What is it?
What it actually does
Real-time example (Structured Streaming with Kafka)
Quick mental picture
Connecting to the cluster manager (Standalone, YARN, Mesos, Kubernetes)
How to run spark
10 unique examples of how you can connect to a Cluster Manager using SparkSession in PySpark
Setting Number of Executors (and other resources)
connect to a Cluster Manager using SparkSession in PySpark in ML field
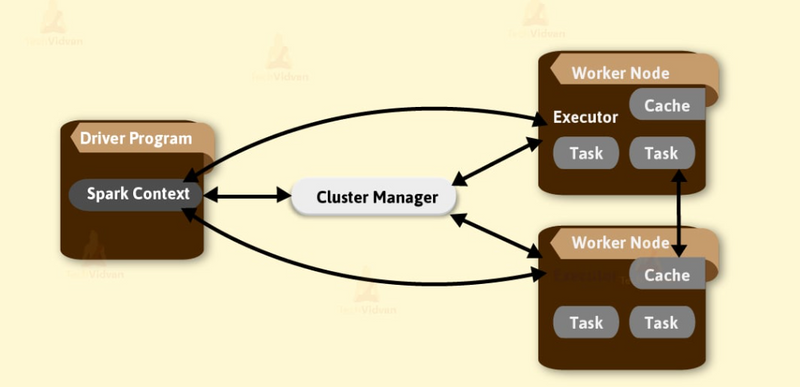
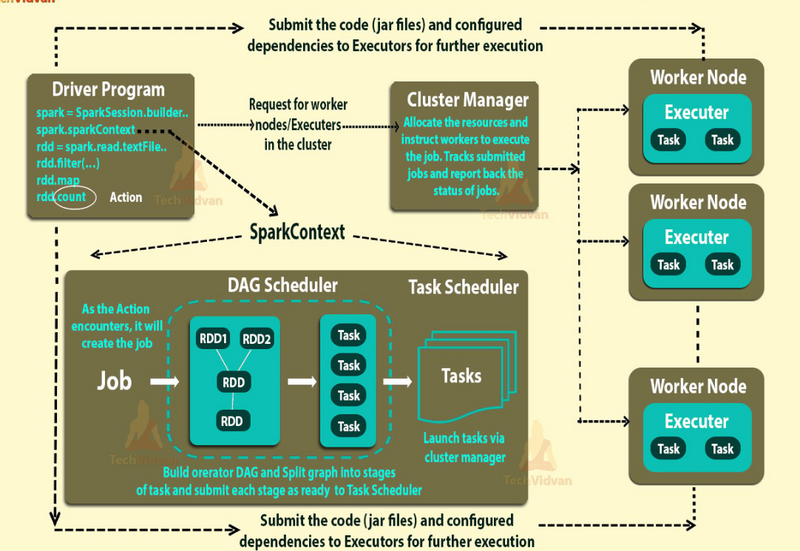
Cluster manager is a platform (cluster mode) where we can run Spark. Simply put, cluster manager provides resources to all worker nodes as per need, it operates all nodes accordingly.
We can say there are a master node and worker nodes available in a cluster. That master nodes provide an efficient working environment to worker nodes.
There are three types of Spark cluster manager. Spark supports these cluster manager:
Standalone cluster manager
Hadoop Yarn
Apache Mesos
Apache Spark also supports pluggable cluster management. The main task of cluster manager is to provide resources to all applications. We can say it is an external service for acquiring required resources on the cluster.
What is it?
Think of the cluster manager as the traffic controller + receptionist for your Spark jobs. It doesn’t do the data work itself—it finds machines, gives Spark the CPUs/RAM it needs, starts/stops worker processes, and keeps them healthy.
What it actually does
Finds resources: “You need 50 CPU cores and 100 GB RAM? I’ll reserve those on these machines.”
Starts executors: Launches the Spark executors (the workers that run your tasks).
Schedules & monitors: Keeps track of which tasks are running where, restarts them if a machine dies.
Scales up/down: Can add or remove executors (dynamic allocation) based on load.
Shares the cluster: Enforces queues/quotas so multiple teams can run jobs without stepping on each other.
(Under the hood, Spark can use different cluster managers: Standalone, YARN, Kubernetes, or Mesos. Same idea, different environments.)
