What is Apache Spark
parallel processing on single computer using apache spark
parallel processing on Multiple computer using apache spark
Configuring SparkSession with Off-Heap Memory in PySpark
What is Apache Spark
Local workstations (computer) have their limitations and cannot handle extremely large datasets using languages like R and Python.This is where a distributed processing system like Apache Spark comes in. Distributed processing is a setup in which multiple processors are used to run an application. Instead of trying to process large datasets on a single computer
Apache Spark is a distributed processing system used to perform big data and machine learning tasks on large datasets. With Apache Spark, users can run queries and machine learning workflows on petabytes of data, which is impossible to do on your local device.
This framework is even faster than previous data processing engines like Hadoop, and has increased in popularity in the past eight years. Companies like IBM, Amazon, and Yahoo are using Apache Spark as their computational framework.
parallel processing on single computer using apache spark
On a Single Computer:
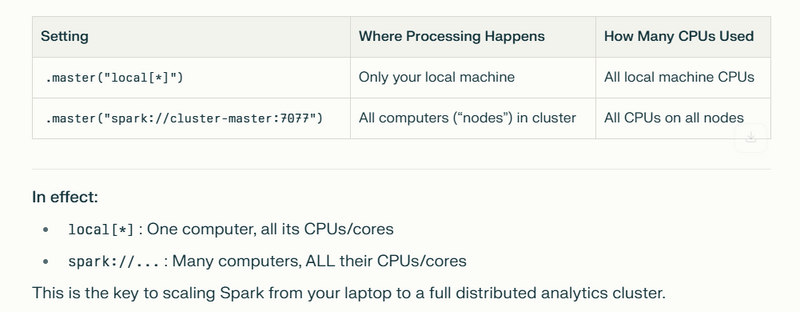
.master("local[*]") uses all CPU cores for parallel execution.
This tells Spark to run on your own machine.
The * means, “Use all CPU cores (processors) available on this computer.”
Example: If your laptop has 8 cores, Spark will split the work into 8 chunks and run them all in parallel—on your laptop only.
No network or distributed computing: All the parallel tasks stay on your single computer.
- On a Cluster:
.master("spark://cluster-master:7077") uses CPUs from multiple nodes.
This tells Spark to connect to a cluster (a group of networked computers/servers).
The spark://... URL points Spark to a master node that coordinates the cluster.
Now, Spark splits work across all connected computers (“nodes”)—not just yours.
Each node uses all its own CPUs in parallel (like before), but now many computers execute in parallel.
Data and jobs are distributed by the Spark cluster software.
This setup allows you to process very large datasets and workloads, much bigger than what fits on one computer.

How Distributed Systems Like Spark Work
Core Concepts:
Cluster: A group of computers (“nodes” or “workers”) connected on a network.
Driver: Your application code, which coordinates jobs.
Workers: Machines that process slices (“partitions”) of your data.
Resilient Distributed Datasets (RDDs): Spark’s main data structure for distributed collections, supporting in-memory and fault-tolerant processing.
Workflow Example:
Data is loaded from distributed storage (like HDFS or S3) or your local filesystem.
The data is split (“partitioned”) across many nodes.
Operations (like map, filter, reduce, machine learning, etc.) are applied in parallel across the cluster.
Results are combined and delivered back to the user or written to storage.
Install (on cluster or local machine for testing):
pip install pyspark
Sample Spark code to process a huge CSV file:
from pyspark.sql import SparkSession
# Start a Spark session (local or connect to real cluster)
spark = SparkSession.builder \
.appName("Big Data Example") \
.master("local[*]") # Use real cluster URL in production
.getOrCreate()
# Load a huge CSV into a distributed DataFrame
df = spark.read.csv("hdfs:///bigdata/all_sales_2024.csv", header=True)
# Perform distributed operations
result = df.groupBy("region").sum("sales_amount")
# Write result, also distributed
result.write.csv("hdfs:///bigdata/results/regional_sales.csv")
spark.stop()
Here, you don’t need to worry if the file is 10GB, 100GB, or 1TB—Spark automatically parallelizes all steps.
Visual: How This Scales
Imagine a 1TB dataset that would crash your laptop.
Spark splits it into e.g., 1000 partitions, each one processed by a separate executor.
You get results much faster—and if one node fails, Spark automatically tries again (fault tolerance).
Where multiple processors come in:
Spark splits the CSV file into partitions
Example: a 1 TB dataset might be split into 1000 partitions of 1 GB each.
Partitions are distributed to executors
Executors are processes running on different CPUs across the cluster.
All partitions are processed in parallel
Each processor runs the same instructions (groupBy(...) and sum(...)) on its partition of data.
