list of string with specified boundry using findall
Extracting 5 letters of word from string using findall
Extracting some range of word from string using findall
Extracting string begins with A and ends with J from string using findall
Date Extraction example of regx using findall
extract acronyms define a pattern that matches words in all uppercase letters at least 2 character
find all words that are at least 4 characters long in a string
find all three, four, and five character words in a string
split a string into uppercase letters.
match a date string in the form of Month name followed by day number and year like September 18, 2023
find the substrings is available if it is available then find its position range then put in list like [(22, 31), (36, 45)] within a string
print the numbers and their position of a given string
**separate string based on digits and put all digits in list then find its position
find sequences of one upper case letter followed by lower case letters
word frequency analysis
Extracting email addresses from a text corpus.
Common Regular Expression
2 ways to represent digit==\d or [0-9]
2 ways to represent word===\W or [A-Za-z]
words = re.findall(r'\d+', pattern) ===>
['123', '678']
words = re.findall(r'\d', pattern)
['123', '678']==>
['1', '2', '3', '6', '7', '8']
match.start()==>substring or digits starting position
match.end()==>substring or digits ending position
match.group()===> found substring or digits on text
words = re.findall(r'\d+', pattern) ===>
['123', '678']
words = re.findall(r'\d', pattern)
['123', '678']==>
['1', '2', '3', '6', '7', '8']
a.b matches "axb", "a2b", "a@b", etc.
ca*t matches "ct", "cat", "caaat", etc.
ca+t matches "cat", "caaat", but not "ct".
colou?r matches "color" and "colour"
cat|dog matches either "cat" or "dog".
^[A-Z][a-z]+ match start with uppercase letter followed by one or more lowercase letter eg Importanve,Hero
[aeiou] matches any vowel.
[^0-9] matches any non-digit character.
(abc)+ matches "abc", "abcabc", etc.
a{3} matches "aaa".
\$ matches a dollar sign "$".
^Start matches "Start of text"
,\s* ==split string by comma
re.split(r'\d', text) ==>split string by digit
text.split(',') split string by comma
text.split('is', 1) string at the first occurrence of 'is'
re.split(r'\s*\.\s*', text) split string by dot
re.split(r'\s*\|\s*', text) split string by |
end$ matches "end of text".
\bword\b matches "word" but not "wording".
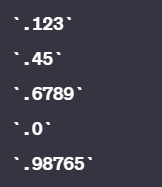
(\.\d+)? Match: .14 and Match: .99
\d{2} matches any two-digit number.

r'[^\w\s]' ==>not a word character (\w) or a whitespace character
\w+ matches one or more word characters
a\sb matches "a b".
\w{4,} ==>find all words at least 4 characters long in a string
(?i)abc matches "abc", "ABC", "AbC", etc.
a.b matches "a\nb" when using (?s).
(\.\d+)+
[A-Za-z0-9._%+-]

[A-Z|a-z]{2,7}

\S+
#\w+ ===> ['#MachineLearning', '#DataScience']
+? ==> makes + sign optional
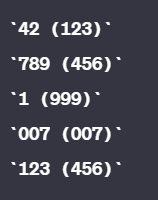
\d{1,3} \(\d{3}\)
\b[A-Z]{2,}\b

\b\w+\b

import re
text = "Contact us at info@example.com or support@test.org"
pattern = r"\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,7}\b"
result = re.findall(pattern, text)
print(result)
# Output: ['info@example.com', 'support@test.org']
Certainly, here's a real-world example that demonstrates the use of the regular expression [A-Za-z0-9._%+-] in Python to extract valid email addresses from a text:
output:
import re
# Sample text containing email addresses
text = "Please contact john.doe@example.com for inquiries or support. For more information, email info%my-site.com."
# Define the regular expression pattern to match email addresses
pattern = r"[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,7}"
# Use the findall function to extract all email addresses from the text
matches = re.findall(pattern, text)
# Print the matched email addresses
for match in matches:
print(match)
output
john.doe@example.com
info%my-site.com

URL Extraction:
Extracting URLs or hyperlinks from web content.
import re
text = "Visit our website at https://www.example.com for more information."
pattern = r"https?://\S+"
result = re.findall(pattern, text)
print(result)
# Output: ['https://www.example.com']

Hashtag Extraction:
Extracting hashtags from social media posts.
import re
text = "Join the conversation with #MachineLearning and #DataScience."
pattern = r"#\w+"
result = re.findall(pattern, text)
print(result)
# Output: ['#MachineLearning', '#DataScience']
Mention Extraction:
Extracting mentions or usernames from social media posts.
import re
text = "The meeting is scheduled for 2023-09-15 and 09/20/2023."
pattern = r"\d{4}-\d{2}-\d{2}|\d{2}/\d{2}/\d{4}"
result = re.findall(pattern, text)
print(result)
# Output: ['2023-09-15', '09/20/2023']
Date Extraction:
Extracting dates in various formats from documents.
import re
text = "The meeting dates are 2023-09-15 and 09/20/2023. Don't forget the event on 12-31-2022."
# Use a regular expression pattern to match dates in various formats
pattern = r"\d{4}-\d{2}-\d{2}|\d{2}/\d{2}/\d{4}|\d{2}-\d{2}-\d{4}"
dates = re.findall(pattern, text)
print(dates)
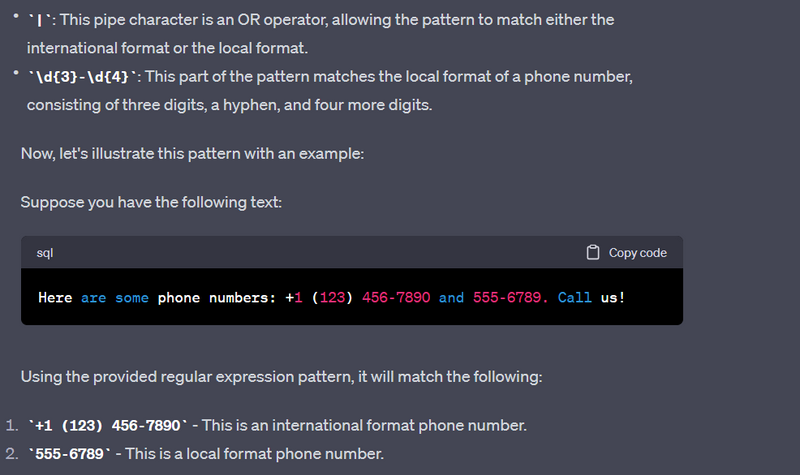
Phone Number Extraction:
Extracting phone numbers with different formats.
import re
text = "Call us at +1 (123) 456-7890 or 555-5555."
