Explain concept of training accuracy,validation accuracy,training loss and validation loss
list out checklist of reason training losses,validation losses.
list out checklist to improve training loss and validation loss.
Explain concept of training accuracy,validation accuracy,training loss and validation loss
Training loss and validation loss are essential metrics in deep learning that help you assess the performance of your neural network during the training process. They are used to gauge how well your model is learning and generalizing from the training data. Here's an explanation of training and validation loss with examples:
Training Loss:
Training loss (also known as training error or training objective) measures how well your model is performing on the training data. It quantifies the discrepancy between the predicted values and the actual target values in the training dataset.
Validation Loss:
Validation loss measures how well your model generalizes to unseen data. It's computed using a separate dataset called the validation dataset, which the model has not seen during training. The goal is to assess how well your model performs on data it hasn't been exposed to.
Example:
Let's consider a simple example of training and validation loss using a regression task. Suppose you are building a neural network to predict house prices based on the number of bedrooms and square footage of houses.
# Example code in Python using TensorFlow/Keras
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
# Generate synthetic data
X = np.random.rand(100, 2)
y = 2 * X[:, 0] + 3 * X[:, 1] + 1 + 0.1 * np.random.randn(100)
# Split data into training and validation sets
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# Build a simple neural network
model = Sequential()
model.add(Dense(1, input_dim=2, activation='linear'))
# Compile the model
model.compile(optimizer='sgd', loss='mean_squared_error')
# Train the model
history = model.fit(X_train, y_train, validation_data=(X_val, y_val), epochs=100, verbose=0)
# Extract training and validation losses
training_losses = history.history['loss']
validation_losses = history.history['val_loss']
# Plot the losses to visualize training and validation performance
import matplotlib.pyplot as plt
plt.plot(training_losses, label='Training Loss')
plt.plot(validation_losses, label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
In this example:
- We generate synthetic data for the house price prediction task.
- We split the data into training and validation sets using train_test_split.
- We create a simple neural network with one output neuron for regression.
- We compile the model with a mean squared error (MSE) loss function.
- We train the model using the training data, monitoring the validation loss . After training, we extract and plot the training and validation losses over the training epochs. The training loss should decrease as the model learns, and the validation loss should ideally follow a similar trend, indicating that the model is generalizing well. If the validation loss starts to increase while the training loss is still decreasing, it may be a sign of overfitting, which should be addressed. ==============================================================
Training accuracy and validation accuracy are metrics used to assess the performance of a deep learning model during training and evaluation on unseen data, respectively. They provide insights into how well a neural network is learning from the training data and how effectively it generalizes to new, unseen data. Here's an explanation of training accuracy and validation accuracy with examples:
Training Accuracy:
Training accuracy measures how well your model is performing on the training data. It calculates the proportion of correctly classified examples in the training dataset. High training accuracy indicates that the model is learning the training data well but does not necessarily imply good generalization to new data.
Validation Accuracy:
Validation accuracy assesses the model's performance on a separate dataset known as the validation dataset, which the model has not seen during training. It quantifies the proportion of correctly classified examples in the validation dataset. Validation accuracy provides an estimate of how well the model is likely to perform on new, unseen data.
Example:
Let's consider a classification task using a simple neural network to classify images of handwritten digits as either "0" or "1" (binary classification).
# Example code in Python using TensorFlow/Keras
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.datasets import mnist
# Load the MNIST dataset
(X_train, y_train), (X_val, y_val) = mnist.load_data()
# Preprocess the data
X_train = X_train.reshape(60000, 784)
X_val = X_val.reshape(10000, 784)
X_train = X_train / 255.0
X_val = X_val / 255.0
y_train = (y_train == 1).astype(int)
y_val = (y_val == 1).astype(int)
# Build a simple neural network
model = Sequential()
model.add(Dense(128, input_dim=784, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
model.fit(X_train, y_train, validation_data=(X_val, y_val), epochs=10, batch_size=32)
# Evaluate the model on the validation data
validation_loss, validation_accuracy = model.evaluate(X_val, y_val)
print(f"Validation Accuracy: {validation_accuracy:.2f}")
In this example:
- We load the MNIST dataset, which contains images of handwritten digits.
- We preprocess the data by reshaping it and normalizing pixel values to the range [0, 1].
- We build a simple neural network for binary classification of "0" or "1" digits.
- We compile the model with binary cross-entropy loss and accuracy as a metric.
- We train the model using the training data while monitoring the validation accuracy.