Real-time example (Structured Streaming with Kafka)
Imagine a fraud-detection pipeline:
Driver program starts your streaming query (read from Kafka, window and aggregate, write alerts to a database).
The cluster manager (say, Kubernetes) receives the request and allocates pods/nodes with enough CPU/RAM.
It launches executors across those nodes; Spark sends mini-batches/micro-tasks to them.
If traffic spikes (more transactions), the cluster manager adds more executors so you keep low latency.
If a node crashes, it restarts the lost executors elsewhere and Spark retries the failed tasks—your stream keeps running.
At night when traffic drops, it scales down to save resources.
Quick mental picture
Driver app → asks Cluster Manager → gets Executors → Executors process your data.
Connecting to the cluster manager (Standalone, YARN, Mesos, Kubernetes)
That’s it: the cluster manager’s job is to make sure the right amount of muscle is available and kept alive so your Spark job—batch or real-time—runs smoothly.
Spark needs a cluster manager to acquire resources (executors/cores/memory). You choose it via --master (or in code with .master(...) for local testing).
How to do it
Standalone: Spark’s built-in manager
YARN: Hadoop clusters
Kubernetes: Containerized clusters
Mesos: (legacy, rarely used today)
Commands (spark-submit)
# Standalone cluster (replace host:port with your master URL)
spark-submit \
--master spark://spark-master:7077 \
--deploy-mode client \
--conf spark.executor.instances=4 \
app.py
# YARN (cluster mode)
spark-submit \
--master yarn \
--deploy-mode cluster \
--conf spark.executor.instances=4 \
--conf spark.executor.memory=4g \
app.py
# Kubernetes (example)
spark-submit \
--master k8s://https://my-k8s-apiserver:6443 \
--deploy-mode cluster \
--name my-spark-app \
--conf spark.kubernetes.container.image=myrepo/spark-py:latest \
--conf spark.executor.instances=4 \
--conf spark.kubernetes.namespace=data \
local:///opt/spark/app.py
# Mesos (legacy example)
spark-submit \
--master mesos://zk://mesos-zk:2181/mesos \
--deploy-mode client \
app.py
Local/dev (code)
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("ConnectDemo")
.master("local[4]") # local dev only
.getOrCreate())
EXPLANATION
Why “connecting to a cluster manager” matters
Spark needs a cluster manager to allocate resources (executors/cores/memory). You pick the manager with --master when you submit your job (or .master("local[...]") for laptop dev). The driver (your app) talks to the cluster manager, which launches executors that actually run your tasks.
Standalone (Spark’s built-in manager)
Command (annotated)
spark-submit \
--master spark://spark-master:7077 \ # URL of the Standalone "Master" node
--deploy-mode client \ # driver runs on your submitting machine
--conf spark.executor.instances=4 \ # request 4 executor JVMs
app.py
# your application file
What each piece does
--master spark://spark-master:7077: tells Spark where the Standalone Master lives.
--deploy-mode client: the driver runs where you launch spark-submit (logs print in your terminal).
(Tip: use cluster if you want the driver to run on a worker node.)
spark.executor.instances=4: asks the manager for 4 executors (parallel workers).
app.py: your PySpark program; the driver process executes it.
When to use: Non-Hadoop clusters where you installed Spark’s Standalone master/worker daemons.
YARN (Hadoop clusters)
Command (annotated)
spark-submit \
--master yarn \ # use Hadoop YARN as cluster manager
--deploy-mode cluster \ # driver runs inside YARN (on a node in the cluster)
--conf spark.executor.instances=4 \ # 4 executors
--conf spark.executor.memory=4g \ # memory per executor
app.py
What each piece does
--master yarn: integrate with Hadoop’s YARN RM.
--deploy-mode cluster: the driver runs in the cluster; logs go to YARN (check YARN UI).
spark.executor.instances, spark.executor.memory
: resource sizing knobs.
Prereqs: HADOOP_CONF_DIR/YARN_CONF_DIR visible to Spark so it can talk to YARN; HDFS access if reading from HDFS.