pattern = r"\+?\d{1,3} \(\d{3}\) \d{3}-\d{4}|\d{3}-\d{4}"
result = re.findall(pattern, text)
print(result)
# Output: ['+1 (123) 456-7890', '555-5555']

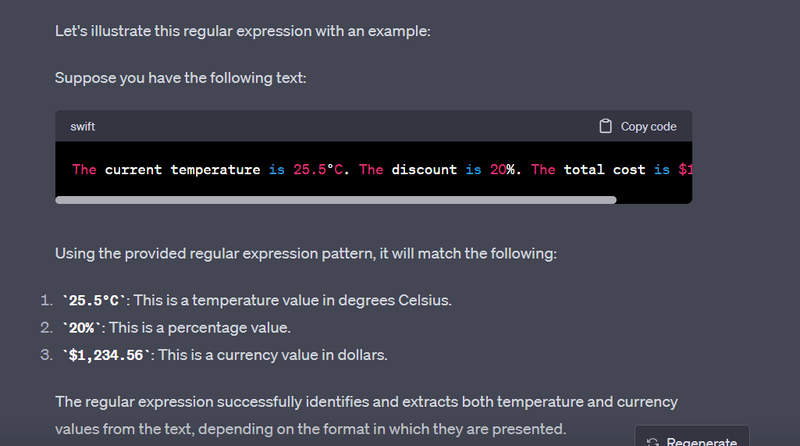
Numeric Value Extraction:
Extracting numeric values like currency amounts, percentages, or measurements from text.
import re
text = "The total cost is $500.50, which is 20% of the total. The temperature is 25.5°C."
# Use a regular expression pattern to match numeric values
pattern = r"\d+(\.\d+)?%?°?C?|\$[\d,.]+"
numeric_values = re.findall(pattern, text)
print(numeric_values)

Acronym Extraction:
Identifying and extracting acronyms or abbreviations from documents.
import re
text = "NASA (National Aeronautics and Space Administration) is a famous organization. FBI (Federal Bureau of Investigation) is another one."
# Use a regular expression pattern to match acronyms in uppercase letters
pattern = r'\b[A-Z]{2,}\b'
acronyms = re.findall(pattern, text)
print(acronyms)

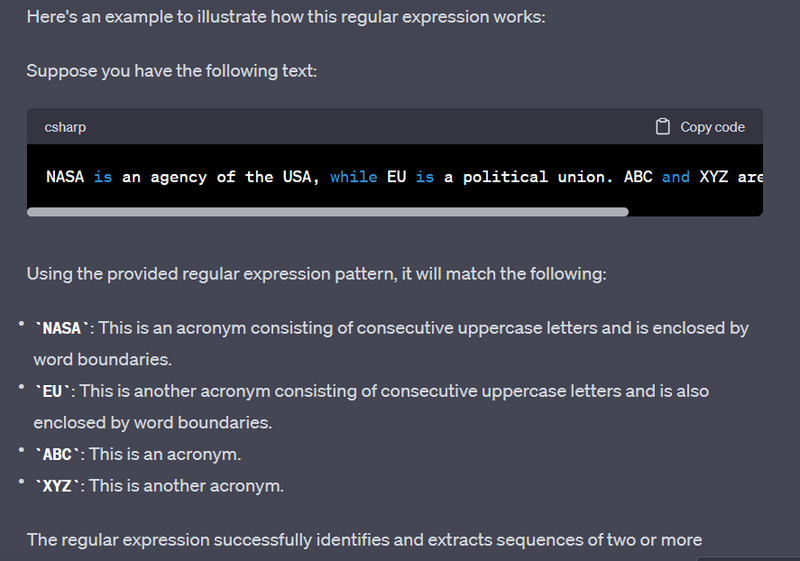
The regular expression successfully identifies and extracts sequences of two or more consecutive uppercase letters that are considered acronyms in the given text.
Entity Extraction:
Extracting specific named entities like persons, organizations, or locations from text.
import re
text = "Apple Inc. is headquartered in Cupertino, California."
pattern = r"\b[A-Z][a-z]+(?:\s[A-Z][a-z]+)*\b"
result = re.findall(pattern, text)
print(result)
# Output: ['Apple Inc.', 'Cupertino', 'California']

Code Snippet Extraction:
Extracting code snippets or programming constructs from source code.
import re
code = """
def calculate_area(length, width):
return length * width
"""
pattern = r"def\s\w+\(.*\):"
result = re.findall(pattern, code)
print(result)
# Output: ['def calculate_area(length, width):']
Emoji Extraction:
Extracting emojis from text data, useful for sentiment analysis.
import re
text = "😃 Hello, world! 🌍"
pattern = r"[\U0001F600-\U0001F64F\U0001F300-\U0001F5FF]"
result = re.findall(pattern, text)
print(result)
# Output: ['😃', '🌍']
HTML Tag Extraction:
Extracting HTML tags or attributes from web pages.
import re
html = "<p>This is a <b>bold</b> statement.</p>"
pattern = r"<.*?>"
result = re.findall(pattern, html)
print(result)
# Output: ['<p>', '</b>', '</p>']
Keyword Extraction:
Extracting important keywords or phrases from documents for document summarization or keyword analysis.
import re
text = "Keywords: machine learning, deep learning, NLP, AI"
pattern = r"\b\w+\b"
result = re.findall(pattern, text)
print(result)
# Output: ['Keywords', 'machine', 'learning', 'deep', 'learning', 'NLP', 'AI']
IP Address Extraction:
Extracting IP addresses from log files or network data.
import re
text = "Server log: 192.168.1.1, 10.0.0.2, 172.16.0.1"
pattern = r"\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b"
result = re.findall(pattern, text)
print(result)
# Output: ['192.168.1.1', '10.0.0.2', '172.16.0.1']
Version Number Extraction:
Extracting version numbers from software release notes or documents.
import re
text = "Version 2.1.0 released with new features."
pattern = r"\d+(\.\d+)+"
result = re.findall(pattern, text)
print(result)
# Output: ['2.1.0']
License Key Extraction:
Extracting software license keys from user input.
import re
text = "License Key: ABCD-1234-EFGH-5678"
pattern = r"[A-Z]{4}-\d{4}-[A-Z]{4}-\d{4}"
result = re.findall(pattern, text)
print(result)
# Output: ['ABCD-1234-EFGH-5678']
Product Code Extraction:
Extracting product codes or SKUs from product listings.
import re
text = "Product codes: ABC123, XYZ456, DEF789"
pattern = r"[A-Z]{3}\d{3}"
result = re.findall(pattern, text)
print(result)
# Output: ['ABC123', 'XYZ456', 'DEF789']
ISBN Extraction:
Extracting International Standard Book Numbers (ISBNs) from bibliographic data.
import re
text = "ISBN-13: 978-0-13-449416-6, ISBN-10: 0134494164"
pattern = r"ISBN-(13|10): \d{3}-\d{1,5}-\d{1,7}-\d{1}"
result = re.findall(pattern, text)
print(result)
# Output: ['ISBN-13: 978-0-13-449416-6', 'ISBN-10: 0134494164']
Scientific Notation Extraction:
Extracting numbers in scientific notation from scientific articles.
import re
text = "Scientific notation: 3.0e-5 and 2.5e+10"
pattern = r"\d+\.\d+e[+-]\d+"
result = re.findall(pattern, text)
print(result)
# Output: ['3.0e-5', '2.5e+10']
Custom Pattern Matching:
Creating custom regular expressions to match specific patterns or structures unique to your dataset.
