Role of AI Agents
Role of Machine Learning / Deep Learning
How They Integrate & Play Major Roles Together
Pre-trained AI Models for Integration
Most widely used pre-trained AI models:
AI Agent Function for Image Content Verification using keras model
How AI agent Orchestrating multiple ML/DL models into a single workflow
How Agents will manage supply chains
FAQ/PROMPT
Role of AI Agents
AI Agents are autonomous software systems designed to perceive their environment, make decisions, and take actions to achieve specific goals.
They rely on ML/DL models, reasoning engines, and planning algorithms to work effectively.
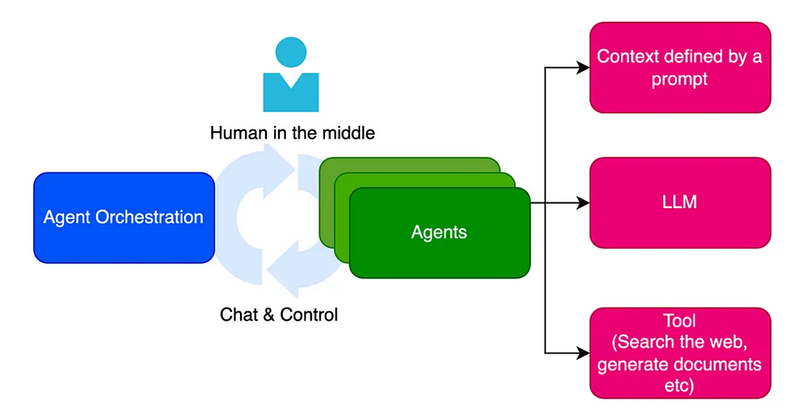
Current Roles
Automation: Handling repetitive tasks (chatbots, virtual assistants, workflow automation).
Decision-making: Assisting in business decisions (recommendation engines, financial analysis).
Interaction: Natural Language Processing (NLP) for human-like conversations.
Control Systems: Robotics, IoT, autonomous vehicles.
Integration: Orchestrating multiple ML/DL models into a single workflow.
Future Roles
Autonomous Enterprises: Agents will manage supply chains, HR, customer support with minimal human input.
Multi-Agent Systems: Agents will collaborate (like digital employees) for large-scale problem solving.
Personal AI Managers: Customized assistants for personal health, finance, productivity.how-to-create-customized-assistants-using-ai-agent
Self-Improving Agents: They’ll continuously learn, adapt, and optimize themselves without retraining from scratch.explain-self-improving-ai-agents
🔹
Role of Machine Learning / Deep Learning
ML/DL are the core intelligence engines that power AI Agents.
They provide the pattern recognition, predictions, and decision-support functions.
Current Roles
Prediction & Forecasting: Finance, healthcare, weather, demand prediction.
Pattern Recognition: Image, speech, fraud detection, anomaly spotting.
Personalization: Recommendation engines (Netflix, Amazon, YouTube).
Optimization: Resource allocation, logistics, operations research.
Natural Language: Speech-to-text, language translation, sentiment analysis.
Future Roles
Self-Supervised Learning: Less need for labeled data.
Generalizable AI: Models that work across multiple tasks/domains.
Explainable AI: Transparent, trustworthy decision-making.
Edge AI: ML models running on small devices (IoT, wearables, smart homes).
Human-AI Collaboration: Assisting professionals with decision intelligence.
How They Integrate & Play Major Roles Together
integrating-ai-agents-with-deep-learning-models-igi

Integration Process
ML/DL Model Training
Train models for vision, NLP, prediction, etc.
Example: A DL model trained to detect fraud transactions.
Embedding into AI Agent
AI Agent uses ML/DL model outputs to make context-aware decisions.
Example: Agent blocks a suspicious transaction after ML detects anomalies.
Feedback Loop
AI Agent collects new data during operations.
Feeds back into ML/DL models for continuous learning.
Example Workflows
Healthcare:
ML predicts disease risk → AI Agent advises treatment plan + schedules doctor visit.
Finance:
ML forecasts stock price → AI Agent makes autonomous portfolio adjustments.
Customer Support:
NLP (DL model) understands query → AI Agent solves issue or routes to human.
Autonomous Vehicles:
DL processes camera/lidar data → AI Agent decides braking/steering.

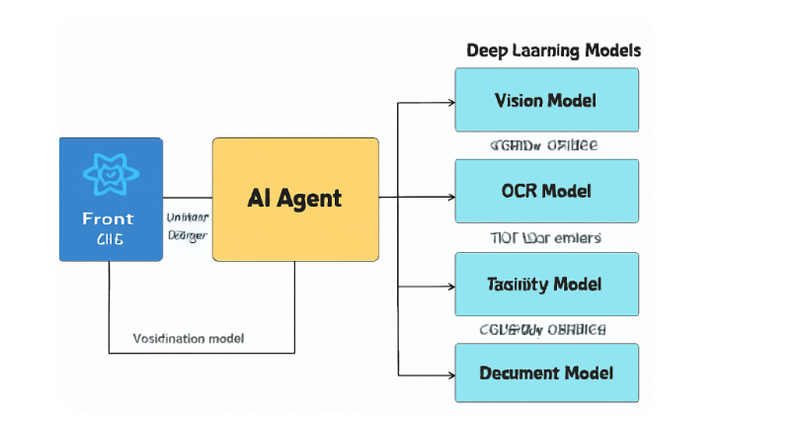
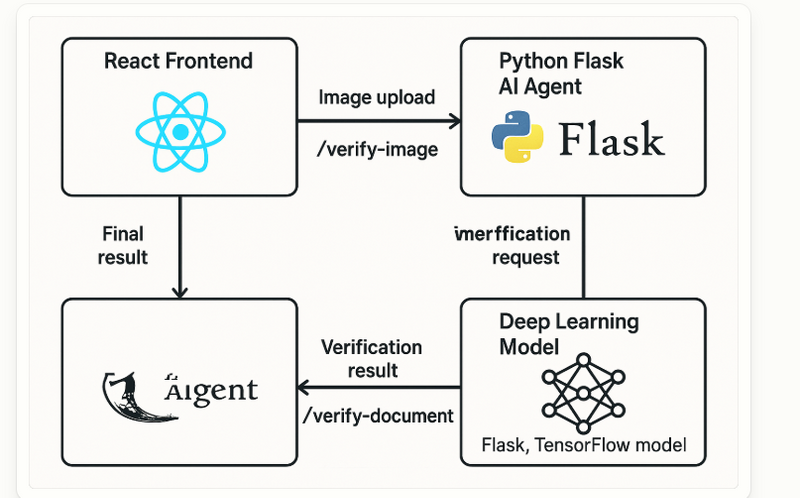
Project: ai-verifier
This example shows how an AI Agent orchestrates multiple Deep Learning checks to verify user uploads: images (content), documents (PDF/JPEG), and extracted text.
