Why is RAG Important for AI Agents?
How to Retrieve Useful Information Sources
How to Add Information to AI's Knowledge (Augment)
How to Generate Better Responses
Step-by-Step Process of Building an AI Agent Using RAG
Real-World Example
Advantages of Using RAG in AI Agents
RAG (Retrieval-Augmented Generation) is a method that combines retrieval-based approaches (searching external data sources) with generation-based models (e.g., large language models) to create more powerful and accurate AI systems
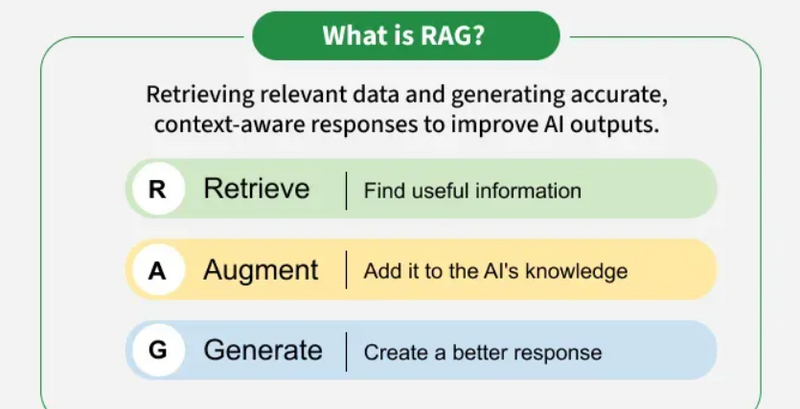
How to Retrieve Useful Information Sources
Useful information for AI agents can come from a variety of sources depending on your application:
Web Search APIs: Pull real-time information (e.g., Bing, Google Custom Search).
Databases: Structured data (e.g., SQL, NoSQL, vector stores like Pinecone).
Document Repositories: PDFs, docs, or datasets (via file retrieval or OCR).
Internal Tool Integrations: APIs for calendars, emails, proprietary databases.
Enterprise Knowledge Bases: Wikis, Confluence, SharePoint, CRM systems.
Public Datasets: Kaggle, UCI Machine Learning Repository, GitHub.
# Web Search retrieval using SerpAPI (as an example)
from serpapi import GoogleSearch
params = {
"q": "latest advancement in AI",
"api_key": "YOUR_SERPAPI_KEY"
}
search = GoogleSearch(params)
results = search.get_dict()
print(results['organic_results'][0]['snippet'])
# Document retrieval with FAISS (vector store)
import faiss
import numpy as np
# Assume you have document embeddings and a query embedding
index = faiss.IndexFlatL2(768)
index.add(doc_embeddings) # doc_embeddings is a numpy array
D, I = index.search(query_embedding, k=5) # k nearest docs
How to Add Information to AI's Knowledge (Augment)
Methods to Augment:
Pass Retrieved Context to LLM: Provide retrieved snippets as context/"prompt engineering."
Fine-Tuning: Train model with new data (mainly used in deep learning).
Vector Stores for Retrieval-Augmented Generation: Store docs as embeddings for semantic search.
In-Memory Short-Term/Long-Term Storage: Store as a stack/list or in key-value stores.
# Augment response: pass retrieved docs to prompt for OpenAI GPT
import openai
retrieved_evidence = "OpenAI introduced GPT-4 Turbo, which is faster and cheaper."
prompt = f"Using the following information:\n{retrieved_evidence}\n\nExplain the latest advancements in AI technology."
response = openai.ChatCompletion.create(
model="gpt-4-turbo",
messages=[{"role": "user", "content": prompt}]
)
print(response['choices'][0]['message']['content'])
OTHER EXAMPLES Add Information to AI's Knowledge (Augment)
Augmenting with Prompt Context (Direct Prompt Injection)
Pass the retrieved or supplementary text directly into the prompt before the LLM answers.
retrieved_info = "ACME Corp was founded in 1995 and specializes in AI solutions."
prompt = f"Using the following background info:\n{retrieved_info}\n\nWhat's ACME Corp's area of expertise?"
import openai
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
answer = response['choices'][0]['message']['content']
print(answer)
Explanation: You add new knowledge directly in the prompt—no model retraining required. This ensures the model references up-to-date or contextually relevant info.
Vector Store Embedding Retrieval
Store documents as embeddings, retrieve them at runtime, and add their text to the LLM's input.
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
docs = ["Doc about cloud security.", "Doc about AI ethics."]
doc_embeddings = model.encode(docs)
# Save embeddings in FAISS
index = faiss.IndexFlatL2(doc_embeddings.shape[1])
index.add(np.array(doc_embeddings))
# At query time
query = "Tell me about AI and responsibility."
query_embedding = model.encode([query])
_, indices = index.search(np.array(query_embedding), k=2)
context = " ".join([docs[i] for i in indices[0]])
augmented_prompt = f"Context:\n{context}\n\nQ: {query}\nA:"
Explanation: You use semantic search to find the most relevant documents, then feed their content as context to the AI model.
