What is word2vec.
How ord2vec captures their meanings, similarities, and relationships.
Difference between word2vec and word embedding using keras.
Why word2vector is popular than word embedding using keras ohe
Coding example of word2vec
list of genism commands
What is word2vec
In simple terms, Word2Vec is a technique used to represent words as numbers (vectors) in a way that captures their meaning and relationships with other words. It’s like giving each word its own “address” in a multi-dimensional space, where words with similar meanings are closer together.
Here’s a step-by-step breakdown of Word2Vec:
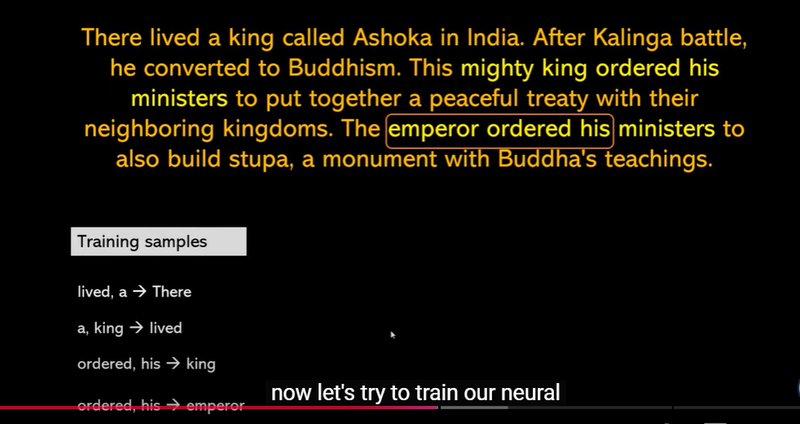
Goal: The main goal of Word2Vec is to understand the meaning of words based on the words they appear with in sentences. For example, if "cat" and "dog" often appear in similar contexts (like “I have a pet cat” and “I have a pet dog”), Word2Vec learns to put "cat" and "dog" closer together in its "word space."
How It Works:
- Word2Vec looks at words and their nearby words (context) in a large amount of text.
- It tries to learn how to predict either a word given its surrounding words or the surrounding words given a word. There are two main methods for this
:
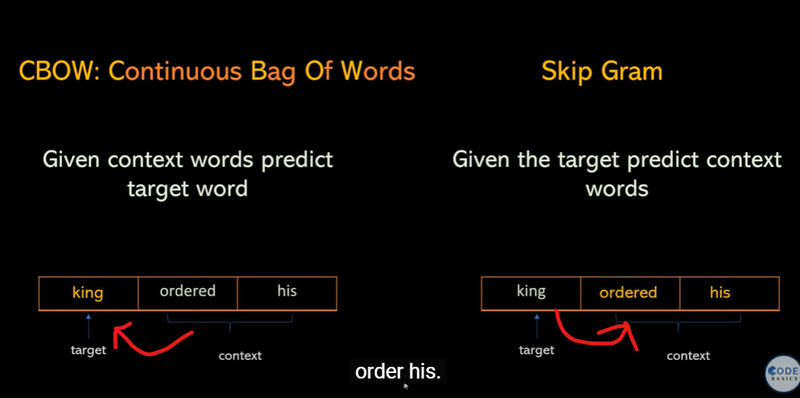
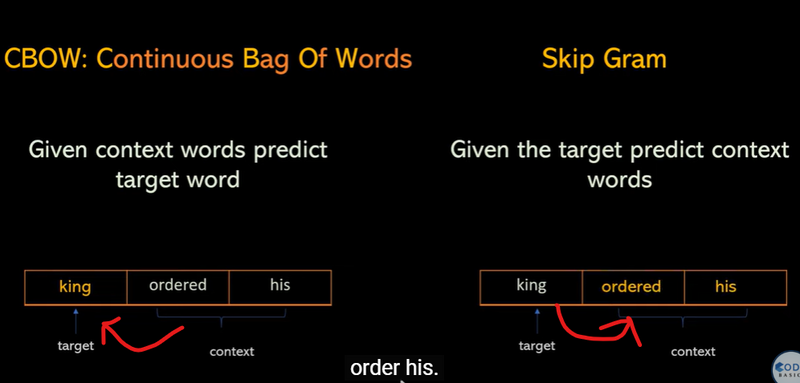
