How to use full XPATH to submit after send keys to search
How to remove any empty elements or whitespace elements from list using list comprhension
How to select class using anchor tag,span tag by XPATH
Step 1: install selenium using python
pip install --upgrade selenium
Step 2: Import Required Libraries
import pandas as pd
from selenium import webdriver
import warnings
warnings.filterwarnings('ignore')
from selenium.webdriver.common.by import By
import time
Step 3: Start a WebDriver Instance
driver=webdriver.Chrome()
Step 4: Navigate to a Webpage
Navigate to the webpage where you want to interact with the search input bar:
driver.get('https://www.shine.com/')
Step 5: Find the Search Input Element
designationinput=driver.find_element(By.ID, 'id_q')
Step 6: Send Keys to the Input Element
designationinput.send_keys('Data Analyst')
Step 7: Find the Search Input Element for location
location=driver.find_element(By.ID, 'id_loc')
Step 8: Send Keys to the Input Element location
location.send_keys('Banglore')
step 9: submit button
How to use full XPATH to submit after send keys to search
search_button = driver.find_element(By.XPATH, '/html/body/div[1]/div[4]/div/div[2]/div[2]/div/form/div/div[2]/div/button')
search_button.click()
Step 10: Scrape the Results
job_titles=[]
job_locations=[]
company_name=[]
experience_required=[]
Step 11: Scrape the header element using XPATH
h2_elements = driver.find_elements(By.XPATH, "//h2[@itemprop='name']")
for i in h2_elements[0:10]:
a_tag = i.find_element(By.TAG_NAME, 'a')
job_titles.append(a_tag.text)
job_titles = [title for title in job_titles if title.strip()]
job_titles = job_titles[:10]
job_titles
output
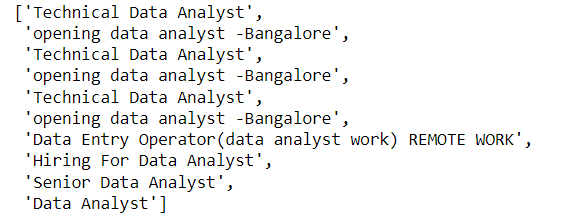
Step 12: Scrape the location result using class_name
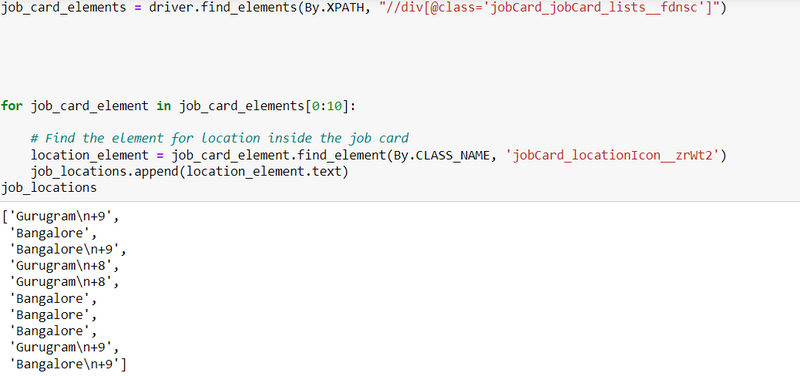
output
Step 13: Scrape the location result using class_name
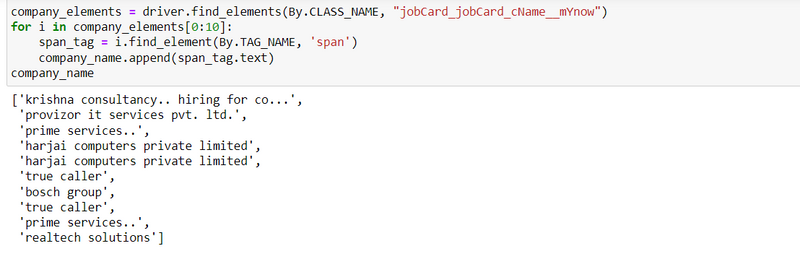
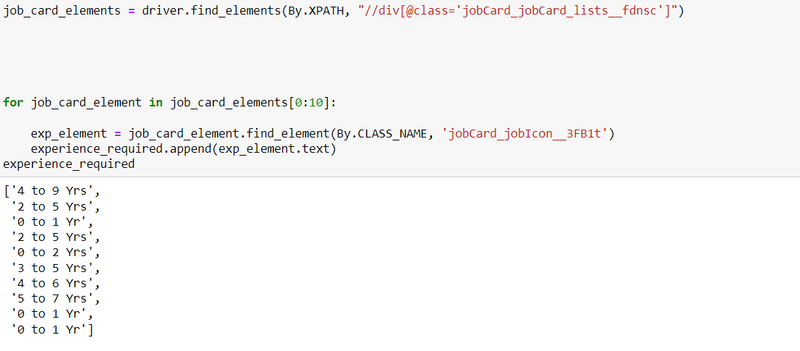
Step 13: Create data frame of all scraping results
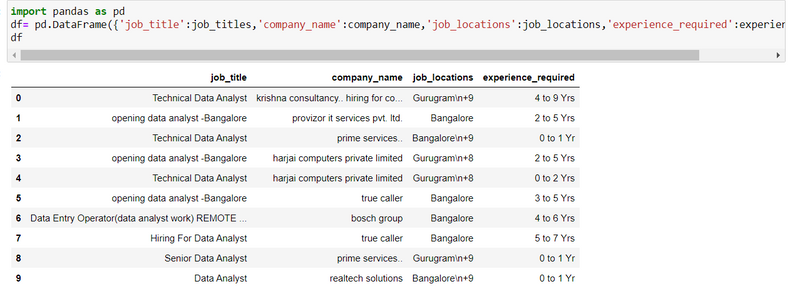
Another Examples
Step 1: install selenium using python
pip install --upgrade selenium
Step 2: Import Required Libraries
import pandas as pd
from selenium import webdriver
import warnings
warnings.filterwarnings('ignore')
from selenium.webdriver.common.by import By
import time
Step 3: Start a WebDriver Instance
driver=webdriver.Chrome()
Step 4: Navigate to a Webpage
Navigate to the webpage where you want to interact with the search input bar:
driver.get('https://www.shine.com/')
Step 5: Find the Search Input Element
requirement=driver.find_element(By.ID, 'id_q')
Step 6: Send Keys to the Input Element
requirement.send_keys('Data Scientist')
Step 7: Find the Search Input Element for location by sending S Keys to the Input Element location and then submit button
locations=driver.find_element(By.ID, 'id_loc')
locations.send_keys('Banglore')
search_button = driver.find_element(By.XPATH, '/html/body/div[1]/div[4]/div/div[2]/div[2]/div/form/div/div[2]/div/button')
search_button.click()
Step 8: Scrape the Results
jobs=[]
joblocations=[]
companiesname=[]
experience=[]
Step 9: Scrape the header element using XPATH
jobs = driver.find_elements(By.XPATH, "//h2[@itemprop='name']")
for i in jobs[0:10]:
a_tag = i.find_element(By.TAG_NAME, 'a')
job_titles.append(a_tag.text)
job_titles = [title for title in job_titles if title.strip()]
job_titles = job_titles[:10]
job_titles
output