API-Based Live Knowledge Injection
Query a live API and inject its output as context at inference time, for always-fresh answers.
import requests
weather_data = requests.get("http://api.weatherapi.com/v1/current.json", params={
"key": "YOUR_API_KEY",
"q": "New York"
}).json()
weather_context = f"Current weather in New York: {weather_data['current']['temp_c']}°C, {weather_data['current']['condition']['text']}."
prompt = f"{weather_context}\n\nWill it rain today in New York?"
# Pass this prompt to your LLM of choice
Explanation: Real-time data is fetched via API and provided inline in the prompt for accurate, up-to-date responses.
Knowledge Graph Augmentation
Extract facts or entities from a knowledge graph and add them into LLM context.
from rdflib import Graph
g = Graph()
g.parse("company_ontology.rdf")
q = "SELECT ?field WHERE { ?company <hasName> 'ACME Corp' . ?company <specializesIn> ?field . }"
results = g.query(q)
field = [row[0] for row in results]
prompt = f"ACME Corp specializes in {', '.join(field)}. Could you explain what this means in plain terms?"
Explanation: Structured knowledge (from RDF or similar sources) is queried and then passed into the AI's prompt as natural language.
sparql-queries
Tool-Calling or Function Augmentation Pattern
Let the LLM decide to "call a tool" (function), retrieve the resulting data, and then return a richer, grounded answer.
def get_stock_price(symbol):
# Pretend API call
return "274.50 USD"
query = "What's the current stock price of AAPL?"
if "stock price" in query:
stock_info = get_stock_price("AAPL")
prompt = f"{query}\n\nAAPL stock price is {stock_info}."
else:
prompt = query
# Feed prompt to LLM for a grounded response
Explanation: The system detects when external data is needed, fetches it on the fly, then passes it as context so the LLM can ground its answer in new info.
These approaches illustrate how to add, augment, or ground new information in an LLM’s workflow—without full model retraining. Depending on the use case, you can combine these techniques for robust, real-world-ready AI system
How to Generate Better Responses
How Generation Works:
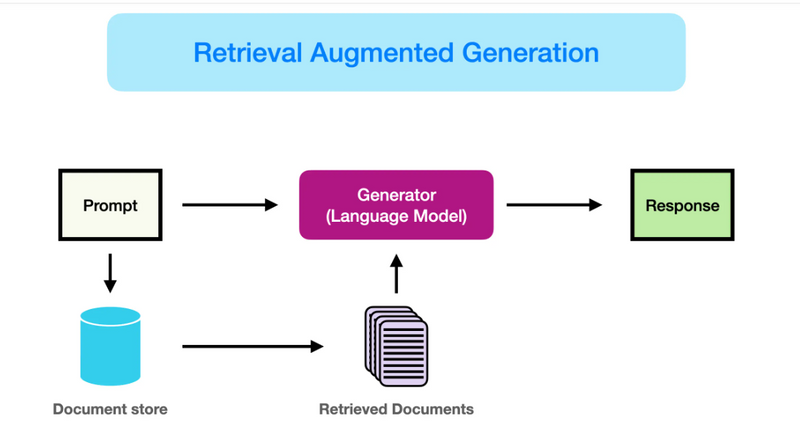
The AI takes the user’s query plus the retrieved/augmented context, and generates an answer using a language model.
Modern frameworks automatically build prompts that combine the two before generation.
Python Example with LangChain (RAG pipeline):
from langchain.chains import RetrievalQA
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.llms import OpenAI
# Suppose you already have a FAISS index and retriever set up:
retriever = vectorstore.as_retriever()
# Build a question-answering chain – retrieves context, then generates
qa = RetrievalQA.from_chain_type(
llm=OpenAI(),
chain_type="stuff",
retriever=retriever
)
query = "What are the benefits of RAG in AI?"
answer = qa.run(query)
print(answer)
Explanation:
faiss (or another vector store) retrieves relevant passages.
The retrieved context is supplied with the user's question to the Language Model.
The Language Model generates a context-aware, improved answer.
For vector stores, you continually add new documents and their embeddings for up-to-date retrieval.
----------------SOME MORE EXAMPLES-------------------------
Chain-of-Thought Prompting
Have the AI model generate its answer step by step, simulating human reasoning for more accurate and detailed responses.
import openai
prompt = (
"Let's solve this math problem step by step. "
"Question: If a train travels at 60 km/h for 3 hours, how far does it go?\n"
"First, find speed and time. Then multiply to get the distance."
