SparkContext Task
Creating a SparkContext
Difference between SparkContext and spark session
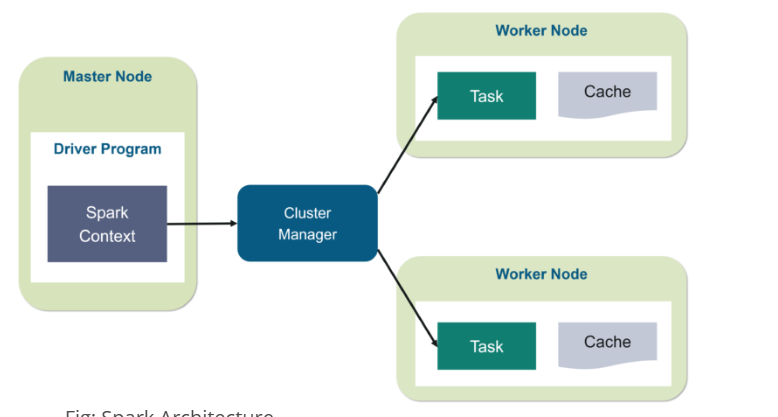
In Spark’s architecture, the SparkContext object connects your driver program to a Spark cluster, manages jobs, and hands out tasks to worker nodes.
It’s the primary object in Spark Core that allows your application to talk to the Spark cluster.
SparkContext Task
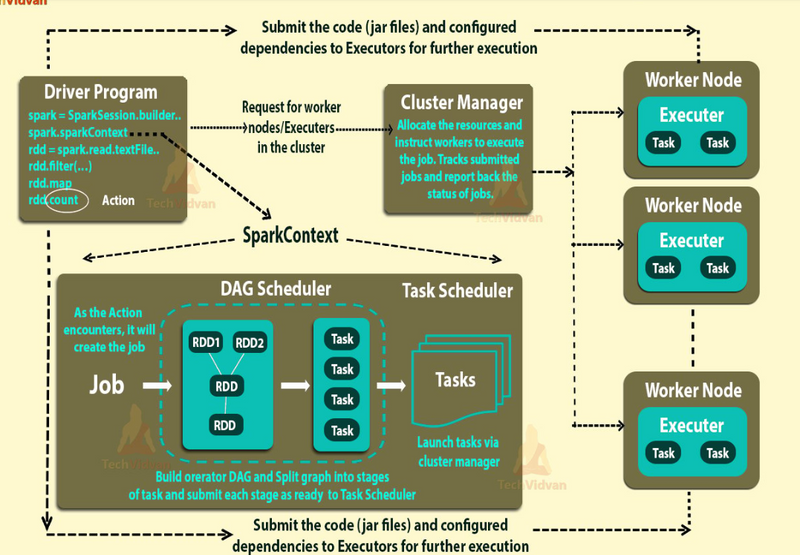
Connecting to the cluster manager (Standalone, YARN, Mesos, Kubernetes)Read More
Coordinating executors and task schedulingRead More
Creating RDDs from data sources or collectionsRead More
Managing configuration and job execution
Providing access to services like the Hadoop FileSystem, broadcast variables, and accumulators.
It’s the main object that creates and coordinates distributed operations in Spark Core.
Handles: cluster communication, job scheduling, resource management, and much more.
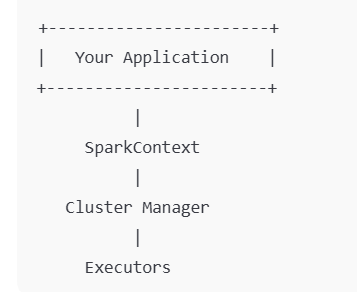
Every Spark application has (or starts with) a SparkContext.
Creating a SparkContext
Note
In modern Spark (2.x+), we usually create it via SparkSession, but you can still work with it directly.
from pyspark import SparkConf, SparkContext
# Create Spark configuration
conf = SparkConf() \
.setAppName("SparkContextExample") \
.setMaster("local[2]") # local mode with 2 threads
# Initialize SparkContext
sc = SparkContext(conf=conf)
# --- Using SparkContext ---
# Create RDD from a Python list
data = [1, 2, 3, 4, 5]
rdd = sc.parallelize(data)
# Transformation + Action
squares = rdd.map(lambda x: x * x)
print("Squares:", squares.collect())
# Read a text file into RDD
text_rdd = sc.textFile("file:///tmp/sample.txt")
print("Number of lines:", text_rdd.count())
# Broadcast variable
broadcast_val = sc.broadcast([10, 20, 30])
print("Broadcast value:", broadcast_val.value)
# Accumulator
accum = sc.accumulator(0)
rdd.foreach(lambda x: accum.add(x))
print("Accumulator sum:", accum.value)
# Stop SparkContext
sc.stop()

Explanation
Set up Spark in local mode
conf = SparkConf().setAppName("SparkContextExample").setMaster("local[2]")
sc = SparkContext(conf=conf)
local[2] = run Spark on your single machine using 2 worker threads (like 2 tiny executors). Great for learning/tests.
Driver creates a SparkContext (entry point) and talks to the two worker threads.
Build an RDD from a Python list
data = [1, 2, 3, 4, 5]
rdd = sc.parallelize(data)
parallelize slices the list into partitions so tasks can run in parallel (with local[2], two tasks at a time).