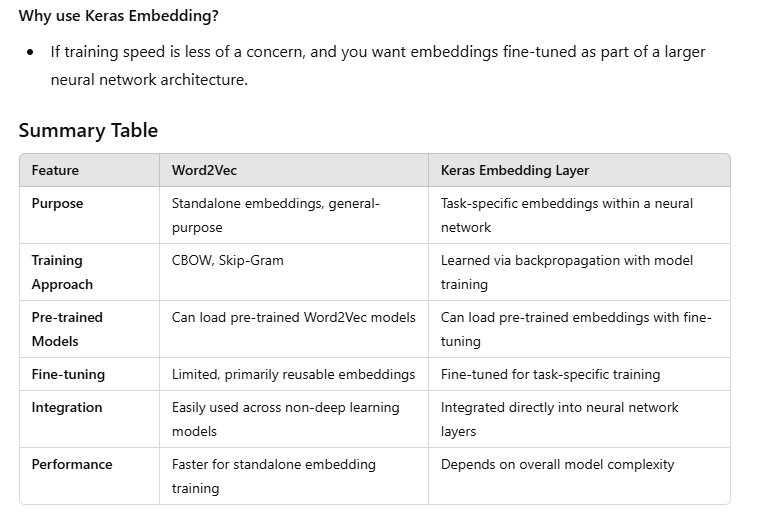
CBOW (Continuous Bag of Words): Predicts a word based on its surrounding words.
Skip-Gram: Predicts surrounding words based on a target word.
Output: After training, each word is represented as a list of numbers (called a vector). These vectors are designed in a way that similar words (like "king" and "queen") have similar vectors.
Why It’s Useful:
Once words are turned into these number vectors, you can do cool things like:
Find similar words: Words that appear in similar contexts get similar vectors, so you can find words that have similar meanings.
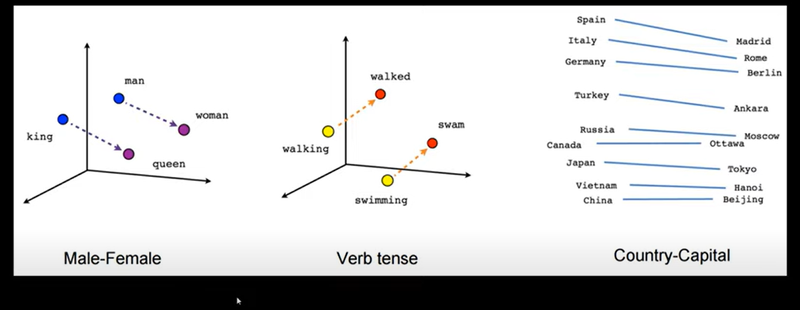
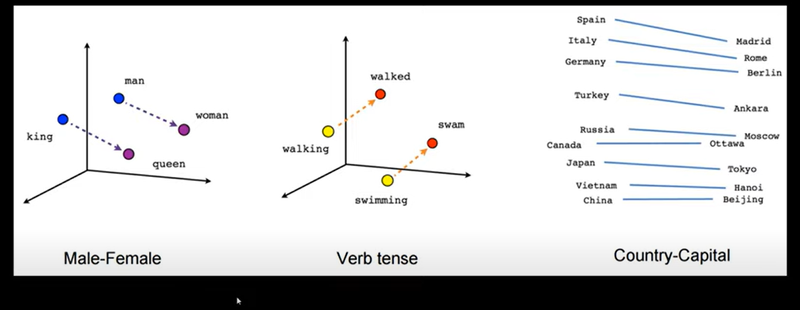
Solve analogies: With Word2Vec, you can solve things like “king is to queen as man is to ___” by calculating vectors. The model learns that "king" and "queen" have a relationship similar to "man" and "woman."
Example of Word Relationships:
- Imagine that after training, the vector for "king" is something like [0.25, 0.75, -0.4, ...] and the vector for "queen" is similar but with a slight difference in certain dimensions.
- If you subtract the vector for "man" from "king" and add "woman," you’ll get close to the vector for "queen." This is because Word2Vec captures relationships like gender and royalty in the word vectors .
