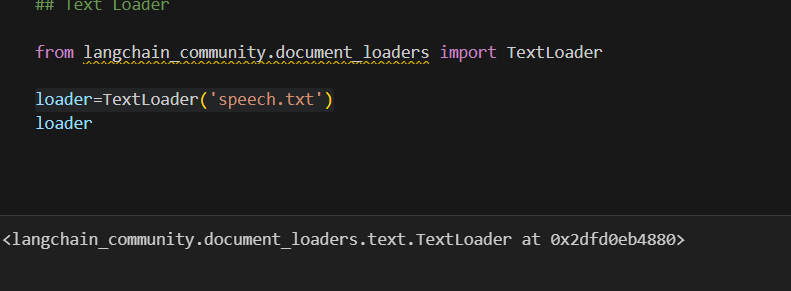
Load Text data
from langchain.document_loaders import TextLoader
# Example: Loading text data
loader = TextLoader('your_data_file.txt')
documents = loader.load()
raw_text = [doc.page_content for doc in documents]
===========or======================
from langchain.document_loaders import TextLoader
# Example: Loading text data
loader = TextLoader('your_data_file.txt').load()

Load csv data
from langchain.document_loaders import CSVLoader
# Load data from a CSV file (each row as a document)
loader = CSVLoader("path/to/your_file.csv")
documents = loader.load()
Load JSON File
[
{"id": 1, "text": "This is the first document.", "author": "Alice"},
{"id": 2, "text": "This is the second document.", "author": "Bob"},
{"id": 3, "text": "Another document here.", "author": "Charlie"}
]
from langchain.document_loaders import JSONLoader
# Load JSON data and extract the `text` field using jq_schema
loader = JSONLoader("example.json", jq_schema=".text")
documents = loader.load()
# Print the documents
for doc in documents:
print(doc.page_content)
Output:
This is the first document.
This is the second document.
Another document here.
Load PDF File
from langchain.document_loaders import PyMuPDFLoader
# Load data from a PDF file
loader = PyMuPDFLoader("path/to/your_file.pdf")
documents = loader.load()
Load Web Page by URL
from langchain.document_loaders import UnstructuredURLLoader
# Load data from a URL (web page)
urls = ["https://example.com/article"]
loader = UnstructuredURLLoader(urls=urls)
documents = loader.load()
Load HTML File
from langchain.document_loaders import UnstructuredHTMLLoader
# Load data from an HTML file
loader = UnstructuredHTMLLoader("path/to/your_file.html")
documents = loader.load()
Load Text from S3 Bucket
from langchain.document_loaders import S3Loader
# Replace with your actual bucket name and key
bucket_name = "my-langchain-documents"
key = "data/sample_file.txt"
# Initialize the loader
loader = S3Loader(bucket_name=bucket_name, key=key)
# Load the documents
documents = loader.load()
# Print the loaded documents
for doc in documents:
print(doc.page_content)
=======OR======================
import boto3
from langchain.document_loaders import S3Loader
# Step 1: Set up AWS credentials
# Replace with your actual AWS Access Key, Secret Key, and Region
aws_access_key_id = "YOUR_AWS_ACCESS_KEY_ID"
aws_secret_access_key = "YOUR_AWS_SECRET_ACCESS_KEY"
aws_region = "YOUR_AWS_REGION" # Example: 'us-east-1'
# Step 2: Initialize Boto3 Session (This ensures credentials are used)
session = boto3.Session(
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
region_name=aws_region,
)
# Step 3: Define S3 bucket and file key
bucket_name = "my-langchain-documents" # Replace with your bucket name
key = "data/sample_file.txt" # Replace with your file path in the bucket
# Step 4: Initialize LangChain's S3Loader
loader = S3Loader(
bucket_name=bucket_name,
key=key,
boto3_session=session # Pass the session with credentials
)
# Step 5: Load the document
documents = loader.load()
# Step 6: Print the content of the loaded document
for doc in documents:
print(doc.page_content)
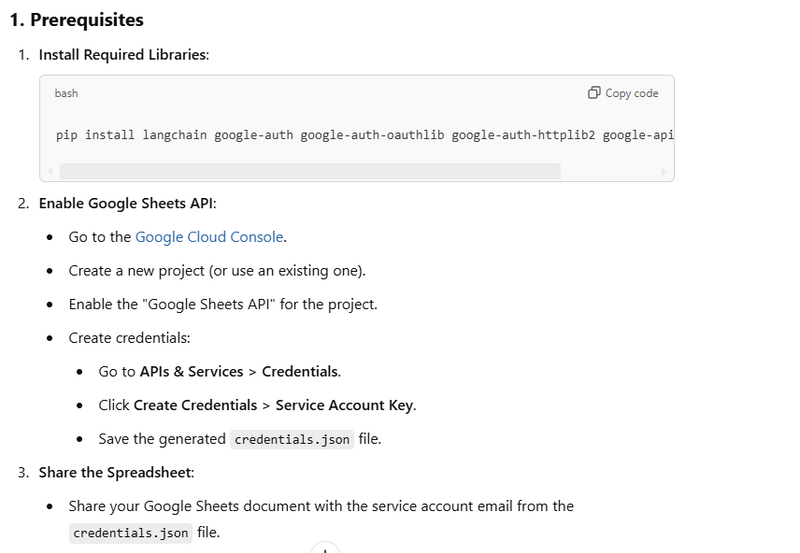
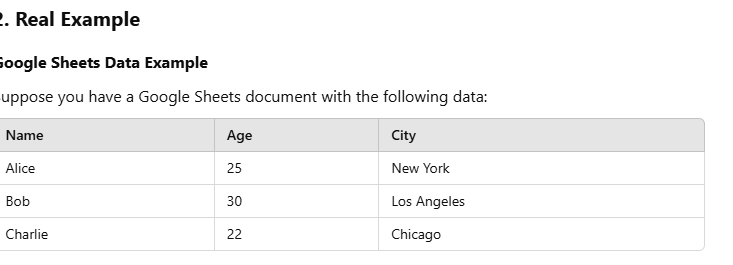
Load Data from Google Sheets
from langchain.document_loaders import GoogleSheetsLoader
# Load data from a Google Sheets document
loader = GoogleSheetsLoader(spreadsheet_id="your-spreadsheet-id", credentials_path="path/to/credentials.json")
documents = loader.load()
from langchain.document_loaders import GoogleSheetsLoader
# Step 1: Set up your spreadsheet ID and credentials path
spreadsheet_id = "your-spreadsheet-id" # Replace with your Google Sheets ID
credentials_path = "path/to/credentials.json" # Replace with the path to your credentials.json file
# Step 2: Initialize GoogleSheetsLoader
loader = GoogleSheetsLoader(spreadsheet_id=spreadsheet_id, credentials_path=credentials_path)
# Step 3: Load the data as documents
documents = loader.load()
# Step 4: Print the loaded documents
for doc in documents:
print(doc.page_content)
Load Text from Word Document (DOCX)
from langchain.document_loaders import UnstructuredWordDocumentLoader
# Load data from a Word document
loader = UnstructuredWordDocumentLoader("path/to/your_file.docx")
documents = loader.load()
Load Text from Email (EML) File
from langchain.document_loaders import UnstructuredEmailLoader
# Load data from an email file (.eml)
loader = UnstructuredEmailLoader("path/to/your_file.eml")
documents = loader.load()
Images (OCR): Pytesseract with Pillow or UnstructuredImageLoader
Description: Requires OCR (Optical Character Recognition) tools to convert image text to strings. Pytesseract combined with Pillow or UnstructuredImageLoader can extract text from image files.
