layers
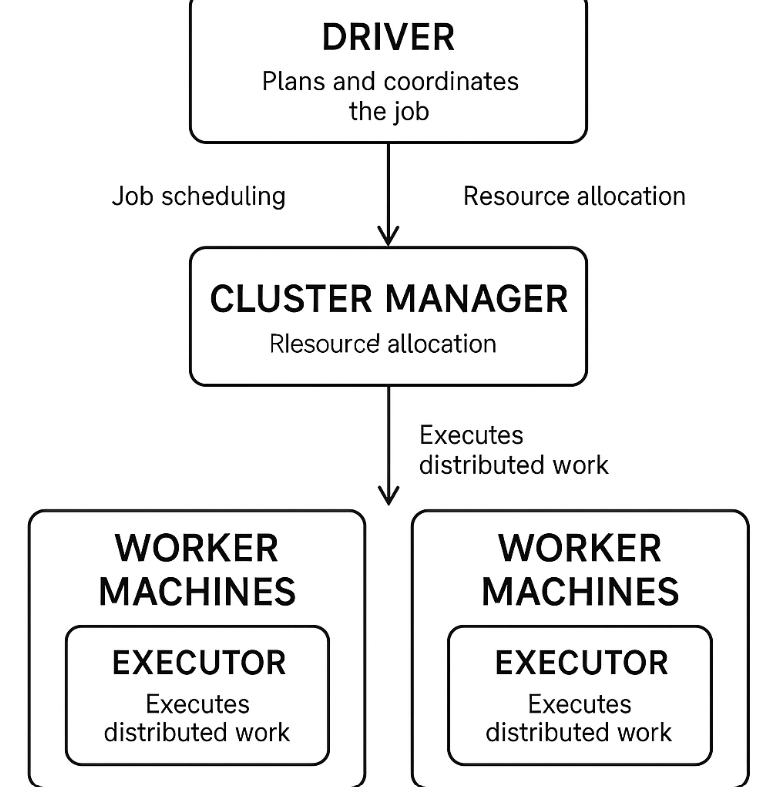
Driver Program
Cluster Manager
Executors
Spark Job Execution Flow (Tasks Breakdown)
In summary
Explain 3 layers with coding example
How Spark decides partitions (and thus tasks)
Example of spark architecture to make software product
Example of Spark Architecture as a Travel Platform
Example of Spark Architecture as a Ecommerce website
Apache Spark is a distributed computing framework. It takes a big job (like analyzing huge data) and splits it into small tasks, then runs them in parallel on many machines to finish faster.
layers
It has 3 main layers:
Driver Program
Cluster Manager
Executors (Workers)
[Driver Program]
│
▼
[Cluster Manager]
/ | \
/ | \
[Worker] [Worker] [Worker]
| | |
[Executor][Executor][Executor]
| | |
[Tasks: data chunks processed]
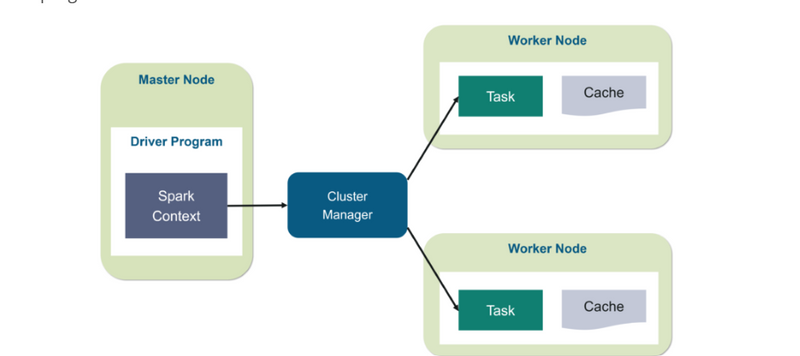
And it organizes work into Jobs → Stages → Tasks.
Driver Program
Driver Program
👉 Think of the Driver as the project manager.
Responsibilities / Tasks:
Runs your main application code (Python/Java/Scala).
Converts user code into a logical plan (what needs to be done).
Breaks the job into stages and tasks.
Sends tasks to executors.
Collects results back from executors.
Maintains metadata and monitoring using the SparkContext.
📌 Example: If you write df.groupBy("city").count(), the driver decides:
First read the data,
Then group by city,
Then count,
And finally collect results.