How word2vec captures their meanings, similarities, and relationships
Word2Vec captures the meanings, similarities, and relationships of words by learning from the context in which words appear. It does this by observing large amounts of text data and trying to predict words based on their neighbors. Here’s a step-by-step explanation of how it achieves this:
- Learning Through Context Word2Vec operates on the principle that words that appear in similar contexts have similar meanings. For example, words like "king" and "queen" often appear near words like "royal" and "crown." Similarly, "cat" and "dog" might appear near words like "pet" and "animal." By learning these patterns, Word2Vec creates a "map" of words where words with similar meanings are closer together.
- Two Methods: CBOW and Skip-Gram
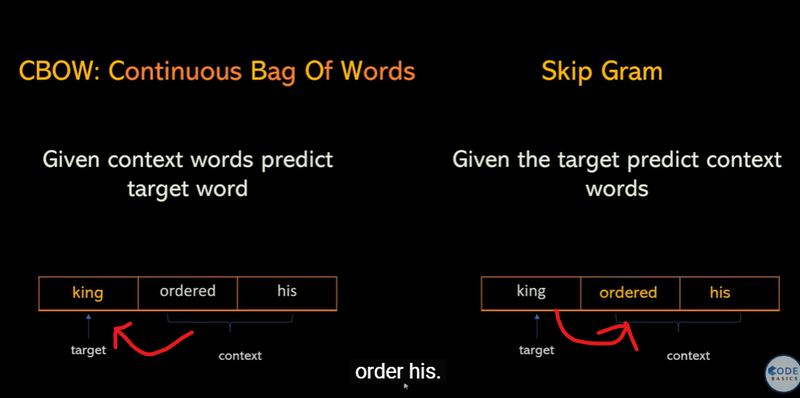
Word2Vec uses two main methods to learn word representations: Continuous Bag of Words (CBOW) and Skip-Gram.
CBOW (Continuous Bag of Words): This method tries to predict a target word based on its surrounding context words. For example, if we have the sentence "The cat sits on the mat," CBOW might try to predict "sits" given ["The", "cat", "on", "the", "mat"] as context words. This helps the model understand what kinds of words typically appear together.
Skip-Gram: This method works in the opposite way. Given a target word, Skip-Gram tries to predict the context words around it. So, with "sits" as the target, it would try to predict words like "cat," "on," "the," and "mat." This helps the model understand how a word relates to its surrounding words.
Both methods help Word2Vec learn that words in similar contexts tend to be related in meaning.
- Creating Word Vectors (Embeddings) As Word2Vec trains, it creates a unique vector (a list of numbers) for each word in the vocabulary. The position of each word vector in this high-dimensional space (often hundreds of dimensions) is determined by the patterns Word2Vec has learned from the context in which words appear. Each dimension in these vectors represents some aspect of a word’s meaning or relationship to other words, though these aspects are not directly interpretable by humans.
- Capturing Similarities: Clustering of Related Words Words that appear in similar contexts end up with similar vectors, which means they are closer together in the vector space. For example, "king," "queen," "prince," and "princess" may form a cluster in the vector space, while "cat," "dog," "animal," and "pet" form another cluster. This is because the model has learned that these words are often used in similar contexts, so it places them near each other.