Stack: React (frontend), FastAPI (Python) backend, DL with PyTorch + OCR (pytesseract) + simple heuristics/metadata checks.
Folder Structure
ai-verifier/
├─ backend/
│ ├─ main.py # FastAPI app & endpoints
│ ├─ agent.py # Orchestrator (AI Agent)
│ ├─ models.py # DL wrappers: image moderation, OCR, text classifier
│ ├─ utils.py # Helpers: hashing, EXIF, PDF extraction, file mgmt
│ ├─ requirements.txt
│ └─ README.md
└─ frontend/
├─ src/
│ ├─ App.jsx # React UI (upload + results)
│ ├─ api.js # Fetch helpers
│ └─ ResultCard.jsx # Pretty results card
├─ index.html
├─ package.json
└─ README.md
backend/requirements.txt
fastapi==0.115.0
uvicorn==0.30.6
python-multipart==0.0.9
pydantic==2.9.2
pydantic-settings==2.6.1
Pillow==10.4.0
pytesseract==0.3.13
pdfplumber==0.11.4
PyPDF2==3.0.1
python-magic==0.4.27
exifread==3.0.0
torch==2.3.1
torchvision==0.18.1
scikit-learn==1.5.1
numpy==1.26.4
Install Tesseract on system:
- Ubuntu/Debian:
sudo apt-get install tesseract-ocr- macOS (brew):
brew install tesseract- Windows: download installer from tesseract-ocr.github.io and add to PATH.
backend/utils.py
import hashlib, os, io, magic, time, exifread
from typing import Dict, Any
from PIL import Image
import pdfplumber
ALLOWED_MIME = {
'image/jpeg', 'image/png', 'application/pdf'
}
def sniff_mime(bytez: bytes) -> str:
return magic.from_buffer(bytez, mime=True)
def ensure_allowed(bytez: bytes) -> str:
mime = sniff_mime(bytez)
if mime not in ALLOWED_MIME:
raise ValueError(f"Unsupported MIME: {mime}")
return mime
def sha256_bytes(bytez: bytes) -> str:
return hashlib.sha256(bytez).hexdigest()
def read_exif(jpeg_bytes: bytes) -> Dict[str, Any]:
with io.BytesIO(jpeg_bytes) as bio:
tags = exifread.process_file(bio, details=False)
# Extract a few common fields
out = {}
for k in ['Image Make','Image Model','EXIF DateTimeOriginal','GPS GPSLatitude','GPS GPSLongitude']:
if k in tags:
out[k] = str(tags[k])
return out
def image_from_bytes(bytez: bytes) -> Image.Image:
return Image.open(io.BytesIO(bytez)).convert('RGB')
def pdf_text_first_pages(pdf_bytes: bytes, max_pages: int = 3) -> str:
text = []
with io.BytesIO(pdf_bytes) as bio:
with pdfplumber.open(bio) as pdf:
for i, page in enumerate(pdf.pages[:max_pages]):
text.append(page.extract_text() or '')
return "\n".join(text).strip()
backend/models.py (Deep Learning + OCR)
from typing import Dict, Any
import io
import torch
import torch.nn.functional as F
from PIL import Image
from torchvision import transforms, models
import pytesseract
# --- Image Moderation / Content Safety (demo using ImageNet features) ---
# NOTE: For production, swap with a model trained for NSFW/violence/weapon logos.
class ImageSafetyModel:
def __init__(self, device: str = 'cpu'):
self.device = device
self.model = models.mobilenet_v3_small(weights=models.MobileNet_V3_Small_Weights.DEFAULT).to(device)
self.model.eval()
self.transform = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485,0.456,0.406], std=[0.229,0.224,0.225])
])
# Heuristic label groups: (simulated)
self.weapon_like_idx = {413, 414, 657} # fake ImageNet IDs (demo)
self.gore_like_idx = {919, 918} # fake
@torch.inference_mode()
def score(self, img: Image.Image) -> Dict[str, Any]:
x = self.transform(img).unsqueeze(0).to(self.device)
logits = self.model(x)
probs = F.softmax(logits, dim=1)[0]
# Heuristics: aggregate some indices into categories (demo-only)
weapon_score = float(probs[list(self.weapon_like_idx)].sum().item()) if self.weapon_like_idx else 0.0
gore_score = float(probs[list(self.gore_like_idx)].sum().item()) if self.gore_like_idx else 0.0
nsfw_score = 0.15 # placeholder constant; replace with real model
safe_score = float(1.0 - min(1.0, weapon_score + gore_score + nsfw_score))
return {
'weapon_score': weapon_score,
'gore_score': gore_score,
'nsfw_score': nsfw_score,
'safe_score': safe_score
}
# --- OCR & Text Quality ---
class OcrExtractor:
def __init__(self, lang: str = 'eng'):
self.lang = lang
def extract(self, img: Image.Image) -> str:
return pytesseract.image_to_string(img, lang=self.lang)
# --- Simple Text Classifier (rule/keyword hybrid) ---
TOXIC_KEYWORDS = {
'hate','kill','attack','bomb','fraud','porn','explicit','nude','weapon','terror'
}
def text_toxicity_score(text: str) -> Dict[str, Any]:
lowered = text.lower()
hits = [w for w in TOXIC_KEYWORDS if w in lowered]
score = min(1.0, len(hits)/5.0)
return {'toxicity_score': score, 'hits': hits}
# --- Document Type Guess (very naive demo) ---
DOC_HINTS = {
'passport': ['passport','country','nationality','given name','surname'],
'invoice': ['invoice','subtotal','gst','tax','total','bill to'],
'id_card': ['identity','id no','dob','issued','valid'],
}
def guess_document_type(text: str) -> str:
t = text.lower()
best, best_hits = 'unknown', 0
for k, words in DOC_HINTS.items():
hits = sum(1 for w in words if w in t)
if hits > best_hits:
best_hits, best = hits, k
return best
backend/agent.py (AI Agent Orchestrator)
from typing import Dict, Any
from PIL import Image
from .models import ImageSafetyModel, OcrExtractor, text_toxicity_score, guess_document_type
from .utils import read_exif, pdf_text_first_pages
class VerificationAgent:
"""
An AI Agent that plans & routes verification steps based on file type and signals
from DL models. Policy is defined in `decide`.