Transform then trigger an action
squares = rdd.map(lambda x: x * x) # transformation (lazy)
print("Squares:", squares.collect()) # action (executes)
Transformations (like map) are lazy: Spark builds a plan (DAG) but does nothing yet.
collect() is an action: it triggers execution, runs tasks on the workers, and returns results to the driver.
Expected output: Squares: [1, 4, 9, 16, 25].
Read a text file and count lines
text_rdd = sc.textFile("file:///tmp/sample.txt")
print("Number of lines:", text_rdd.count())
textFile creates an RDD where each element is a line.
count() is an action; it returns how many lines exist.
If you saw Number of lines: 3, it means the file has 3 newline-separated lines. (Exactly how many lines are in /tmp/sample.txt on your machine.)
Note: In cluster mode, file:// must point to a path visible to each worker; in local[...] you’re fine.
Broadcast variable (read-only, shipped once to workers)
broadcast_val = sc.broadcast([10, 20, 30])
print("Broadcast value:", broadcast_val.value)
What it is: a small, read-only object that Spark sends once to every executor/worker.
Why: avoids resending the same data with every task or doing an expensive join.
In your snippet you just print it; a real use would be:
bc = sc.broadcast(set(["a","an","the"]))
words = text_rdd.flatMap(lambda line: line.split())
clean = words.filter(lambda w: w not in bc.value)
Output here: Broadcast value: [10, 20, 30].
Accumulator (driver-readable counter for metrics)
accum = sc.accumulator(0)
rdd.foreach(lambda x: accum.add(x))
print("Accumulator sum:", accum.value)
What it is: a write-only (for workers) / read-only (for driver) counter. Good for metrics (e.g., “bad rows seen”).
foreach runs on the workers; each element adds to the accumulator.
For your data [1,2,3,4,5], the sum becomes 15.
Output: Accumulator sum: 15.
Tips:
Accumulator values are reliable after an action runs.
Because tasks can retry, accumulators are for monitoring, not core business logic.
Modern API prefers sc.longAccumulator("name") over sc.accumulator(0).
Clean shutdown
sc.stop()
Releases resources and closes the Spark app
Summary
Quick expected output (if /tmp/sample.txt has 3 lines)

Squares: [1, 4, 9, 16, 25]
Number of lines: 3
Broadcast value: [10, 20, 30]
Accumulator sum: 15
Difference between SparkContext and spark session
SparkContext is the original entry point to Apache Spark (pre–Spark 2.0).
SparkSession was introduced in Spark 2.0 to unify SparkContext, SQLContext, and HiveContext into a single entry point.


SparkSession
|
--> SparkContext (for RDD & low-level cluster interaction)
--> SQLContext (for DataFrame & SQL operations)
Old style (pre–2.0)
from pyspark import SparkConf, SparkContext
from pyspark.sql import SQLContext
conf = SparkConf().setAppName("OldWay").setMaster("local[2]")
sc = SparkContext(conf=conf)
sqlContext = SQLContext(sc)
# RDD
rdd = sc.parallelize([1, 2, 3])
print(rdd.collect())
# DataFrame
df = sqlContext.read.json("people.json")
df.show()
Modern style (2.0+)
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("NewWay") \
.master("local[2]") \
.getOrCreate()
# DataFrame
df = spark.read.json("people.json")
df.show()
# RDD (via SparkContext inside SparkSession)
rdd = spark.sparkContext.parallelize([1, 2, 3])
print(rdd.collect())
Using SparkContext from SparkSession
In all modern PySpark code, you use SparkSession, but you can always get the underlying SparkContext:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("MyApp").getOrCreate()
sc = spark.sparkContext # Access the SparkContext if needed
# Use sc for RDD work
data = [10, 20, 30]
rdd = sc.parallelize(data)
print(rdd.collect())
When to Use
Use SparkSession for all new Spark applications — it gives you everything:
✅ DataFrame API
✅ SQL queries
✅ RDD API via .sparkContext
✅ Catalog & Hive integration
Use SparkContext directly only when:
You are working in very old Spark code (pre–2.0)
You specifically want only the low-level RDD API without higher-level features
Quick Analogy
SparkContext → like the engine of a car (makes the cluster run, handles RDDs)
SparkSession → like the dashboard that controls the engine and gives extra features like GPS, media, AC, etc.

Top comments (0)