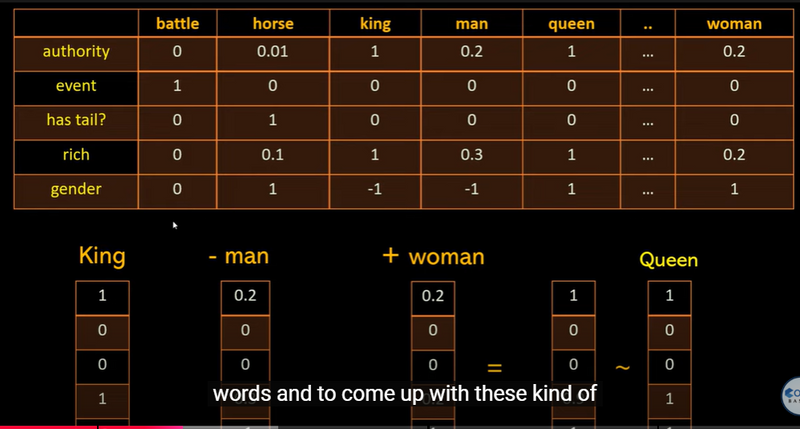
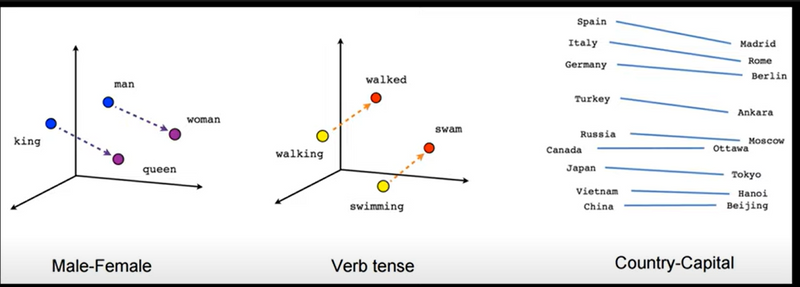
- Capturing Relationships: Vector Arithmetic One of the most powerful aspects of Word2Vec is that it can capture relationships between words in a way that allows for vector arithmetic. For example, the model learns that "king" and "queen" are related in a similar way that "man" and "woman" are. This relationship can be captured by vector arithmetic:
king - man + woman ≈ queen
This works because the difference between "king" and "man" (representing something like "royalty" or "gender") is similar to the difference between "queen" and "woman." Word2Vec has learned these relationships by observing word co-occurrences in text.
- Example: Solving Analogies Because Word2Vec captures these relationships, it can solve analogies. For example: "Paris is to France as Tokyo is to ____." By calculating Paris - France + Japan, the model’s vector arithmetic will lead it close to the vector for "Tokyo." This ability to solve analogies happens because Word2Vec learns not just meanings but also relationships and patterns among words.
- Subsampling of Frequent Words During training, very common words like "the," "is," and "and" are downsampled or ignored. This helps Word2Vec focus on the meaningful relationships between less common words rather than just learning that "the" appears everywhere. By focusing on more informative words, Word2Vec better captures the nuances of meaning between words.
- Negative Sampling and Context Window Word2Vec uses techniques like negative sampling to make training efficient, where it selectively learns from both correct word-context pairs and incorrect (negative) pairs. It also uses a context window, which is a fixed number of words around each target word, to define the context. This helps Word2Vec learn associations within a reasonable range, capturing both local word relationships and broader thematic similarities.
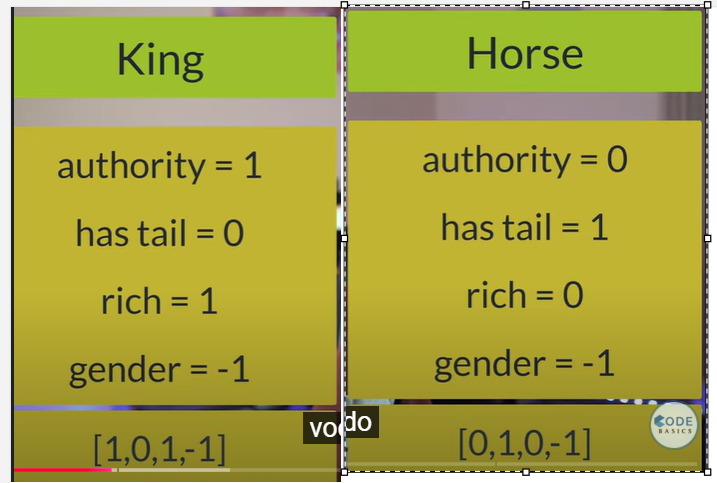
Feature Representation of Words ("King" vs. "Horse")
Feature-Based Representation - Demonstrates how specific features define each word

Word Embedding Similarity (King vs. Emperor)
Word Embedding Similarity - Shows similar words have similar embeddings.


Attribute-Based Vector Representation and Analogies (King - Man + Woman ≈ Queen
Analogy Solving - Arithmetic on embeddings reflects real-world analogies.

Contextual Meaning ("NASA launched ____ last month")
Contextual Meaning - Words gain meaning from context.