Example:
from PIL import Image
import pytesseract
image = Image.open("path/to/image.png")
text = pytesseract.image_to_string(image)

CSVLoader: Loads structured data from CSV files, often used for tabular data.
PyMuPDFLoader: Extracts text from PDF files using the PyMuPDF library.
PDFMinerLoader: Extracts text from PDF files with detailed control over layout using PDFMiner.
UnstructuredURLLoader: Loads and extracts content from web pages at specified URLs.
UnstructuredImageLoader: Converts text in images to strings using OCR (Optical Character Recognition).
UnstructuredHTMLLoader: Loads and parses HTML files, targeting specific tags if needed.
UnstructuredWordDocumentLoader: Extracts text from .docx Microsoft Word documents.
UnstructuredEmailLoader: Loads email content from .eml files, including body and metadata.
JSONLoader: Extracts data from JSON files, allowing filtering by specific keys.
YouTubeLoader: Retrieves video transcripts and metadata from YouTube videos.
GoogleSheetsLoader: Loads spreadsheet data from Google Sheets, requiring OAuth authentication.
NotionLoader: Loads records from a Notion database using the Notion API.
MongoDBLoader: Extracts documents from MongoDB collections.
SlackLoader: Loads messages from specified Slack channels, with keyword and date filtering.
GitHubRepoLoader: Loads files from GitHub repositories.
RSSFeedLoader: Retrieves articles from RSS feeds, useful for loading updates or news.
GoogleDriveLoader: Loads files from Google Drive, requiring access via OAuth.
SQLDatabaseLoader: Loads records from SQL databases by querying specified tables.
ElasticsearchLoader: Loads documents from an Elasticsearch index for search-based data retrieval.
AirtableLoader: Loads records from Airtable databases via the Airtable API.
EmailLoader: Connects to IMAP servers to load emails directly from an inbox.
Load Data from SQL Database
from langchain.document_loaders import SQLDatabaseLoader
from sqlalchemy import create_engine
# Create an engine for a SQL database (e.g., PostgreSQL, MySQL)
engine = create_engine("postgresql://username:password@localhost/dbname")
# Load data from SQL table (specify table name or query)
loader = SQLDatabaseLoader(engine, table_name="your_table_name")
documents = loader.load()
Load Data from a REST API
from langchain.document_loaders import RESTAPILoader
# Load data from a REST API endpoint
url = "https://api.example.com/data"
headers = {"Authorization": "Bearer your_token"}
loader = RESTAPILoader(url=url, headers=headers)
documents = loader.load()
Load Text Data from Google Drive
from langchain.document_loaders import GoogleDriveLoader
# Load data from a Google Drive file (e.g., Google Docs or Google Sheets)
loader = GoogleDriveLoader(file_id="your_file_id", credentials_path="path/to/credentials.json")
documents = loader.load()
Load Data from MongoDB
from langchain.document_loaders import MongoDBLoader
# Load data from a MongoDB collection
loader = MongoDBLoader(
connection_string="mongodb://localhost:27017",
database="your_database",
collection="your_collection"
)
documents = loader.load()
Load Data from AWS DynamoDB
from langchain.document_loaders import DynamoDBLoader
# Load data from an AWS DynamoDB table
loader = DynamoDBLoader(table_name="your_table_name", aws_access_key="your_key", aws_secret_key="your_secret")
documents = loader.load()
Load Text from Google Cloud Storage (GCS)
from langchain.document_loaders import GCSLoader
# Load text data from a Google Cloud Storage bucket
loader = GCSLoader(bucket_name="your_bucket_name", key="path/to/your_file.txt")
documents = loader.load()
Load Data from Snowflake Database
from langchain.document_loaders import SnowflakeLoader
# Load data from a Snowflake database
loader = SnowflakeLoader(
account="your_account",
user="your_user",
password="your_password",
warehouse="your_warehouse",
database="your_database",
schema="your_schema",
table="your_table"
)
documents = loader.load()
Load Data from SharePoint Document
from langchain.document_loaders import SharePointLoader
# Load data from a SharePoint document or library
loader = SharePointLoader(
site_url="https://yourcompany.sharepoint.com/sites/your_site",
client_id="your_client_id",
client_secret="your_client_secret",
file_path="path/to/your_file.docx"
)
documents = loader.load()
Load Data from Elasticsearch Index
from langchain.document_loaders import ElasticsearchLoader
# Load data from an Elasticsearch index
loader = ElasticsearchLoader(
hosts=["http://localhost:9200"],
index="your_index",
query={"match_all": {}}
)
documents = loader.load()
Load Data from an RSS Feed
from langchain.document_loaders import RSSFeedLoader
# Load data from an RSS feed
feed_url = "https://example.com/feed.rss"
loader = RSSFeedLoader(feed_url)
documents = loader.load()
Summary
These commands cover loading text data from a diverse range of sources:
Databases (SQL, MongoDB, Snowflake, Elasticsearch)
Cloud Storage (Google Cloud Storage, SharePoint, AWS DynamoDB)
Web-Based Sources (REST API, RSS Feed, Google Drive
Loading Research Papers from Arxiv
The ArxivLoader lets you load research papers by specifying either the query or the paper ID.