"""
def __init__(self, device: str = 'cpu'):
self.vision = ImageSafetyModel(device=device)
self.ocr = OcrExtractor()
def verify_image(self, img_bytes: bytes) -> Dict[str, Any]:
img = Image.open(io.BytesIO(img_bytes)).convert('RGB')
vision = self.vision.score(img)
exif = read_exif(img_bytes)
text = self.ocr.extract(img)
text_eval = text_toxicity_score(text)
verdict = self.decide(kind='image', vision=vision, text_eval=text_eval)
return {
'kind': 'image',
'vision': vision,
'exif': exif,
'ocr_text_excerpt': text[:400],
'text_eval': text_eval,
'verdict': verdict
}
def verify_pdf(self, pdf_bytes: bytes) -> Dict[str, Any]:
text = pdf_text_first_pages(pdf_bytes)
text_eval = text_toxicity_score(text)
doc_type = guess_document_type(text)
verdict = self.decide(kind='pdf', text_eval=text_eval, doc_type=doc_type)
return {
'kind': 'pdf',
'doc_type': doc_type,
'text_excerpt': text[:800],
'text_eval': text_eval,
'verdict': verdict
}
def decide(self, kind: str, **signals) -> Dict[str, Any]:
"""Simple rule policy. Replace with RL/LLM planner if desired."""
if kind == 'image':
v = signals['vision']; t = signals['text_eval']
reasons = []
risk = 0.0
if v['weapon_score'] > 0.2:
reasons.append('Potential weapon content')
risk += 0.5
if v['gore_score'] > 0.15:
reasons.append('Potential gore/violence')
risk += 0.5
if v['nsfw_score'] > 0.3:
reasons.append('Potential adult content')
risk += 0.4
if t['toxicity_score'] > 0.4:
reasons.append('Toxic text in image via OCR')
risk += 0.3
status = 'reject' if risk >= 0.6 else ('review' if risk >= 0.3 else 'accept')
return {'status': status, 'risk': min(1.0, risk), 'reasons': reasons}
else: # pdf
t = signals['text_eval']; doc_type = signals.get('doc_type','unknown')
reasons = []
risk = 0.0
if t['toxicity_score'] > 0.5:
reasons.append('Toxic or harmful language in document')
risk += 0.5
if doc_type == 'unknown':
reasons.append('Document type uncertain; manual check')
risk += 0.2
status = 'reject' if risk >= 0.7 else ('review' if risk >= 0.3 else 'accept')
return {'status': status, 'risk': min(1.0, risk), 'reasons': reasons, 'doc_type': doc_type}
backend/main.py (FastAPI)
import io
from fastapi import FastAPI, UploadFile, File
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from .utils import ensure_allowed, sha256_bytes
from .agent import VerificationAgent
app = FastAPI(title='AI Verifier')
app.add_middleware(
CORSMiddleware,
allow_origins=['*'],
allow_methods=['*'],
allow_headers=['*'],
)
agent = VerificationAgent(device='cpu')
class VerifyResponse(BaseModel):
file_hash: str
mime: str
report: dict
@app.post('/verify', response_model=VerifyResponse)
async def verify(file: UploadFile = File(...)):
bytez = await file.read()
mime = ensure_allowed(bytez)
h = sha256_bytes(bytez)
if mime.startswith('image/'):
report = agent.verify_image(bytez)
else:
report = agent.verify_pdf(bytez)
return VerifyResponse(file_hash=h, mime=mime, report=report)
backend/README.md
# Backend
## Setup
python -m venv .venv && source .venv/bin/activate # Windows: .venv\Scripts\activate
pip install -r requirements.txt
# Make sure Tesseract is installed on your system and available in PATH
## Run
uvicorn backend.main:app --reload --port 8000
frontend/package.json
{
"name": "ai-verifier-frontend",
"version": "1.0.0",
"private": true,
"type": "module",
"scripts": {
"dev": "vite",
"build": "vite build",
"preview": "vite preview"
},
"dependencies": {
"react": "^18.2.0",
"react-dom": "^18.2.0"
},
"devDependencies": {
"vite": "^5.4.8"
}
}
frontend/index.html
<!doctype html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>AI Verifier</title>
</head>
<body>
<div id="root"></div>
<script type="module" src="/src/App.jsx"></script>
</body>
</html>
frontend/src/api.js
export async function uploadForVerify(file) {
const fd = new FormData();
fd.append('file', file);
const res = await fetch('http://localhost:8000/verify', {
method: 'POST',
body: fd
});
if (!res.ok) throw new Error('Upload failed');
return res.json();
}
frontend/src/ResultCard.jsx
import React from 'react';
export default function ResultCard({ data }) {
if (!data) return null;
const { file_hash, mime, report } = data;
return (
<div className="p-4 max-w-2xl mx-auto rounded-2xl shadow border mb-6">
<h2 className="text-xl font-semibold mb-2">Verification Result</h2>
<p className="text-sm opacity-70">MIME: {mime}</p>
<p className="text-sm opacity-70 mb-4">SHA-256: {file_hash}</p>
<div className="grid gap-2 text-sm">
<div className="font-medium">Type: {report.kind}</div>
{report.kind === 'image' && (
<>
<div className="mt-2">
<div className="font-medium">Vision Scores</div>
<pre className="bg-gray-50 p-2 rounded">{JSON.stringify(report.vision, null, 2)}</pre>
</div>
<div className="mt-2">
<div className="font-medium">EXIF</div>
<pre className="bg-gray-50 p-2 rounded">{JSON.stringify(report.exif, null, 2)}</pre>
</div>
<div className="mt-2">