Kubernetes (K8s)
spark-submit \
--master k8s://https://my-k8s-apiserver:6443 \ # K8s API endpoint
--deploy-mode cluster \ # driver runs in a K8s pod
--name my-spark-app \ # K8s app (driver) name
--conf spark.kubernetes.container.image=myrepo/spark-py:latest \ # driver+executor image
--conf spark.executor.instances=4 \ # 4 executor pods
--conf spark.kubernetes.namespace=data \ # submit into this K8s namespace
local:///opt/spark/app.py
# path inside the container image
What each piece does
--master k8s://...: point Spark to your K8s API server.
--deploy-mode cluster: the driver is a pod; executors are pods.
spark.kubernetes.container.image: container image that already contains Spark and your code (or use --py-files to ship code).
local:///opt/spark/app.py: local:// means “file already present in the driver container at this path.”
(Use file:// for host paths, not recommended here; hdfs:///s3a:// for remote.)
Prereqs: image in a registry accessible by the cluster, correct service account/RBAC, and a valid kubeconfig (or in-cluster submission).
Mesos (legacy, rarely used today)
spark-submit \
--master mesos://zk://mesos-zk:2181/mesos \ # Mesos master from ZooKeeper
--deploy-mode client \ # driver on submit host
app.py
What each piece does
--master mesos://...: connects to Mesos; ZooKeeper provides HA master discovery.
Client vs cluster mode same semantics as others.
Local/dev code (no cluster—just your machine)
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("ConnectDemo")
.master("local[4]") # run locally with 4 worker threads
.getOrCreate())
What it means
.master("local[4]"): run Spark locally with 4 threads (great for unit tests and debugging).
In production, don’t hardcode .master(...); let spark-submit --master ... decide.
(If both are present, spark-submit settings typically win.)
Minimal end-to-end example (app.py)
Use this same file with ANY of the spark-submit commands above (Standalone/YARN/K8s). It prints where it connected, how many executors it sees, and does some parallel work so you can see tasks run.
# app.py
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("ClusterConnectDemo")
.getOrCreate())
sc = spark.sparkContext
# --- Introspection: where am I running? ---
print("Master URL :", sc.master) # e.g., spark://..., yarn, k8s...
try:
app_id = sc._jsc.sc().applicationId()
except Exception:
app_id = "n/a"
print("Application ID :", app_id)
print("Default parallelism :", sc.defaultParallelism)
# How many executors are alive (driver not guaranteed included)
try:
ems = sc._jsc.sc().getExecutorMemoryStatus()
print("Executor slots (map size):", ems.size())
except Exception:
pass
# --- Actual work across partitions/tasks ---
rdd = sc.parallelize(range(1_000_000), numSlices=sc.defaultParallelism)
total = (rdd
.map(lambda x: x * x)
.reduce(lambda a, b: a + b))
print("Sum of squares :", total)
# Check how many partitions were used
print("Partitions used :", rdd.getNumPartitions())
spark.stop()
How to run it
Standalone
spark-submit \
--master spark://spark-master:7077 \
--deploy-mode client \
--conf spark.executor.instances=4 \
app.py
YARN
spark-submit \
--master yarn \
--deploy-mode cluster \
--conf spark.executor.instances=4 \
--conf spark.executor.memory=4g \
app.py
Kubernetes (bake app.py into the image at /opt/spark/app.py)
spark-submit \
--master k8s://https://my-k8s-apiserver:6443 \
--deploy-mode cluster \
--name my-spark-app \
--conf spark.kubernetes.container.image=myrepo/spark-py:latest \
--conf spark.executor.instances=4 \
--conf spark.kubernetes.namespace=data \
local:///opt/spark/app.py
How to run spark
For local testing of Spark on your Ubuntu system, you should:
Install Apache Spark on your Ubuntu machine.
Set the SPARK_HOME environment variable.
Ensure the bin/ folder is included in your system's PATH so you can run spark-submit.
Steps to run spark-submit locally:
Install Spark (if you haven't already):
sudo apt-get update
sudo apt-get install openjdk-8-jdk # Java is a prerequisite
wget https://apache.claz.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
tar -xvf spark-3.1.2-bin-hadoop3.2.tgz
mv spark-3.1.2-bin-hadoop3.2 /opt/spark
Set Environment Variables:
Add the following lines to your ~/.bashrc file:
export SPARK_HOME=/opt/spark
export PATH=$SPARK_HOME/bin:$PATH
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
Then, run source ~/.bashrc to reload the environment variables.
