step 1 first install libraries
pip install bs4
pip install request
step 2 import libraries
from bs4 import BeautifulSoup
import requests
step3:Send an HTTP GET request to the URL and (status code 200)
page = requests.get('https://www.wikipedia.org')
page
output
<Response [200]>
step4: check page content
soup= BeautifulSoup(page.content)
soup
output
step5: get header tag information
header_tags = soup.find_all(['h1', 'h2', 'h3', 'h4', 'h5', 'h6'])
header_tags
output
step6: append all header and store in list
name=[]
for tag in header_tags:
name.append(tag.name)
name
output
['h1', 'h2', 'h2', 'h2', 'h2', 'h2']
step6: append all header content and store in list
text=[]
for tag in header_tags:
text.append(tag.text.strip())
text
output
['Wikipedia\n\nThe Free Encyclopedia',
'1\xa0000\xa0000+\n\n\narticles',
'100\xa0000+\n\n\narticles',
'10\xa0000+\n\n\narticles',
'1\xa0000+\n\n\narticles',
'100+\n\n\narticles']
step7: make a dataframe
import pandas as pd
df= pd.DataFrame({'tag':name,'text':text})
df
output
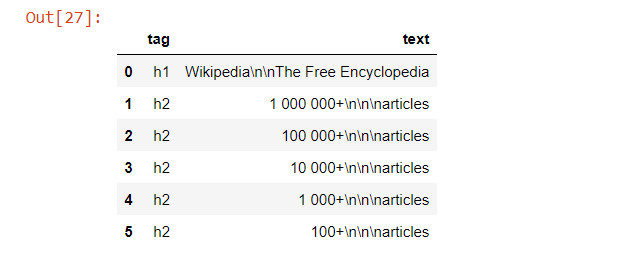
step7: make a dataframe for only header tag
import pandas as pd
df= pd.DataFrame({'tag':name})
df

Another Methods
import requests
import pandas as pd
from bs4 import BeautifulSoup
# URL of the web page to scrape
url = 'https://en.wikipedia.org/wiki/Main_Page'
# Send an HTTP GET request to the URL
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse the HTML content of the web page
soup = BeautifulSoup(response.text, 'html.parser')
# Find all header tags (h1, h2, h3, etc.)
header_tags = soup.find_all(['h1', 'h2', 'h3', 'h4', 'h5', 'h6'])
# Create a DataFrame to store the header tags
header_df = pd.DataFrame(columns=['Tag', 'Text'])
# Iterate through the header tags and extract their text
for tag in header_tags:
header_df = header_df.append({'Tag': tag.name, 'Text': tag.get_text()}, ignore_index=True)
# Display the DataFrame with header tags
print(header_df)
else:
print('Failed to retrieve the web page.')
==================================================
import requests
import pandas as pd
from bs4 import BeautifulSoup
# URL of the web page to scrape
url = 'https://en.wikipedia.org/wiki/Main_Page'
# Send an HTTP GET request to the URL
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse the HTML content of the web page
soup = BeautifulSoup(response.text, 'html.parser')
# Find all header tags (h1, h2, h3, h4, h5, h6)
header_tags = soup.find_all(['h1', 'h2', 'h3', 'h4', 'h5', 'h6'])
# Create a list to store the names of header tags
header_tag_names = []
# Iterate through the header tags and extract their names
for tag in header_tags:
header_tag_names.append(tag.name)
# Display the list of header tag names
print(header_tag_names)
else:
print('Failed to retrieve the web page.')
=================================
import requests
from bs4 import BeautifulSoup
# scraping a wikipedia article
url_link = 'https://www.geeksforgeeks.org/how-to-scrape-all-pdf-files-in-a-website/'
request = requests.get(url_link)
Soup = BeautifulSoup(request.text, 'lxml')
# creating a list of all common heading tags
heading_tags = ["h1", "h2", "h3"]
for tags in Soup.find_all(heading_tags):
print(tags.name + ' -> ' + tags.text.strip())
Output
h2 -> Related Articles
h2 -> Python3
h2 -> Python3
h2 -> Python3
h2 -> Python3
h2 -> Python3
h2 -> Python3

Top comments (0)