Cluster Manager
👉 Acts like the HR or resource manager.
Responsibilities / Tasks:
Allocates resources (CPU, memory, machines) to Spark applications.
Decides which machine will run executors.
Works with one of the resource managers:
Standalone Manager (Spark’s own)
YARN (Hadoop)
Kubernetes
📌 Example: If your job needs 10 executors, the cluster manager decides where to place those executors across available machines.
Executors
👉 Executors are the workers (developers) who do the actual job.
Responsibilities / Tasks:
Run the tasks assigned by the driver.
Store data in memory or disk (for caching).
Send results back to the driver.
Each Spark application gets its own set of executors.
📌 Example: One executor might be working on counting people in “Mumbai” data, another on “Delhi” data, another on “Bangalore” data — all in parallel.
Spark Job Execution Flow (Tasks Breakdown)
When you submit a Spark job, it goes like this:
Job
A complete Spark action (like collect(), save(), count()).
Example: “Find number of users in each city.”
Stages
Spark splits a job into stages based on shuffle boundaries (when data has to be moved between nodes).
Example:
Stage 1: Read and map data.
Stage 2: Shuffle and reduce (group by city).
Tasks
The smallest unit of work, executed by executors.
Each stage is split into tasks.
Example:
Task 1: Count users in Mumbai partition.
Task 2: Count users in Delhi partition.
Task 3: Count users in Bangalore partition.
🔹 Putting It All Together (Simple Analogy)
Imagine you want to prepare a company report:
Driver (Project Manager): Plans the project, breaks it into pieces (collect sales, group by branch, prepare final report).
Cluster Manager (HR): Assigns how many employees (resources) will work.
Executors (Employees): Actually collect sales data branch-wise, group and summarize.
Stages: Collect raw data → Group by branch → Prepare summaries.
Tasks: Each branch’s sales calculation is one task, done in parallel.
Result: Final company sales report.
✅
In summary
Driver: Plans and coordinates.
Cluster Manager: Assigns resources.
Executors: Do the work.
Job → Stage → Task: The hierarchy of work.
👉 Do you want me to also make a simple diagram with arrows (Driver → Cluster Manager → Executors → Results) so you can visualize the flow better?


Explain 3 layers with coding example
from pyspark.sql import SparkSession
# ---------------- DRIVER ----------------
spark = SparkSession.builder \
.appName("WordCountExample") \
.master("local[*]") \ # or yarn / k8s / standalone
.getOrCreate()
sc = spark.sparkContext
# Load data (Driver tells cluster manager resources are needed)
text_rdd = sc.textFile("data/input.txt")
# Transformations (lazy operations - Driver creates a plan)
words = text_rdd.flatMap(lambda line: line.split(" "))
pairs = words.map(lambda word: (word, 1))
word_counts = pairs.reduceByKey(lambda a, b: a + b)
# Action (triggers execution)
results = word_counts.collect()
# Print results
for word, count in results:
print(f"{word}: {count}")
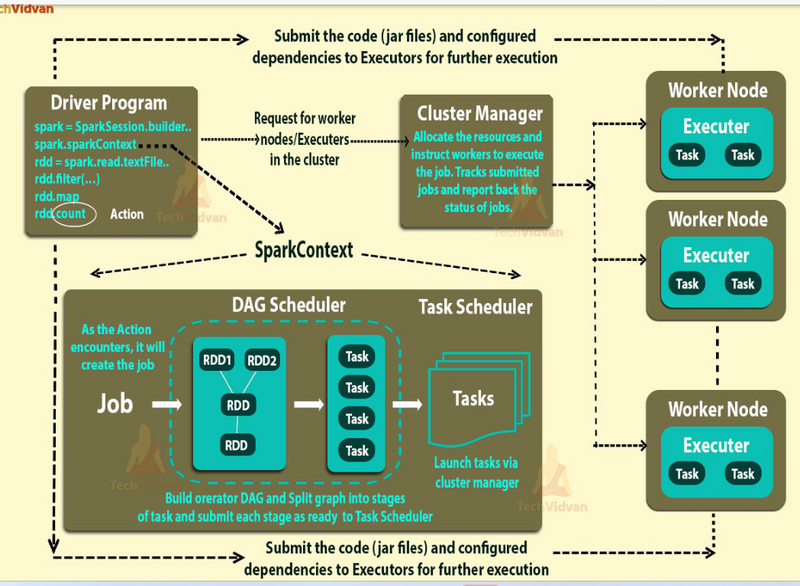
🔹 How This Runs Across the 3 Layers
Driver Layer
The Driver is running this Python script.