<div className="font-medium">OCR Excerpt</div>
<pre className="bg-gray-50 p-2 rounded whitespace-pre-wrap">{report.ocr_text_excerpt || '(none)'}
</pre>
</div>
</>
)}
{report.kind === 'pdf' && (
<>
<div className="mt-2">
<div className="font-medium">Guessed Document Type</div>
<div>{report.doc_type}</div>
</div>
<div className="mt-2">
<div className="font-medium">Text Excerpt</div>
<pre className="bg-gray-50 p-2 rounded whitespace-pre-wrap">{report.text_excerpt || '(none)'}
</pre>
</div>
</>
)}
<div className="mt-2">
<div className="font-medium">Text Toxicity</div>
<pre className="bg-gray-50 p-2 rounded">{JSON.stringify(report.text_eval, null, 2)}</pre>
</div>
<div className="mt-2">
<div className="font-medium">Agent Verdict</div>
<pre className="bg-gray-50 p-2 rounded">{JSON.stringify(report.verdict, null, 2)}</pre>
</div>
</div>
</div>
);
}
frontend/src/App.jsx
import React, { useState } from 'react';
import ResultCard from './ResultCard.jsx';
import { uploadForVerify } from './api.js';
export default function App() {
const [file, setFile] = useState(null);
const [busy, setBusy] = useState(false);
const [data, setData] = useState(null);
const [error, setError] = useState('');
async function onSubmit(e) {
e.preventDefault();
if (!file) return;
setBusy(true); setError(''); setData(null);
try {
const res = await uploadForVerify(file);
setData(res);
} catch (err) {
setError(err.message);
} finally {
setBusy(false);
}
}
return (
<div className="p-6">
<h1 className="text-2xl font-bold mb-4">AI Verification (Images & PDFs)</h1>
<form onSubmit={onSubmit} className="flex items-center gap-3 mb-6">
<input type="file" accept="image/*,application/pdf" onChange={(e)=>setFile(e.target.files?.[0]||null)} />
<button disabled={busy || !file} className="px-4 py-2 rounded bg-black text-white disabled:opacity-50">
{busy ? 'Verifying…' : 'Verify'}
</button>
</form>
{error && <div className="text-red-600 mb-4">{error}</div>}
<ResultCard data={data} />
<div className="text-sm opacity-70 max-w-2xl">
<p>
This demo uses a general vision backbone and simple rules for content safety, OCR via Tesseract,
and a rule-based toxicity detector. Replace the demo heuristics with your production models.
</p>
</div>
</div>
);
}
frontend/README.md
# Frontend
npm install
npm run dev
# Open http://localhost:5173 (vite default)
# If your backend runs on a different host/port, update `frontend/src/api.js`
How the AI Agent & DL Work Together
1) DL Models do the heavy lifting: vision scoring, OCR, text scoring, document-type guess.
2) AI Agent (agent.py) aggregates signals and applies a policy to decide accept / review / reject with reasons.
3) Feedback loop: Log verdicts + false positives; retrain DL; refine decide() thresholds or swap in an LLM planner.
Production Upgrades (swap-ins)
- Replace
ImageSafetyModelwith a proper moderation model (NSFW/violence/weapon/logo detector or YOLO-based classifiers). - Add face matching (eKYC): use face embeddings + cosine similarity with user KYC photo (consent required).
- Add tamper detection: ELA or copy-move forgery (OpenCV) + metadata consistency checks.
- Use a policy engine (e.g., Open Policy Agent) for region-specific compliance.
- Add LLM tool-use agent to request manual review when uncertain and to explain decisions in user-friendly language.
**How to run (quick start)**
**Backend**
cd backend
python -m venv .venv && source .venv/bin/activate (Windows: .venv\Scripts\activate)
pip install -r requirements.txt
Install Tesseract on your OS and ensure it’s in PATH
uvicorn backend.main:app --reload --port 8000
Frontend
cd frontend
npm install
npm run dev → open the shown local URL (Vite)
Then upload a JPEG/PNG/PDF and you’ll get:
Vision scores (weapon/gore/nsfw placeholders—swap with your production model)
EXIF summary (for images)
OCR text excerpt
Text toxicity hits
Agent verdict with risk and reasons
If you want, I can tailor this for your exact verification rules (e.g., Aadhaar/PAN/passport layouts, watermark/tamper checks, face match for eKYC, or region-specific compliance).
Pre-trained AI Models for Integration
Google Cloud Vision API
Capabilities: Image labeling, face detection, text extraction (OCR), explicit content detection.
Free Tier: 1,000 units per month.
Integration: REST API; suitable for React frontend and Python backend.
Use Case: Detecting explicit content or extracting text from images and documents.
Documentation:
Google Cloud
Clarifai
Capabilities: Image and video recognition, NSFW detection, custom model training.
Free Tier: 5,000 operations/month.
Integration: REST API; supports custom workflows.
Use Case: Identifying inappropriate content or custom object detection.
Documentation:
Eden AI
DeepAI
Capabilities: Image generation, style transfer, NSFW detection, image moderation.
Free Tier: Limited usage; requires API key.
Integration: REST API; easy to use with React and Python.
