Imagine your entire data infrastructure suddenly grinding to a screeching halt because a hardcoded rules engine failed to predict a massive spike in consumer transaction volume. Traditional software structures require manual updates for every new variable, creating an operational bottleneck that stalls business growth. Consequently, modern engineering teams are abandoning rigid legacy code in favor of dynamic learning models to maintain operational agility at scale.
This specific shift from manual rule creation to automated data adaptation represents the core power of modern data science. This extensive resource breaks down everything you need to build, evaluate, and scale these intelligent models effectively. By mastering these principles, your technical teams can predict anomalies, automate complex decision-making frameworks, and ensure continuous system reliability across distributed environments.
Throughout this guide, we will analyze the history of systemic automation, map out foundational predictive architectures, and explore real-world deployment methodologies. We will also detail the crucial metrics required to monitor model health and performance over time. Therefore, you will gain a complete understanding of how to transition from traditional operations to data-driven system management.
Ready to transform your engineering career and master these predictive frameworks under expert mentorship? Start your technical journey today by exploring the comprehensive educational resources available at Debug.school.
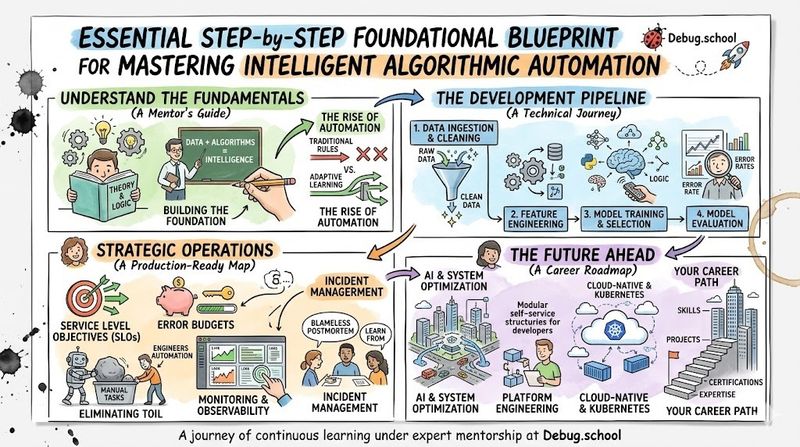
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
Historically, early enterprise computing architectures relied heavily on deterministic software patterns where engineers explicitly programmed every single logical condition. However, as business requirements expanded, maintaining these massive, interconnected codebases became an operational nightmare. Siloed engineering teams struggled constantly to update thousands of manual rules, which inevitably resulted in fragile deployments and frequent production outages.
Furthermore, static infrastructure configurations could not adapt dynamically to shifting user behaviors or fluctuating resource workloads. Because data streams grew increasingly complex, manual code adjustments simply could not keep pace with real-time operational demands. This operational bottleneck highlighted the critical need for a new paradigm that allowed software setups to learn independently from historical patterns.
Moving Toward Unified Workflow Automation
To resolve these growing bottlenecks, pioneering organizations began unifying development workflows and integrating automated data pipes directly into their core operational structures. This cultural transformation helped break down the walls between isolated teams, allowing for continuous integration and rapid algorithmic testing. As a result, companies replaced brittle, hardcoded parameters with automated data loops that refined themselves through continuous feedback.
Subsequently, infrastructure management evolved from a reactive chore into a proactive engineering discipline focused on system scalability. Teams discovered that treating data patterns as code allowed them to build more resilient, self-healing software ecosystems. This shift laid the groundwork for deploying advanced pattern recognition systems directly into large-scale IT operations.
Global Expansion Across Commercial Ecosystems
Once enterprise tech leaders demonstrated the immense value of automated workflows, this progressive operational philosophy spread rapidly across global commercial networks. Today, massive digital platforms leverage these adaptive data models to optimize global supply chains, manage cloud computing resources, and secure digital networks. What began as a localized attempt to fix rigid codebases has now grown into a standard global framework for enterprise technology management.