- After training, we evaluate the model on the validation data to compute the validation accuracy . The training accuracy represents how well the model is learning the "0" and "1" digits from the training data, while the validation accuracy provides an estimate of the model's performance on new, unseen digits. In practice, you want the validation accuracy to be as close as possible to the training accuracy, indicating that the model generalizes well to new data. If there is a significant gap between training and validation accuracy, it could be a sign of overfitting, which may require regularization techniques or other adjustments.
Training loss and validation loss are essential metrics in deep learning that help you assess the performance of your neural network during the training process. They are used to gauge how well your model is learning and generalizing from the training data. Here's an explanation of training and validation loss with examples:
Training Loss:
Training loss (also known as training error or training objective) measures how well your model is performing on the training data. It quantifies the discrepancy between the predicted values and the actual target values in the training dataset.
Validation Loss:
Validation loss measures how well your model generalizes to unseen data. It's computed using a separate dataset called the validation dataset, which the model has not seen during training. The goal is to assess how well your model performs on data it hasn't been exposed to.
Example:
Let's consider a simple example of training and validation loss using a regression task. Suppose you are building a neural network to predict house prices based on the number of bedrooms and square footage of houses.
# Example code in Python using TensorFlow/Keras
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
# Generate synthetic data
X = np.random.rand(100, 2)
y = 2 * X[:, 0] + 3 * X[:, 1] + 1 + 0.1 * np.random.randn(100)
# Split data into training and validation sets
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# Build a simple neural network
model = Sequential()
model.add(Dense(1, input_dim=2, activation='linear'))
# Compile the model
model.compile(optimizer='sgd', loss='mean_squared_error')
# Train the model
history = model.fit(X_train, y_train, validation_data=(X_val, y_val), epochs=100, verbose=0)
# Extract training and validation losses
training_losses = history.history['loss']
validation_losses = history.history['val_loss']
# Plot the losses to visualize training and validation performance
import matplotlib.pyplot as plt
plt.plot(training_losses, label='Training Loss')
plt.plot(validation_losses, label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
In this example:
- We generate synthetic data for the house price prediction task.
- We split the data into training and validation sets using train_test_split.
- We create a simple neural network with one output neuron for regression.
- We compile the model with a mean squared error (MSE) loss function.