These are just a few examples of how re.findall() can be used in machine learning and NLP for text preprocessing and data extraction tasks. Depending on your specific project and dataset, you may encounter various other use cases for regular expression-based pattern matching.
Matching specific word using findall
If you want to use re.findall() to match a specific word in a text, you can construct a regular expression pattern that matches that word. Here's an example of how to do this:
Suppose you want to find all occurrences of the word "apple" in a text:
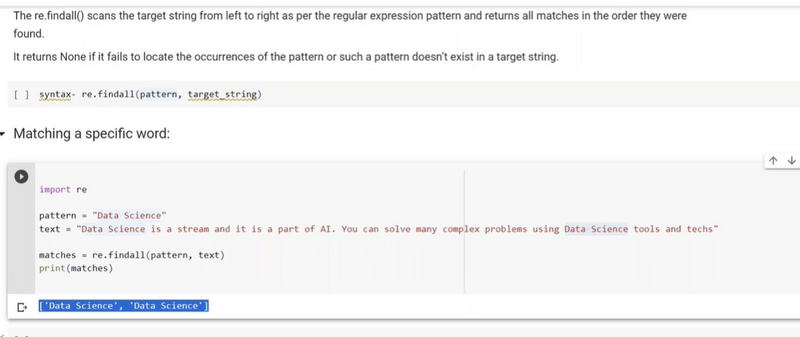
import re
text = "I have an apple, and I like to eat apples."
word_to_find = "apple"
# Construct a regular expression pattern to match the word "apple" as a whole word
pattern = r"\b" + re.escape(word_to_find) + r"\b"
result = re.findall(pattern, text, re.IGNORECASE) # Use re.IGNORECASE for case-insensitive matching
print(result)
# Output: ['apple', 'apple']
In this example:
We construct the pattern using the \b word boundary anchors to ensure that "apple" is matched as a whole word and not as part of other words.
We use re.escape() to escape any special characters in the word (in case the word contains characters with special meaning in regular expressions).
We use re.IGNORECASE as the optional flag to perform case-insensitive matching, so "Apple" and "apple" are both matched.
The re.findall() function will return a list containing all occurrences of the word "apple" in the text.
Extracting digits within text using findall
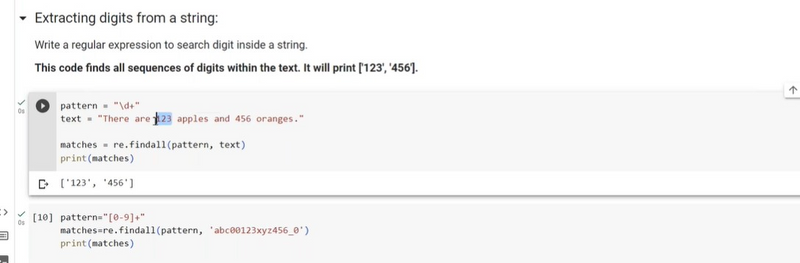
import re
text = "There are 42 apples and 7 oranges in the basket."
# Use the pattern \d+ to match one or more digits
pattern = r"\d+"
result = re.findall(pattern, text)
print(result)
# Output: ['42', '7']
In this example:
The regular expression pattern r"\d+" is used. Here's what it means:
\d matches any digit (0-9).
- matches one or more occurrences of the preceding pattern (in this case, one or more digits). The re.findall() function then finds and extracts all substrings that match this pattern in the input text and returns them as a list of strings. In this case, it extracts the digits "42" and "7" from the text.
Extracting specific digits within text using findall
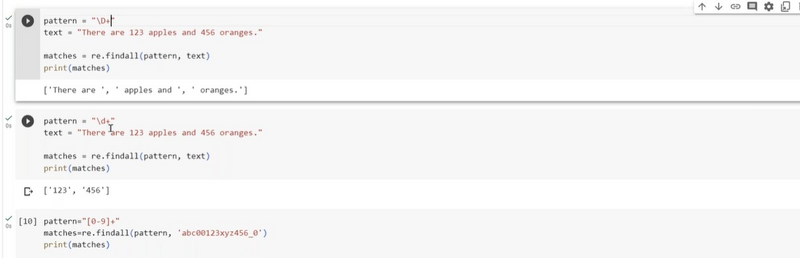
To extract specific digits within a text using re.findall(), you need to define a regular expression pattern that matches the digits you want to extract based on some criteria. Here's an example where we extract specific two-digit numbers from a text:
import re
text = "I have 42 apples, 7 oranges, and 99 grapes."
# Use the pattern \b\d{2}\b to match two-digit numbers as whole words
pattern = r"\b\d{2}\b"
result = re.findall(pattern, text)
print(result)
# Output: ['42', '99']
In this example:
The regular expression pattern r"\b\d{2}\b" is used. Here's what it means:
\b matches a word boundary to ensure that we match whole numbers, not parts of larger numbers.
\d matches any digit (0-9).
{2} specifies that we want to match exactly two digits.
Again, \b is used to ensure that we're matching whole words.
This pattern will find and extract all two-digit numbers that appear as whole words in the input text. In this case, it extracts "42" and "99" from the text. You can adjust the pattern to match specific digits or patterns based on your requirements.
Extracting specific range digits within text using findall
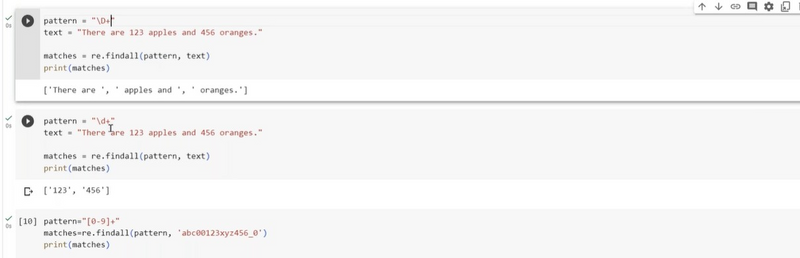
To extract specific range of digits within a text using re.findall(), you can define a regular expression pattern that matches digits falling within the desired range. Here's an example where we extract digits between 20 and 50 from a text:
import re
text = "I have 42 apples, 7 oranges, and 99 grapes. Some are between 20 and 50."
# Use the pattern \b[2-4][0-9]\b to match digits between 20 and 49 as whole words
pattern = r"\b[2-4][0-9]\b"
result = re.findall(pattern, text)
print(result)
# Output: ['42']
In this example:
The regular expression pattern r"\b[2-4][0-9]\b" is used. Here's what it means:
\b matches a word boundary to ensure that we match whole numbers, not parts of larger numbers.
[2-4] matches any digit between 2 and 4 (inclusive).
[0-9] matches any single digit (0-9).
Again, \b is used to ensure that we're matching whole words.
This pattern will find and extract all two-digit numbers that fall within the range of 20 to 49 as whole words in the input text. In this case, it extracts "42" from the text. You can adjust the pattern to match a different range or specific criteria based on your requirements.