from langchain.document_loaders import ArxivLoader
# Load up to 2 documents from Arxiv for the paper ID "1706.03762" (e.g., Attention is All You Need)
docs_arxiv = ArxivLoader(query="1706.03762", load_max_docs=2).load()
# Displaying the content
for doc in docs_arxiv:
print("Arxiv Content:", doc.page_content)
Loading Content from a Web Page (using WebBaseLoader)
The WebBaseLoader can load specific parts of a webpage by targeting HTML elements with certain classes using bs4.SoupStrainer. Here’s how to use it for loading sections from a webpage.
from langchain.document_loaders import WebBaseLoader
import bs4
# Load specific parts of the web page by class name
loader_web = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_=("post-title", "post-content", "post-header")))
)
docs_web = loader_web.load()
# Displaying the content
for doc in docs_web:
print("Web Page Content:", doc.page_content)
Loading Content from Wikipedia
The WikipediaLoader loads summaries or sections from a Wikipedia article based on the query term.
from langchain.document_loaders import WikipediaLoader
# Load up to 2 documents from Wikipedia for the topic "Generative AI"
docs_wikipedia = WikipediaLoader(query="Generative AI", load_max_docs=2).load()
# Displaying the content
for doc in docs_wikipedia:
print("Wikipedia Content:", doc.page_content)
Combining All Loaders Together
If you want to load data from all these sources at once and combine them, you can load each into a list and then combine all the documents into one list.
# Combine all documents from different sources
all_docs = docs_arxiv + docs_web + docs_wikipedia
# Displaying the combined content
for i, doc in enumerate(all_docs):
print(f"Document {i+1} Content:", doc.page_content)
Summary of Each Loader Used
ArxivLoader: Loads scientific papers by query or paper ID from Arxiv.
WebBaseLoader: Loads specific content from a webpage using HTML filters.
WikipediaLoader: Loads summaries or sections of a Wikipedia article.
Load from Notion Database
from langchain.document_loaders import NotionLoader
# Load content from a Notion database (requires integration token)
loader_notion = NotionLoader(integration_token="your_token", database_id="your_database_id")
docs_notion = loader_notion.load()
Load from Google Docs
from langchain.document_loaders import GoogleDriveLoader
# Load a Google Docs file by its ID (requires Google OAuth credentials)
loader_gdoc = GoogleDriveLoader(file_id="your_file_id", credentials_path="path/to/credentials.json")
docs_gdoc = loader_gdoc.load()
Load from YouTube Transcript
from langchain.document_loaders import YouTubeLoader
# Load transcript from a YouTube video (requires video ID)
docs_youtube = YouTubeLoader(video_id="your_video_id").load()
Load from a Slack Channel
from langchain.document_loaders import SlackLoader
# Load messages from a Slack channel (requires API token)
loader_slack = SlackLoader(api_token="your_slack_token", channel_id="your_channel_id")
docs_slack = loader_slack.load()
Load from GitHub Repository Files
from langchain.document_loaders import GitHubRepoLoader
# Load files from a GitHub repository (requires access token)
loader_github = GitHubRepoLoader(repo_url="https://github.com/username/repo", access_token="your_access_token")
docs_github = loader_github.load()
Load from an RSS Feed
from langchain.document_loaders import RSSFeedLoader
# Load recent articles from an RSS feed
feed_url = "https://example.com/rss"
loader_rss = RSSFeedLoader(feed_url)
docs_rss = loader_rss.load()
*Load from Airtable Database
*
from langchain.document_loaders import AirtableLoader
# Load records from an Airtable table (requires API key and table ID)
loader_airtable = AirtableLoader(api_key="your_api_key", base_id="your_base_id", table_name="your_table_name")
docs_airtable = loader_airtable.load()
Example: Combining All Loaded Documents
After loading documents from each source, you may want to combine them into a single list for further processing.
# Combine all documents into one list
all_docs = docs_notion + docs_gdoc + docs_youtube + docs_slack + docs_github + docs_rss + docs_airtable
# Displaying content from each document
for i, doc in enumerate(all_docs):
print(f"Document {i+1} Content:", doc.page_content)
Summary of Sources
Arxiv - Research papers by query or ID.
Web Page - Specific parts of a web page.
Wikipedia - Wikipedia article sections.
Notion - Notion database entries.
Google Docs - Google Docs file content.
YouTube - Transcript from YouTube videos.
Slack - Messages from a Slack channel.
GitHub - Files from a GitHub repository.
RSS Feed - Articles from an RSS feed.
Airtable - Records from an Airtable table.