- We train the model using the training data, monitoring the validation loss . After training, we extract and plot the training and validation losses over the training epochs. The training loss should decrease as the model learns, and the validation loss should ideally follow a similar trend, indicating that the model is generalizing well. If the validation loss starts to increase while the training loss is still decreasing, it may be a sign of overfitting, which should be addressed.
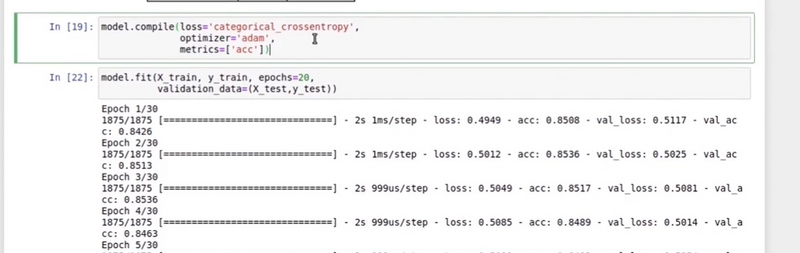
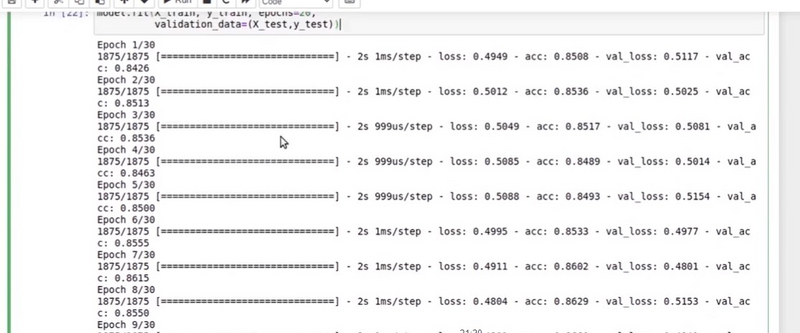
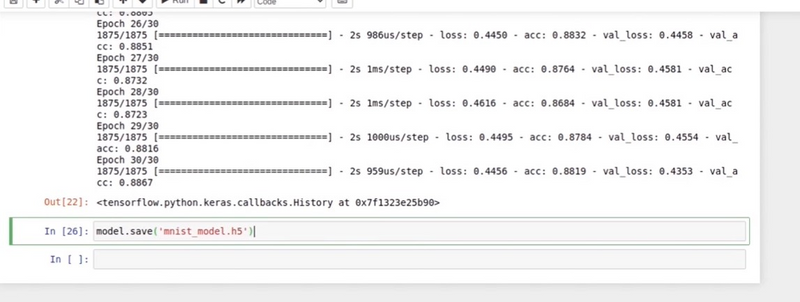
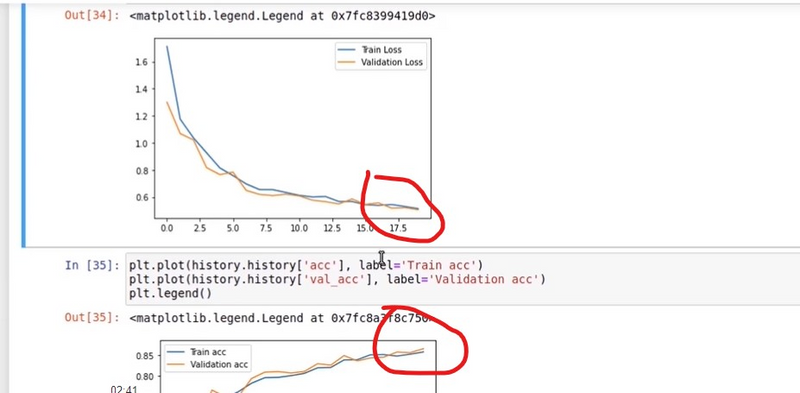
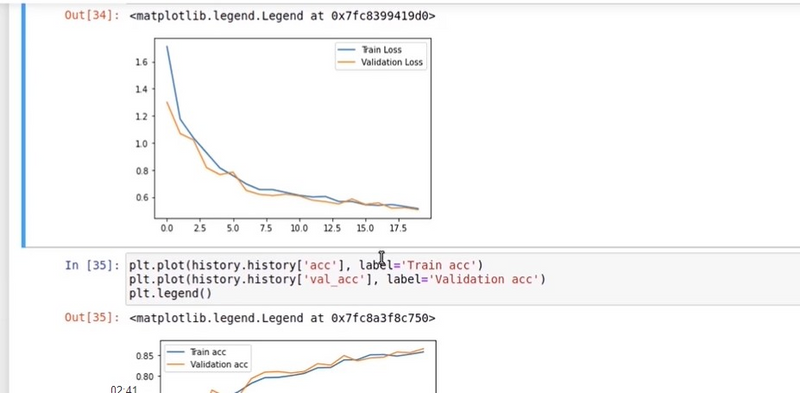
if training accuracy and validation accuracy both are attached nearby then it is neither great loss or accuracy
list out checklist of reason training losses,validation losses
When training a neural network, it's common to monitor both training losses and validation losses to ensure that the model is learning effectively. If the training and validation losses are not decreasing or if they are increasing, it indicates that there may be issues with the model or training process. Here's a checklist of potential reasons for such behavior, along with examples:
Overfitting:
Reason: The model has learned to fit the training data too closely and is not generalizing well to unseen data.
Example: You have a deep neural network for image classification, but it consistently performs poorly on new images not seen during training.
Complex Model:
Reason: The model may be too complex for the amount of training data, leading to overfitting.
Example: You are training a neural network with a large number of layers and parameters on a small dataset of medical images, and the validation loss is increasing.
Insufficient Data:
Reason: If you have a small dataset, the model may not have enough diverse examples to learn general patterns.
Example: You are training a natural language processing model for sentiment analysis, but you have only a few hundred training samples.
Learning Rate Too High:
Reason: A high learning rate can cause the model to overshoot the optimal parameter values and make it difficult for the loss to converge.
Example: Your deep reinforcement learning agent's training losses are not decreasing because the learning rate is too large.
Learning Rate Decay:
Reason: If the learning rate decays too quickly, the model may stop learning prematurely.
Example: The initial learning rate for your neural network is too high, and it drops too rapidly during training.
Gradient Vanishing/Exploding:
Reason: Poorly initialized weights or deep networks can lead to vanishing or exploding gradients, making it difficult for the model to learn.
Example: Training a very deep recurrent neural network (RNN) for sequence prediction, and the training loss is not decreasing.
Data Preprocessing Issues:
Reason: Data preprocessing, such as normalization or feature scaling, might be incorrect, leading to poor convergence.
Example: You forgot to normalize your input data before training a deep learning model.
