Need for Faster RCNN
Model architecture of Faster RCNN
Why we need RPN layer in Faster RCNN
Difference between feature map and region generated by region proposal
why use anchor box
pros and cons of faster RCNN
Need for Faster RCNN
After the Fast R-CNN, the bottleneck of the architecture is selective search. Since it needs to generate 2000 proposals per image. It constitutes a major part of the training time of the whole architecture. In Faster R-CNN, it was replaced by the region proposal network. First of all, in this network, we passed the image into the backbone network. This backbone network generates a convolution feature map. These feature maps are then passed into the region proposal network. The region proposal network takes a feature map and generates the anchors (the centre of the sliding window with a unique size and scale). These anchors are then passed into the classification layer (which classifies that there is an object or not) and the regression layer (which localize the bounding box associated with an object).
Faster R-CNN improves upon the Fast R-CNN architecture in several key aspects, providing several advantages over its predecessor. Here are some of the advantages of Faster R-CNN over Fast R-CNN:
Integrated Region Proposal Network (RPN):
Faster R-CNN introduces an additional network called the Region Proposal Network (RPN), which shares the convolutional features with the object detection network.
This integration eliminates the need for an external region proposal method, such as Selective Search used in Fast R-CNN, making the model end-to-end trainable.
The RPN efficiently generates region proposals by sliding a small network over the convolutional feature map, significantly reducing computation compared to external methods.
Improved Speed and Efficiency:
By incorporating the RPN directly into the network architecture, Faster R-CNN streamlines the object detection pipeline and reduces computation time.
The shared convolutional features between the RPN and the object detection network help in reducing redundant computations, resulting in faster inference times.
Better Localization Accuracy:
The RPN generates region proposals with more accurate bounding box coordinates compared to external methods like Selective Search.
By learning to predict bounding box coordinates directly from convolutional features, Faster R-CNN improves localization accuracy, leading to more precise object detections.
End-to-End Training:
Faster R-CNN enables end-to-end training of both the region proposal and object detection networks.
This end-to-end training approach allows the network to learn features that are optimized for the specific task of object detection, leading to improved performance compared to separately trained components.
Flexibility and Adaptability:
The modular design of Faster R-CNN facilitates the incorporation of different backbone networks, such as VGG, ResNet, or Inception, providing flexibility in model architecture and allowing users to choose networks based on performance and computational resources.
Model architecture of Faster RCNN
Identifying and localizing objects within images or video streams is one of the key tasks in computer vision. With the arrival of deep learning, there is significant growth in this field. Faster R-CNN, a major breakthrough, has reshaped how objects are detected and categorized in real-world images. It is the advancement of R-CNN architecture. The R-CNN family operates in the following phases:
- Region proposal networks to identify possible locations in an image where objects might be present.
- CNN to extract important features.
- Classification to predict the class.
- Regression to fine-tune object bounding box coordinates
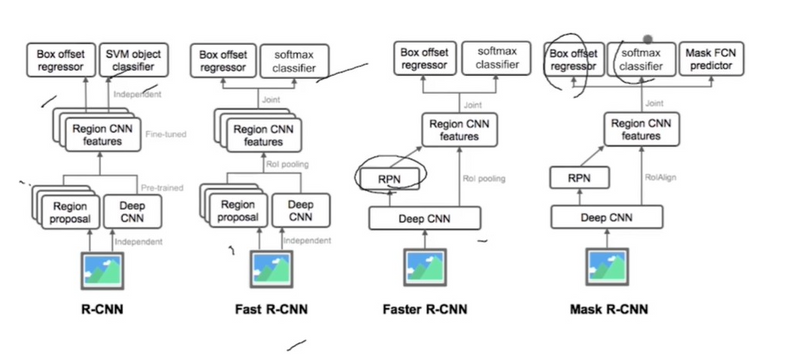
Both R-CNN and Fast R-CNN use CPU-based algorithms, which is slower because it runs on CPU computation. Faster R-CNN uses deep learning-based CNN architecture and attention to generate the regions proposals, which significantly reduces the time and also improves the accuracy of object detections and localizations in images.