Defining Strategic Operations Management
The Core Operational Structure
The foundational architecture of an intelligent predictive framework relies on a continuous, multi-staged information pipeline that transforms raw inputs into actionable business intelligence. Initially, data ingestion layers collect diverse information streams from distributed microservices, application logs, and system metrics. Following ingestion, preprocessing components clean, normalize, and format this raw data to remove corrupt or irrelevant entries.
| Pipeline Phase | Primary Technical Objective | Expected Engineering Outcome |
|---|---|---|
| Ingestion & Logging | Consolidate distributed data streams | Unified raw repository |
| Preprocessing & Cleansing | Eliminate structural anomalies and noise | Normalized training sets |
| Model Training & Evaluation | Execute iterative matrix computations | Validated algorithmic weights |
| Production Deployment | Serve predictions via scalable microservices | Low-latency inference endpoints |
Next, the structured datasets pass into the core training environment, where algorithms iteratively compute statistical weights and optimize predictive accuracy. Once the model achieves performance targets, deployment systems package the artifact into a scalable container for real-time inference. Finally, continuous monitoring tools trace data paths and evaluate live outputs to ensure long-term operational stability.
Daily Tasks of Systems Coordinators
Engineers specializing in automated intelligence manage a highly dynamic set of daily operational responsibilities to keep production pipelines functioning efficiently. Consequently, they spend a large portion of their day optimizing training infrastructure, tuning hyperparameters, and validating data integrity.
- Auditing incoming data streams to identify and eliminate systemic bias or corrupt logs.
- Configuring scalable GPU clusters to accelerate deep learning training jobs.
- Writing automated testing scripts to validate model accuracy before production rollouts.
- Collaborating closely with software developers to embed inference endpoints into microservices.
- Monitoring model latency and resource consumption across live containerized environments.
- Troubleshooting prediction anomalies and implementing rollback procedures during unexpected outages.
Localized Control vs. Broad System Architecture
Managing an intelligent infrastructure requires a careful balance between tracking individual algorithmic parameters and monitoring the entire multi-system architecture. Granular control focus areas involve fine-tuning specific model weights, adjusting localized learning rates, and auditing feature engineering components. While this precise optimization ensures individual model accuracy, it must align seamlessly with broader systemic performance goals.
On the other hand, macro-level systems architecture oversees how these distributed models interact with core network databases, storage clusters, and user applications. If a single predictive model experiences high latency, it can trigger a domino effect that impacts the entire enterprise platform. Therefore, modern teams must monitor localized behavioral metrics alongside total system resource utilization to prevent widespread operational failures.
The Efficiency Mindset
Transitioning to data-driven operations requires a cultural shift that prioritizes long-term system stability over short-term manual fixes. Instead of manually resolving individual application alerts, engineers focus on building automated workflows that address the root cause of systemic issues. This efficiency mindset drives teams to treat every operational failure as an opportunity to train better predictive models and refine automation loops.
The 7 Core Principles of Beginner’s Guide to Machine Learning at Debug.school
1. Embracing Risk and Managing Variability
Modern systems engineering operates on the absolute reality that achieving zero systemic risk or perfect uptime is mathematically impossible. Because real-world data environments are inherently volatile, teams must design infrastructure to accept and manage a certain degree of operational variability. By acknowledging that models will occasionally produce errors, engineers can build resilient fallback mechanisms that protect the core customer experience.
2. Establishing Service Level Objectives (SLOs)
To maintain consistent system health, engineering teams must establish clear, measurable targets for performance and reliability. These quantified objectives define the acceptable boundaries for model latency, prediction accuracy, and resource utilization across the infrastructure. By tracking live metrics against these strict operational targets, businesses can make data-driven decisions about when to deploy new models or freeze updates.
3. Eliminating Toil and Manual Processes
Repetitive, manual tasks that lack long-term engineering value can severely stall operational velocity and exhaust human engineering resources. Therefore, a core principle of modern operations involves identifying these repetitive workflows and systematically designing them away through code automation. By engineering out manual data preparation and script execution, teams free up valuable time to focus on complex architectural innovations.