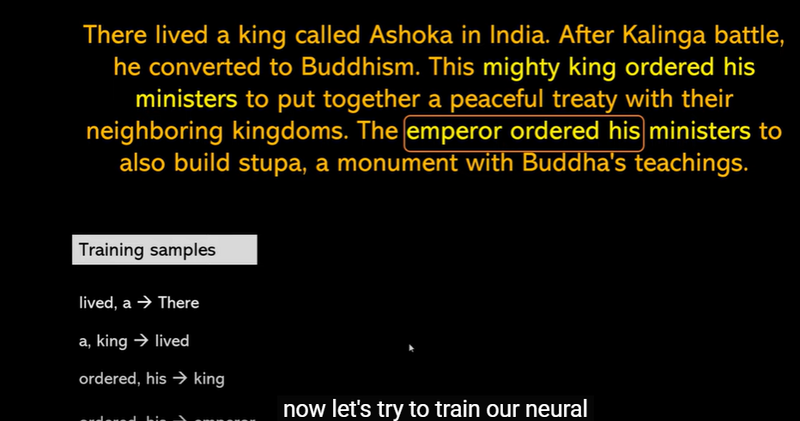
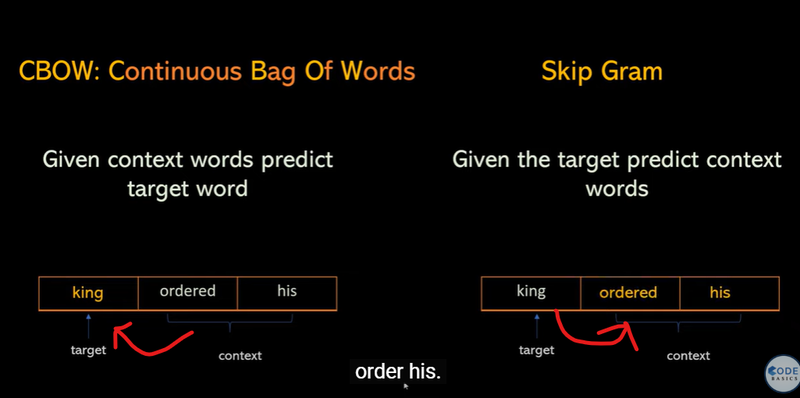
Training Examples for Word Embeddings (Context Pairs)
Training Samples for Word Embeddings - Context-target pairs help models learn word relationships.

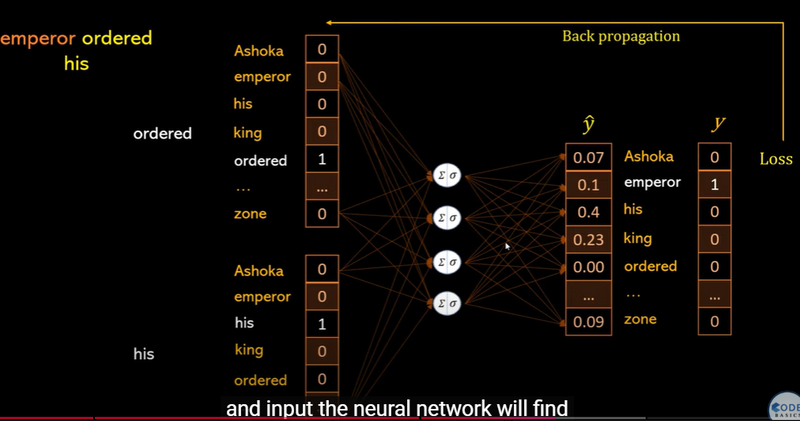
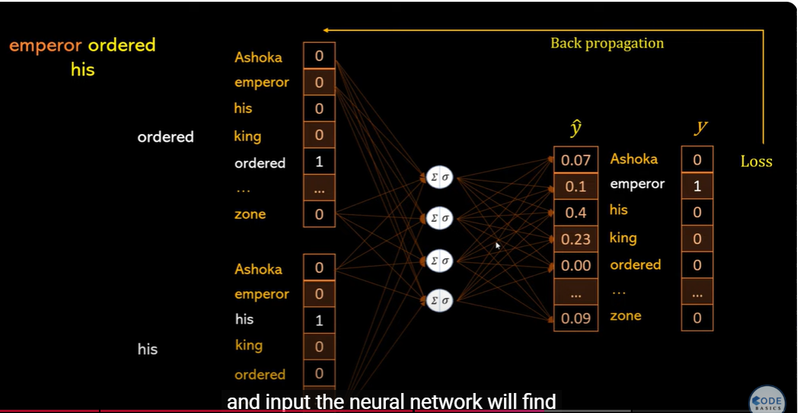
Neural Network Backpropagation in Word Embedding Training
Backpropagation in Embedding Training - Model adjusts embeddings based on error.