Verify the Spark installation:
You should be able to run:
spark-submit --version
Run your Spark application:
From anywhere in your terminal, you can now run spark-submit (as long as you're inside a folder that contains your Spark application):
spark-submit --master local[4] --deploy-mode client --conf spark.executor.instances=4 app.py
10 unique examples of how you can connect to a Cluster Manager using SparkSession in PySpark
Local Mode (Development)
Runs Spark on your local machine with multiple threads. Ideal for quick testing.
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("LocalDevExample")
.master("local[4]") # Use 4 threads locally
.getOrCreate())
Standalone Cluster Mode
Runs Spark on a cluster where the cluster manager is Spark's own Standalone Manager.
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("StandaloneClusterExample")
.master("spark://spark-master:7077") # Connect to the standalone Spark master
.getOrCreate())
YARN (Cluster Mode)
Use YARN as the cluster manager, suitable for Hadoop-based environments.
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("YarnClusterExample")
.master("yarn") # YARN as the cluster manager
.config("spark.executor.memory", "4g") # Set memory for executors
.getOrCreate())
Kubernetes (Cluster Mode)
Submit a job to run in Kubernetes using Spark's support for Kubernetes clusters.
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("KubernetesClusterExample")
.master("k8s://https://my-k8s-apiserver:6443") # Kubernetes API endpoint
.config("spark.kubernetes.container.image", "myrepo/spark:latest") # Image with Spark & app
.config("spark.executor.instances", "4") # Number of executors
.getOrCreate())
Mesos (Cluster Mode)
Using Mesos as the cluster manager (legacy mode).
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("MesosClusterExample")
.master("mesos://zk://mesos-zk:2181/mesos") # Mesos master URL
.getOrCreate())
K8s (Pod-Specific)
If you need to use Kubernetes and configure specific pods for your job.
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("K8sPodExample")
.master("k8s://https://my-k8s-apiserver:6443")
.config("spark.kubernetes.namespace", "my-namespace") # K8s namespace
.config("spark.kubernetes.driver.pod.name", "driver-pod") # Specific pod name
.getOrCreate())
YARN (Client Mode)
Running YARN in client mode, where the driver runs on your local machine and the executors run in the cluster.
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("YarnClientModeExample")
.master("yarn")
.config("spark.executor.memory", "4g")
.config("spark.yarn.submit.file.replication", "3") # Replication factor for files in HDFS
.getOrCreate())
Standalone Mode (With Spark Configurations)
Running Spark in Standalone mode with additional configurations for resource allocation.
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("StandaloneClusterWithConfigExample")
.master("spark://spark-master:7077")
.config("spark.executor.cores", "4") # 4 cores per executor
.config("spark.executor.memory", "8g") # 8GB per executor
.getOrCreate())
Amazon EMR (YARN on AWS)
When running Spark on AWS EMR, the cluster manager is YARN, but you’re running on AWS infrastructure.
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("AWSEMRClusterExample")
.master("yarn")
.config("spark.executor.memory", "4g")
.config("spark.executor.instances", "10") # 10 executors
.getOrCreate())
Local Mode with Custom Parallelism
Running Spark locally but controlling the number of partitions or parallelism.
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("LocalCustomParallelismExample")
.master("local[6]") # 6 threads (local parallelism)
.config("spark.sql.shuffle.partitions", "6") # Set shuffle partitions
.getOrCreate())
Setting Number of Executors (and other resources)
You can specify how many executors you want to run and how much memory and CPU each executor should use.
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("StandaloneClusterWithExecutorExample")
.master("spark://spark-master:7077") # Connect to the Standalone Spark master
.config("spark.executor.instances", "4") # Number of executors
.config("spark.executor.cores", "2") # Number of cores per executor
.config("spark.executor.memory", "4g") # Memory per executor (4GB)
.getOrCreate())
# Example operation
rdd = spark.sparkContext.parallelize(range(1000), 4) # Create RDD with 4 partitions
print("Total sum:", rdd.reduce(lambda a, b: a + b))
# Stop the Spark session after work is done
spark.stop()

What happens here?
spark.executor.instances: Specifies the number of executors. Here, we set it to 4. This means 4 workers will perform tasks in parallel.
spark.executor.cores: Specifies how many cores per executor. Here, each executor gets 2 cores.
spark.executor.memory: Specifies how much memory each executor gets. Here, each executor gets 4 GB of memory.