When you call flatMap, map, and reduceByKey, the driver doesn’t run them immediately.
Instead, it builds a DAG (Directed Acyclic Graph) of operations (the execution plan).
When you call collect(), the Driver submits a Job to the Cluster Manager.
👉 Driver Tasks:
Parse the code.
Build execution plan (DAG).
Request resources from the Cluster Manager.
Split work into Stages and Tasks.
Cluster Manager Layer
The Driver asked for resources using .master("local[*]") (local) or Yarn/K8s in production.
The Cluster Manager decides:
How many Executors should be launched.
On which machine to run them.
How much CPU and memory each executor gets.
👉 Cluster Manager Tasks:
Allocate resources to Spark app.
Launch Executors on worker nodes.
Executor Layer
Executors actually run the tasks.
Example breakdown for word count:
Executor 1 → Counts words in Partition 1 (lines 1–1000).
Executor 2 → Counts words in Partition 2 (lines 1001–2000).
Executor 3 → Counts words in Partition 3 (lines 2001–3000).
After local counts, they shuffle data (so all “apple” counts go to one executor, all “banana” counts to another).
Executors return results to the Driver.
👉 Executor Tasks:
Execute assigned tasks (map, reduce, etc.).
Store intermediate data in memory/disk.
Send results back to Driver.
🔹 Job → Stage → Task in this Example
Job: word_counts.collect()
Stages:
Read + flatMap + map (narrow transformations)
Shuffle + reduceByKey (wide transformation)
Tasks: Each partition’s work is one Task sent to an Executor.
✅
Summary with Code Context
Driver: Runs your script, builds DAG, submits job.
Cluster Manager: Allocates resources, launches executors.
Executors: Run tasks on partitions (actual data crunching).
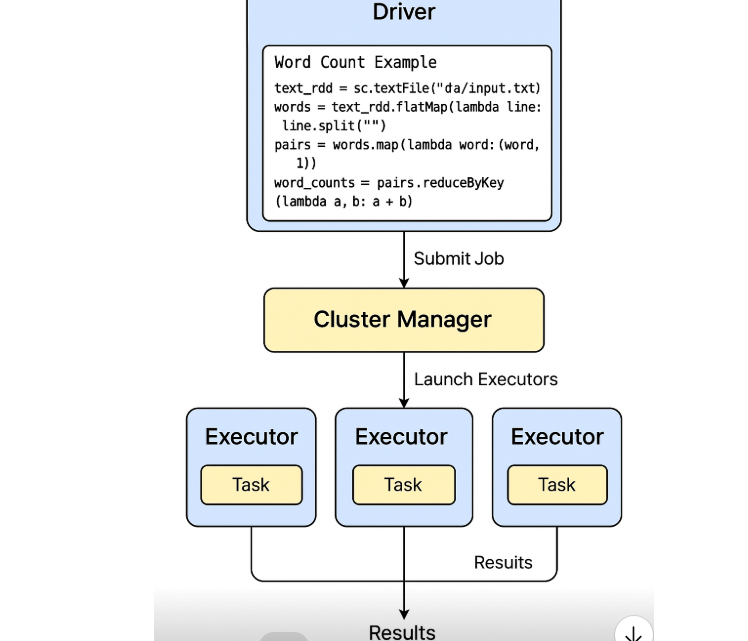
How Spark decides partitions (and thus tasks)

RDD API (textFile, repartition, reduceByKey)
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
sc = spark.sparkContext
# 1) Control the number of input partitions (minPartitions is a hint)
rdd = sc.textFile("s3://bucket/logs.txt", minPartitions=12)
# 2) Inspect how many partitions you got
print("Input partitions:", rdd.getNumPartitions())
# 3) Force a new partitioning (shuffle) to exactly N partitions
rdd2 = rdd.repartition(24) # wider shuffle, more parallelism
# Or coalesce to reduce without full shuffle:
rdd_small = rdd.coalesce(6)
# 4) Control shuffle partitions for a key-based op
pairs = rdd2.flatMap(lambda line: line.split()).map(lambda w: (w, 1))
# reduceByKey with explicit number of partitions (affects the shuffle stage)
counts = pairs.reduceByKey(lambda a, b: a + b, numPartitions=36)
Effect: The number of partitions determines how many tasks are created in each stage.