Extract data specific part from data sources
data = [
{
'title': 'Title of the paper',
'authors': ['Author 1', 'Author 2'],
'abstract': 'This is the abstract of the paper.',
'published': '2017-06-01',
'url': 'https://arxiv.org/abs/1706.03762'
},
{
'title': 'Title of related paper 1',
'authors': ['Author 1', 'Author 2'],
'abstract': 'Abstract for related paper 1.',
'published': '2017-06-02',
'url': 'https://arxiv.org/abs/1706.03763'
},
{
'title': 'Title of related paper 2',
'authors': ['Author 3', 'Author 4'],
'abstract': 'Abstract for related paper 2.',
'published': '2017-06-03',
'url': 'https://arxiv.org/abs/1706.03764'
}
]
all the documents published in 2017
[doc for doc in data if datetime.strptime(doc['published'], '%Y-%m-%d').year == year]
[doc for doc in data if datetime.strptime(doc['published'], '%Y-%m-%d').year == '2017']
documents where "ram" is listed as one of the authors
[doc for doc in data if author_name in doc['authors']]
[doc for doc in data if 'ram'in doc['authors']]
Load Only Titles from Arxiv Papers
from langchain.document_loaders import ArxivLoader
# Load Arxiv documents and extract only titles
docs_arxiv = ArxivLoader(query="1706.03762", load_max_docs=3).load()
titles = [doc.metadata['title'] for doc in docs_arxiv]
print("Arxiv Titles:", titles)
Load Only Content Body from Specific Web Page Sections
from langchain.document_loaders import WebBaseLoader
import bs4
# Load specific parts of a web page (e.g., only main content sections)
loader_web = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_="post-content"))
)
docs_web = loader_web.load()
content_sections = [doc.page_content for doc in docs_web]
print("Web Content Sections:", content_sections)
Load Only Summaries from Wikipedia Articles
docs_wikipedia = [
{
"page_content": "This is the detailed content of the Wikipedia page on the subject.",
"metadata": {"section": "Summary"}
},
{
"page_content": "This content covers another aspect of the topic in more detail.",
"metadata": {"section": "Introduction"}
},
{
"page_content": "This is the section providing a summary of the article, focusing on key facts.",
"metadata": {"section": "Summary"}
}
]
from langchain.document_loaders import WikipediaLoader
# Load Wikipedia articles and extract summaries
docs_wikipedia = WikipediaLoader(query="Generative AI", load_max_docs=2).load()
summaries = [doc.page_content for doc in docs_wikipedia if 'summary' in doc.metadata.get('section', '').lower()]
print("Wikipedia Summaries:", summaries)
Load Only Specific Column from Google Sheets
docs_gsheet = [
{
"page_content": {"A": "This is the content for A", "B": "Content for B"}
},
{
"page_content": {"A": "Another content for A", "C": "Content for C"}
},
{
"page_content": {"B": "Only content for B"}
}
]
from langchain.document_loaders import GoogleSheetsLoader
# Load specific column (e.g., 'A' column) from a Google Sheets document
loader_gsheet = GoogleSheetsLoader(spreadsheet_id="your_spreadsheet_id", credentials_path="path/to/credentials.json")
docs_gsheet = loader_gsheet.load()
column_a = [doc.page_content['A'] for doc in docs_gsheet if 'A' in doc.page_content]
print("Column A Values:", column_a)
Extract Transcripts from YouTube by Section
docs_youtube = [
{
"page_content": "Introduction to Artificial Intelligence.\nAI is revolutionizing industries.\nMachine Learning is a part of AI."
},
{
"page_content": "Deep Learning is a subset of AI.\nAI in healthcare.\nAI ethics and privacy concerns."
},
{
"page_content": "This document does not mention the keyword."
}
]
from langchain.document_loaders import YouTubeLoader
# Load transcripts and extract specific sections by keywords
docs_youtube = YouTubeLoader(video_id="your_video_id").load()
important_sections = [line for doc in docs_youtube for line in doc.page_content.split('\n') if "AI" in line]
print("Important Transcript Sections:", important_sections)
Extract Messages with Specific Keywords from Slack
from langchain.document_loaders import SlackLoader
# Load Slack messages containing specific keywords
loader_slack = SlackLoader(api_token="your_slack_token", channel_id="your_channel_id")
docs_slack = loader_slack.load()
keyword_messages = [doc.page_content for doc in docs_slack if "update" in doc.page_content.lower()]
print("Keyword Messages:", keyword_messages)
output
[
"Introduction to Artificial Intelligence.",
"AI is revolutionizing industries.",
"Machine Learning is a part of AI.",
"Deep Learning is a subset of AI.",
"AI in healthcare.",
"AI ethics and privacy concerns."
]
Load Files from GitHub Repo by File Type (e.g., .md files)
from langchain.document_loaders import GitHubRepoLoader
# Load files from GitHub and filter for only Markdown files
loader_github = GitHubRepoLoader(repo_url="https://github.com/username/repo", access_token="your_access_token")
docs_github = loader_github.load()
markdown_files = [doc.page_content for doc in docs_github if doc.metadata['file_path'].endswith('.md')]
print("Markdown Files Content:", markdown_files)
Load RSS Feed Titles Only
from langchain.document_loaders import RSSFeedLoader
# Load only the titles of articles from an RSS feed
feed_url = "https://example.com/rss"
loader_rss = RSSFeedLoader(feed_url)
docs_rss = loader_rss.load()
titles = [doc.metadata['title'] for doc in docs_rss]
print("RSS Feed Titles:", titles)
Load Specific Fields from Airtable Records (e.g., "Name" field)
from langchain.document_loaders import AirtableLoader
# Load only specific fields from Airtable records
loader_airtable = AirtableLoader(api_key="your_api_key", base_id="your_base_id", table_name="your_table_name")
docs_airtable = loader_airtable.load()
names = [doc.page_content['Name'] for doc in docs_airtable if 'Name' in doc.page_content]
print("Names from Airtable:", names)
Load Specific Headings from PDF Content
from langchain.document_loaders import PyMuPDFLoader
# Load specific headings from a PDF file based on keyword search
loader_pdf = PyMuPDFLoader("path/to/your_file.pdf")
docs_pdf = loader_pdf.load()
headings = [line for doc in docs_pdf for line in doc.page_content.split('\n') if line.strip().endswith(':')]
print("PDF Headings:", headings)
Explanation and Use Cases
Filtering by Field or Metadata: Examples 1, 3, 4, 7, and 9 filter specific fields like titles, summaries, or names based on metadata.
Keyword Extraction: Examples 5, 6, and 10 focus on content sections with certain keywords or formats.
Specific Section Loading: Examples 2 and 8 load only the desired section, such as titles or main content, by targeting specific HTML elements or XML tags.