4. Monitoring & Observability Across the Pipeline
Complete visibility across the entire data lifecycle is absolutely essential for preventing critical blind spots within modern software deployments. Engineers achieve this deep observability by collecting comprehensive system logs, execution traces, and performance metrics from every pipeline phase. This continuous stream of operational telemetry allows teams to quickly isolate performance bottlenecks and diagnose model degradation issues before they impact end-users.
5. Automation Over Manual Coordination
Relying on manual human communication to coordinate deployments or scale infrastructure is highly inefficient and prone to catastrophic errors. Instead, modern platforms leverage intelligent software solutions to automate release pipelines, resource provisioning, and container orchestration. This systemic reliance on code-driven orchestration ensures that deployments remain completely repeatable, consistent, and safe at any scale.
6. Release Engineering and Deployment Stability
Safe and predictable application delivery requires a structured, highly disciplined approach to release engineering and version control. Teams must treat model weights, training configurations, and data preprocessing schemas exactly like production software source code. By enforcing automated testing, gradual canary rollouts, and rapid rollback strategies, organizations can introduce innovative features without threatening baseline system safety.
7. Simplicity in Network Architecture
Complex, over-engineered infrastructure environments significantly increase failure surfaces and make troubleshooting incredibly difficult for engineering teams. Because intricate systems hide underlying bugs, keeping network architectures clean, modular, and minimal directly reduces operational risk. By prioritizing simple data paths and clear service interfaces, teams can maintain high system reliability and accelerate incident response times.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Understanding the distinct relationships between Service Level Agreements, Objectives, and Indicators is vital for managing system reliability effectively.
- Service Level Agreement (SLA): A formal, legally binding commitment made directly to external customers regarding overall service uptime and performance guarantees.
- Service Level Objective (SLO): A strict, target reliability metric used internally by engineering teams to measure system health and guide operational priorities.
- Service Level Indicator (SLI): A precise, real-time measurement that quantifies the current performance of a specific system component, such as API latency.
Error Budgets — The Game Changer for Operational Risk
An error budget represents the exact amount of system unreliability that an engineering team is allowed to accumulate over a specific timeframe. Calculated directly as $100\% - \text{SLO}$, this metric serves as a dynamic balancing mechanism between rapid structural innovation and baseline system safety. When a platform maintains a healthy error budget, development teams can aggressively deploy experimental models and innovative code updates.
However, if unexpected outages or performance drops completely consume the allocated error budget, the engineering team must pause all new feature releases. During this deployment freeze, resources shift entirely toward improving infrastructure stability, refining model accuracy, and resolving architectural bugs. This quantitative approach effectively removes emotional debate from operational decision-making, ensuring that system reliability always remains a top priority.
Toil — The Silent Productivity Killer in Infrastructure
Toil defines any operational work that is repetitive, manual, easily automatable, and scales linearly with growing service volumes. Left unchecked, manual toil creates massive operational debt, drains engineering morale, and blocks teams from completing strategic project work.
Total Engineering Time = Strategic Project Work (High Value) + Operational Toil (Manual Tasks)
To eliminate this productivity killer, teams must continuously audit their workflows, track time spent on manual scripts, and write automation code.
Incident Management & Postmortems
When a major production failure inevitably happens, a healthy engineering culture relies on blameless postmortems to uncover root systemic vulnerabilities. Instead of pointing fingers at individual human errors, teams meticulously analyze the underlying process gaps, monitoring failures, or code bugs that allowed the incident to occur. This open approach ensures that engineers document every system failure completely, turning unexpected production outages into invaluable lessons for future optimization.
Capacity Planning
Capacity planning is the highly strategic process of forecasting future data processing demands and preparing system infrastructure well ahead of time. By analyzing historical traffic trends and seasonal growth patterns, teams can calculate exactly when cloud storage clusters or compute nodes will require scaling. This proactive approach prevents sudden resource exhaustion events, optimizes cloud infrastructure costs, and ensures smooth performance during unexpected customer traffic spikes.