CBOW and Skip-Gram Models for Word Embeddings
CBOW and Skip-Gram - Two techniques for learning embeddings.

Analogy Examples in Vector Space
Analogy in Vector Space - Visual demonstration of embeddings capturing analogies.


Why word2vector is popular than word embedding using keras ohe








Coding example of word2vec
Preprocess Text (simple_preprocess)
review_text = df.reviewText.apply(gensim.utils.simple_preprocess)
- This line preprocesses the text from the reviewText column in the df DataFrame, converting each review into a list of lowercased words with only alphabetic characters.
- The simple_preprocess function tokenizes text and removes punctuation, preparing the data for Word2Vec .
preprocessing helps in identifying context words for target words. Preprocessing ensures that only relevant words (like “rocket” instead of “NASA launched, rocket!”) are included.

Initialize Word2Vec Model
model = gensim.models.Word2Vec(
window=10,
min_count=2,
workers=4,
)
This initializes the Word2Vec model with specific parameters:
window=10: The context window size, meaning the model considers up to 10 words on either side of a target word.
min_count=2: Words that appear less than twice are ignored, filtering out rare words.
workers=4: Specifies the number of CPU cores to use for training.
Word2Vec can be trained with either CBOW or Skip-Gram. By default, Gensim's Word2Vec uses Skip-Gram, which learns to predict context words from the target word. This mirrors the Skip-Gram approach in the image, where given "king" as the target, the model predicts nearby context words like "ordered" and "his."
Build Vocabulary
model.build_vocab(review_text, progress_per=1000)
- This line builds the vocabulary from the review_text dataset, setting up the words that will be included in the model.
- progress_per=1000 displays progress updates for every 1000 processed reviews
vocabulary building is similar to the creation of context-target pairs for training. It ensures that the model "knows" the words it will process and the relationships it will learn between them.
.Train the Word2Vec Model
model.train(review_text, total_examples=model.corpus_count, epochs=model.epochs)
- This trains the Word2Vec model on the review_text data.
- total_examples=model.corpus_count specifies the number of sentences (or documents), while epochs=model.epochs sets the number of times the model will go through the entire dataset .
Save the Trained Model
model.save("./word2vec-amazon-cell-accessories-reviews-short.model")
Saving the model preserves the learned embeddings, allowing us to use them for semantic analysis later, similar to how Image 8 shows embeddings being used to draw relationships, like "King - Man + Woman ≈ Queen.
This saves the trained model so it can be loaded and used later without retraining.
Find Most Similar Words
model.wv.most_similar("bad")
- This line retrieves words that are most similar to "bad" based on their vector representations in the embedding space.
- The model uses cosine similarity to find words that appear in similar contexts as "bad," which might include words like "poor," "awful," or "terrible ."
Similar words, like "king" and "emperor," share similar embeddings because they appear in similar contexts. Likewise, "bad" will have similar words that capture the same sentiment or meaning.

Calculate Similarity between Words
model.wv.similarity(w1="cheap", w2="inexpensive")
This calculates the cosine similarity between the words "cheap" and "inexpensive." A high similarity score indicates that these words are used in similar contexts and have similar meanings.
Relation to Images:
Just as relationships like "king" and "queen" can be observed, "cheap" and "inexpensive" should be close to each other in the vector space. Their similarity score reflects that they are semantically related.
list of genism commands
Setup: Loading the Dataset and Preparing Word2Vec Model
import gensim
from gensim.models import Word2Vec
import pandas as pd
# Sample dataset of Amazon reviews (assuming 'df' is your DataFrame)
df = pd.DataFrame({
'reviewText': [
"This product is great and easy to use",
"Bad quality, not worth the price",
"Amazing product with excellent features",
"Cheap and affordable, but breaks easily",
"Very happy with the purchase, good value",
]
})
# Preprocess text data
review_text = df['reviewText'].apply(gensim.utils.simple_preprocess)
# Initialize Word2Vec model
model = Word2Vec(
vector_size=100,
window=5,
min_count=1,
workers=4,
)
model.build_vocab(review_text)
model.train(review_text, total_examples=model.corpus_count, epochs=model.epochs)
- Train Word2Vec Model Train the Word2Vec model on a tokenized dataset.
model.train(review_text, total_examples=model.corpus_count, epochs=model.epochs)
Output: Model trains, and updates embeddings based on the dataset.