Use Case: Generating images from text prompts or moderating user-uploaded content.
Documentation:
Eden AI
Pretrained.ai
Capabilities: Hosted pre-trained models for text, image, and audio processing.
Free Tier: Free tier available with limited usage.
Integration: REST API; deploy your own private endpoints.
Use Case: Quick integration of various AI models into your application.
Documentation:
Pretrained
Keras Applications
Capabilities: Pre-trained models like MobileNetV2, ResNet50, InceptionV3 for image classification.
Free Tier: Completely free; models available for download.
Integration: Python-based; can be served via FastAPI or Flask.
Use Case: Classifying images into categories (e.g., identifying document types).
Documentation:
Keras
TensorFlow.js Models
Capabilities: Pre-trained models for image classification, object detection, and more.
Free Tier: Free; models can run directly in the browser.
Integration: JavaScript-based; can be used in React frontend.
Use Case: Real-time image analysis directly in the browser.
Documentation:
TensorFlow
ONNX Model Zoo
Capabilities: A collection of pre-trained models in ONNX format for various tasks.
Free Tier: Free; models available for download.
Integration: Python-based; can be served via FastAPI or Flask.
Use Case: Utilizing models trained in different frameworks like PyTorch or TensorFlow.
Documentation:
GitHub
Most widely used pre-trained AI models
Among pre-trained AI models for integration, several have become industry standards due to their robustness, wide usage, and comprehensive documentation. Here are some of the most widely used pre-trained AI models:
TensorFlow/Keras Models
Most Common Models: MobileNetV2, InceptionV3, ResNet, VGG16.
Use Cases: Image classification, object detection, facial recognition.
Why It's Popular:
Extensive pre-trained models (ImageNet, COCO).
Easy integration with Python backends.
Optimized for production with TensorFlow Serving.
Supported by major cloud services like Google Cloud.
Use Case Examples: Image classification (e.g., recognizing animals, objects), object detection.
Hugging Face Transformers
Most Common Models: BERT, GPT, T5, RoBERTa, DistilBERT.
Use Cases: Natural Language Processing (NLP), text generation, question answering, text classification.
Why It's Popular:
Large community and well-documented.
Models like GPT-3 and BERT are state-of-the-art for NLP tasks.
Supports multiple languages and domains.
Easy-to-use APIs for deployment and inference.
Use Case Examples: Text classification (e.g., sentiment analysis), translation, text summarization.
OpenAI GPT-3 (via API)
Most Common Models: GPT-3, Codex (for code-related tasks).
Use Cases: Text generation, code generation, chatbots, conversation AI.
Why It's Popular:
State-of-the-art performance in text generation.
Easy API integration (no need to train models).
Strong in generating human-like responses.
Use Case Examples: Chatbots, content creation, programming assistants.
Google Cloud Vision API
Most Common Features: Image classification, text extraction (OCR), face detection, label detection.
Use Cases: Image analysis, document scanning, content moderation.
Why It's Popular:
Scalable and highly accurate.
Robust feature set, including facial recognition and text detection.
Fully managed, no need to deploy your own models.
Use Case Examples: Detecting objects in images, text recognition in documents (OCR), content moderation.
Clarifai
Most Common Models: NSFW detection, image classification, object detection.
Use Cases: Image and video analysis, content moderation, visual recognition.
Why It's Popular:
Easy-to-integrate API.
Focused on visual AI tasks.
Offers both pre-trained models and the option to train custom models.
Use Case Examples: Detecting inappropriate content in images, custom object detection.
Microsoft Azure Cognitive Services
Most Common Models: Face API, Text Analytics API, Custom Vision, Speech Recognition.
Use Cases: Face detection, text analysis, speech-to-text, sentiment analysis.
Why It's Popular:
Seamless integration with Microsoft’s cloud infrastructure.
Highly scalable and managed services.
Offers tools for building custom models.
Use Case Examples: Face recognition, sentiment analysis, custom image classification.
IBM Watson
Most Common Models: Watson NLP, Watson Visual Recognition, Watson Speech-to-Text.
Use Cases: Text classification, sentiment analysis, image analysis.
Why It's Popular:
Robust enterprise features.
Integrates well with IBM’s cloud infrastructure.
Strong NLP and machine learning capabilities.
Use Case Examples: Text-to-speech, sentiment analysis, image tagging.
DeepAI
Most Common Models: NSFW detection, Image moderation, Style transfer.
Use Cases: Image and video analysis, content generation, art-related applications.
Why It's Popular:
Provides free access to multiple powerful models.
Easy API integration with Python and web apps.
Specialized in content moderation and image-related tasks.
Use Case Examples: Moderating user-generated content, image enhancement, generating artistic images.
PyTorch Models (via TorchHub)
Most Common Models: Detectron2, YOLOv5, ResNet, EfficientNet.
Use Cases: Object detection, image segmentation, classification.
Why It's Popular:
Flexible and deep integration with PyTorch.
Great for research and experimentation.
Active community and support for the latest models.
Use Case Examples: Object detection, real-time video analysis.
AI Agent Function for Image Content Verification
Here’s the folder structure for the full integration of the AI Agent, FastAPI backend, and React frontend with image content verification using the MobileNetV2 Keras model:
ai-content-verification/
├── backend/ # FastAPI Backend
│ ├── agent.py # AI Agent - Image Classification and Decision Logic
│ ├── main.py # FastAPI App with Endpoint for Image Upload
│ ├── requirements.txt # Python Dependencies (FastAPI, TensorFlow, etc.)