The Four Golden Signals of Pipeline Performance
To maintain complete observability over distributed learning environments, teams must track the four foundational metrics of system performance.
| Golden Signal | Technical Metric Definition | Operational Mitigation Strategy |
|---|---|---|
| Latency | Time taken to service a request ($ms$) | Optimize algorithmic execution paths |
| Traffic | Total demand placed on the system | Dynamically scale active compute nodes |
| Errors | Rate of requests that fail structurally | Trigger automated container rollbacks |
| Saturation | Fraction of system resources utilized | Provision additional cloud infrastructure |
Platform Implementation vs. Culture — What's the Real Difference?
The Philosophy Difference
Many organizations frequently confuse high-level cultural frameworks with the concrete technical implementations required to run reliable production systems. High-level frameworks provide broad organizational values that encourage collaboration, open communication, and shared responsibility across different engineering teams. While these cultural guiding concepts are incredibly valuable, they do not provide the explicit technical tooling or metrics needed to manage complex data systems.
In contrast, concrete technical implementations provide the highly specific engineering methodologies, algorithmic architectures, and measurement tools required for daily operations. This structured approach applies rigorous software engineering principles directly to infrastructure management, using quantitative data to enforce operational goals. Therefore, culture sets the collaborative mindset, while implementation delivers the technical discipline needed to build scalable solutions.
Roles & Responsibilities Compared
While both paradigms focus on improving the software lifecycle, their day-to-day operational execution and core focus areas differ significantly.
- Cultural Automation Frameworks: Focus primarily on breaking down organizational silos, improving cross-team communication, and accelerating overall business delivery speed.
- Technical Implementation Systems: Concentrate on writing automated code to manage infrastructure, monitoring pipeline health, and managing error budgets.
- Deployment Ownership: Cultural frameworks share deployment responsibilities broadly, whereas technical specialists build the automated deployment platforms.
- Incident Response Duties: General frameworks encourage collective ownership during outages, while technical implementation teams establish exact on-call rotations and blameless analysis procedures.
Can You Have Both Disciplines?
Modern enterprise technology organizations do not view these two paradigms as mutually exclusive alternatives, but rather as deeply complementary philosophies. A healthy engineering culture creates the psychological safety needed to run blameless postmortems and share data across traditional team boundaries. Simultaneously, technical implementation practices provide the precise metrics, automated tools, and pipeline structures required to realize that cultural vision.
Which One Should Your Team Adopt?
Choosing where to focus your engineering resources depends heavily on your current organizational size and technical maturity level. Small startups with simple application setups should prioritize establishing a collaborative culture and automating basic build pipelines early on. However, as an enterprise grows and begins managing hundreds of complex microservices, it must adopt strict technical implementation methodologies to maintain infrastructure stability.
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Global technology leaders leverage advanced data tracking systems to monitor thousands of live algorithmic parameters and application endpoints simultaneously. By analyzing continuous telemetry streams, these companies can automatically detect subtle micro-anomalies that indicate model drift or system degradation. This automated detection allows infrastructure platforms to initiate self-healing protocols, optimize database queries, and redirect network traffic before users notice any performance lag.
Chaos Engineering Approaches to Resilient Systems
To guarantee absolute system resilience, modern engineering teams intentionally inject controlled failures into their production networks using chaos engineering practices. By systematically shutting down compute nodes, inducing network latency, or corrupting data streams, teams can actively test how their models respond to stress. This proactive experimentation uncovers hidden architectural flaws, validates automated recovery scripts, and ensures that distributed applications remain highly resilient under catastrophic conditions.
Handling Reliability at Massive Scale
Distributed microservice architectures processing millions of global data points per second require highly specialized load-balancing and caching systems to survive. When a specific regional data center experiences an unexpected hardware failure, automated orchestration engines instantly reroute incoming queries to healthy clusters. This dynamic resource reallocation prevents widespread regional service outages, ensuring that global consumer applications maintain continuous availability without manual intervention.
