In machine learning, the use of regular expression (regex) splitting functions is less common compared to traditional data splitting techniques like train-test splits and cross-validation. However, regex splitting can still be useful in specific scenarios where data needs to be preprocessed or cleaned. Here are eight real-time applications of using regex split functions in machine learning, along with examples and potential outputs:
Text Data Preprocessing
Cleaning Data(Extracting Features from Text)
Tokenization
Parsing Log Files
Data Cleaning for Time Series
Extracting Numerical Data
Structured Data Extraction
Text Data Preprocessing:
Example: Splitting a text document into individual words for text classification or sentiment analysis.
Output: A list of words from the text document.
import re
# Sample text document
text = "Natural language processing (NLP) is a subfield of artificial intelligence."
# Split the text into words using regex
words = re.findall(r'\b\w+\b', text)
# Print the list of words
print("Words:", words)
Output:
Words: ['Natural', 'language', 'processing', 'NLP', 'is', 'a', 'subfield', 'of', 'artificial', 'intelligence']
Extracting Features from Text:
Example: Using regex to split text into sentences or paragraphs for feature extraction in NLP tasks.
Output: Lists of sentences or paragraphs as features.
Cleaning Data:
import re
# Sample data with concatenated values
data = "Name: John, Age: 30, Gender: Male"
# Split the data into separate columns using regex
columns = re.split(r',\s*', data)
# Print the separate columns
print("Columns:", columns)
Columns: ['Name: John', 'Age: 30', 'Gender: Male']
Example: Splitting a messy dataset containing concatenated values (e.g., "Name: John, Age: 30") into structured columns.
Output: Separate columns for name and age.
Tokenization:
import nltk
from nltk.tokenize import word_tokenize
# Sample text
text = "Tokenization is a common preprocessing step in NLP."
# Tokenize the text using NLTK
tokens = word_tokenize(text)
# Print the result
print("Tokens:", tokens)
output
Tokens: ['Tokenization', 'is', 'a', 'common', 'preprocessing', 'step', 'in', 'NLP', '.']
Example: Tokenizing text data by splitting sentences into individual words or splitting code into separate tokens for natural language processing or code analysis.
Output: Lists of tokens or words.
Parsing Log Files:
import re
# Sample log file
log_file = "INFO: User logged in | ERROR: Database connection failed | WARNING: High CPU usage"
# Split the log entries using regex
log_entries = re.split(r'\s*\|\s*', log_file)
# Print the individual log entries
print("Log Entries:", log_entries)
Log Entries: ['INFO: User logged in', 'ERROR: Database connection failed', 'WARNING: High CPU usage']
Example: Using regex to split log files into individual log entries for anomaly detection or log analysis.
Output: List of log entries.
Data Cleaning for Time Series:
Example: Splitting time series data with irregular or combined timestamps into separate columns (e.g., date and time).
Output: Cleaned time series data with separate timestamp columns.
Extracting Numerical Data:
import re
# Sample data with mixed alphanumeric strings
data = "Price: $150, Discount: 20%, Rating: 4.5"
# Extract numerical values using regex
numerical_values = re.findall(r'\d+(\.\d+)?', data)
# Print the extracted numerical values
print("Numerical Values:", numerical_values)
Numerical Values: ['150', '20', '4.5']
Example: Splitting strings to extract numerical values, such as extracting product prices from product descriptions.
Output: Lists of extracted numerical values.
Structured Data Extraction:
import spacy
# Load the spaCy English model
nlp = spacy.load("en_core_web_sm")
# Sample text with multiple sentences
text = "Natural language processing (NLP) is a subfield of artificial intelligence. It deals with the interaction between humans and computers using natural language. NLP techniques are used in various applications."
# Tokenize the text into sentences using spaCy
doc = nlp(text)
# Extract sentences as features
sentences = [sent.text for sent in doc.sents]
# Print the result
for i, sentence in enumerate(sentences):
print(f"Sentence {i + 1}: {sentence}")
output
entence 1: Natural language processing (NLP) is a subfield of artificial intelligence.
Sentence 2: It deals with the interaction between humans and computers using natural language.
Sentence 3: NLP techniques are used in various applications.
Another way
import re
# Sample log file
text = "Natural language processing (NLP) is a subfield of artificial intelligence. It deals with the interaction between humans and computers using natural language. NLP techniques are used in various applications."
# Split the log entries using regex
log_entries = re.split(r'\s*\.\s*', text)
for data in log_entries:
print(data)
print(log_entries)