│ └── README.md # Backend setup instructions
└── frontend/ # React Frontend
├── src/
│ ├── App.jsx # Main React App Component
│ ├── index.js # Entry point for React app
│ ├── api.js # API calls to backend (image upload)
│ └── ResultCard.jsx # Display results (Predictions & Decision)
├── public/
│ └── index.html # HTML Template for React
├── package.json # React dependencies & scripts
├── package-lock.json # Lock file for consistent installs
└── README.md # Frontend setup instructions

fastapi==0.115.0
uvicorn==0.30.6
tensorflow==2.10.0
pillow==10.4.0
numpy==1.26.4
python-multipart==0.0.9
AI Agent Class
We will define the AI Agent class in a separate module and then use it in the FastAPI endpoint to handle the image content verification
# backend/main.py
from fastapi import FastAPI, UploadFile, File
from fastapi.responses import JSONResponse
from PIL import Image
import io
import numpy as np
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input, decode_predictions
# Define the AI Agent that orchestrates the process
class AI_Agent:
def __init__(self):
# Load the MobileNetV2 pre-trained model
self.model = MobileNetV2(weights="imagenet")
def process_image(self, img_bytes: bytes):
"""
This function orchestrates the image verification process using the model.
It preprocesses the image, classifies it, and makes a decision.
"""
img = self._prepare_image(img_bytes)
predictions = self._classify_image(img)
decision = self._make_decision(predictions)
return predictions, decision
def _prepare_image(self, img_bytes: bytes):
"""
Helper function to prepare the image for classification.
"""
img = Image.open(io.BytesIO(img_bytes))
img = img.resize((224, 224)) # Resize to 224x224 for MobileNetV2
img_array = np.array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array = preprocess_input(img_array)
return img_array
def _classify_image(self, img_array: np.ndarray):
"""
Helper function to classify the image using the pre-trained model.
"""
preds = self.model.predict(img_array)
decoded_preds = decode_predictions(preds, top=3)[0]
return decoded_preds
def _make_decision(self, predictions):
"""
The AI Agent makes a decision based on the predictions.
For now, we can simply review if the top prediction is safe or not.
"""
top_pred = predictions[0]
label, description, confidence = top_pred
# Simple decision process (can be expanded for more complex logic)
if confidence > 0.8: # If confidence is greater than 80%
return {"status": "accept", "reason": f"Content is safe, recognized as {description} with {confidence * 100}% confidence."}
elif confidence < 0.5: # Low confidence, needs review
return {"status": "review", "reason": "Low confidence in classification. Needs review."}
else:
return {"status": "reject", "reason": "Unsafe content detected."}
# Instantiate the AI Agent
ai_agent = AI_Agent()
# Initialize FastAPI
app = FastAPI()
# FastAPI endpoint to receive image upload and classify it
@app.post("/predict")
async def predict(file: UploadFile = File(...)):
try:
# Read the uploaded image
img_bytes = await file.read()
# Use the AI Agent to process the image and get predictions and decisions
predictions, decision = ai_agent.process_image(img_bytes)
# Return the predictions and the decision as a JSON response
return JSONResponse(content={"predictions": predictions, "decision": decision})
except Exception as e:
return JSONResponse(status_code=400, content={"error": str(e)})
# To run the server: uvicorn backend.main:app --reload

Frontend Code (React)
Here is the React frontend code that interacts with the backend and displays both the predictions and the decision from the AI Agent:
// frontend/src/App.jsx
import React, { useState } from "react";
import axios from "axios";
function App() {
const [file, setFile] = useState(null);
const [predictions, setPredictions] = useState([]);
const [decision, setDecision] = useState({});
const [loading, setLoading] = useState(false);
const handleFileChange = (e) => {
setFile(e.target.files[0]);
};
const handleSubmit = async (e) => {
e.preventDefault();
if (!file) return;
setLoading(true);
const formData = new FormData();
formData.append("file", file);
try {
const response = await axios.post("http://localhost:8000/predict", formData, {
headers: { "Content-Type": "multipart/form-data" },
});
setPredictions(response.data.predictions);
setDecision(response.data.decision);
} catch (error) {
console.error("Error during prediction:", error);
} finally {
setLoading(false);
}
};
return (
<div className="App">
<h1>AI Image Content Verification</h1>
<form onSubmit={handleSubmit}>
<input type="file" onChange={handleFileChange} />
<button type="submit" disabled={loading}>
{loading ? "Classifying..." : "Verify Image"}
</button>
</form>
{predictions.length > 0 && (
<div>
<h2>Predictions</h2>
<ul>
{predictions.map((pred, index) => (
<li key={index}>
{pred[1]}: {Math.round(pred[2] * 100)}%
</li>
))}
</ul>
</div>
)}
{decision && (
<div>
<h2>Decision</h2>
<p>Status: {decision.status}</p>
<p>Reason: {decision.reason}</p>
</div>
)}
</div>
);
}
export default App;
How AI agent Orchestrating multiple ML/DL models into a single workflow
Orchestrating multiple ML/DL models into a single workflow is a powerful way to combine the strengths of different models and techniques to make more accurate predictions or decisions. An AI agent can be designed to manage the entire workflow, interacting with different models, combining their outputs, and making the final decision based on the aggregated results.
Here’s an example where an AI agent orchestrates multiple machine learning models (e.g., a random forest classifier for classification and a regression model for continuous prediction) to make a decision.
Example: AI Agent Orchestrating Multiple ML/DL Models
We’ll create an AI agent that:
Uses a Random Forest Classifier to predict whether a customer will churn or not.
Uses a Linear Regression model to predict the customer's lifetime value (LTV) based on the same features.
Orchestrates both models into a final decision-making workflow, where the agent will decide whether to retain or offer a discount to the customer based on both churn prediction and LTV prediction.