See which partition a record runs in (for learning/debug):
def tag_with_partition(idx, it):
for x in it:
yield (idx, x)
tagged = rdd.mapPartitionsWithIndex(tag_with_partition)
Now you can look at partition indices attached to lines
(Note: partitions aren’t “lines 1–1000”, they are byte-range slices; line boundaries are handled by the input format.)
DataFrame / Dataset API
df = spark.read.text("s3://bucket/logs.txt")
# Before a shuffle: df partitions follow the input splits.
print("Input partitions:", df.rdd.getNumPartitions())
# Control partitioning for later shuffles (joins/groupBy)
spark.conf.set("spark.sql.shuffle.partitions", "300")
# Hash-partition by a column (causes a shuffle to 48 partitions):
by_word = df.selectExpr("explode(split(value, ' ')) as word") \
.repartition(48, "word") \
.groupBy("word").count()
Effect: repartition(48, "word") ensures the shuffle stage produces 48 tasks (one per partition).
spark.sql.shuffle.partitions sets the default for all shuffles unless you override with repartition.
Who gets which task? (Executor assignment)
Spark’s Task Scheduler assigns each partition = one task to any available executor based on:
Resource availability (cores, memory)
Data locality (try to run near the data)
You don’t pin “partition 0 must run on Executor 1.” Spark decides at runtime.
You can, however, influence how many executors / cores exist:
# Example spark-submit knobs (YARN/Standalone)
--num-executors 8 \
--executor-cores 4 \
--executor-memory 6g \
--conf spark.dynamicAllocation.enabled=true \
--conf spark.dynamicAllocation.minExecutors=2 \
--conf spark.dynamicAllocation.maxExecutors=40
If you really want “line 1–1000” style control
Spark doesn’t natively partition by line counts. If you must:
Read the file as a single block (wholeTextFiles) or stream bytes,
Manually chunk the content by line counts, then
Parallelize your custom chunks:
# WARNING: This is for controlled demos, not huge files
content = sc.textFile("file:///path/small.txt").collect()
chunks = [content[i:i+1000] for i in range(0, len(content), 1000)]
rdd = sc.parallelize(chunks, numSlices=len(chunks)) # one partition per chunk
This gives you “Partition 0 = lines 1–1000” semantics, but it doesn’t scale for big data and bypasses efficient input splitting.
TL;DR
You don’t assign executors to specific line ranges.
Spark partitions input (by bytes/splits), creates one task per partition, and schedules tasks on executors.
Control the number and shape of partitions with:
RDD: minPartitions, repartition, coalesce, reduceByKey(numPartitions=…)
DataFrame: repartition(…), spark.sql.shuffle.partitions
Executors & cores are controlled via submit-time configs; the scheduler decides which executor runs which task.
Example of spark architecture to make software product
The Cluster (Like the Company Infrastructure)
Imagine you are running a software company.
The cluster is like the entire office building (all resources: computers, network, employees).
It provides the machines and resources where your product team (Spark jobs) will work.
The Driver (Like the Project Manager / Team Lead)
The driver is like the project manager.
Responsibilities:
Understands the goal of the project (the job you want to run).
Plans the work: divides the project into smaller tasks.
Coordinates with the team (executors).
Keeps track of progress and collects the final results.
In Spark terms:
The Driver runs your main() program.
It converts the work into tasks and sends them to executors.
The Executors (Like the Developers / Engineers)
Executors are the software developers in your team.
Each developer (executor) works on a piece of the project given by the project manager (driver).
They do the actual coding & building (processing data).
After finishing, they report results back to the manager (driver).
In Spark terms:
Executors run on cluster nodes.
They process data and store results temporarily for the driver.
The Cluster Manager (Like the HR / Resource Manager)
The cluster manager is like the HR department or operations manager.
They don’t do the actual work but decide who gets what resources:
How many computers (nodes) should the team get?
How much memory/CPU should each developer (executor) use?
In Spark terms:
Examples: YARN, Kubernetes, Spark’s Standalone Manager.