Faster R-CNN
Faster R-CNN short for “Faster Region-Convolutional Neural Network” is a state-of-the-art object detection architecture of the R-CNN family, The primary goal of the Faster R-CNN network is to develop a unified architecture that not only detects objects within an image but also locates the objects precisely in the image. It combines the benefits of deep learning, convolutional neural networks (CNNs), and region proposal networks(RPNs) into a cohesive network, which significantly improves the speed and accuracy of the model.
Faster R-CNN architecture consists of two components
- Region Proposal Network (RPN)
- Fast R-CNN detector
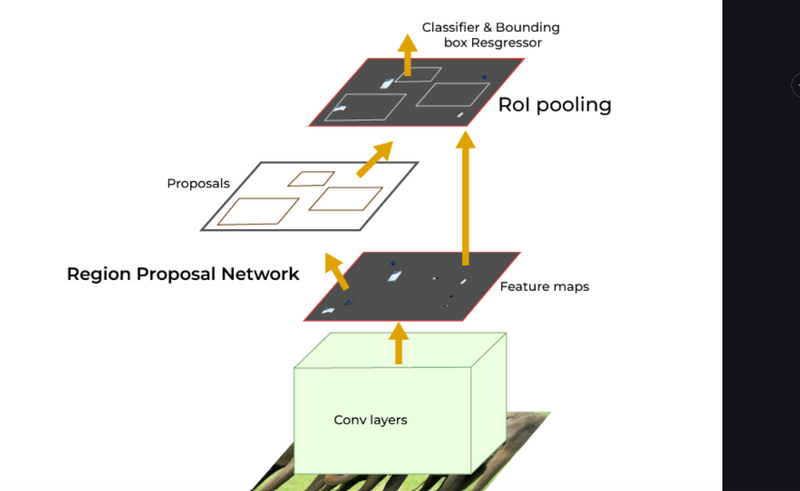
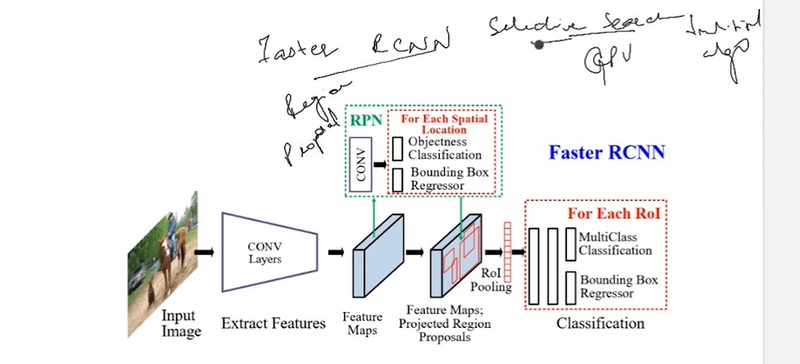
Before discussing the RPN and Fast R-CNN detector, Let’s understand the Shared Convolutional Layers that works as the backbone in Faster R-CNN architecture. It is the common CNN layer used for both RPN and Fast R-CNN detector as shown in the figure.
Convolutional Neural Network (CNN) Backbone
The Convolutional Neural Network (CNN) Backbone is the starting layers of Faster R-CNN architecture. The input image is passed through a CNN backbone (e.g., ResNet, VGG) to extract feature maps. These feature maps capture different levels of visual information from the image. Which is further used by Region Proposal Network (RPN) and Fast R-CNN detector. Let’s understand the role of Convolutional Neural Network (CNN) Backbone in detatils
- The primary objective of CNN is to extract the relevant features from the input image. It consists of multiple convolutions layers that apply different-different convolutions kernel to extract the feature from the input image.
- These kernels are designed to capture the hierarchical representations of the input image means the initial layers of CNN captures the low-lavel fetures likes edges and tectures, and while deeper layers captures the high lavel semantic features like objects parts and shapes.