High-Availability in Fintech Operations
Financial technology platforms operate within high-stakes environments that have a absolute zero-tolerance policy for system downtime, data corruption, or prediction latency. Because a delay of a few milliseconds can result in millions of dollars in lost transactions, these platforms enforce rigorous high-availability architectures. By deploying multi-region model replicas and instantaneous failover protocols, fintech systems protect transaction integrity and maintain strict compliance with global financial regulations.
Scaled-Down but Essential Systems for Startups
Early-stage technology startups often lack the massive engineering budgets or extensive infrastructure resources enjoyed by global tech giants. However, these agile teams can still successfully apply core reliability principles by using lean, managed open-source cloud services. By setting up basic automated alerts, clear internal SLOs, and simple container configurations, startups can prevent catastrophic outages while remaining focused on product innovation.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
A common operational error involves treating reliability specialists as a traditional IT support team that simply reacts to production alerts. If engineers spend their entire day manually fixing recurring server issues, they cannot write the code needed to automate those problems away. This reactive pattern leaves infrastructure fragile, burns out engineering talent, and completely ignores the core goal of building self-healing software systems.
Mistake 2 — Setting Unrealistic SLOs
Many engineering managers mistakenly demand perfect $100\%$ uptime for their applications, believing that higher reliability is always better for business. However, chasing absolute perfection completely stalls feature velocity because development teams must freeze deployments at the slightest hint of system variance. Furthermore, achieving extreme uptime targets requires massive infrastructure investments that offer minimal marginal value to the actual end-user experience.
Mistake 3 — Ignoring Toil Until It's Too Late
When engineering organizations scale rapidly without automating repetitive processes, they accumulate a dangerous amount of operational debt. Manual data preparation scripts, manual configuration changes, and manual system patches quickly overwhelm daily engineering schedules. If teams ignore this growing wave of toil, they eventually lose the capacity to work on strategic architectural projects, completely stalling long-term business innovation.
Mistake 4 — Skipping Blameless Postmortems
When a company fosters a culture of blame, engineers instinctively hide their mistakes, obscure root causes, and avoid experimenting with innovative systems. Consequently, the organization continues to suffer from the exact same technical vulnerabilities over and over again without ever fixing the root architectural flaws. Skipping comprehensive, blameless postmortems dooms an enterprise to repeat past failures, severely limiting long-term system optimization and cultural growth.
Mistake 5 — Monitoring Without Actionable Alerts
Flooding engineering communication channels with thousands of non-actionable notifications creates severe alert fatigue across your technical teams. When low-priority informational alerts trigger the same emergency alarms as critical system outages, engineers quickly learn to ignore notifications entirely. Therefore, every single alert configured in your monitoring ecosystem must point directly to a clear, actionable problem that requires immediate human engineering intervention.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Separating software architectural design from production reality frequently results in applications that are incredibly difficult to deploy, monitor, and scale. If development teams build complex model pipelines without consulting operational specialists from day one, production rollouts will inevitably encounter severe performance bottlenecks. Involving operational experts early ensures that infrastructure constraints, monitoring hooks, and automated scaling patterns are baked directly into the codebase.
Essential Infrastructure Tools & Technologies
Monitoring & Observability
Maintaining complete control over modern data pipelines requires a powerful suite of integrated monitoring, logging, and distributed tracing technologies. Prominent open-source visualization platforms allow teams to build real-time dashboards that track model performance, query latency, and resource utilization metrics. Additionally, centralized logging engines consolidate unstructured system messages from thousands of containers, giving engineers a single workspace to quickly diagnose complex system issues.
Incident Management
When a critical production failure occurs, engineering teams rely on automated incident response platforms to coordinate their technical recovery efforts. These platforms integrate directly with monitoring systems to instantly ingest alerts, classify severity levels, and route emergency notifications to on-call engineers. By providing unified communication channels, automated escalation paths, and clear runbooks, these tools help teams minimize system downtime and accelerate incident resolution.