)
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
print(response['choices'][0]['message']['content'])
Explanation: Instructing the model to explain its thinking process stepwise (chain-of-thought) increases reasoning quality and transparency.
Few-Shot Learning with Examples
Provide the AI with several input/output samples to help establish the desired response format and logic.
prompt = (
"Q: Capital of France?\nA: Paris\n"
"Q: Capital of Italy?\nA: Rome\n"
"Q: Capital of Spain?\nA:"
)
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
print(response['choices'][0]['message']['content'])
Explanation: Including clear Q&A pairs makes it easier for the AI to infer the right structure and type of output for new questions.
Role and Instruction Prompting
Tell the AI to "act as" a role for tone and expert-level answers.
prompt = (
"Act as a Python coding instructor. "
"Explain how to use list comprehensions with an example."
)
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
print(response['choices'][0]['message']['content'])
Explanation: Assigning a specific role (doctor, teacher, journalist, etc.) aligns responses more closely with user intent and context.
Specify Output Format with Directives
Explicitly ask for a desired output format like JSON, table, or code, so the response is ready for downstream use.
prompt = (
"List three major programming languages and their main uses. "
"Present the output as a markdown table with columns Language and Usage."
)
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
print(response['choices'][0]['message']['content'])
Explanation: Telling the AI exactly how you want information presented ensures response usability and minimizes post-processing.
Self-Evaluation and Critique
Prompt the AI to review and improve its initial answer by providing feedback to itself.
prompt = (
"You are an AI assistant. "
"First, answer: What are the benefits of using renewable energy? "
"Then, critique your answer for accuracy and completeness. "
"Finally, revise your answer based on your critique."
)
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
print(response['choices'][0]['message']['content'])
Why is RAG Important for AI Agents?
Enhanced Performance: RAG allows AI agents to retrieve relevant information from large datasets (such as documents, databases, or the web) and use it as a context for generating responses. This combination improves the agent's ability to answer more specific or nuanced queries.
Reduced Hallucinations: Traditional generative models (like GPT-3) sometimes produce inaccurate or fabricated information (called hallucinations). By integrating a retrieval step, RAG can ensure that the generated responses are based on real, factual data.
Scalability: Instead of embedding the entire knowledge in a language model, which is computationally expensive, RAG allows the agent to use external knowledge sources dynamically, improving the efficiency and scalability of the system.
Step-by-Step Process of Building an AI Agent Using RAG
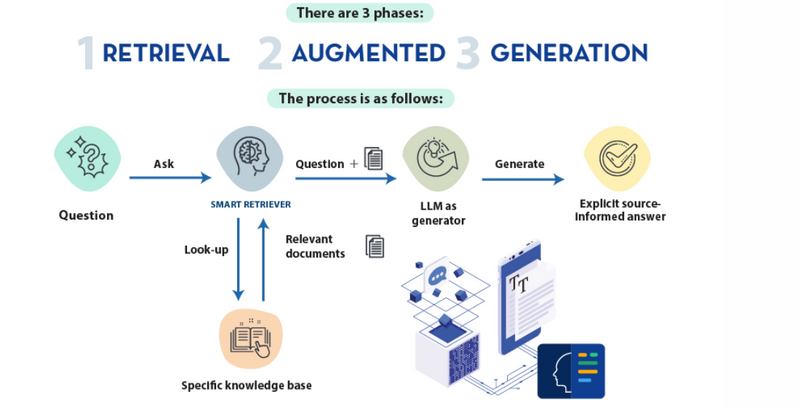
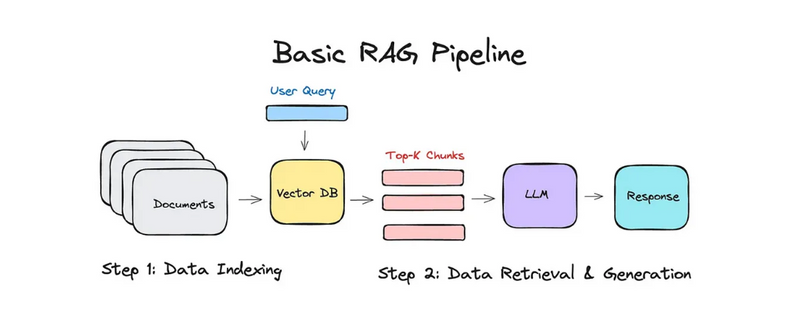
Step 1: Define the Task for the AI Agent
Task: The AI agent needs to generate contextually relevant answers to user queries using external knowledge.
Example: Suppose we want an AI agent to help users with technical support for a software product by answering questions about specific issues or errors.
Step 2: Set Up a Retrieval System
To implement RAG, we first need a retrieval system to fetch relevant information. This could be:
A search engine (e.g., Elasticsearch, FAISS, or other vector databases).