Step 10: Scrape the companies name result using class_name
company_element = driver.find_elements(By.CLASS_NAME, "jobCard_jobCard_cName__mYnow")
for i in company_element[0:10]:
span_tag = i.find_element(By.TAG_NAME, 'span')
companiesname.append(span_tag.text)
companiesname
output

Step 11: Scrape the job locations result using xpath for div class

output

Step 11: Scrape the experience result using xpath for div class
job_exp_elements = driver.find_elements(By.XPATH, "//div[@class='jobCard_jobCard_lists__fdnsc']")
for job_card_element in job_exp_elements[0:10]:
exp_element = job_card_element.find_element(By.CLASS_NAME, 'jobCard_jobIcon__3FB1t')
experience.append(exp_element.text)
experience
output
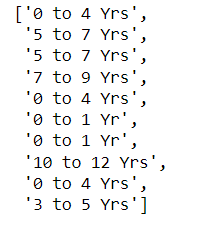
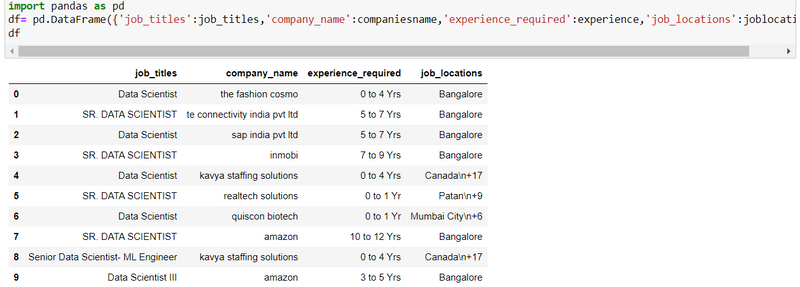
Step 13: Create data frame of all scraping results
==================================================
How to select class using anchor tag,span tag by XPATH
job_title=[]
job_location=[]
company_name=[]
#Scrap all require data from webpage
title_tags=driver.find_elements(By.XPATH,"//a[@class='title ']")
for i in title_tags[0:10]:
title=i.text
job_title.append(title)
company_tags=driver.find_elements(By.XPATH,"//a[@class=' comp-name mw-25']")
for i in company_tags[0:10]:
company=i.text
company_name.append(company)
location_tags=driver.find_elements(By.XPATH,"//span[@class='locWdth']")
for i in location_tags[0:10]:
location=i.text
job_location.append(location)
print(len(job_title),len(job_location),len(company_name))

Top comments (0)