Explanation of each configuration:
spark.executor.instances: This configuration defines how many executors are launched by the cluster manager for this Spark job. The default number of executors is 1 (for single-machine execution), but when working on a cluster, you can specify the number of executors.
Example: "spark.executor.instances", "4" means Spark will launch 4 executors for your job.
spark.executor.cores: This sets how many CPU cores each executor will use. By default, each executor uses 1 core. You can increase this to parallelize tasks more effectively.
Example: "spark.executor.cores", "2" means each executor gets 2 cores.
spark.executor.memory: This configures how much RAM each executor will use. It can be helpful to allocate more memory if you’re processing large datasets.
Example: "spark.executor.memory", "4g" means each executor gets 4 GB of memory.
Understanding how Executors are Allocated
Standalone cluster mode will allocate the number of executors you specify, and each executor will be scheduled to run tasks on a separate core/CPU of the available cluster nodes.
If you run locally (e.g., using local[*]), you don't control the number of executors directly, but Spark will run tasks on the available threads (cores) of your machine.
Example Output
# RDD example
Total sum: 499500
This would indicate that Spark used 4 executors (2 cores per executor, with each executor processing tasks in parallel) to compute the sum of the range from 0 to 999.
Cluster Manager Impact
Standalone: If you specify 4 executors, Spark will launch 4 executors on your cluster’s machines (assuming they are available).
YARN/Kubernetes: If you use YARN or Kubernetes, these clusters will schedule and assign executors on available resources. In that case, the configuration (spark.executor.instances, spark.executor.cores, spark.executor.memory) controls the size and number of executors, but the exact placement depends on the cluster manager.
When to use spark.executor.instances and other resources:
Scale for large data: When you have large data and need parallel processing.
Increased parallelism: If your job has tasks that can run in parallel (e.g., map or reduce tasks), you can increase the number of executors to reduce the overall processing time.
Memory-intensive jobs: If you're dealing with large in-memory data, you might need to allocate more memory per executor.
connect to a Cluster Manager using SparkSession in PySpark in ML field
Local Mode for Small Datasets (Quick Data Exploration)
Data scientists often start with small datasets for EDA (Exploratory Data Analysis) and prototyping locally.
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("LocalMLExample")
.master("local[4]") # Local mode, 4 threads
.getOrCreate())
# DataFrame-based operations for quick exploration
data = spark.read.csv("file:///tmp/small_data.csv", header=True, inferSchema=True)
data.show()
Standalone Cluster for Scalable Data Processing
When working with larger datasets (e.g., using MLlib), Data Scientists often connect to a Standalone cluster.
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("MLProcessingExample")
.master("spark://spark-master:7077") # Connect to Standalone Spark master
.getOrCreate())
# Process large datasets for ML model training
data = spark.read.csv("hdfs://spark-cluster/data/large_data.csv", header=True, inferSchema=True)
YARN for Distributed Machine Learning
For a large-scale machine learning task (e.g., training models on large datasets), YARN provides the cluster management needed to scale across a large number of executors.
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("DistributedMLEngine")
.master("yarn") # Connect to YARN cluster
.config("spark.executor.memory", "4g")
.getOrCreate())
# Training on large dataset
data = spark.read.parquet("hdfs://yarn-cluster/large_ml_dataset")
# Example: using Spark MLlib for training a RandomForest model
from pyspark.ml.classification import RandomForestClassifier
rf = RandomForestClassifier(featuresCol="features", labelCol="label")
model = rf.fit(data)
Kubernetes for Containerized AI Workflows
When running AI jobs in containerized environments (like Kubernetes), Data Scientists can scale workloads in a flexible way.