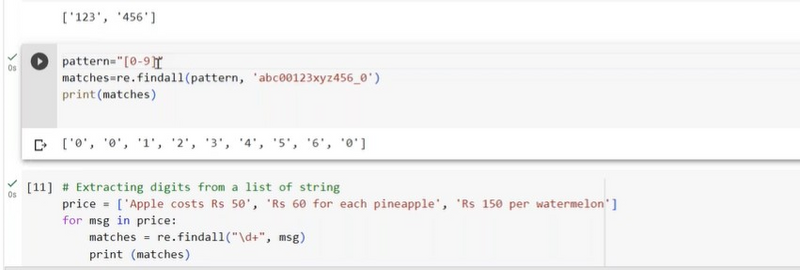
Extracting digits from list of string using findall
If you have a list of strings and you want to extract digits from each string using re.findall(), you can loop through the list and apply the re.findall() function to each string individually. Here's an example:
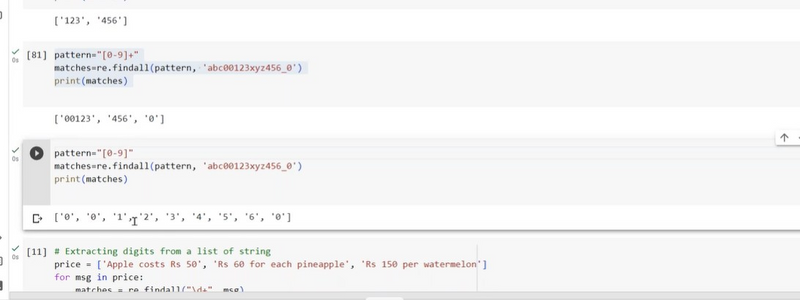
import re
text_list = ["I have 42 apples.", "There are 7 oranges.", "I want 99 grapes."]
# Use the pattern \d+ to match one or more digits in each string
pattern = r"\d+"
result_list = [re.findall(pattern, text) for text in text_list]
for i, result in enumerate(result_list):
print(f"Digits in string {i + 1}: {result}")
In this example:
The text_list variable contains a list of strings.
We define the regular expression pattern r"\d+" to match one or more digits.
We use a list comprehension to apply re.findall(pattern, text) to each string in text_list, extracting the digits from each string.
The result is a list of lists where each inner list contains the extracted digits from the corresponding string.
The output will show the digits extracted from each string in the list:
Digits in string 1: ['42']
Digits in string 2: ['7']
Digits in string 3: ['99']
This approach allows you to extract digits from each string in the list individually and collect the results in a structured format.
To extract digits from a list of strings using re.findall() and a simple for loop, you can iterate through the list and apply re.findall() to each string. Here's an example:
import re
text_list = ["I have 42 apples.", "There are 7 oranges.", "I want 99 grapes."]
# Use the pattern \d+ to match one or more digits
pattern = r"\d+"
digit_list = [] # Initialize an empty list to store the extracted digits
for text in text_list:
digits = re.findall(pattern, text)
digit_list.extend(digits) # Extend the list with the extracted digits
print(digit_list)
In this example:
We iterate through each string in the text_list.
For each string, we apply the re.findall(pattern, text) function to extract the digits.
The extracted digits are added to the digit_list using the extend method to create a flat list of all the extracted digits.
The output will be a list containing all the extracted digits from the strings:
['42', '7', '99']
This approach uses a simple for loop to extract digits from each string in the list and collects them into a single list.
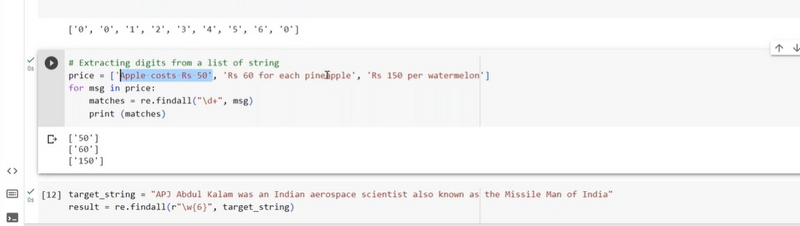
Extracting 5 letters of word from list of string using findall
If you want to extract 5-letter words from a list of strings using re.findall(), you can define a regular expression pattern that matches such words. Here's an example:
import re
text_list = ["Apple is a fruit.", "Banana is tasty.", "Cherry pie is delicious.", "Date is a sweet fruit."]
# Use the pattern \b\w{5}\b to match 5-letter words
pattern = r"\b\w{5}\b"
word_list = [] # Initialize an empty list to store the extracted words
for text in text_list:
words = re.findall(pattern, text)
word_list.extend(words) # Extend the list with the extracted words
print(word_list)
In this example:
We define the regular expression pattern r"\b\w{5}\b" to match 5-letter words.
\b matches a word boundary to ensure that we match whole words.
\w matches any word character (letters, digits, or underscores).
{5} specifies that we want to match exactly five word characters.
Again, \b is used to ensure that we're matching whole words.
We iterate through each string in the text_list.
For each string, we apply the re.findall(pattern, text) function to extract the 5-letter words.
The extracted words are added to the word_list using the extend method to create a flat list of all the extracted words.
The output will be a list containing all the 5-letter words from the strings:
['Apple', 'fruit', 'Banana', 'tasty', 'Cherry', 'sweet', 'fruit']
This approach uses a simple for loop to extract 5-letter words from each string in the list and collects them into a single list.
Extracting 5 letters of word from string using findall
To extract 5-letter words from a single string using re.findall(), you can follow a similar approach as before but applied to a single string. Here's an example:
import re
text = "The quick brown fox jumps over the lazy dog. Apples are tasty."
# Use the pattern \b\w{5}\b to match 5-letter words
pattern = r"\b\w{5}\b"
word_list = re.findall(pattern, text)
print(word_list)
In this example:
We define the regular expression pattern r"\b\w{5}\b" to match 5-letter words.
\b matches a word boundary to ensure that we match whole words.
\w matches any word character (letters, digits, or underscores).
{5} specifies that we want to match exactly five word characters.
Again, \b is used to ensure that we're matching whole words.
We apply the re.findall(pattern, text) function to the input text to extract the 5-letter words.
The output will be a list containing all the 5-letter words found in the input string:
['quick', 'brown', 'fox', 'jumps', 'over', 'lazy', 'Apples', 'tasty']
This approach extracts 5-letter words from a single string using re.findall().