- Both RPN and Fast R-CNN detector uses the same extracted hierarchical features. This results in a significant reduction in computing time and memory use because the computations carried out by these layers are employed for both tasks .
Region Proposal Network (RPN)
Previously R-CNN and Fast R-CNN models uses traditional Selective Search algorithm for generating region proposals. It runs on CPU So, it takes more time in computations. Faster R-CNN fixes these issues by introducing a convolutional-based network i.e. RPN, which reduces proposal time for each image to 10 ms from 2 seconds and improves feature representation by sharing layers with detection stages.
Region Proposal Network (RPN) is an essential component of Faster R-CNN. It is responsible for generating possible regions of interest (region proposals) in images that may contain objects. It uses the concept of attention mechanism in neural networks that instruct the subsequent Fast R-CNN detector where to look for objects in the image. The key components of the Region Proposal Network are as follows:
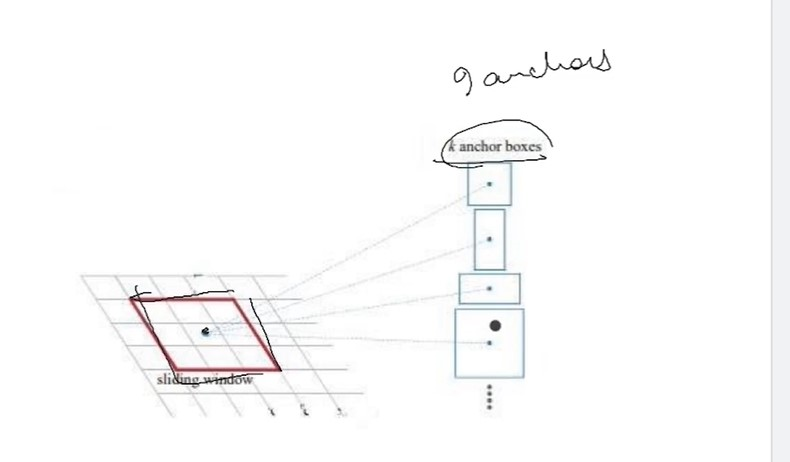
Anchors boxes: Anchors are used to generate region proposals in the Faster R-CNN model. It uses a set of predefined anchor boxes with various scales and aspect ratios. These anchor boxes are placed at different positions on the feature maps.
An anchor box has two key parameters
scale
aspect ratio
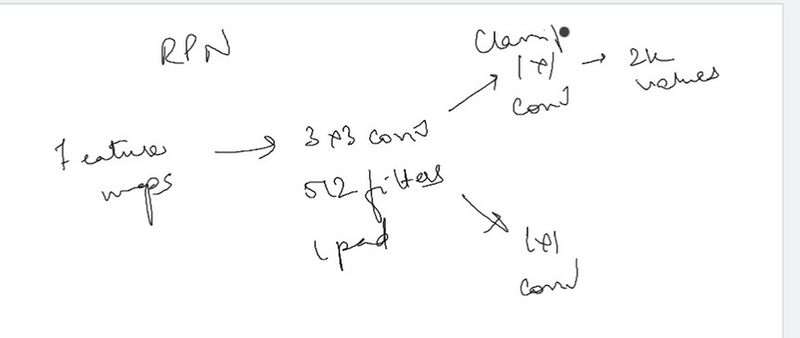
Sliding Window approach: The RPN operates as a sliding window mechanism over the feature map obtained from the CNN backbone. It uses a small convolutional network (typically a 3×3 convolutional layer) to process the features within the receptive field of the sliding window. This convolutional operation produces scores indicating the likelihood of an object’s presence and regression values for adjusting the anchor boxes.
Objectness Score: The objectness score represents the probability that a given anchor box contains an object of interest rather than being just background. In Faster R-CNN, the RPN predicts this score for each anchor. The objectness score reflects the confidence that the anchor corresponds to a meaningful object region. This score is used to classify anchors as either positive (object) or negative (background) during training.
