Use of df.head() and df.set_index()
Importing from a CSV file and saving to a Django model:
import pandas as pd
from myapp.models import MyModel
data = pd.read_csv('data.csv')
for index, row in data.iterrows():
my_model = MyModel(field1=row['field1'], field2=row['field2'])
my_model.save()
Importing from an Excel file and saving to a Django model:
import pandas as pd
from myapp.models import MyModel
data = pd.read_excel('data.xlsx')
for index, row in data.iterrows():
my_model = MyModel(field1=row['field1'], field2=row['field2'])
my_model.save()
Importing from a JSON file and saving to a Django model:
import pandas as pd
from myapp.models import MyModel
data = pd.read_json('data.json')
for index, row in data.iterrows():
my_model = MyModel(field1=row['field1'], field2=row['field2'])
my_model.save()
Importing from a SQL database and saving to a Django model:
import pandas as pd
from myapp.models import MyModel
from django.db import connection
query = 'SELECT * FROM table_name'
data = pd.read_sql(query, connection)
for index, row in data.iterrows():
my_model = MyModel(field1=row['field1'], field2=row['field2'])
my_model.save()
Importing from a URL (CSV format) and saving to a Django model:
import pandas as pd
from myapp.models import MyModel
url = 'https://example.com/data.csv'
data = pd.read_csv(url)
for index, row in data.iterrows():
my_model = MyModel(field1=row['field1'], field2=row['field2'])
my_model.save()
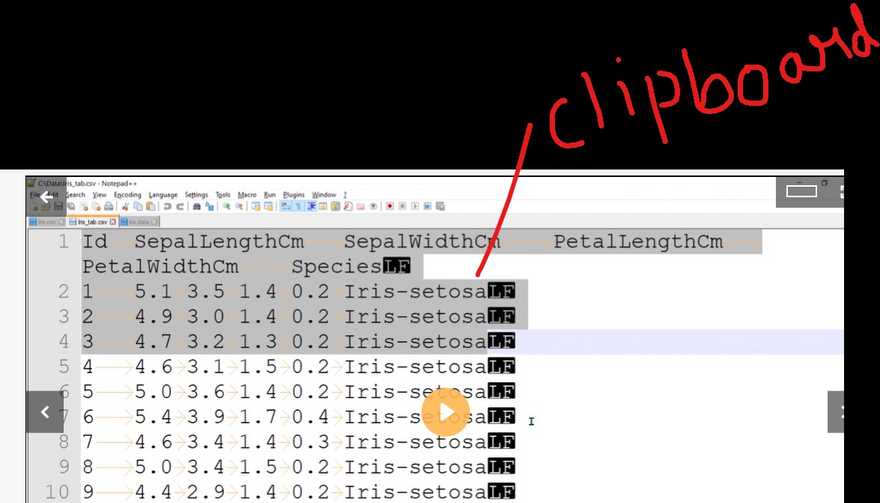
Importing from a clipboard (data copied from a table) and saving to a Django model:
import pandas as pd
from myapp.models import MyModel
data = pd.read_clipboard()
for index, row in data.iterrows():
my_model = MyModel(field1=row['field1'], field2=row['field2'])
my_model.save()
Importing from a Python dictionary and saving to a Django model:
import pandas as pd
from myapp.models import MyModel
data = pd.DataFrame({
'field1': [1, 2, 3],
'field2': ['A', 'B', 'C']
})
for index, row in data.iterrows():
my_model = MyModel(field1=row['field1'], field2=row['field2'])
my_model.save()
Importing from a CSV file and using Django's bulk_create() for efficient saving:
import pandas as pd
from myapp.models import MyModel
data = pd.read_csv('data.csv')
my_models = [MyModel(field1=row['field1'], field2=row['field2']) for index, row in data.iterrows()]
MyModel.objects.bulk_create(my_models)
Importing from a CSV file and using Django's get_or_create() to avoid duplicates:
import pandas as pd
from myapp.models import MyModel
data = pd.read_csv('data.csv')
for index, row in data.iterrows():
MyModel.objects.get_or_create(field1=row['field1'], field2=row['field2'])
Use of df.head() and df.set_index()
df.head(): This method is used to view the first few rows of the DataFrame. By default, it returns the first 5 rows, but you can specify a different number of rows as an argument. Here's an example:
import pandas as pd
data = pd.read_csv('data.csv')
print(data.head())
Output:
Column1 Column2 Column3
0 1 A True
1 2 B False
2 3 C True
3 4 D False
4 5 E True
In this example, we import a CSV file and assign it to the data DataFrame. By calling data.head(), we can see the first 5 rows of the DataFrame.
df.set_index(): This method is used to set a specific column as the index of the DataFrame. By default, DataFrame rows are indexed with numeric values. However, you can set an existing column as the index to provide a more meaningful index. Here's an example:
import pandas as pd
data = pd.read_csv('data.csv')
data.set_index('Column1', inplace=True)
print(data.head())
Output:
Column2 Column3
Column1
1 A True
2 B False
3 C True
4 D False
5 E True
In this example, we import a CSV file and assign it to the data DataFrame. We then use data.set_index('Column1', inplace=True) to set the 'Column1' as the index. By calling data.head(), we can see the first 5 rows of the DataFrame with the updated index.
===========================================


Top comments (0)