A document store that stores structured or unstructured data (e.g., PDFs, knowledge base articles, or FAQs).
For example, we can store all knowledge about the software in a vector database that allows efficient similarity search.
Step 3: Integrate with a Generative Model
Once the relevant data is retrieved, we pass it to a generative model (like GPT-3 or T5) to generate a response that uses the retrieved information.
GPT-3, for instance, will generate an answer based on both the query and the retrieved documents or data.
This process helps the agent provide more accurate and contextually rich answers.
Step 4: Combine the Retrieval and Generation (RAG Process)
In a RAG setup, the agent will:
Receive a query from the user.
Retrieve the most relevant documents or data based on the query using a retrieval method.
Generate a response by passing both the query and the retrieved information to a generative model.
The overall architecture of a RAG-based AI Agent can be visualized as follows:
+-----------------+ +------------------------+
| User Query | | Retrieval System |
| (e.g. "How to | ----> | (e.g. Elasticsearch, |
| fix error X?")| | FAISS, or Vector DB) |
+-----------------+ +------------------------+
| |
v v
+----------------+ +----------------------+
| Query | | Relevant Documents |
| Encoding | ----> | (retrieved from DB) |
+----------------+ +----------------------+
| |
v v
+-------------------------+ +----------------------------+
| Generative Model (e.g. | <----> | Model + Retrieved Data |
| GPT-3, T5) | | (generate context-aware |
+-------------------------+ | answer using retrieved |
| data and query) |
+----------------------------+
|
v
+-----------------------+
| Final Answer to User |
+-----------------------+
Step 5: Integrate with Langchain for Building a RAG-based AI Agent
Langchain is a framework that simplifies building applications using LLMs (like GPT-3) with integration to external tools and data sources, such as retrieval systems.
Let’s walk through how to build an AI agent using Langchain and RAG.
Langchain Setup for RAG
Install Langchain:
pip install langchain
pip install openai
Set Up OpenAI API (or another LLM provider):
import openai
from langchain.llms import OpenAI
openai.api_key = 'your-openai-api-key'
llm = OpenAI(temperature=0.7) # Create the generative LLM
Set Up the Retrieval System (using FAISS for simplicity):
pip install faiss-cpu
Create the Retrieval System: For the example, let’s use FAISS as the vector store.
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.chains import RetrievalQA
# Example: Using FAISS for document retrieval
embeddings = OpenAIEmbeddings() # Using OpenAI embeddings for document encoding
# Assume `docs` is a list of your knowledge base documents
# Initialize the FAISS index
faiss_index = FAISS.from_documents(docs, embeddings)
# Create the retrieval system
qa_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=faiss_index.as_retriever())
Generate the Response Using RAG:
query = "How to fix error X?"
response = qa_chain.run(query)
print(response)
Langchain Code Explanation:
Embeddings: We use OpenAIEmbeddings to encode documents into vectors that can be stored in a vector database like FAISS.
FAISS: The vector store is built using FAISS, which allows fast similarity search in large datasets.
RetrievalQA: RetrievalQA chain is a Langchain chain that retrieves the most relevant documents and uses the generative model (e.g., GPT-3) to generate an answer based on both the query and the retrieved context.
Generate Response: We send the query to the RAG system, which retrieves documents and generates a response.
Real-World Example
Imagine an AI agent built for customer support in a SaaS company. The agent’s task is to answer users' questions based on a knowledge base of documents (FAQs, manuals, etc.) stored in a database.
User asks a question: "How do I reset my password?"
Retrieval step: The system retrieves the most relevant documents (e.g., "Password reset guide").
Generation step: The generative model, using the retrieved documents, formulates an accurate and detailed response for the user.
This allows the AI agent to:
Retrieve the most relevant information in real-time.
Use this data to generate a contextual response.
Advantages of Using RAG in AI Agents
Increased Accuracy: By leveraging a retrieval system (such as FAISS or Elasticsearch), the agent can base its response on real, factual data instead of relying solely on a generative model that may hallucinate information.
Dynamic Knowledge: RAG allows the AI agent to pull in information from external sources in real-time, ensuring the answers are up-to-date.
Efficiency: Instead of embedding all knowledge into a model, which can be computationally expensive, RAG uses external knowledge sources, making the system scalable and efficient.
Summary
RAG combines retrieval (searching data) with generation (creating responses) to improve the performance of AI agents.
It is useful in scenarios where an AI agent needs to answer complex or factual questions using large external datasets.
Langchain simplifies building RAG systems by providing easy integrations with LLMs and retrieval systems like FAISS.
The architecture allows the AI agent to retrieve relevant data, pass it to a generative model, and provide the user with accurate, context-aware answers.
what-is-retrieval-augmented-generation-rag
rag
building-a-rag-system-with-gpt-4-a-step-by-step-guide

Top comments (0)