CI/CD & Release Engineering
Automating the continuous integration and deployment of data models requires robust, highly reliable release engineering infrastructure. Modern automation engines allow teams to define entire deployment pipelines as code, executing automated validation checks, and building isolated container images. These tools ensure that every single model update undergoes rigorous testing and gradual production rollouts, significantly reducing the risk of introducing buggy code into live networks.
Chaos Engineering
To actively validate system resilience, teams leverage specialized fault-injection software frameworks to run controlled chaos experiments in production environments. These specialized tools systematically introduce artificial network latency, simulate disk space exhaustion, or terminate live application containers according to predefined schedules. By observing how the broader infrastructure adapts to these sudden failures, engineers can verify that automated self-healing mechanisms function correctly under stress.
SLO Management
Tracking long-term compliance against user reliability thresholds requires specialized platforms that gather real-time performance indicators and calculate remaining error budgets. These modern platforms interface directly with existing monitoring tools to aggregate complex operational metrics into clear, human-readable compliance reports. This continuous calculation gives product stakeholders and engineering leads the precise data needed to balance development speed with system stability.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Building a successful career in modern systems operations requires a diverse, well-rounded blend of software engineering capabilities and deep infrastructure knowledge.
- Linux Systems & Terminal Command Proficiency: Mastering bash scripting, file permissions, process management, and network troubleshooting utilities.
- Core Programming & Scripting Languages: Writing clean, scalable automation code using modern languages like Python or Go.
- Cloud Infrastructure Platforms: Configuring virtual networks, scalable compute nodes, and managed storage solutions across major cloud environments.
- Containerization & Orchestration: Packaging applications into isolated containers and orchestrating them at scale using Kubernetes clusters.
- Infrastructure as Code (IaC): Defining and provisioning enterprise cloud infrastructure using declarative configuration files.
- Statistical Data Analysis: Understanding core data structures, matrix operations, and foundational predictive modeling concepts.
The Professional Learning Path
Your educational journey should begin by mastering the absolute fundamentals of operating systems, local networking protocols, and basic shell scripting. Once you can navigate terminal environments confidently, focus on learning a core programming language to automate routine administrative tasks. Next, expand your technical expertise into container technologies, learning how to build, run, and isolate applications inside lightweight environments.
After mastering local containers, progress to studying large-scale container orchestration platforms and managing distributed cloud infrastructure environments securely. Simultaneously, start exploring the fundamentals of data engineering, learning how information flows through automated ingestion pipelines and training environments. Finally, integrate these distinct fields by studying advanced site reliability engineering, learning to manage error budgets, SLOs, and large-scale self-healing systems.
Certifications Worth Pursuing
Earning industry-recognized professional credentials is an excellent way to validate your technical expertise and accelerate your career growth. Aspiring specialists should consider pursuing fundamental cloud architectural certifications to build a strong baseline understanding of modern distributed networks. Following that, securing advanced container orchestration credentials provides definitive proof that you can manage complex production clusters effectively.
Additionally, earning dedicated site reliability and data engineering certifications demonstrates to enterprise employers that you possess the advanced skills needed to run high-availability systems. These rigorous technical examinations validate your ability to troubleshoot production failures, optimize resource utilization, and automate complex workflows. Holding these credentials sets you apart in the competitive global technology job market.
Educational Resources with Debug.school
Navigating the vast world of systems engineering and predictive automation can feel completely overwhelming without structured, practical guidance. Fortunately, the comprehensive, mentor-led programs available at Debug.school provide the exact path you need to master these complex technical concepts. By working through real-world labs, simulated production outages, and hands-on automation projects, you will gain the practical skills required to manage enterprise-grade infrastructure confidently.
The Future of Systems Management
AI and Automation in System Optimization
The next major evolution in systems infrastructure centers on integrating advanced machine intelligence directly into core monitoring and optimization workflows. Instead of relying on human engineers to manually tune system parameters, autonomous algorithms will continuously analyze telemetry data to optimize configurations in real-time. These intelligent platforms will predict resource shortages, isolate root causes of incidents instantly, and apply corrective system patches without requiring any human intervention.