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("K8sAIExample")
.master("k8s://https://my-k8s-apiserver:6443") # Kubernetes API endpoint
.config("spark.kubernetes.container.image", "myrepo/spark-py:latest") # Docker image with Spark + MLlib
.config("spark.executor.instances", "4")
.getOrCreate())
# Spark job for deep learning or reinforcement learning training
AI-based Hyperparameter Tuning using YARN
AI practitioners often use distributed hyperparameter tuning frameworks like Hyperopt or Optuna that require large-scale parallelization across YARN nodes.
from pyspark.sql import SparkSession
from hyperopt import fmin, tpe, hp, Trials
spark = (SparkSession.builder
.appName("HyperparameterTuningYARN")
.master("yarn")
.getOrCreate())
# Define hyperparameter search space and objective function for ML model tuning
def objective(params):
# Code to train model and compute error metric
pass
space = {
'learning_rate': hp.uniform('learning_rate', 0.01, 0.1),
'max_depth': hp.choice('max_depth', [3, 5, 7, 9])
}
# Use Spark to distribute the tuning process
trials = Trials()
best = fmin(objective, space, algo=tpe.suggest, max_evals=50)
TensorFlow or PyTorch Distributed Training on Kubernetes
For deep learning models that require distributed training, Kubernetes can be used to deploy a TensorFlow or PyTorch cluster across multiple nodes.
import tensorflow as tf
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("DistributedDLModel")
.master("k8s://https://my-k8s-apiserver:6443")
.config("spark.kubernetes.container.image", "tensorflow/tensorflow:2.6.0")
.getOrCreate())
# Train a distributed TensorFlow model
# Using TensorFlow's `DistributedStrategy` on Kubernetes
MLlib for Scalable Machine Learning on YARN
You might need to process very large datasets for tasks like logistic regression or random forests. In this case, YARN ensures you can leverage a massive cluster to scale out.
from pyspark.sql import SparkSession
from pyspark.ml.classification import LogisticRegression
spark = (SparkSession.builder
.appName("MLlibYARNExample")
.master("yarn")
.getOrCreate())
# Large dataset for classification
data = spark.read.parquet("hdfs://cluster/large_data.parquet")
# Train model using MLlib
lr = LogisticRegression(featuresCol='features', labelCol='label')
lr_model = lr.fit(data)
Apache Spark with H2O.ai for AI and Machine Learning
H2O.ai integrates with Spark for scalable machine learning. The cluster manager (YARN/Standalone) ensures that tasks are distributed effectively across the cluster.
from pyspark.sql import SparkSession
import h2o
from h2o.estimators import H2ORandomForestEstimator
spark = (SparkSession.builder
.appName("H2OAIExample")
.master("yarn") # H2O on YARN
.getOrCreate())
# H2O initialization
h2o.init()
# Load dataset into H2O cluster
data = h2o.import_file("hdfs://hadoop-cluster/data.csv")
# Train model using H2O's RandomForest
model = H2ORandomForestEstimator()
model.train(x=['col1', 'col2'], y='target', training_frame=data)
Distributed Graph Processing with GraphX on YARN
Graph analytics (like PageRank) can be done at scale using GraphX in Spark, and the YARN cluster manager ensures scalability.
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("GraphXExample")
.master("yarn") # YARN as the cluster manager
.getOrCreate())
# Create RDD for GraphX
from pyspark.graphx import Graph
# Example: creating a simple graph with vertices and edges
vertices = sc.parallelize([(1, "Alice"), (2, "Bob")])
edges = sc.parallelize([(1, 2, "knows")])
# Create graph and perform operations
graph = Graph(vertices, edges)
pageRank = graph.pageRank(0.1)
print(pageRank.vertices.collect())
Streaming Data with Spark Streaming on YARN
For real-time analytics with streaming data (e.g., from Kafka), YARN can be used to allocate resources dynamically based on the incoming stream.
from pyspark.sql import SparkSession
from pyspark.streaming import StreamingContext
spark = (SparkSession.builder
.appName("RealTimeStreamingExample")
.master("yarn") # YARN to handle dynamic resource allocation
.getOrCreate())
ssc = StreamingContext(spark.sparkContext, 10) # 10 second batch interval
# Read from Kafka (simulated)
kafkaStream = ssc.socketTextStream("localhost", 9999)
# Process stream
kafkaStream.pprint()
ssc.start() # Start streaming
ssc.awaitTermination()

Top comments (0)