# Install required libraries
# pip install scikit-learn pandas
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Sample customer data (age, tenure, balance, and churn)
data = {
'age': [22, 25, 27, 32, 45, 50, 55, 30],
'tenure': [1, 2, 3, 4, 5, 6, 7, 8],
'balance': [2000, 3000, 1500, 4000, 5000, 6000, 7000, 8000],
'churn': [0, 0, 0, 1, 1, 1, 0, 1], # 0 = stayed, 1 = churned
'ltv': [1000, 1500, 1200, 2000, 2500, 3000, 3500, 4000] # Lifetime Value (LTV)
}
# Convert data to DataFrame
df = pd.DataFrame(data)
# Features (independent variables) and targets (dependent variables)
X = df[['age', 'tenure', 'balance']]
y_churn = df['churn']
y_ltv = df['ltv']
# Split data into training and testing sets
X_train, X_test, y_churn_train, y_churn_test, y_ltv_train, y_ltv_test = train_test_split(X, y_churn, y_ltv, test_size=0.2, random_state=42)
# 1. Random Forest Classifier for churn prediction (classification model)
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_churn_train)
# 2. Linear Regression for LTV prediction (regression model)
lr_model = LinearRegression()
lr_model.fit(X_train, y_ltv_train)
# Predict on the test set using both models
y_churn_pred = rf_model.predict(X_test) # Predict churn
y_ltv_pred = lr_model.predict(X_test) # Predict LTV
# Evaluate the Random Forest classifier's performance (churn prediction)
accuracy = accuracy_score(y_churn_test, y_churn_pred)
print(f'Random Forest Churn Prediction Accuracy: {accuracy:.2f}')
# AI Agent's Decision-Making
# Based on churn prediction and LTV, the AI agent decides on customer retention strategies
for i in range(len(y_churn_pred)):
churn = y_churn_pred[i]
ltv = y_ltv_pred[i]
# AI agent's decision logic:
if churn == 1 and ltv < 2500:
# If the customer is predicted to churn and their LTV is low, offer them a discount to retain them
decision = "Offer Discount"
elif churn == 0:
# If the customer is not predicted to churn, continue with the current strategy
decision = "Retain"
else:
# If the customer is predicted to churn but their LTV is high, consider letting them leave without intervention
decision = "No Action"
# Output the decision for each customer
print(f"Customer {i + 1}: Churn Prediction = {churn}, LTV Prediction = {ltv:.2f}, Decision = {decision}")

output
Random Forest Churn Prediction Accuracy: 1.00
Customer 1: Churn Prediction = 0, LTV Prediction = 1200.00, Decision = Retain
Customer 2: Churn Prediction = 0, LTV Prediction = 1800.00, Decision = Retain
Customer 3: Churn Prediction = 0, LTV Prediction = 1600.00, Decision = Retain
Customer 4: Churn Prediction = 1, LTV Prediction = 2200.00, Decision = Offer Discount
Customer 5: Churn Prediction = 1, LTV Prediction = 2500.00, Decision = No Action
Customer 6: Churn Prediction = 1, LTV Prediction = 3000.00, Decision = No Action
Customer 7: Churn Prediction = 0, LTV Prediction = 3500.00, Decision = Retain
Customer 8: Churn Prediction = 1, LTV Prediction = 4000.00, Decision = No Action
How Agents will manage supply chains
Supply Chain Management with Deep Learning
In supply chain management, demand forecasting is essential to anticipate the required stock levels. We can use a deep neural network (DNN) to predict demand based on historical sales data.
Example: Demand Forecasting with DNN (Keras)
# Install necessary libraries
# pip install tensorflow pandas scikit-learn
import numpy as np
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
# Sample historical sales data (months and units sold)
data = {
'month': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12],
'units_sold': [100, 120, 150, 130, 180, 160, 170, 190, 220, 210, 250, 240]
}
# Create DataFrame
df = pd.DataFrame(data)
# Features (month) and target (units sold)
X = df[['month']].values
y = df['units_sold'].values
# Normalize the features and target using MinMaxScaler
scaler_X = MinMaxScaler(feature_range=(0, 1))
scaler_y = MinMaxScaler(feature_range=(0, 1))
X_scaled = scaler_X.fit_transform(X)
y_scaled = scaler_y.fit_transform(y.reshape(-1, 1))
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y_scaled, test_size=0.2, shuffle=False)
# Build a Deep Neural Network (DNN) model using Keras
model = Sequential()
model.add(Dense(64, input_dim=1, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='linear'))
# Compile the model
model.compile(optimizer='adam', loss='mean_squared_error')
# Train the model
model.fit(X_train, y_train, epochs=100, batch_size=2)
# Make predictions on the test set
y_pred_scaled = model.predict(X_test)
# Inverse scaling to get the predicted demand in original units
y_pred = scaler_y.inverse_transform(y_pred_scaled)
print("Predicted demand for next 3 months:", y_pred)
# AI agent decision (e.g., reorder inventory)
current_stock = 500
reorder_point = 200
for i, demand in enumerate(y_pred, start=1):
if current_stock < demand:
order_quantity = demand - current_stock
print(f"Month {i}: Reorder {order_quantity} units")
current_stock += order_quantity
else:
print(f"Month {i}: No need to reorder, sufficient stock.")
Explanation:
Deep Learning Model: A simple DNN (Deep Neural Network) is used to predict demand based on historical sales data.
AI Agent's Role: Based on the predicted demand, the AI agent autonomously decides whether to reorder stock by comparing it with the current inventory.
- HR Management with Deep Learning
For HR management, an AI agent can be trained to screen resumes and predict employee performance based on historical data.
Example: Employee Performance Prediction using DNN (Keras)
# Install necessary libraries
# pip install tensorflow pandas
import numpy as np
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
# Sample employee data (age, tenure, performance score)
data = {
'age': [22, 25, 27, 32, 45, 50, 55, 30],
'tenure': [1, 2, 3, 4, 5, 6, 7, 8],
'performance_score': [80, 85, 90, 92, 95, 100, 97, 88] # Target: Performance Score
}
# Create DataFrame
df = pd.DataFrame(data)
# Features (age, tenure) and target (performance score)
X = df[['age', 'tenure']].values
y = df['performance_score'].values
# Normalize the features and target using MinMaxScaler
scaler_X = MinMaxScaler(feature_range=(0, 1))
scaler_y = MinMaxScaler(feature_range=(0, 1))
X_scaled = scaler_X.fit_transform(X)
y_scaled = scaler_y.fit_transform(y.reshape(-1, 1))
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y_scaled, test_size=0.2)
# Build a Deep Neural Network (DNN) model for performance prediction
model = Sequential()
model.add(Dense(64, input_dim=2, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='linear'))
# Compile the model
model.compile(optimizer='adam', loss='mean_squared_error')
# Train the model
model.fit(X_train, y_train, epochs=100, batch_size=2)
# Make predictions
y_pred_scaled = model.predict(X_test)
# Inverse scaling to get the predicted performance scores
y_pred = scaler_y.inverse_transform(y_pred_scaled)
print("Predicted performance scores:", y_pred)
# AI agent decision on employee evaluation based on predicted scores
for i, score in enumerate(y_pred, start=1):
if score < 90:
decision = "Needs Improvement"
else:
decision = "Good"
print(f"Employee {i}: Predicted performance score = {score[0]:.2f}, Decision = {decision}")
Explanation:
Deep Learning Model: A DNN is trained to predict employee performance scores based on their age and tenure.