Incorrect Loss Function:
Reason: The choice of loss function may not be suitable for the specific problem, making it challenging for the model to optimize effectively.
Example: Using Mean Squared Error (MSE) loss for a classification task instead of Cross-Entropy loss.
Insufficient Training Steps:
Reason: The model may need more training steps/epochs to converge properly.
Example: You stopped training a neural network after just a few epochs, assuming it's converged when it hasn't.
Bugs in Code:
Reason: There may be errors in the code, such as incorrect data loading, model architecture, or training loop.
Example: There's a bug in the code that causes the model to not learn correctly, leading to stagnating losses.
Class Imbalance:
Reason: In a classification task, class imbalances can lead to poor performance, and the model may not be learning the minority class well.
Example: Your model is not performing well on detecting rare diseases because the dataset has an imbalance of healthy and disease cases.
Model Initialization:
Reason: The choice of initialization for the model's weights can affect convergence.
Example: Using random initialization for a deep network instead of using Xavier/Glorot or He initialization.
To address these issues, you can experiment with various techniques such as adjusting model complexity, using regularization methods, changing the learning rate, applying early stopping, improving data quality, or choosing different loss functions. It often takes some iteration and experimentation to fine-tune a neural network for the best performance.
list out checklist to improve training loss and validation loss
Improving training and validation loss in a neural network is essential for achieving better model performance. Here's a checklist to help you address issues when the training and validation losses are not decreasing as expected, along with examples:
Check Data Quality:
- Issue: Poor-quality or noisy data can lead to training difficulties.
Example: If you're working with an image classification dataset, check for mislabeled or corrupted images
.
Data Augmentation:Issue: Limited data can cause overfitting.
Example: In computer vision tasks, apply data augmentation techniques (e.g., rotation, scaling, and flipping) to artificially increase the size of the training dataset
.
Regularization Techniques:Issue: Overfitting can occur when the model is too complex.
Example: Apply L1 or L2 regularization, dropout, or early stopping to prevent overfitting
.
Model Complexity:Issue: A too complex model can lead to overfitting.
Example: Reduce the number of layers or neurons in the network, especially if the dataset is small
.
Learning Rate Tuning:Issue: An inappropriate learning rate can slow down or impede convergence.
Example: Experiment with different learning rates or learning rate schedules to find the optimal value for your problem
.
Batch Size Selection:Issue: An incorrect batch size may affect training.
Example: Adjust the batch size based on available memory and problem complexity. Smaller batch sizes may generalize better
.
Normalization and Scaling:Issue: Input features may need scaling or normalization.
Example: Normalize input data (e.g., using z-score normalization) to ensure all features have similar scales
.
Exploratory Data Analysis (EDA):Issue: Lack of understanding of the dataset can lead to suboptimal models.
Example: Conduct EDA to understand feature distributions, correlations, and patterns in the data
.
Feature Engineering:Issue: Poorly engineered features can hinder model performance.
Example: Create new features or transform existing ones to capture relevant information
.
Loss Function Selection:Issue: An inappropriate loss function can hinder optimization.
Example: Choose the correct loss function for your task (e.g., Cross-Entropy for classification, Mean Squared Error for regression)
.
Model Initialization:Issue: Poor initialization of model weights can affect convergence.
Example: Use appropriate weight initialization techniques (e.g., Xavier/Glorot, He initialization) for your network
.
Hyperparameter Tuning:Issue: Poorly chosen hyperparameters can lead to poor performance.
Example: Systematically search for optimal hyperparameters using techniques like grid search or random search
.
Monitor and Visualize Loss:Issue: Without monitoring and visualizing loss, it's challenging to identify issues.
Example: Use tools like TensorBoard to visualize loss and other metrics during training
.
Early Stopping:Issue: Training for too long can lead to overfitting.
Example: Implement early stopping based on validation loss to stop training when it starts to deteriorate
.
Ensemble Learning:Issue: Individual models may underperform.
Example: Create an ensemble of models with different architectures or hyperparameters to improve overall performance
.
Transfer Learning:Issue: Training from scratch on a small dataset can be challenging.
Example: Use pre-trained models and fine-tune them on your specific task
.
Regular Monitoring and Iteration:Issue: Models may need multiple iterations of improvement.
Example: Continuously monitor model performance, make adjustments, and iterate through the checklist as needed
.
Improving training and validation loss often requires a combination of these techniques and iterative experimentation. The checklist provides a structured approach to diagnosing and addressing issues in your neural network training.

Top comments (0)