Extract website part using beautifull soup library
Load Only Main Content by Class Name
from langchain.document_loaders import WebBaseLoader
import bs4
loader = WebBaseLoader(
web_paths=["https://example.com"],
bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_="main-content"))
)
docs_main_content = loader.load()
for doc in docs_main_content:
print("Main Content:", doc.page_content)
Load Only Article Titles and Content by Multiple Classes
loader = WebBaseLoader(
web_paths=["https://example.com/articles"],
bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_=("article-title", "article-content")))
)
docs_articles = loader.load()
for doc in docs_articles:
print("Titles and Content:", doc.page_content)
Load Only Header and Footer Sections
loader = WebBaseLoader(
web_paths=["https://example.com"],
bs_kwargs=dict(parse_only=bs4.SoupStrainer(["header", "footer"]))
)
docs_header_footer = loader.load()
for doc in docs_header_footer:
print("Header and Footer:", doc.page_content)
Load Only Links in Navigation Bar
loader = WebBaseLoader(
web_paths=["https://example.com"],
bs_kwargs=dict(parse_only=bs4.SoupStrainer("a", class_="navbar"))
)
docs_nav_links = loader.load()
nav_links = [a['href'] for doc in docs_nav_links for a in BeautifulSoup(doc.page_content, "html.parser").find_all("a", href=True)]
print("Navbar Links:", nav_links)
Load Only Text from a JavaScript-Rendered Table
from selenium import webdriver
from langchain.document_loaders import WebBaseLoader
import bs4
driver = webdriver.Chrome()
driver.get("https://example.com/table-page")
loader = WebBaseLoader(
web_paths=[driver.page_source],
bs_kwargs=dict(parse_only=bs4.SoupStrainer("table"))
)
docs_table = loader.load()
for doc in docs_table:
print("Table Data:", doc.page_content)
driver.quit()
Load Only Image URLs
loader = WebBaseLoader(
web_paths=["https://example.com"],
bs_kwargs=dict(parse_only=bs4.SoupStrainer("img"))
)
docs_images = loader.load()
image_urls = [img['src'] for doc in docs_images for img in BeautifulSoup(doc.page_content, "html.parser").find_all("img", src=True)]
print("Image URLs:", image_urls)
Load Only Text from Multiple Pages in a Loop
urls = ["https://example.com/page1", "https://example.com/page2", "https://example.com/page3"]
loader = WebBaseLoader(
web_paths=urls,
bs_kwargs=dict(parse_only=bs4.SoupStrainer(["p", "h1", "h2"]))
)
docs_multiple_pages = loader.load()
for i, doc in enumerate(docs_multiple_pages):
print(f"Content of Page {i+1}:", doc.page_content)
Load Only Elements with Specific Attributes
loader = WebBaseLoader(
web_paths=["https://example.com"],
bs_kwargs=dict(parse_only=bs4.SoupStrainer(attrs={"id": "specific-id"}))
)
docs_specific_id = loader.load()
for doc in docs_specific_id:
print("Elements with Specific ID:", doc.page_content)
Click Button and Extract Updated Content (Using Selenium)
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
driver = webdriver.Chrome()
driver.get("https://example.com")
# Click a button to load new content
button = driver.find_element(By.ID, "load-more-button")
button.click()
time.sleep(2) # Wait for content to load
loader = WebBaseLoader(
web_paths=[driver.page_source],
bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_="dynamic-content"))
)
docs_dynamic = loader.load()
for doc in docs_dynamic:
print("Updated Content:", doc.page_content)
driver.quit()
Load Only Dropdown Options
from selenium import webdriver
from selenium.webdriver.support.ui import Select
driver = webdriver.Chrome()
driver.get("https://example.com")
dropdown = Select(driver.find_element(By.ID, "dropdown-menu"))
options = [option.text for option in dropdown.options]
print("Dropdown Options:", options)
# Load the page source to parse any other relevant data from the dropdown
loader = WebBaseLoader(
web_paths=[driver.page_source],
bs_kwargs=dict(parse_only=bs4.SoupStrainer("select"))
)
docs_dropdown = loader.load()
for doc in docs_dropdown:
print("Dropdown Options HTML:", doc.page_content)
driver.quit()
Summary
Each example here combines LangChain’s WebBaseLoader with BeautifulSoup’s SoupStrainer to filter for specific parts of a web page:
Specific classes, tags, or IDs
Links, images, or table data
Content from dynamic sections loaded with JavaScript (using Selenium)
Extract Wikipedia section
WikipediaLoader with Higher Document Limit
from langchain.document_loaders import WikipediaLoader
# Load up to 5 documents about "Machine Learning"
docs = WikipediaLoader(query="Machine Learning", load_max_docs=5).load()
WikipediaLoader with Different Query Term
# Load up to 2 documents on "Artificial Intelligence"
docs = WikipediaLoader(query="Artificial Intelligence", load_max_docs=2).load()
WikipediaLoader with Summary Sections Only
# Load only summary sections of "Deep Learning" with 3 documents max
docs = WikipediaLoader(query="Deep Learning", load_max_docs=3, include_summaries=True).load()
WikipediaLoader with Subsection Inclusion
# Load up to 4 documents, including subsections of "Neural Networks"
docs = WikipediaLoader(query="Neural Networks", load_max_docs=4, include_subsections=True).load()
WebBaseLoader with Different Web Page and Class Filter
from langchain.document_loaders import WebBaseLoader
import bs4
# Load only the title and content from another blog page
loader = WebBaseLoader(
web_paths=["https://example.com/another-post"],
bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_=("post-title", "post-content")))
)
docs = loader.load()
WebBaseLoader with Specific Tags (Header and Footer Only)
# Load only header and footer sections
loader = WebBaseLoader(
web_paths=["https://example.com/page"],
bs_kwargs=dict(parse_only=bs4.SoupStrainer(["header", "footer"]))
)
docs = loader.load()
WebBaseLoader with Multiple Pages
# Load from multiple web pages, extracting only article content
loader = WebBaseLoader(
web_paths=["https://example.com/article1", "https://example.com/article2"],
bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_="article-content"))
)
docs = loader.load()
WebBaseLoader with ID Filter
# Load a specific section identified by an HTML ID
loader = WebBaseLoader(
web_paths=["https://example.com/special-article"],
bs_kwargs=dict(parse_only=bs4.SoupStrainer(id="important-section"))
)
docs = loader.load()
WebBaseLoader with Multiple Classes and Custom Tags
# Load post title, date, and content from a blog post
loader = WebBaseLoader(
web_paths=["https://blog.example.com/post"],
bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_=("post-title", "post-date", "post-content")))
)
docs = loader.load()
WikipediaLoader with Content Sections Only
# Load content sections only from "Large Language Models" page, max 3 documents
docs = WikipediaLoader(query="Large Language Models", load_max_docs=3, include_summaries=False
Common Parameters Across Different Data Loaders
query(WikipediaLoader, ArxivLoader, etc.)
Description: Specifies the search term or query to retrieve specific documents.
Example: query="Machine Learning"
load_max_docs(WikipediaLoader, ArxivLoader, GoogleSheetsLoader, etc.)
Description: Limits the maximum number of documents to load.
Example: load_max_docs=5
include_summaries(WikipediaLoader)
Description: If True, only summary sections are loaded.
Example: include_summaries=True
include_subsections(WikipediaLoader, ArxivLoader)
Description: Loads subsections in addition to main sections.