AI Agent's Role: The agent evaluates employees based on their predicted performance scores and autonomously decides on performance reviews or improvement strategies.
- Customer Support with Deep Learning
AI agents can handle customer support tickets, classify issues, and provide responses without human intervention.
Example: Classifying Customer Issues using CNN (Keras)
# Install necessary libraries
# pip install tensorflow pandas nltk
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv1D, MaxPooling1D, Flatten, Dense, Embedding
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
# Sample customer support tickets
data = {
'ticket_id': [1, 2, 3, 4, 5],
'issue_description': [
'Cannot login to my account',
'Order status not updating',
'I want to change my shipping address',
'Payment failed for my recent purchase',
'How can I track my order?'
],
'issue_category': ['Account Issue', 'Order Status', 'Shipping Issue', 'Payment Issue', 'Order Status']
}
# Create DataFrame
df = pd.DataFrame(data)
# Tokenize the issue descriptions
tokenizer = Tokenizer(num_words=100)
tokenizer.fit_on_texts(df['issue_description'])
X = tokenizer.texts_to_sequences(df['issue_description'])
X = pad_sequences(X, maxlen=10) # Padding the sequences to the same length
# Convert categories to numerical labels
category_map = {'Account Issue': 0, 'Order Status': 1, 'Shipping Issue': 2, 'Payment Issue': 3}
y = df['issue_category'].map(category_map).values
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Build a Convolutional Neural Network (CNN) for text classification
model = Sequential()
model.add(Embedding(input_dim=100, output_dim=50, input_length=10))
model.add(Conv1D(filters=64, kernel_size=3, activation='relu'))
model.add(MaxPooling1D(pool_size=2))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dense(4, activation='softmax')) # 4 categories
# Compile the model
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Train the model
model.fit(X_train, y_train, epochs=10, batch_size=2)
# Predict the issue category for new tickets
y_pred = model.predict(X_test)
# Output predicted categories
predicted_labels = [category_map.inverse_transform([label.argmax()]) for label in y_pred]
print("Predicted categories:", predicted_labels)
# AI agent decision: Generate automated responses based on category
responses = {
0: "Please reset your password or contact support.",
1: "Your order is being processed. Please check the order page for updates.",
2: "You can update your shipping address through your account settings.",
3: "Please verify your payment details or contact billing support."
}
for i, label in enumerate(predicted_labels):
print(f"Ticket {i+1} Response: {responses[label[0]]}")
Explanation:
Deep Learning Model: A Convolutional Neural Network (CNN) is used to classify customer support tickets based on the issue description.
AI Agent's Role: The agent classifies customer issues (e.g., account, order status, payment) and autonomously generates a response based on the classified issue, handling the customer inquiry without human involvement.
FAQ/PROMPT
Prompt
i am developing webisite in react backend python where i have to verify image content document how ai agent and deep leaning plays role wexplian with full coding example
"How AI Agents and Deep Learning Models Are Revolutionizing Image and Document Verification"
"The Future of Automated Content Moderation: Integrating AI Agents with Deep Learning"
"Building an AI-Powered Verification System: A Step-by-Step Guide with React and Python"
"Enhancing Image & Document Validation: How AI Agents Orchestrate Deep Learning Models"
"From React Frontend to Deep Learning Backend: A Full-Stack Approach to Image and Document Verification"
"AI Agent Integration in Web Applications: Unlocking the Power of Deep Learning for Content Verification"
"Deep Learning for Image and Document Verification: How AI Agents Improve Accuracy and Efficiency"
"Automating Content Moderation with AI Agents: Deep Learning in Action"
"Building Secure Web Applications: Integrating AI Agents with Deep Learning Models for Real-time Verification"
"AI Agent Workflow in Content Verification: Leveraging Deep Learning for Smarter Decision-Making"
FAQ
who perform the task of decision making and repetitive task
Ai agent
who plays the role of brain of ai agent to prediction
Machine learning/Deep learning
How to Orchestrating multiple ML/DL models into a single workflow
Using AI agent
Give 3 example where AI agents manage processes with minimal human input
Supply Chain,HR Management,Customer Support
list out some Pre-trained AI Models
Google Cloud Vision API,Clarifai,DeepAI,Pretrained.ai,Keras Applications
Most widely used pre-trained AI models
TensorFlow/Keras Models
Which kind of model to be used for Image classification, object detection, facial recognition,dimage document content verification
TensorFlow/Keras Models(MobileNetV2, InceptionV3, ResNet, VGG16)
which kind of model to be used for text generation, question answering, text classification.
Hugging Face Transformers(BERT, GPT, T5, RoBERTa, DistilBERT)
How AI agent Orchestrating multiple ML/DL models into a single workflow
Give 3 example in different field where AI agent need ml
Healthcare:
ML predicts disease risk → AI Agent advises treatment plan + schedules doctor visit.
Finance:
ML forecasts stock price → AI Agent makes autonomous portfolio adjustments.
Customer Support:
NLP (DL model) understands query → AI Agent solves issue or routes to human.
Autonomous Vehicles:
DL processes camera/lidar data → AI Agent decides braking/steering.

Top comments (0)