IoU (Intersection over Union): Intersection over Union (IoU) is a metric used to measure the degree of overlap between two bounding boxes. It calculates the ratio of the area of overlap between the two boxes to the area of their union. Mathematically, it is represented as:

Non-Maximum Suppression (NMS): NMS is used to remove redundancy and select the most accurate proposals, based on the objectness scores of overlapping proposals and keeps only the proposal with the highest score while suppressing the others.
The feature maps obtained from the CNN backbone are used by the RPN. On these feature maps, the RPN uses a sliding window approach with anchor boxes of varying scales and shapes to designate potential object positions. The network refines these anchor boxes throughout training to better match actual object positions and sizes. For each anchor, the RPN predicts two parameters.
- The probability of the anchor containing an object (“objectness Score”)..
- Adjustments to the anchor’s coordinates to match the actual object’s shape
.
When a large number of region proposals are generated, many of them may overlap and correspond to the same object. Here the Non-Maximum Suppression (NMS) are used to ranks the anchor boxes based on their objectness probabilities and selects the top-N anchor boxes with the highest scores. NMS ensures that the final selected proposals are both accurate and non-overlapping. These selected anchor boxes are considered as possible region proposals.
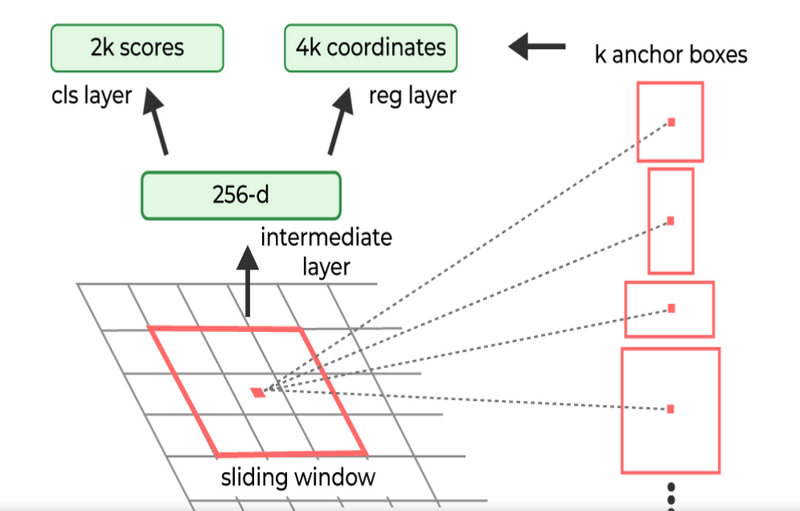
Step by Step Faster R-CNN Process
Input and Shared Convolutional Layers:
- The RPN takes an image of any size as input and aims to produce rectangular object proposals based on the objectness score.
- The input image is processed using fully convolution layer, and because these compuations are shared with Both RPN and the Fast R-CNN object detection network, a common set of convolutional layers are used.
Two fully convolution models are commonly used i.e:
Zeiler and Fergus model (ZF): It has the 5 shareable convolutional layers.
Simonyan and Zisserman model (VGG-16): It has the 13 shareable convolutional layers
.
Sliding Window Approach:The RPN generates proposals by sliding a small network over the convolutional feature map output obtained from the last shared convolutional layer.
This small network operates on an n × n spatial window of the input convolutional feature map.
Each sliding window is mapped to a lower-dimensional feature, with dimensions of :
256-d for Zeiler and Fergus model (ZF)
512-d for Simonyan and Zisserman model (VGG-16)
Further it is followed by a Rectified Linear Unit (ReLU) activation.The small network works in a sliding-window manner across the feature map.
The fully-connected layers are shared across all spatial locations due to the sliding-window operation.
The sliding window architecture is effectively realized using an n × n convolutional layer, followed by two 1 × 1 convolutional layers for box regression and box classification.
The sliding window, typically of size nxn (e.g., n = 3 for the sliding window leads to a large effective receptive field on the input image (171 pixels for ZF and 228 pixels for VGG)), is moved across the feature map
.