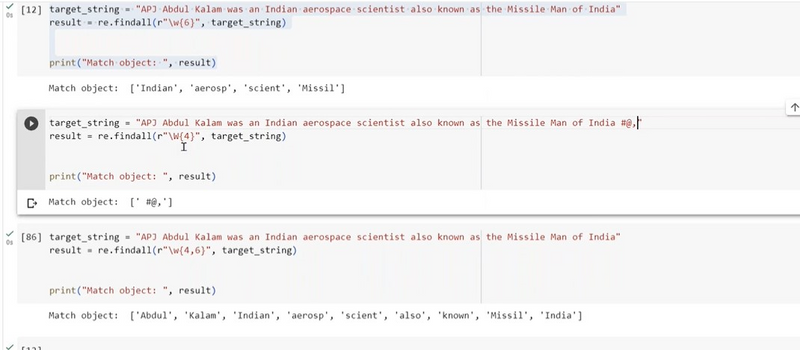
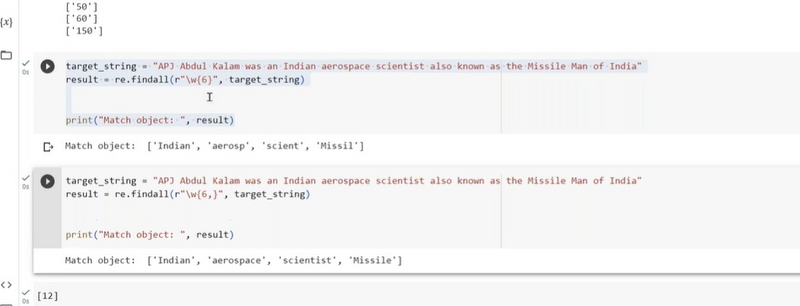
Extracting some range of word from string using findall
To extract words within a specific range of lengths from a string using re.findall(), you can define a regular expression pattern that matches words of the desired lengths. Here's an example where we extract words with lengths between 4 and 6 characters from a string:
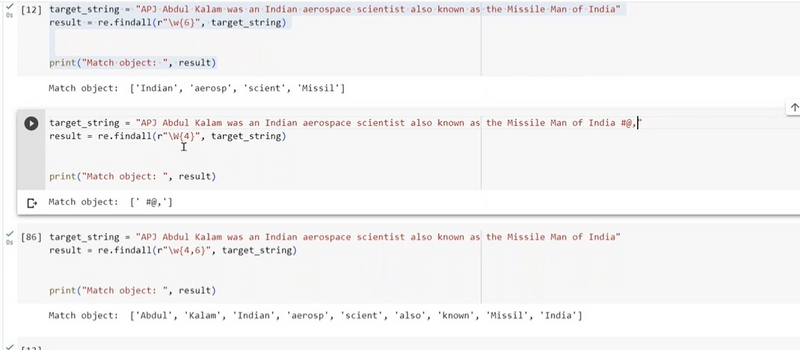
import re
text = "The quick brown fox jumps over the lazy dog. Apples are tasty."
# Use the pattern \b\w{4,6}\b to match words with lengths between 4 and 6 characters
pattern = r"\b\w{4,6}\b"
word_list = re.findall(pattern, text)
print(word_list)
In this example:
The regular expression pattern r"\b\w{4,6}\b" is used. Here's what it means:
\b matches a word boundary to ensure that we match whole words.
\w matches any word character (letters, digits, or underscores).
{4,6} specifies a range where we want to match words with lengths between 4 and 6 characters.
Again, \b is used to ensure that we're matching whole words.
The re.findall() function then finds and extracts all words that match this pattern in the input string. In this case, it extracts words like "quick," "brown," "fox," "the," "over," "lazy," "are," and "tasty" from the string.
You can adjust the pattern and the range to match words of different lengths based on your requirements.
Extracting string begins with A and ends with J from string using findall
To extract strings from a larger string that begin with 'A' and end with 'J' using re.findall(), you can use the following regular expression pattern:
import re
text = "The alphabet contains words like Apple, Banana, and Applejack. Enjoy your day."
# Use the pattern 'A\w*J' to match strings that start with 'A' and end with 'J'
pattern = r'A\w*J'
matches = re.findall(pattern, text)
print(matches)
In this example:
The regular expression pattern r'A\w*J' is used. Here's what it means:
A matches the character 'A' literally.
\w* matches zero or more word characters (letters, digits, or underscores).
J matches the character 'J' literally.
The re.findall() function finds and extracts all substrings in the input text that match this pattern. In this case, it extracts "Apple" and "Applejack" from the string because they both start with 'A' and end with 'J'.
The output will be:
['Apple', 'Applejack']
This code extracts strings that meet the specified criteria: starting with 'A' and ending with 'J'. You can adjust the pattern based on your specific requirements.
Extracting string begins with A and ends with J or begins with a and ends with i from string using findall
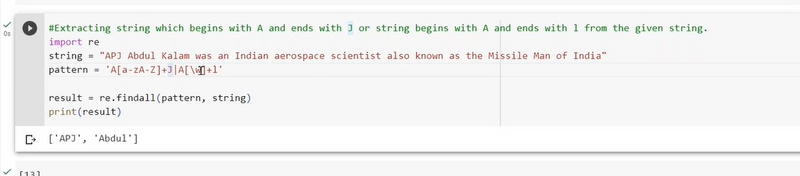
To extract strings from a larger string that either begin with 'A' and end with 'J' or begin with 'a' and end with 'i' using re.findall(), you can use a regular expression pattern with the "OR" (|) operator. Here's how you can do it:
import re
text = "The alphabet contains words like Apple, Applejack, and antialiasing."
# Use the pattern 'A\w*J|a\w*i' to match strings with either condition
pattern = r'A\w*J|a\w*i'
matches = re.findall(pattern, text)
print(matches)
In this example:
The regular expression pattern r'A\w*J|a\w*i' is used. Here's what it means:
A\w*J matches strings that start with 'A' and end with 'J'.
a\w*i matches strings that start with 'a' (lowercase 'A') and end with 'i' (lowercase 'i').
The | operator between the two patterns acts as an OR condition, matching either pattern.
The re.findall() function finds and extracts all substrings in the input text that match either condition. In this case, it extracts "Apple," "Applejack," and "antialiasing" from the string because they match either of the specified conditions.
The output will be:
['Apple', 'Applejack', 'antialiasing']
This code extracts strings that meet either of the specified conditions: starting with 'A' and ending with 'J' or starting with 'a' and ending with 'i'. You can adjust the pattern based on your specific requirements.
Date Extraction example of regx using findall
Certainly, here's an example of date extraction using regular expressions and re.findall():
import re
text = "The meeting dates are 2023-09-15 and 09/20/2023. Don't forget the event on 12-31-2022."
# Use a regular expression pattern to match dates in various formats
pattern = r"\d{4}-\d{2}-\d{2}|\d{2}/\d{2}/\d{4}|\d{2}-\d{2}-\d{4}"
dates = re.findall(pattern, text)
print(dates)
In this example:
The regular expression pattern r"\d{4}-\d{2}-\d{2}|\d{2}/\d{2}/\d{4}|\d{2}-\d{2}-\d{4}" is used. Here's what it means:
\d{4}-\d{2}-\d{2} matches dates in the format "YYYY-MM-DD."
\d{2}/\d{2}/\d{4} matches dates in the format "MM/DD/YYYY."
\d{2}-\d{2}-\d{4} matches dates in the format "MM-DD-YYYY."
The | operator between the three patterns acts as an OR condition, matching any of the date formats.
The re.findall() function finds and extracts all substrings in the input text that match any of the specified date formats. In this case, it extracts "2023-09-15," "09/20/2023," and "12-31-2022" from the string.