Example: include_subsections=True
web_paths(WebBaseLoader)
Description: Specifies a list of URLs to load content from.
Example: web_paths=["https://example.com/page1", "https://example.com/page2"]
bs_kwargs(WebBaseLoader)
Description: Dictionary of BeautifulSoup options for filtering specific sections of HTML.
Example: bs_kwargs=dict(parse_only=bs4.SoupStrainer("div", class_="content"))
parse_only(used within bs_kwargs in WebBaseLoader)
Description: Filters HTML to parse only specific tags, classes, or IDs.
Example: parse_only=SoupStrainer(["h1", "h2", "p"])
output_format(Some loaders like JSONLoader or CSVLoader)
Description: Specifies the format of the output (e.g., dict, json).
Example: output_format="json"
table_name(SQLDatabaseLoader, AirtableLoader)
Description: The name of the table to query or load data from.
Example: table_name="users"
credentials_path (GoogleSheetsLoader, GoogleDriveLoader)
Description: Path to the credentials file for Google-based loaders.
Example: credentials_path="path/to/credentials.json"
Advanced Parameters for Specific Data Loaders
column_names(CSVLoader, GoogleSheetsLoader)
Description: Specifies which columns to load from the CSV or Google Sheets document.
Example: column_names=["Title", "Summary"]
api_key(Some loaders like AirtableLoader, SlackLoader, and OpenAI-based loaders)
Description: API key for authentication with third-party services.
Example: api_key="your_api_key_here"
file_id(GoogleDriveLoader, YouTubeLoader)
Description: The ID of the file to load from Google Drive or YouTube.
Example: file_id="your_file_id"
database_id (NotionLoader, AirtableLoader)
Description: ID of the database to load content from.
Example: database_id="notion_database_id"
section_filter(WikipediaLoader, ArxivLoader)
Description: Filters specific sections within a document (e.g., "Abstract," "Introduction").
Example: section_filter=["Introduction", "Conclusion"]
keywords(SlackLoader, RSSFeedLoader)
Description: Filters messages or articles based on specific keywords.
Example: keywords=["update", "meeting"]
chunk_size(TextLoader, TextSplitter, other loaders)
Description: Specifies the number of characters or tokens per chunk when splitting text.
Example: chunk_size=500
content_filter(WikipediaLoader, WebBaseLoader)
Description: Filters content based on keywords or topics.
Example: content_filter="AI"
load_comments(RedditLoader, DiscourseLoader)
Description: If True, loads comments or responses in addition to main content.
Example: load_comments=True
time_range(RSSFeedLoader, TwitterLoader)
Description: Specifies a time range to filter content by date.
Example: time_range=("2023-01-01", "2023-12-31")
query (WikipediaLoader, ArxivLoader, etc.)
Description: Specifies the topic or search term for documents.
Example: Loading documents on "Machine Learning."
from langchain.document_loaders import WikipediaLoader
docs = WikipediaLoader(query="Machine Learning", load_max_docs=1).load()
print(docs[0].page_content)
Output:
"Machine learning is a field of computer science focused on enabling computers to learn from data..."
load_max_docs (WikipediaLoader, ArxivLoader, etc.)
Description: Limits the number of documents loaded.
Example: Loading 2 documents on "Artificial Intelligence."
docs = WikipediaLoader(query="Artificial Intelligence", load_max_docs=2).load()
print(len(docs))
Output:
2 # Two documents loaded.
include_summaries (WikipediaLoader)
Description: Loads only summary sections if True.
Example: Loading summaries of "Deep Learning."
docs = WikipediaLoader(query="Deep Learning", load_max_docs=1, include_summaries=True).load()
print(docs[0].page_content)
Output:
"Deep learning is a subset of machine learning that uses neural networks with many layers..."
include_subsections (WikipediaLoader)
Description: Loads subsections within the main document.
Example: Loading document on "Neural Networks" with subsections.
docs = WikipediaLoader(query="Neural Networks", load_max_docs=1, include_subsections=True).load()
print(docs[0].page_content)
Output:
"Neural Networks: ...\nApplications: ...\nTypes of Networks: ..."
web_paths (WebBaseLoader)
Description: Specifies URLs to load data from.
Example: Loading content from a webpage.
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader(web_paths=["https://example.com"])
docs = loader.load()
print(docs[0].page_content)
Output:
"Welcome to Example.com! Here you'll find articles and resources on various topics..."
bs_kwargs (WebBaseLoader)
Description: BeautifulSoup options for filtering HTML content.
Example: Extracting only paragraph (p) tags.
import bs4
loader = WebBaseLoader(
web_paths=["https://example.com"],
bs_kwargs=dict(parse_only=bs4.SoupStrainer("p"))
)
docs = loader.load()
print(docs[0].page_content)
Output:
"This is the main content of the webpage in paragraph form."
- parse_only (within bs_kwargs) Description: Filters HTML by specific tags or classes. Example: Loading content from headers and paragraphs only.
loader = WebBaseLoader(
web_paths=["https://example.com"],
bs_kwargs=dict(parse_only=bs4.SoupStrainer(["h1", "p"]))
)
docs = loader.load()
print(docs[0].page_content)
Output:
"Example.com - Your source for news.\nToday's main article discusses..."
output_format (JSONLoader, CSVLoader, etc.)
Description: Specifies output format, like dict or json.
Example: Loading a JSON document.
from langchain.document_loaders import JSONLoader
loader = JSONLoader("path/to/data.json", output_format="dict")
docs = loader.load()
print(docs)
Output:
{'title': 'Introduction to JSON', 'content': 'JSON is a lightweight data format...'}
table_name (SQLDatabaseLoader, AirtableLoader)
Description: The name of the table to load data from.
Example: Loading data from a "users" table in SQL.
from langchain.document_loaders import SQLDatabaseLoader
from sqlalchemy import create_engine
engine = create_engine("sqlite:///mydatabase.db")
loader = SQLDatabaseLoader(engine, table_name="users")
docs = loader.load()
print(docs[0].page_content)
Output:
{'id': 1, 'name': 'John Doe', 'email': 'john@example.com'}
credentials_path (GoogleSheetsLoader, GoogleDriveLoader)
Description: Path to the credentials file for Google services.