Anchors Boxes:The sliding window, typically of size nxn (e.g., n = 3 for the sliding window leads to a large effective receptive field on the input image (171 pixels for ZF and 228 pixels for VGG)), is moved across the feature map. For each window position, K region proposals are generated. Each proposal is defined by an anchor box, which is parameterized by scale and aspect ratio.
Multiple anchor boxes are created by varying these parameters, resulting in different scales and aspect ratios. This creates a set of anchor boxes, usually K=9, allowing the model to consider various object sizes and shapes. These anchor variations enable the model to handle scale invariance and share features between the RPN and Fast R-CNN.
Anchors enable the use of a single image at a single scale while still achieving scale-invariant object detection. This eliminates the need for multiple images or filters for handling different scales
.
Sibling Fully-Connected Layers:
For each generated region proposal, a feature vector is extracted. This vector has a length of 256 (for ZF net) or 512 (for VGG-16 net) and is then processed by two sibling fully-connected (FC) layers:
The lower-dimensional feature extracted from the sliding window is fed into two sibling fully-connected layers
Box-Classification Layer (cls):It Predicts an objectness score for the proposed region, indicating whether the region contains an object or is background.The “cls” FC layer is a binary classifier that assigns an objectness score to each region proposal. It determines whether the proposal contains an object or is part of the background.
Box-Regression Layer (reg): It predict adjustments for the bounding box of the proposed region.The “reg” FC layer returns a 4-D vector that defines the bounding box of the region proposal.
The “cls” FC layer produces two outputs: one for classifying the region as background and another for classifying the region as an object. The objectness score assigned to each anchor helps generate the classification label.
Why we need RPN layer in Faster RCNN
The feature maps obtained from the CNN backbone are used by the RPN. On these feature maps, the RPN uses a sliding window approach with anchor boxes of varying scales and shapes to designate potential object positions. The network refines these anchor boxes throughout training to better match actual object positions and sizes. For each anchor, the RPN predicts two parameters.
The probability of the anchor containing an object (“objectness Score”)..
Adjustments to the anchor’s coordinates to match the actual object’s shape.
When a large number of region proposals are generated, many of them may overlap and correspond to the same object. Here the Non-Maximum Suppression (NMS) are used to ranks the anchor boxes based on their objectness probabilities and selects the top-N anchor boxes with the highest scores. NMS ensures that the final selected proposals are both accurate and non-overlapping. These selected anchor boxes are considered as possible region proposals.
Difference between feature map and region generated by region proposal
Definition: A feature map is a spatial grid of features extracted from an input image by a convolutional neural network (CNN).
Purpose: Feature maps capture the hierarchical representation of the input image, encoding various visual patterns and structures at different levels of abstraction.
Dimensionality: Feature maps typically have a lower spatial resolution compared to the input image, as they undergo down-sampling through convolutional and pooling layers.
Representation: Each pixel in a feature map represents the activation of a particular feature detector (neuron) in the CNN, indicating the presence of certain visual patterns.
Usage: Feature maps serve as input to subsequent layers of the neural network for further processing and analysis, such as classification or object detection.
Region Generated by Region Proposal:
Definition: A region generated by a region proposal algorithm, such as the Region Proposal Network (RPN) in Faster R-CNN, is a candidate bounding box that potentially contains an object of interest within an image.
Generation: Region proposals are generated by algorithms based on features extracted from the feature map. These algorithms propose regions likely to contain objects, reducing the search space for object detection.
Characteristics: Region proposals are defined by their bounding box coordinates (x, y, width, height) and often associated with a confidence score indicating the likelihood of containing an object.
Selection: Region proposals are typically selected based on their objectness scores and may undergo post-processing steps like non-maximum suppression (NMS) to filter out redundant or overlapping proposals.