The output will be:
['2023-09-15', '09/20/2023', '12-31-2022']
This code extracts dates in various formats from the input text using regular expressions and re.findall(). You can adjust the pattern to match specific date formats according to your needs.
Numeric Value Extraction example of regx using findall
Certainly, here's an example of extracting numeric values, such as currency amounts, percentages, and measurements, using regular expressions and re.findall():
import re
text = "The total cost is $500.50, which is 20% of the total. The temperature is 25.5°C."
# Use a regular expression pattern to match numeric values
pattern = r"\d+(\.\d+)?%?°?C?|\$[\d,.]+"
numeric_values = re.findall(pattern, text)
print(numeric_values)
In this example:
The regular expression pattern r"\d+(.\d+)?%?°?C?|\$[\d,.]+" is used. Here's what it means:
\d+ matches one or more digits.
(.\d+)? optionally matches a decimal part (e.g., .50) preceded by a dot.
%? optionally matches a percentage sign.
°? optionally matches a degree symbol (e.g., °C).
C? optionally matches the letter 'C' (e.g., for Celsius).
\$[\d,.]+ matches currency amounts with the dollar sign (e.g., $500.50) where digits, commas, and periods are allowed.
The re.findall() function finds and extracts all substrings in the input text that match any of the specified numeric value formats. In this case, it extracts "$500.50," "20%," and "25.5°C" from the string.
The output will be:
['$500.50', '20%', '25.5°C']
This code demonstrates how to extract various numeric values, including currency amounts, percentages, and measurements, from the input text using regular expressions and re.findall(). You can customize the pattern to match specific numeric formats based on your requirements.
Acronym Extraction example of regx using findall
To extract acronyms from a text using regular expressions and re.findall(), you can define a pattern that matches words in all uppercase letters. Here's an example:
import re
text = "NASA (National Aeronautics and Space Administration) is a famous organization. FBI (Federal Bureau of Investigation) is another one."
# Use a regular expression pattern to match acronyms in uppercase letters
pattern = r'\b[A-Z]{2,}\b'
acronyms = re.findall(pattern, text)
print(acronyms)
In this example:
The regular expression pattern r'\b[A-Z]{2,}\b' is used. Here's what it means:
\b matches a word boundary to ensure that we match whole words.
[A-Z] matches any uppercase letter from 'A' to 'Z'.
{2,} specifies that we want to match two or more consecutive uppercase letters.
Again, \b is used to ensure that we're matching whole words.
The re.findall() function finds and extracts all sequences of consecutive uppercase letters that match this pattern in the input text. In this case, it extracts "NASA" and "FBI" as acronyms from the text.
The output will be:
['NASA', 'FBI']
This code demonstrates how to extract acronyms (sequences of uppercase letters) from the input text using regular expressions and re.findall(). You can adjust the pattern to suit your specific requirements for acronym detection.
=======================================================
IMPORTANT QUESTION/ASSIGNMENT
Create a function in python to find all words that are at least 4 characters long in a string. The use of the re.compile() method is mandatory with example
import re
# Function to find all words at least 4 characters long in a string
def find_words_at_least_4_characters(input_string):
# Define a regex pattern to match words of at least 4 characters
pattern = re.compile(r'\b\w{4,}\b')
# Use re.findall() to find all matches in the input string
result = pattern.findall(input_string)
return result
# Input string
input_string = "This is a sample sentence with words of varying lengths, including apple, book, and computer."
# Find words at least 4 characters long using regex
found_words = find_words_at_least_4_characters(input_string)
# Print the found words
print("Words at least 4 characters long:")
print(found_words)
Create a function in python to find all three, four, and five character words in a string. The use of the re.compile() method is mandatory.
import re
# Function to find all three, four, and five-character words in a string
def find_words_of_lengths_3_to_5(input_string):
# Define a regex pattern to match words of lengths 3 to 5 characters
pattern = re.compile(r'\b\w{3,5}\b')
# Use re.findall() to find all matches in the input string
result = pattern.findall(input_string)
return result
# Input string
input_string = "This is a sample sentence with words of varying lengths, including apple, book, and computer."
# Find words of lengths 3 to 5 characters using regex
found_words = find_words_of_lengths_3_to_5(input_string)
# Print the found words
print("Words of lengths 3 to 5 characters:")
print(found_words)
Question 7- Write a regular expression in Python to split a string into uppercase letters.
Sample text: “ImportanceOfRegularExpressionsInPython”
Expected Output: [‘Importance’, ‘Of’, ‘Regular’, ‘Expression’, ‘In’, ‘Python’]
import re
# Sample text
sample_text = "ImportanceOfRegularExpressionsInPython"
# Define a regex pattern to split on uppercase letters
pattern = r'[A-Z][a-z]*'
# Use re.findall() to split the text based on the pattern
words = re.findall(pattern, sample_text)
# Print the resulting words
print(words)
In this code:
We import the re module for regular expressions.
The sample text is defined as "ImportanceOfRegularExpressionsInPython."
We define a regex pattern, r'[A-Z][a-z]*', to split the text based on uppercase letters:
[A-Z] matches an uppercase letter.
[a-z]* matches zero or more lowercase letters that follow the uppercase letter.
['Importance', 'Of', 'Regular', 'Expressions', 'In', 'Python']
Write a python program to extract email address from the text stored in the text file using Regular Expression.
Sample Text- Hello my name is Data Science and my email address is xyz@domain.com and alternate email address is xyz.abc@sdomain.domain.com.
import re
# Function to extract email addresses from text using regex
def extract_email_addresses_from_text(text):
# Define a regex pattern to match email addresses
pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,7}\b'
# Use re.findall() to find all matches in the text
email_addresses = re.findall(pattern, text)
return email_addresses
# Read the content of the input text file
input_file_name = 'input.txt'
try:
with open(input_file_name, 'r') as input_file:
input_text = input_file.read()
except FileNotFoundError:
print(f"Error: The input file '{input_file_name}' does not exist.")
exit(1)
# Extract email addresses from the text
found_email_addresses = extract_email_addresses_from_text(input_text)
# Print the extracted email addresses
print("Email Addresses Found:")
for email in found_email_addresses:
print(email)
Here's how the program works:
We import the re module for regular expressions.
The extract_email_addresses_from_text function takes an input text and performs the following steps:
Defines a regex pattern to match email addresses. The pattern \b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+.[A-Z|a-z]{2,7}\b is a common pattern for matching email addresses.
Uses re.findall() to find all matches of the pattern in the input text.
The program reads the content of the input text file specified by input_file_name.
It extracts email addresses from the input text using the extract_email_addresses_from_text function.
Finally, it prints the extracted email addresses to the console.
Make sure to replace 'input.txt' with the name of your input text file containing the text with email addresses. When you run the program, it will extract and display the email addresses found in the text file.
