Spark’s driver (your app) asks the manager for executors; Spark’s scheduler breaks your job into stages & tasks (one per partition) and runs them on executors.
How to control it (common knobs)
Parallelism: partitions (repartition, coalesce, numSlices)
Executors/cores/memory: --conf on submit or SparkConf
Dynamic allocation: spark.dynamicAllocation.enabled=true
Example (code + useful runtime checks)
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("SchedulingDemo")
.getOrCreate())
sc = spark.sparkContext
# Control initial parallelism via numSlices
rdd = sc.parallelize(range(1_000_000), numSlices=16)
# Partition-level compute (creates 16 tasks)
def sum_sq(iterable):
s = 0
for x in iterable:
s += x*x
return [s]
per_part = rdd.mapPartitions(sum_sq)
total = per_part.reduce(lambda a,b: a+b)
print("Total:", total)
# See the lineage/stages planning (driver-side)
print(rdd.toDebugString())
Submit with executor controls
spark-submit \
--master yarn \
--deploy-mode cluster \
--conf spark.executor.instances=6 \
--conf spark.executor.cores=4 \
--conf spark.executor.memory=6g \
--conf spark.dynamicAllocation.enabled=false \
scheduling_demo.py
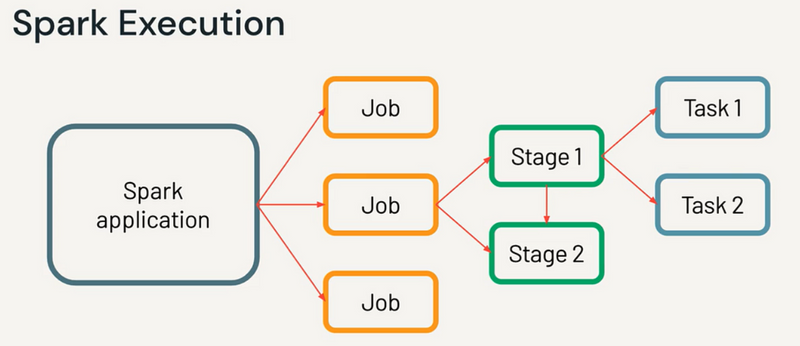
Understanding Jobs, Stages, Tasks, and Partitions in Spark
:
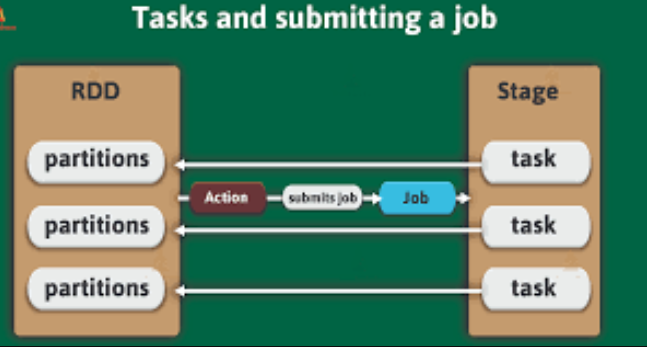
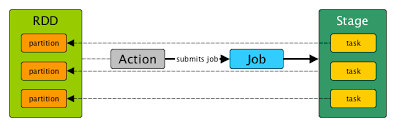
Job: A complete computation triggered by an action (e.g., collect(), show(), save()).
Stage: A logical division of the job, typically caused by wide transformations (like groupBy, join, etc.) that require shuffling of data.
Task: The smallest unit of work. Each stage is divided into tasks that are executed in parallel on different partitions of the data.
Partition: A physical division of data that Spark distributes across nodes in the cluster.
Simple DataFrame Transformation (Filter and Group By)
In this example, Spark will break your job into two stages:
Stage 1: Read data and filter based on a condition.
Stage 2: Group the data based on a key and apply an aggregation.
Example Code:
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[4]").appName("FilterAndGroupBy").getOrCreate()
# Read the data
data = spark.read.csv("file:///tmp/small_data.csv", header=True, inferSchema=True)
# Apply transformations
filtered_data = data.filter(data["age"] > 30)
grouped_data = filtered_data.groupBy("department").agg({"salary": "avg"})
grouped_data.show()
Stage 1: filter operation (applies on a partitioned dataset).
Stage 2: groupBy and aggregation (shuffle data between partitions).