Usage: Selected region proposals are passed to subsequent stages of the object detection pipeline for further refinement and classification to produce the final object detections.
why use anchor box
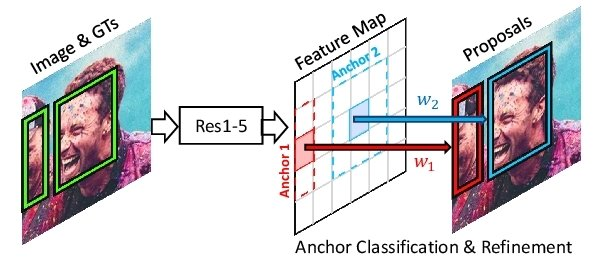
Anchors are used in Faster R-CNN to generate region proposals efficiently and to handle objects of different sizes and aspect ratios within an image. Here's why anchors are used:
Efficient Region Proposal Generation:
- Anchors serve as reference bounding boxes distributed over the spatial locations of the feature map.
- Instead of sliding a window of different sizes across the entire image, which can be computationally expensive, anchors enable the Region Proposal Network (RPN) to generate region proposals by convolving over the feature map.
Anchors effectively reduce the computational cost of generating region proposals, making the process more efficient
.
Handling Objects of Different Sizes and Aspect Ratios:Anchors are designed to cover a range of scales and aspect ratios, allowing the RPN to detect objects of varying sizes and shapes within the image.
By using anchors with different sizes and aspect ratios, the RPN can generate region proposals that accurately localize objects with diverse characteristics.
This flexibility in anchor design enables Faster R-CNN to handle objects with different scales and aspect ratios without the need for multiple scales of sliding windows or manually crafted anchor boxes
.
Localization Accuracy:Anchors provide initial hypotheses for object locations and sizes, which are refined during the subsequent stages of the object detection pipeline.
By using anchors as reference points, Faster R-CNN learns to predict adjustments to the anchor boxes to better fit the objects in the image.
This refinement process improves the localization accuracy of the object detection system, leading to more precise bounding box predictions.
Overall, anchors are a crucial component of Faster R-CNN as they enable efficient region proposal generation, handle objects of different sizes and aspect ratios, and contribute to the localization accuracy of the object detection system
.
pros and cons of Faster R-CNN
Pros:
Accuracy: Faster R-CNN typically achieves high accuracy in object detection tasks due to its integrated Region Proposal Network (RPN) and end-to-end trainable architecture.
Efficiency: By sharing convolutional features between the RPN and the object detection network, Faster R-CNN reduces redundant computations, leading to faster inference times compared to its predecessors like Fast R-CNN.
Flexibility: Faster R-CNN is flexible in terms of backbone network selection, allowing users to choose from various architectures like VGG, ResNet, or Inception based on their performance and computational resources.
End-to-End Training: Faster R-CNN enables end-to-end training of both the region proposal and object detection networks, resulting in better feature representations and improved performance.
Handling Scale and Aspect Ratio: The use of anchor boxes in the RPN allows Faster R-CNN to handle objects of different scales and aspect ratios effectively, enhancing its robustness in detecting objects of varying sizes and shapes.
Cons:
Complexity: Faster R-CNN is a complex architecture with multiple components, including the backbone network, RPN, and object detection network. This complexity may make implementation and training more challenging.
Training Time: Training Faster R-CNN can be time-consuming, especially when using large-scale datasets and complex backbone networks. Training a Faster R-CNN model from scratch may require significant computational resources and time.
Resource Intensive: Inference with Faster R-CNN can be resource-intensive, particularly when processing high-resolution images or deploying models on resource-constrained devices.
Hyperparameter Tuning: Faster R-CNN involves tuning various hyperparameters, such as anchor scales, aspect ratios, and learning rates, to achieve optimal performance. Finding the right set of hyperparameters may require extensive experimentation.
Overfitting: Like many deep learning architectures, Faster R-CNN is susceptible to overfitting, especially when trained on small datasets or with inadequate regularization techniques. Proper data augmentation and regularization strategies are essential to mitigate overfitting.
Overall, despite its complexity and resource requirements, Faster R-CNN remains one of the most effective and widely used architectures for object detection, offering a balance between accuracy, efficiency, and flexibility.

Top comments (0)