Example: Extracting structured data from unstructured sources using regex patterns (e.g., extracting phone numbers or email addresses from text).
Output: Lists of extracted structured data (e.g., phone numbers or email addresses).
Here's an example of splitting text data into words using regex in Python:
In this example, the regex pattern \b\w+\b is used to split the text into words, and the output is a list of words. Depending on the specific use case, you may modify the regex pattern to suit your needs and extract different elements from the data.
example split at each digit
import re
# Sample string containing digits
text = "Hello123World456"
# Split the string at each digit using regex
split_result = re.split(r'\d', text)
# Print the result
print("Split Result:", split_result)
Output:
Split Result: ['Hello', '', '', 'World', '', '', '']
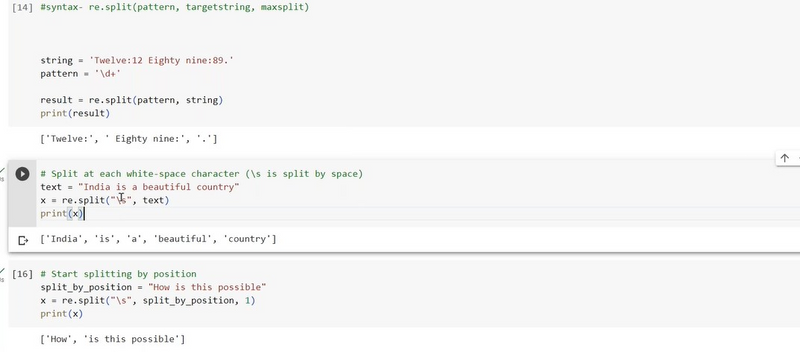
give example split at each white space character
import re
# Sample string containing white space characters
text = "Split this string at spaces and tabs."
# Split the string at each white space character using regex
split_result = re.split(r'\s', text)
# Print the result
print("Split Result:", split_result)
Output:
Split Result: ['Split', 'this', 'string', 'at', 'spaces', 'and', 'tabs.']
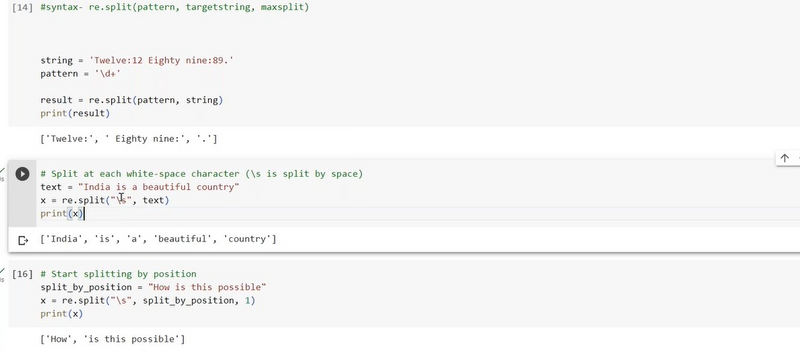
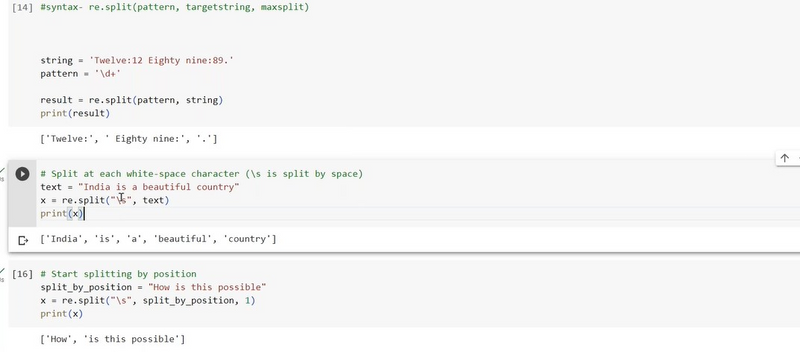
give example split by position
# Sample string
text = "This is an example string."
# Split the string by position
split_position = 8 # Split at the 8th character (index 7, as indexing starts from 0)
split_result = [text[:split_position], text[split_position:]]
# Print the result
print("Split Result:", split_result)
Output:
Split Result: ['This is ', 'an example string.']
text = "This is an example string."
# Split the string by position
split_position = 8 # Split at the 8th character (index 7, as indexing starts from 0)
split_result = [text[:split_position], text[split_position:]]
substring3 = text[7:12]
# Print the result
print(substring3)
print(text[split_position:])
print("Split Result:", split_result)