Spark shuffles and combines the intermediate results
Aggregated per-region totals from each processor are merged into final results.
On a single computer, .master("local[*]") uses all CPU cores for parallel execution.
On a cluster, .master("spark://cluster-master:7077") uses CPUs from multiple nodes.
┌──────────────────────────────┐
│ Your Application Code │
│ (PySpark, R, Dask, etc.) │
└──────────────┬───────────────┘
│
┌───────────────────────┴─────────────────────────┐
│ Cluster Resource Manager │
│ (Spark Driver / Dask Scheduler / YARN) │
└────────────┬────────────┬────────────┬───────────┘
│ │ │
┌────────▼──────┐ ┌───▼────────┐ ┌─▼──────────┐
│ Worker Node 1 │ │ Worker 2 │ │ Worker 3 │
│ CPU cores │ │ CPU cores │ │ CPU cores │
└───────────────┘ └────────────┘ └────────────┘
▲ ▲ ▲
Partition 1 Partition 2 Partition 3 ... N
parallel processing on Multiple computer using apache spark
If you want to process big data across multiple computers, each using their own CPUs with Apache Spark, you need to set up a Spark cluster and write code that connects to that cluster, not just local CPUs. Here’s how to do it step by step:
Set Up a Spark Cluster
Suppose you have several computers (nodes):
One is the Spark Master
Others are Spark Workers
Each worker can use all its CPU cores.
Install Spark (and Java) on every node:
# On every machine:
sudo apt-get update
sudo apt-get install default-jdk scala git -y
wget https://archive.apache.org/dist/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgz
tar -xzf spark-3.5.1-bin-hadoop3.tgz
export SPARK_HOME=~/spark-3.5.1-bin-hadoop3
export PATH=$PATH:$SPARK_HOME/bin
Start the Spark Master (choose one node):
$SPARK_HOME/sbin/start-master.sh
You’ll see:
starting org.apache.spark.deploy.master.Master, logging to ...
Master URL will look like:
spark://master_hostname_or_ip:7077
Start Workers on each worker node and point them to the master:
$SPARK_HOME/sbin/start-slave.sh spark://master_hostname_or_ip:7077
Spark Code Example for a Cluster
When you write code, you connect to the cluster via its master URL. For example:
from pyspark.sql import SparkSession
# Connect to cluster, not local!
spark = SparkSession.builder \
.appName("Distributed Cluster Example") \
.master("spark://master_hostname_or_ip:7077") \
.getOrCreate()
# Now your data and jobs are split across all cluster computers and CPUs!
df = spark.read.csv("hdfs:///big/huge_dataset.csv", header=True)
result = df.groupBy("region").sum("sales_amount")
result.write.csv("hdfs:///big/regional_sales_summary.csv")
spark.stop()
Replace master_hostname_or_ip with the actual hostname or IP address of your Spark master node.
Cluster workers automatically process distributed data partitions using all CPUs on all servers.
How It Works
Master node assigns work to worker nodes in the cluster.
Each worker processes part of the data in parallel, using its own CPUs.
Even enormous data is split and processed much faster than any single workstation.
Configuring SparkSession with Off-Heap Memory in PySpark
from pyspark.sql import SparkSession
Imports the SparkSession class:
This is the entry point for working with DataFrames and the most common way to start using Spark from Python. It lets you create and configure a Spark application (the gateway to using Spark).
spark = SparkSession.builder \
.appName("Datacamp Pyspark Tutorial") \
.config("spark.memory.offHeap.enabled","true") \
.config("spark.memory.offHeap.size","10g") \
.getOrCreate()
Let’s break this down step by step:
SparkSession.builder
Starts building a new Spark session object.
.appName("Datacamp Pyspark Tutorial")
Names your Spark application (useful for tracking jobs in Spark’s dashboard/logs or on a cluster).
.config("spark.memory.offHeap.enabled","true")
Tells Spark to use off-heap memory (memory not managed by the JVM garbage collector, but allocated directly from the OS).
Off-heap memory can help in situations where garbage collection overhead or memory fragmentation is hurting performance, or when you want Spark to use more memory than heap allows.
.config("spark.memory.offHeap.size","10g")
Allocates 10 gigabytes of off-heap memory for Spark to use.
This is the maximum amount of off-heap memory Spark will attempt to use.
.getOrCreate()
Actually creates the Spark session (if it doesn’t exist) or returns the existing one.
Makes the session available via the variable spark.
What does this enable you to do?
With spark, you can now load and process data in a distributed way, whether on your local machine or across a cluster if configured.
The off-heap configuration lets Spark use extra memory more efficiently, which can help with large datasets and heavy computations.

Top comments (0)