They allocate resources for Spark jobs.
Putting It All Together (Real Software Example)
Let’s say you’re building a recommendation system in your product:
You (user) submit the project idea → "Build recommendations".
Driver (Project Manager) breaks it into tasks: "Analyze user data", "Process product history", "Generate recommendations".
Cluster Manager (HR) assigns computers (resources) to the project.
Executors (Developers) actually crunch the data on different machines and finish their assigned tasks.
Driver (PM) collects all results and gives the final recommendation model back to you.
✅ In short:
Cluster = The company office (resources).
Driver = Project Manager (plans & coordinates).
Executors = Developers (do the work).
Cluster Manager = HR/Operations (assigns resources).
Example of Spark Architecture as a Travel Platform
Driver = Trip Booking Orchestrator
In MakeMyTrip, you submit a single trip request (flight + hotel + car + insurance).
The orchestrator service breaks your trip into subtasks—find flights, find hotels, check car availability, bundle offers.
In Spark, the Driver does the same: it takes a big analytics or computation job and splits it into smaller pieces (tasks, stages).
Cluster Manager = Resource Allocator
MakeMyTrip’s backend has a resource allocation/service registry system (maybe powered by Kubernetes or custom logic).
It decides which backend service (flight, hotel, payment microservice, etc.) runs your subtasks and on what servers.
Spark’s Cluster Manager decides which worker machines will run your distributed data tasks.
Worker Machines = Backend Servers
The app has many backend servers in the cloud (handling hotels, flights, cars, payments).
In Spark, these are equivalent to Worker Machines—real servers in the cluster that do the computation.
Executors = Microservice Instances
Each backend microservice instance (e.g., HotelSearch-v2 on server3, FlightPriceChecker on server8) processes a specific part of your travel request.
In Spark, Executors do the same for data jobs—they run in parallel across machines, each doing calculations (finding best hotel deals, flight routes, etc.).
How a Big Data Analytics Job Looks in This Analogy
Scenario:
MakeMyTrip wants to analyze “best travel deals in July for every city.”
User or Analyst submits a request.
Driver (Orchestrator) splits it by category (city, deal type, etc.)
Cluster Manager (Resource Allocator) finds free backend servers.
Worker Machines run the parallel calculations—one finds cheapest hotels, another best flights for each city.
Executors (microservice instances) on each machine crunch their assigned “travel data” in parallel.
All results flow back up and get merged into a report of the “best July deals.”
Example of Spark Architecture as a Ecommerce website
Driver = Orchestrator/Coordinator Service
In a microservices setup, you usually have an API Gateway or a Coordination Service that breaks up a user request into smaller jobs (inventory check, price lookup, shipping, etc.).
In Spark, the Driver is just like this coordinator. It takes a “big job” (an analytics query, recommendation run, etc.), splits it into tasks, and manages them.
Cluster Manager = Service Registry/Load Balancer
In microservices, a service registry or load balancer (like Kubernetes, Consul, or Netflix Eureka) keeps track of all running microservices and their resources.
In Spark, the Cluster Manager (YARN, Kubernetes, Mesos, or Spark’s built-in manager) keeps track of all available machines (nodes) and hands out resources for new jobs.
Executors = Stateless Worker Microservices
In an e-commerce app, you have many instances of various microservices (for searching, recommendations, user profile, payments, etc.) running in parallel, each processing user requests.
In Spark, Executors are like microservice instances—they run on the worker machines, each handling part of the data processing task, just like microservice replicas handle pieces of traffic or business logic.
Worker Machines = Cloud Server Nodes
In the microservice world, your services run on a fleet of machines (VMs, containers on EKS/GKE/AKS, etc.).
In Spark, these are Worker Nodes that run the Executors.
How a Spark Job Runs — Microservices Analogy
Let’s say Flipkart wants to recommend products to users:
User triggers a recommendation.
Driver (Coordinator Service) receives this big job. It figures out what kind of analysis/calculations need to be run.
Driver asks Cluster Manager (Service Registry/Load Balancer) for machines to help.
Cluster Manager assigns Worker Nodes (Cloud Servers).
Executors (Stateless Workers), running on these nodes, each work on a piece of the product/user data.
All the partial results are sent back to the Driver (Coordinator), which combines them and sends back recommendations to the user.

Top comments (0)