Example: Loading data from Google Sheets.
from langchain.document_loaders import GoogleSheetsLoader
loader = GoogleSheetsLoader(spreadsheet_id="your_spreadsheet_id", credentials_path="path/to/credentials.json")
docs = loader.load()
print(docs[0].page_content)
Output:
{'Name': 'Alice', 'Age': '30', 'Occupation': 'Engineer'}
column_names (CSVLoader, GoogleSheetsLoader)
Description: Specifies which columns to load.
Example: Loading only "Title" and "Summary" columns.
from langchain.document_loaders import CSVLoader
loader = CSVLoader("data.csv", column_names=["Title", "Summary"])
docs = loader.load()
print(docs[0].page_content)
Output:
{'Title': 'Introduction to AI', 'Summary': 'This article covers basics of AI...'}
api_key (AirtableLoader, SlackLoader)
Description: API key for authentication with services.
Example: Loading records from Airtable.
from langchain.document_loaders import AirtableLoader
loader = AirtableLoader(api_key="your_api_key", base_id="app123456", table_name="Projects")
docs = loader.load()
print(docs[0].page_content)
Output:
{'Project Name': 'AI Research', 'Status': 'In Progress'}
file_id (GoogleDriveLoader, YouTubeLoader)
Description: The ID of the file to load (e.g., Google Drive).
Example: Loading a file from Google Drive.
from langchain.document_loaders import GoogleDriveLoader
loader = GoogleDriveLoader(file_id="your_file_id", credentials_path="path/to/credentials.json")
docs = loader.load()
print(docs[0].page_content)
Output:
"This is the document content from Google Drive."
database_id (NotionLoader)
Description: ID of the database to load from (Notion).
Example: Loading records from a Notion database.
from langchain.document_loaders import NotionLoader
loader = NotionLoader(database_id="your_notion_database_id", integration_token="your_integration_token")
docs = loader.load()
print(docs[0].page_content)
Output:
{'Task': 'Complete Project', 'Status': 'In Progress'}
section_filter (WikipediaLoader, ArxivLoader)
Description: Filters specific sections like "Abstract."
Example: Loading only "Introduction" and "Conclusion."
docs = WikipediaLoader(query="Machine Learning", load_max_docs=1, section_filter=["Introduction", "Conclusion"]).load()
print(docs[0].page_content)
Output:
"Introduction: Machine learning is... Conclusion: In summary, machine learning..."
keywords (SlackLoader)
Description: Filters messages based on keywords.
Example: Loading messages with "meeting."
from langchain.document_loaders import SlackLoader
loader = SlackLoader(api_token="your_slack_token", channel_id="your_channel_id", keywords=["meeting"])
docs = loader.load()
print(docs[0].page_content)
Output:
"We have a team meeting scheduled for tomorrow."
chunk_size (TextLoader)
Description: Specifies chunk size for splitting text.
Example: Splitting text into 300-character chunks.
from langchain.text_splitter import CharacterTextSplitter
text = "This is a long document that needs to be split into smaller chunks..."
splitter = CharacterTextSplitter(chunk_size=300)
chunks = splitter.split_text(text)
print(chunks)
Output:
["This is a long document that needs...", "Here is another chunk of text..."]
Extract you tube data
Load Only the Video Transcript
Description: Loads only the video transcript.
Example: Loading the transcript of a YouTube video.
from langchain.document_loaders import YouTubeLoader
loader = YouTubeLoader(video_id="your_video_id", load_transcript=True)
docs = loader.load()
for doc in docs:
print("Transcript Content:", doc.page_content)
Output:
"In this video, we’ll explore the basics of machine learning, starting with supervised learning..."
Load Video Transcript and Comments
Description: Loads both transcript and comments if load_comments=True.
Example: Loading transcript and top comments.
loader = YouTubeLoader(video_id="your_video_id", load_transcript=True, load_comments=True)
docs = loader.load()
for doc in docs:
print("Transcript:", doc.page_content)
for comment in doc.metadata.get("comments", []):
print("Comment:", comment)
Output:
Transcript: "In this video, we’ll explore the basics of machine learning..."
Comment: "Great explanation on supervised learning!"
Comment: "Could you make a video on reinforcement learning next?"
Load Transcript with Specific Keyword Filter
Description: Loads only parts of the transcript containing certain keywords.
Example: Filtering transcript for sections mentioning "AI."
loader = YouTubeLoader(video_id="your_video_id", load_transcript=True, content_filter="AI")
docs = loader.load()
for doc in docs:
print("AI Mentions in Transcript:", doc.page_content)
Output:
"AI is transforming industries by enabling machines to make decisions autonomously..."
Load Video Metadata Only
Description: Loads metadata such as title, description, views, and likes.
Example: Loading only metadata without transcript or comments.
loader = YouTubeLoader(video_id="your_video_id", load_transcript=False, load_comments=False, load_metadata=True)
docs = loader.load()
for doc in docs:
print("Video Title:", doc.metadata["title"])
print("Description:", doc.metadata["description"])
print("Views:", doc.metadata["views"])
print("Likes:", doc.metadata["likes"])
Output:
Video Title: "Introduction to Machine Learning"
Description: "This video covers the basics of machine learning."
Views: 15230
Likes: 1345
Load Comments within a Specific Time Range
Description: Filters comments by a specific time range.
Example: Loading comments posted between June and August 2023.
loader = YouTubeLoader(video_id="your_video_id", load_comments=True, time_range=("2023-06-01", "2023-08-31"))
docs = loader.load()
for doc in docs:
print("Transcript:", doc.page_content)
for comment in doc.metadata.get("comments", []):
print("Comment:", comment)
Output:
Comment: "Fantastic explanation, learned a lot from this video!" # Comment posted in the specified time range.
Load Transcript in a Specific Language
Description: Loads the transcript in a specified language.
Example: Loading the transcript in French (if available).
loader = YouTubeLoader(video_id="your_video_id", load_transcript=True, language="fr")
docs = loader.load()
for doc in docs:
print("French Transcript:", doc.page_content)
Output:
"Dans cette vidéo, nous explorons les bases de l'apprentissage automatique..."
Load Only Transcript Sections with Specific Phrases
Description: Filters transcript to include only specific phrases or sections.
Example: Extracting sections mentioning "neural networks."
loader = YouTubeLoader(video_id="your_video_id", load_transcript=True, content_filter="neural networks")
docs = loader.load()
for doc in docs:
print("Neural Network Mentions:", doc.page_content)
Output:
"Neural networks are a type of machine learning model that mimics the human brain..."