- Join Operation Between Two Datasets
Spark breaks the job into stages when performing a shuffle join. The data is shuffled across the network to ensure that all rows with the same join key end up on the same partition.
Example Code:
df1 = spark.read.csv("file:///tmp/employees.csv", header=True, inferSchema=True)
df2 = spark.read.csv("file:///tmp/departments.csv", header=True, inferSchema=True)
joined_df = df1.join(df2, df1["department_id"] == df2["id"])
joined_df.show()
Stage 1: Read both datasets and filter out rows based on partitions.
Stage 2: Shuffle data for the join operation and perform the join across partitions.
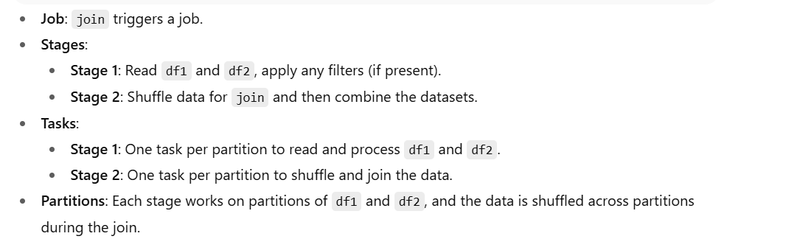
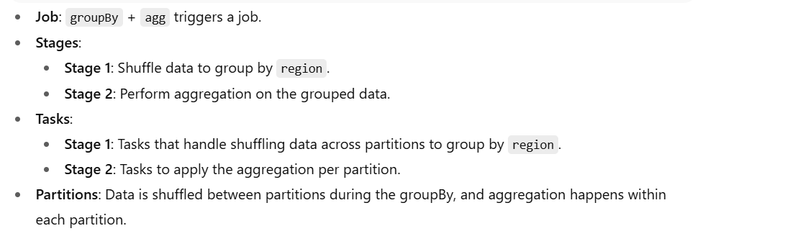
- Wide Transformation with groupBy and agg
When you apply wide transformations like groupBy, Spark must shuffle data across the cluster to bring the required rows together for aggregation.
Example Code:
df = spark.read.csv("file:///tmp/large_sales_data.csv", header=True, inferSchema=True)
result = df.groupBy("region").agg({"sales": "sum"})
result.show()
Stage 1: Shuffle data to group by region.
Stage 2: Aggregate the sales per region.
- Cache or Persisted Dataset
When you persist or cache a dataset, Spark’s scheduler will break the job into stages to store data in memory efficiently. This can speed up subsequent actions.
Example Code:
df = spark.read.csv("file:///tmp/large_data.csv", header=True, inferSchema=True)
# Caching
df.cache()
# Trigger a job to compute and cache
df.count()
Stage 1: Read the data and persist it.
Stage 2: Cache the dataset after a count operation.

- Data Shuffling in repartition Operation
When you perform repartition(), Spark needs to shuffle the data between partitions to achieve the desired number of partitions.
Example Code:
df = spark.read.csv("file:///tmp/sales_data.csv", header=True, inferSchema=True)
# Repartitioning data
repartitioned_df = df.repartition(4)
repartitioned_df.show()
Stage 1: Read data.
Stage 2: Shuffle data to create 4 partitions.

- Window Function with Partitioning
When using window functions, Spark’s scheduler will break the job into stages to partition the data appropriately and perform the window operation on each partition.
Example Code:
from pyspark.sql.window import Window
from pyspark.sql.functions import rank
df = spark.read.csv("file:///tmp/employee_sales.csv", header=True, inferSchema=True)
# Window specification
window_spec = Window.partitionBy("department").orderBy("sales")
# Apply window function
ranked_df = df.withColumn("rank", rank().over(window_spec))
ranked_df.show()
Stage 1: Partition the data based on department.
Stage 2: Apply window function (e.g., rank).

- Repartitioning Data Based on a Key
When performing a key-based repartition (e.g., repartitionByRange()), Spark will break the job into stages that involve shuffling data across partitions based on sorting keys.
Example Code:
df = spark.read.csv("file:///tmp/data.csv", header=True, inferSchema=True)
# Repartition data based on a key
repartitioned_df = df.repartitionByRange(4, "age")
repartitioned_df.show()
Stage 1: Shuffle the data and partition it by age.
Stage 2: Sort the data within the new partitions.

- ReduceByKey in RDD Operations
When using reduceByKey(), Spark performs a shuffle operation that breaks the job into stages. The shuffling involves grouping data by keys, which are redistributed to different partitions.
Example Code:
rdd = spark.sparkContext.parallelize([("a", 1), ("b", 1), ("a", 2), ("b", 3)])
result = rdd.reduceByKey(lambda x, y: x + y)
result.collect()
Stage 1: Shuffle the data by key.
Stage 2: Apply the reduce function to aggregate values by key.

- Writing Data to HDFS
When writing large data to distributed storage like HDFS, Spark performs operations that involve partitioning and breaking the data into stages to optimize the writing process.
Example Code:
df = spark.read.csv("file:///tmp/large_data.csv", header=True, inferSchema=True)
# Write to HDFS
df.write.parquet("hdfs://namenode/data/output")
Stage 1: Read the data.
Stage 2: Partition data for efficient write to HDFS.

- Streaming Data Processing
In Spark Streaming, the job is divided into micro-batches where each micro-batch is processed in stages. This happens for every incoming batch of streaming data.
Example Code:
from pyspark.streaming import StreamingContext
ssc = StreamingContext(spark.sparkContext, 10)
# Create DStream
streaming_data = ssc.socketTextStream("localhost", 9999)
# Process the stream
streaming_data.pprint()
ssc.start()
ssc.awaitTermination()
Stage 1: Process incoming streaming data.
Stage 2: Partition data to process batches every 10 seconds.

Top comments (0)