Write a regular expression in python to match a date string in the form of Month name followed by day number and year stored in a text file
import re
# Function to extract date strings from a text file
def extract_dates_from_file(file_path):
date_pattern = r'([A-Z][a-z]+ \d{1,2}, \d{4})'
with open(file_path, 'r') as file:
file_content = file.read()
dates = re.findall(date_pattern, file_content)
return dates
# Specify the path to the text file containing date strings
file_path = 'date_strings.txt'
# Extract date strings from the text file
matched_dates = extract_dates_from_file(file_path)
# Print the matched date strings
print("Matched Date Strings:")
for date in matched_dates:
print(date)
output
Matched Date Strings:
September 18, 2023
October 1, 2023
Write a Python program to find the substrings within a string.
Sample text : 'Python exercises, PHP exercises, C# exercises'
Pattern : 'exercises'. using regx func
import re
# Sample text
sample_text = 'Python exercises, PHP exercises, C# exercises'
# Substring to search for using regular expression
substring = 'exercises'
positions = []
# Find all occurrences of the substring using re.finditer()
matches = re.finditer(substring, sample_text)
for match in matches:
start_position = match.start()
end_position = match.end()
positions.append((start_position, end_position))
print(match)
print(positions)
output

================or======================
import re
# Sample text
sample_text = 'Python exercises, PHP exercises, C# exercises'
# Substring to search for using regular expression
substring = 'exercises'
# Find all occurrences of the substring using re.finditer()
matches = [match.start() for match in re.finditer(substring, sample_text)]
# Print the starting positions of the substrings
print("Starting Positions of Substrings:")
for position in matches:
print(position)
# Find the occurrence positions of the substring in the test string
occurrence_positions = find_substring_occurrences(test_string, substring)
# Print the occurrence positions
print("Occurrences of the substring 'is':")
for start, end in occurrence_positions:
print(f"Start Position: {start}, End Position: {end}")
===================or==================
import re
# Sample text
sample_text = 'Python exercises, PHP exercises, C# exercises'
# Substring to search for using regular expression
substring = 'exercises'
# Find all occurrences of the substring using re.finditer()
matches = [(match.start(), match.group()) for match in re.finditer(substring, sample_text)]
# Print the positions and occurrences of the substrings
print("Occurrences and Positions of Substrings:")
for position, substring in matches:
print(f"Substring '{substring}' found at position {position}")
Create a function in python to find all decimal numbers with a precision of 1 or 2 in a string. The use of the re.compile() method is mandatory
import re
# Test string
test_string = "The price is $12.34, the temperature is 25.5°C, and there are 7 days in a week."
# Define a regex pattern to match numbers
pattern = r'\d+'
# Use re.finditer() to find all matches of the pattern in the input string
matches = re.finditer(pattern, test_string)
# Print the matched numbers along with their positions
print("Numbers and Their Positions:")
num = []
for match in matches:
number = match.group()
num.append(number)
position = match.start() + 1 # Adjust position to be 1-based
print(f"Number: {number}, Position: {position}")
print(num)
OUTPUT
Numbers and Their Positions:
Number: 12, Position: 15
Number: 34, Position: 18
Number: 25, Position: 41
Number: 5, Position: 44
Number: 7, Position: 63
['12', '34', '25', '5', '7']
Write a Python program to separate and print the numbers and their position of a given string. using regx fun
import re
# Function to separate and print numbers with their positions in a string
def separate_and_print_numbers(input_string):
# Define a regex pattern to match numbers
pattern = r'\d+'
# Use re.finditer() to find all matches of the pattern in the input string
matches = re.finditer(pattern, input_string)
# Print the matched numbers along with their positions
print("Numbers and Their Positions:")
for match in matches:
number = match.group()
position = match.start() + 1 # Adjust position to be 1-based
print(f"Number: {number}, Position: {position}")
# Test string
test_string = "The price is $12.34, the temperature is 25.5°C, and there are 7 days in a week."
# Call the function to separate and print numbers with their positions
separate_and_print_numbers(test_string)
Output
Numbers and Their Positions:
Number: 12, Position: 14
Number: 34, Position: 17
Number: 25, Position: 39
Number: 5, Position: 42
Number: 7, Position: 64
Write a regular expression in python program to extract maximum/largest numeric value from a string
import re
# Function to extract the maximum numeric value from a string
def extract_maximum_numeric_value(text):
# Define a regex pattern to match numeric values
pattern = re.compile(r'\d+(\.\d+)?')
# Use re.findall() to find all numeric values in the text
numeric_values = re.findall(pattern, text)
# Convert the numeric values to floats and find the maximum
numeric_values = [float(value) for value in numeric_values]
if numeric_values:
maximum_value = max(numeric_values)
return maximum_value
else:
return None
# Test string
test_string = "The prices are $12.34, $15.67, and $10.99. The largest is $15.67."
# Extract and print the maximum numeric value
maximum_numeric_value = extract_maximum_numeric_value(test_string)
if maximum_numeric_value is not None:
print(f"The maximum numeric value in the string is: {maximum_numeric_value}")
else:
print("No numeric values found in the string.")
output
The maximum numeric value in the string is: 15.67
Python regex to find sequences of one upper case letter followed by lower case letters
import re
# Input string
input_string = "This is a TestString with MultipleUppercaseWords and AnotherExampleString."
# Define a regex pattern to find sequences of one uppercase letter followed by lowercase letters
pattern = r'[A-Z][a-z]+'
# Use re.findall() to find all matches of the pattern in the input string
matches = re.findall(pattern, input_string)
# Print the matched sequences
print("Matched Sequences:")
for match in matches:
print(match)
Write a python program using RegEx to extract the hashtags.
Sample Text: """RT @kapil_kausik: #Doltiwal I mean #xyzabc is "hurt" by #Demonetization as the same has rendered USELESS "acquired funds" No wo"""
Expected Output: ['#Doltiwal', '#xyzabc', '#Demonetization'] using regex fun
import re
# Sample Text
sample_text = """RT @kapil_kausik: #Doltiwal I mean #xyzabc is "hurt" by #Demonetization as the same has rendered USELESS <ed><U+00A0><U+00BD><ed><U+00B1><U+0089> "acquired funds" No wo"""
# Define a regex pattern to match hashtags
pattern = r'#\w+'
# Use re.findall() to find all matches of the pattern in the text
hashtags = re.findall(pattern, sample_text)
# Print the extracted hashtags
print("Extracted Hashtags:")
print(hashtags)
Write a python program to extract dates from the text stored in the text file.
Sample Text: Ron was born on 12-09-1992 and he was admitted to school 15-12-1999 using regx function
import re
# Function to extract dates from text using regex
def extract_dates_from_text(text):
# Define a regex pattern for dates in dd-mm-yyyy format
pattern = r'\b\d{2}-\d{2}-\d{4}\b'
# Use re.findall() to find all matches of the pattern in the text
dates = re.findall(pattern, text)
return dates
# Read text from a text file
with open("sample_text.txt", "r") as file:
text = file.read()
# Extract dates from the text
extracted_dates = extract_dates_from_text(text)
# Print the extracted dates
print("Extracted Dates:")
for date in extracted_dates:
print(date)
word frequency analysis
Splitting a text document into individual words for text classification and put in list then convert into table
import re
import pandas as pd
text = "This is a sample text. This text contains repeated words, and the words should be counted."
