Difference between ifference Between OpenAI's GPT-4 and Ollama's Gemma:2b
How to get parsed output using OutputParser and LCEL in Ollama's Gemma:2b
Difference between ifference Between OpenAI's GPT-4 and Ollama's Gemma:2b
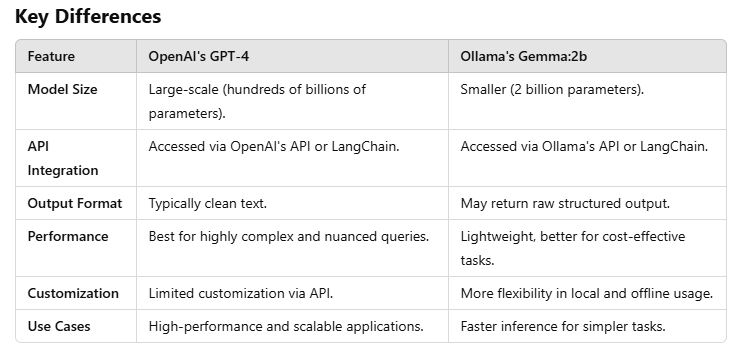
OpenAI's GPT-4 and Ollama's gemma:2b are two distinct language models with different implementations, APIs, and capabilities. Here's a detailed comparison with coding examples to highlight their differences.
Coding Example: OpenAI's GPT-4
OpenAI's GPT-4 is integrated into LangChain using the OpenAI wrapper, which typically provides clean and direct responses.
Example Code:
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.llms import OpenAI
# Initialize OpenAI's GPT-4
llm = OpenAI(model="gpt-4")
# Create a chat prompt template
prompt = ChatPromptTemplate.from_messages([
("system", "You are an expert AI Engineer. Provide precise and detailed answers."),
("user", "{input}")
])
# Input question
input_text = {"input": "Explain the concept of Langsmith."}
# Invoke the model
response = (prompt | llm).invoke(input_text)
# Print the result
print("OpenAI GPT-4 Output:")
print(response)
Example Output:
Langsmith is a developer-centric tool within the LangChain ecosystem designed for tracking, debugging, and managing LLM-powered applications. It provides insights into prompt usage, token consumption, and facilitates iterative improvement.
Coding Example: Ollama's Gemma:2b
Ollama's gemma:2b is integrated via LangChain's Ollama wrapper. It may return raw structured output, including metadata.
Example Code:
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.llms import Ollama
# Initialize Ollama's gemma:2b
llm = Ollama(model="gemma:2b")
# Create a chat prompt template
prompt = ChatPromptTemplate.from_messages([
("system", "You are an expert AI Engineer. Provide precise and detailed answers."),
("user", "{input}")
])
# Input question
input_text = {"input": "Explain the concept of Langsmith."}
# Invoke the model
response = (prompt | llm).invoke(input_text)
# Print the raw result
print("Ollama Gemma:2b Raw Output:")
print(response)
Example Raw Output:
{
"text": "Langsmith is a developer-centric tool within LangChain that provides tracking and debugging capabilities for LLM applications.",
"tokens": {
"input": 10,
"output": 50
},
"model": "gemma:2b"
}
How to get parsed output using OutputParser and LCEL in Ollama's Gemma:2b
Unified Approach Using an Output Parser
To handle the differences in output format, you can use an OutputParser to standardize the response.
Example Code:
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_community.llms import Ollama
from langchain_core.llms import OpenAI
# Initialize both LLMs
openai_llm = OpenAI(model="gpt-4")
ollama_llm = Ollama(model="gemma:2b")
# Create a chat prompt template
prompt = ChatPromptTemplate.from_messages([
("system", "You are an expert AI Engineer. Provide precise and detailed answers."),
("user", "{input}")
])
# Output Parser to standardize output
output_parser = StrOutputParser()
# Chain for OpenAI's GPT-4
openai_pipeline = prompt | openai_llm | output_parser
openai_result = openai_pipeline.invoke({"input": "Explain the concept of Langsmith."})
# Chain for Ollama's Gemma:2b
ollama_pipeline = prompt | ollama_llm | output_parser
ollama_result = ollama_pipeline.invoke({"input": "Explain the concept of Langsmith."})
# Print results
print("OpenAI GPT-4 Parsed Output:")
print(openai_result)
print("\nOllama Gemma:2b Parsed Output:")
print(ollama_result)
Example Output:
OpenAI GPT-4 Parsed Output:
Langsmith is a developer-centric tool within the LangChain ecosystem designed for tracking, debugging, and managing LLM-powered applications.
Ollama Gemma:2b Parsed Output:
Langsmith is a developer-centric tool within LangChain that provides tracking and debugging capabilities for LLM applications.
When to Use Which Model
Use OpenAI GPT-4:
For complex, nuanced tasks requiring high accuracy and detailed reasoning.
When clean text output is a priority.
Scalable, cloud-based use cases.
Use Ollama Gemma:2b:
For lightweight and cost-effective tasks
When metadata (like token usage) or local/offline usage is required.
Scenarios where fast responses are more important than complex reasoning.
This approach ensures a consistent development experience while leveraging the strengths of each model.

Top comments (0)