- Save Model Save the trained model to a file for later use.
model.save("word2vec-amazon-reviews.model")
Output: Model saved as word2vec-amazon-reviews.model.
- Load Saved Model Load a saved Word2Vec model from a file.
model = Word2Vec.load("word2vec-amazon-reviews.model")
Output: Loads the Word2Vec model from file.
- Get Vector for a Word Retrieve the embedding (vector) for a given word.
vector = model.wv['great']
print(vector)
Output: A 100-dimensional vector representing the word "great."
- Find Most Similar Words Find words most similar to a given word.
similar_words = model.wv.most_similar("great", topn=3)
print(similar_words)
Output: Top 3 words similar to "great" along with similarity scores.
- Check Similarity Between Two Words Check cosine similarity between two words.
similarity = model.wv.similarity("cheap", "affordable")
print(similarity)
Output: Cosine similarity score between "cheap" and "affordable."
- Find Odd Word Out Find the word that doesn't belong in a list.
odd_word = model.wv.doesnt_match(["cheap", "affordable", "great", "pricey"])
print(odd_word)
Output: The word that doesn't match others, like "pricey."
- Analogy Completion Solve analogies like "man is to king as woman is to ____."
result = model.wv.most_similar(positive=['great', 'value'], negative=['bad'], topn=1)
print(result)
Output: Word closest to "great" + "value" - "bad."
- Vocabulary Size Check the number of words in the vocabulary.
vocab_size = len(model.wv)
print(vocab_size)
Output: Number of unique words in the vocabulary.
- Words in Vocabulary Get a list of all words in the vocabulary.
vocab_words = list(model.wv.index_to_key)
print(vocab_words)
Output: List of all words in the vocabulary.
- Word Frequency Check the frequency of a word in the corpus.
frequency = model.wv.get_vecattr("product", "count")
print(frequency)
Output: Frequency count of the word "product."
- Update Model Vocabulary Update the model’s vocabulary with new words from additional data.
additional_data = [["great", "value", "for", "price"]]
model.build_vocab(additional_data, update=True)
model.train(additional_data, total_examples=model.corpus_count, epochs=model.epochs)
Output: Model updates with the new vocabulary.
- Get All Vectors Retrieve all word vectors in the model.
all_vectors = model.wv.vectors
print(all_vectors.shape)
Output: Shape of the array containing all word vectors.
- Normalize Word Vectors Normalize vectors to unit length (helpful for similarity computations).
model.init_sims(replace=True)
Output: Model’s word vectors normalized.
- KeyedVectors Conversion Convert Word2Vec model to KeyedVectors (faster and lighter for similarity checks).
keyed_vectors = model.wv
Output: keyed_vectors now contains only word vectors and similarity functions.
- Get Words by Similarity to Vector Get words similar to a given vector (not a specific word).
import numpy as np
random_vector = np.random.rand(100)
similar_to_vector = model.wv.similar_by_vector(random_vector, topn=3)
print(similar_to_vector)
Output
: Top 3 words similar to the given vector.
- Distance Between Words Get the cosine distance between two words.
distance = model.wv.distance("cheap", "affordable")
print(distance)
Output: Cosine distance between "cheap" and "affordable."
- Save Model in KeyedVectors Format Save the model in KeyedVectors format (lightweight, no training functionality).
model.wv.save("word2vec-keyedvectors.kv")
Output
: KeyedVectors model saved as word2vec-keyedvectors.kv.
- Load KeyedVectors Load the model saved in KeyedVectors format.
keyed_vectors = gensim.models.KeyedVectors.load("word2vec-keyedvectors.kv")
Output: Loads KeyedVectors format model, optimized for similarity and lookup.
- Check if Word Exists in Vocabulary Check if a specific word exists in the model’s vocabulary.
word_exists = "great" in model.wv
print(word_exists)
Output: True if "great" is in the vocabulary, otherwise False.

Top comments (0)