# Use re.findall() to extract words
words = re.findall(r'\b\w+\b', text.lower())
word_list = [{'word': word, 'count': words.count(word)} for word in set(words)]
df = pd.DataFrame(word_list)
# Print the result
print(word_list)
print(df)
[{'word': 'the', 'count': 1}, {'word': 'should', 'count': 1}, {'word': 'sample', 'count': 1}, {'word': 'is', 'count': 1}, {'word': 'and', 'count': 1}, {'word': 'counted', 'count': 1}, {'word': 'repeated', 'count': 1}, {'word': 'text', 'count': 2}, {'word': 'words', 'count': 2}, {'word': 'be', 'count': 1}, {'word': 'contains', 'count': 1}, {'word': 'a', 'count': 1}, {'word': 'this', 'count': 2}]


# Example list of words
words = ['apple', 'orange', 'banana', 'apple', 'grape', 'apple']
# Count the occurrences of the word 'apple'
apple_count = words.count('apple')
# Print the result
print(f"The word 'apple' appears {apple_count} times in the list.")
Common mistake or best practice
r"[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,7}"===>correct
r"[A-Za-z0-9._%+-]/@[A-Za-z0-9.-]/\.[A-Za-z]{2,7}" ==wrong
r"https?+://+\S+"===wrong
r"https?://\S+"===correct
add + symbol b/w regx only specified [] like r"[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+.[A-Za-z]{2,7}"
wrong
pattern = r"\w{5}"
correct
bounded with \b \b
pattern = r"\b\w{5}\b"
pattern = r"\b\w{4,6}\b"
wrong
pattern =Aw*j
correct
`pattern = r'A\w*J'`
wrong
pattern = "d+"
correct
pattern = "\d+"
pattern = "\d{1,3}"
Question
match start with uppercase letter followed by one or more lowercase letter
matches any non-digit character.
split string by comma
split string by digit
split string by dot before dot string after dot also string
split string by |
Match: .14 and Match: .99
find all words at least 4 characters long in a string
not a word character (\w) or a whitespace character
find at least two capital letter
range of alphabetic 2 to 7
r'^[A-Z][a-z]+'
r'[^0-9]'
r',\s+'
r',\d'
r'\s*.\s*'
r'\s*|\s*'
r'\w{4,}
r'[^\w\s]
r'[A-Z]{2,}
r'[A-Z|a-z]{2,7}
email extraction
normally gmail pattern
before @ any alphabetic ,numeric includes .%+-
before @ any alphabetic ,numeric includes .
after dot . must be range between two to seven and alphabetic
URL Extraction
starts with http or https followed by : and // then any one or more string
Output: ['https://www.example.com']
Hashtag Extraction
starts with # followed by any words
Output: ['#MachineLearning', '#DataScience']
Mention Extraction:
pattern:2023-09-15 == 4 digit then - then two digit then - then two digit or 09/20/2023 use pipeline
Output: ['2023-09-15', '09/20/2023']
Phone Number Extraction
pattern
Output: ['+1 (123) 456-7890', '555-5555']
starts with either + or without + then
matches one to 3 digits then bounded by () .ex(123)
then must be 3 digits then - eg. 456-
then must be 4 digits then 7890 or 5555
Answer
r"[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,7}"
r"https?://\S+"
pattern = r"#\w+"
pattern = r"\d{4}-\d{2}-\d{2}|\d{2}/\d{2}/\d{4}"
pattern = r"\+?\d{1,3} \(\d{3}\) \d{3}-\d{4}|\d{3}-\d{4}"
Matching specific word using findall
like eg. data science
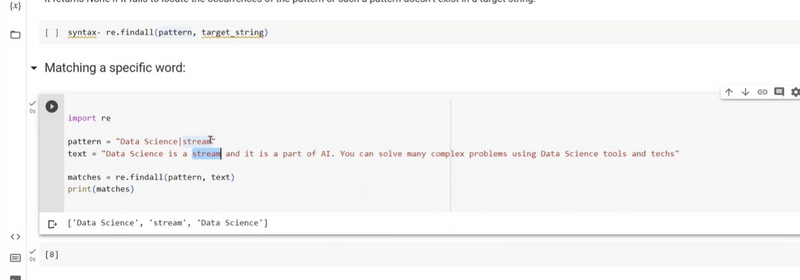
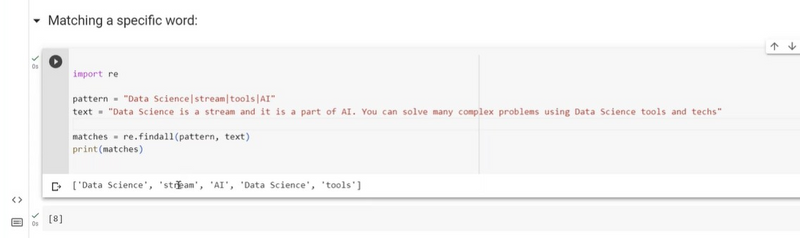
Matching multiple specific word using findall
eg,data science,stream
Matching single specific word and ignore special char and case
sensitive using findall
Extracting digits within text using findall
Extracting non digits within text using findall
Extracting specific digits within text using findall
Extracting specific range digits 0 to 10 within text using findall
Extracting specific range digits 20 to 49 within text using findall
Extracting digits from list of string using findall
Extracting 5 letters of word from list of string with specified boundry using findall
Extracting 5 letters of word from string using findall
Extracting some range of word from string using findall
Extracting string begins with A and ends with J from string using findall
Date Extraction example of regx using findall"The meeting dates are 2023-09-15 and 09/20/2023. Don't forget the event on 12-31-2022."
like text =
split a string into uppercase letters.Month name followed by day number and year
September 18, 2023,October 1, 2023
['Importance', 'Of', 'Regular', 'Expressions', 'In', 'Python']
meaning of uppercase letters is first letter must be capital other small
word frequency analysis
Solution
`
pattern = "Data science"
pattern = "Data science|stream|tools|AI"
re.findall(pattern, text, re.IGNORECASE)
pattern = "\d+"
pattern = "\d{1,3}" or [0-9]
pattern = [^0-9]
pattern = d{3}
pattern = [0-9]
pattern = \b[2-4][0-9]\b
pattern = r"\d+"
pattern = r"\w{5}"
pattern = r"\b\w{5}\b"
pattern = r'A\w*J'
pattern = r"\d{4}-\d{2}-\d{2}|\d{2}/\d{2}/\d{4}|\d{2}-\d{2}-\d{4}" is used. Here's what it means:
pattern = re.compile(r'\b\w{3,5}\b')
pattern = r'[A-Z][a-z]'
date_pattern = r'([A-Z][a-z]+ \d{1,2}, \d{4})'
pattern = re.compile(r'\b\w{3,5}\b')
pattern = r'[A-Z][a-z]'
matches = [(match.start(), match.group()) for match in re.finditer(substring, sample_text)]
==================or===========
matches = [match.start() for match in re.finditer(substring, sample_text)]
word_list = [{'word': word, 'count': words.count(word)} for word in words]
`

Top comments (0)