Load Transcript and Like/Dislike Counts in Metadata
Description: Loads transcript along with like and dislike counts from metadata.
Example: Loading transcript with metadata fields.
loader = YouTubeLoader(video_id="your_video_id", load_transcript=True, load_metadata=True)
docs = loader.load()
for doc in docs:
print("Transcript:", doc.page_content)
print("Likes:", doc.metadata["likes"])
print("Dislikes:", doc.metadata["dislikes"])
Output:
Transcript: "In this video, we explore various types of AI models..."
Likes: 1500
Dislikes: 30
Load Top-Level Comments Only
Description: Loads only top-level comments (no replies).
Example: Loading only top-level comments without transcript.
loader = YouTubeLoader(video_id="your_video_id", load_transcript=False, load_comments=True)
docs = loader.load()
for doc in docs:
for comment in doc.metadata.get("comments", []):
print("Top-Level Comment:", comment)
Output:
Top-Level Comment: "Great video, very informative!"
Load Only Replies to a Specific Comment
Description: Loads replies to a specific comment if load_comments=True.
Example: Loading replies to a specific comment on the video.
loader = YouTubeLoader(video_id="your_video_id", load_transcript=False, load_comments=True)
docs = loader.load()
for doc in docs:
for comment in doc.metadata.get("comments", []):
print("Comment:", comment["text"])
for reply in comment.get("replies", []):
print("Reply:", reply)
Output:
Comment: "Could you explain reinforcement learning in detail?"
Reply: "Sure! Reinforcement learning is a type of machine learning where agents learn by interacting with an environment."
Summary
video_id: Unique ID of the YouTube video.
load_transcript: Loads the video transcript.
load_comments: Loads comments, including replies.
time_range: Filters comments by date.
language: Specifies the transcript language.
content_filter: Filters for specific keywords in the transcript.
load_metadata: Loads metadata fields (e.g., title, views, likes).
SUMMARY
TextLoader('speech.txt').loader.load()||CSVLoader||PyMuPDFLoader
JSONLoader("example.json", jq_schema=".text").load()
for doc in documents:==>print(doc.page_content)
UnstructuredURLLoader(urls=urls).load()
UnstructuredHTMLLoader("path/to/your_file.html")
UnstructuredWordDocumentLoader("path/to/your_file.docx")
UnstructuredEmailLoader("path/to/your_file.eml")
S3Loader(bucket_name="your-bucket-name", key="path/to/your_file.txt")
GoogleSheetsLoader(spreadsheet_id="your-spreadsheet-id", credentials_path="path/to/credentials.json")
Image.open("path/to/image.png")
SQLDatabaseLoader(engine, table_name="your_table_name")
RESTAPILoader(url=url, headers=headers)
GoogleDriveLoader(file_id="your_file_id", credentials_path="path/to/credentials.json")
MongoDBLoader(connection_string="mongodb://localhost:27017",database="your_database",collection="your_collection")
DynamoDBLoader(table_name="your_table_name", aws_access_key="your_key", aws_secret_key="your_secret"GCSLoader)
||SnowflakeLoader||ElasticsearchLoader||RSSFeedLoader||WebBaseLoader||WikipediaLoader||YouTubeLoader||SlackLoader
docs_arxiv = ArxivLoader(query="1706.03762", load_max_docs=2).load()
alldoc = docs_arxiv + docs_web + docs_wikipedia
for i, doc in enumerate(alldoc):==>print(f"Document {i+1} Content:", doc.page_content)
Extract data specific part from data sources================
docs_arxiv = ArxivLoader(query="1706.03762", load_max_docs=2).load()
docs_arxiv = [
{
"metadata": {
"title": "A Comprehensive Study on AI",
"authors": ["Author 1", "Author 2"],
"published": "2024-11-01"
},
"content": "Detailed content of the paper about AI..."
},
{
"metadata": {
"title": "Introduction to Machine Learning",
"authors": ["Author 3", "Author 4"],
"published": "2023-06-15"
},
"content": "Detailed content about machine learning concepts..."
}
]
titles = [doc.metadata['title'] for doc in docs_arxiv]
[doc.page_content for doc in docs_wikipedia if 'summary' in doc.metadata.get('section', '').lower()]
docs_gsheet = [
{
"page_content": {"A": "This is the content for A", "B": "Content for B"}
},
{
"page_content": {"A": "Another content for A", "C": "Content for C"}
},
{
"page_content": {"B": "Only content for B"}
}
]
[doc.page_content['A'] for doc in docs_gsheet if 'A' in doc.page_content]
docs_youtube = [
{
"page_content": "Introduction to Artificial Intelligence.\nAI is revolutionizing industries.\nMachine Learning is a part of AI."
},
{
"page_content": "Deep Learning is a subset of AI.\nAI in healthcare.\nAI ethics and privacy concerns."
},
{
"page_content": "This document does not mention the keyword."
}
]
important_sections = [line for doc in docs_youtube for line in doc.page_content.split('\n') if "AI" in line]
output
[
"Introduction to Artificial Intelligence.",
"AI is revolutionizing industries.",
"Machine Learning is a part of AI.",
"Deep Learning is a subset of AI.",
"AI in healthcare.",
"AI ethics and privacy concerns."
]
docs_github = [
{
'metadata': {'file_path': 'docs/intro.md'},
'page_content': 'This is the content of the markdown file.'
},
{
'metadata': {'file_path': 'docs/guide.txt'},
'page_content': 'This is a text file.'
}
]
markdown_files = [doc.page_content for doc in docs_github if doc.metadata['file_path'].endswith('.md')]
docs_pdf = [
{
'page_content': 'This is a title:\nThis is a description.'
},
{
'page_content': 'Another heading:\nThis is more content.'
}
]
headings = [line for doc in docs_pdf for line in doc.page_content.split('\n') if line.strip().endswith(':')]
output
[
'This is a title:',
'Another heading:'
]
Extract website part using beautifull soup library==============
Main Content by Class Name||Only Article Titles and Content by Multiple Classes|| Header and Footer Sections
Links in Navigation Bar|| Image URLs||Text from Multiple Pages in a Loop(h1,p)||Specific Attributes||dropdown||

Top comments (0)