Platform Engineering — The Evolution of Infrastructure
Platform engineering is rapidly transforming how modern software development teams interact with underlying cloud infrastructure and deployment networks. By building internal self-service developer platforms, platform teams provide software engineers with pre-configured, fully compliant application templates and automated pipelines. This shift removes infrastructure complexity from the development cycle, allowing software engineers to deploy models faster while maintaining high reliability standards across the organization.
Management in Cloud-Native & Kubernetes Environments
As enterprise applications transition completely toward highly dynamic, cloud-native container clusters, managing distributed networks becomes increasingly complex. Microservices scale up and down rapidly across global regions, generating massive streams of volatile configuration data and network paths. Future systems engineers must master service mesh architectures, decentralized logging systems, and automated cluster governance to keep these elastic environments stable.
Operational Skills That Will Matter Most
In the coming years, the role of the systems specialist will shift focus from basic automation scripting toward advanced architectural governance and cloud financial management. Engineers must develop deep expertise in data observability, learning to trace complex information paths across heterogeneous multi-cloud environments. Additionally, optimizing cloud resource spend and balancing infrastructural costs against strict performance SLOs will become a critical differentiator for top-tier technical talent.
FAQ Section
- What is the primary difference between traditional systems administration and modern operations engineering? Traditional systems administration relies heavily on manual configuration management, reactive troubleshooting, and human-led coordination to maintain server environments. In sharp contrast, modern operations engineering applies rigorous software development methodologies to automate infrastructure management, leveraging code to build self-healing, highly scalable systems.
- How do engineering teams accurately calculate and use an error budget? Teams calculate an error budget directly as $100\% - \text{SLO}$ based on their target system reliability metrics over a specific time window. This quantitative budget serves as a formal operating agreement that balances rapid development feature releases with the baseline stability of the production platform.
- What are the typical entry-level salary trends for specialists in this technical field? Entry-level specialists starting their careers in this high-demand domain typically command highly competitive salaries across global technology hubs. As engineers acquire advanced skills in container orchestration, infrastructure automation, and data pipeline management, their earning potential increases significantly within enterprise organizations.
- Can a software developer successfully transition into a systems reliability engineering role? Yes, software developers can transition into this field by expanding their core coding expertise to include deep networking concepts, operating systems internals, and automated deployment infrastructure. Their strong programming background gives them a massive advantage when writing code to automate complex system management tasks.
- Why is a blameless postmortem culture essential for long-term system reliability? A blameless postmortem culture ensures that technical teams focus entirely on discovering systemic vulnerabilities and process gaps rather than punishing individual human errors. This open environment encourages transparent documentation of failures, preventing the exact same production bugs from disrupting the network in the future.
- What specific programming language should a beginner learn first for infrastructure automation? Beginners entering the infrastructure automation space should prioritize learning Python or Go due to their widespread industry adoption and extensive library support. These languages feature clean syntax, run efficiently across diverse operating systems, and integrate seamlessly with modern cloud computing platform APIs.
Final Summary
Maintaining long-term system health in today's data-driven world requires moving completely away from brittle legacy architectures and embracing automated, intelligent frameworks. By implementing measurable performance targets, eliminating repetitive manual toil, and enforcing blameless postmortem analysis, teams can protect their core infrastructure from critical outages. This comprehensive engineering approach ensures that complex software environments remain highly adaptable, secure, and resilient as they scale to meet growing global demands.
Ultimately, mastering these foundational optimization frameworks is what separates traditional IT operations from high-performing, innovative software engineering teams. As automated intelligence continues to reshape the global technology ecosystem, developing a deep understanding of infrastructure scalability becomes an invaluable professional asset. Take the next definitive step in your technical career by joining the advanced professional certification programs at [Debug.school].

Top comments (0)