give example split at first occurance
# Sample string
text = "Split this string at the first occurrence of 'is'."
# Split the string at the first occurrence of 'is'
split_result = text.split('is', 1)
# Print the result
print("Split Result:", split_result)
Output:
Split Result: ['Split th', ' string at the first occurrence of 'is'.']

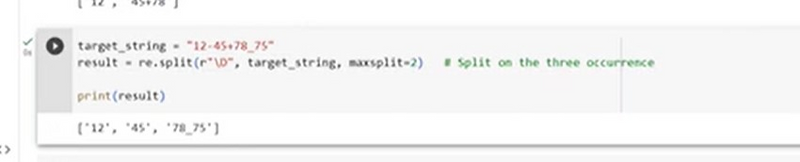
give example split at on three occurance
To split a string at the third occurrence of a specific substring, you can use a custom Python function with the str.split() method. Here's an example:
# Sample string
text = "Split this string at the third occurrence of 'is'. This is a test string with 'is'."
# Custom split function
def split_at_nth_occurrence(input_string, delimiter, n):
parts = input_string.split(delimiter)
if len(parts) <= n:
return parts
first_n_parts = parts[:n]
remaining_text = delimiter.join(parts[n:])
return first_n_parts + [remaining_text]
# Split the string at the third occurrence of 'is'
split_result = split_at_nth_occurrence(text, 'is', 3)
# Print the result
print("Split Result:", split_result)
Output:
Split Result: ['Split th', ' string at the third occurrence of ', "'is'. This is a test string with 'is'."]
give example split at delimeter
# Sample string
text = "Split this string at the delimiter, like this."
# Split the string at the delimiter ','
split_result = text.split(',')
# Print the result
print("Split Result:", split_result)
Output:

Split Result: ['Split this string at the delimiter', ' like this.']
=====================================================
IMPORTANT QUESTION/ASSIGNMENT
Write a Python program to convert a date of yyyy-mm-dd format to dd-mm-yyyy format
# Function to convert yyyy-mm-dd to dd-mm-yyyy format
def convert_date_format(input_date):
# Split the input date into year, month, and day components
year, month, day = input_date.split('-')
# Rearrange the components to the desired format
output_date = f"{day}-{month}-{year}"
return output_date
# Input date in yyyy-mm-dd format
input_date = "2023-09-18"
# Convert the date format
output_date = convert_date_format(input_date)
# Print the converted date
print("Original Date (yyyy-mm-dd):", input_date)
print("Converted Date (dd-mm-yyyy):", output_date)
Summary
Seperate string based on comma extracting feature
splitting sentences into individual words using tokenize
splitting log file into individual words based on comma
splitting numerical data
Extracting text into sentences
Split the string at each digit using regex
split at each white space character
split string by position using slicing
split at first occurance
convert a date of yyyy-mm-dd format to dd-mm-yyyy format
Answer
columns = re.split(r',\s*', data)
split_result = data.split(',')
tokens = word_tokenize(text)
log_entries = re.split(r'\s*\|\s*', log_file)
numerical_values = re.findall(r'\d+(\.\d+)?', data)
doc = nlp(text)
sentences = [sent.text for sent in doc.sents]
or log_entries = re.split(r'\s*\.\s*', text)
re.split(r'\d', text)
re.split(r'\s', text)
substring3 = text[7:12]
split_result = [text[:split_position], text[split_position:]]
text.split('is', 1)
year, month, day = input_date.split('-')
output_date = f"{day}-{month}-{year}"

Top comments (0)