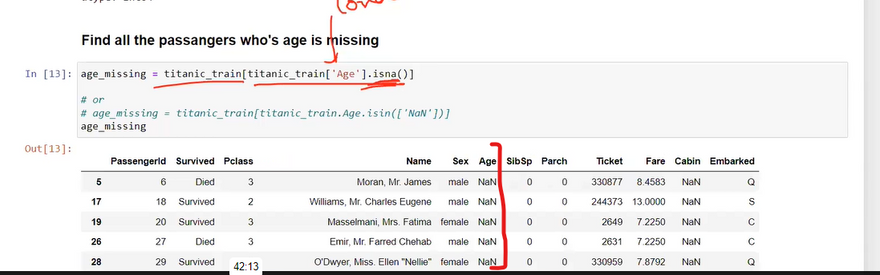
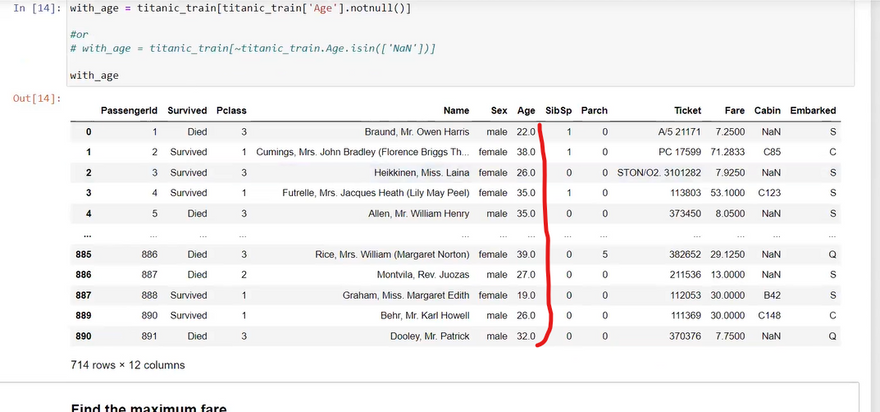
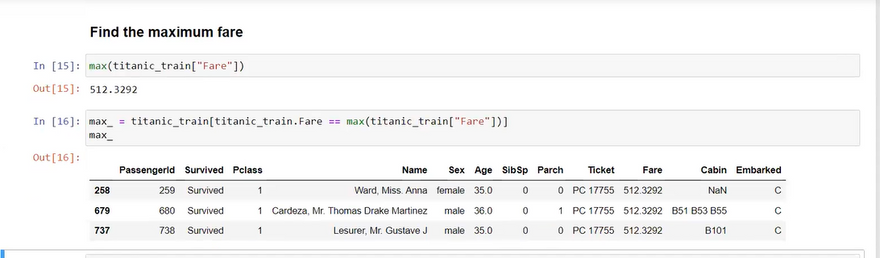
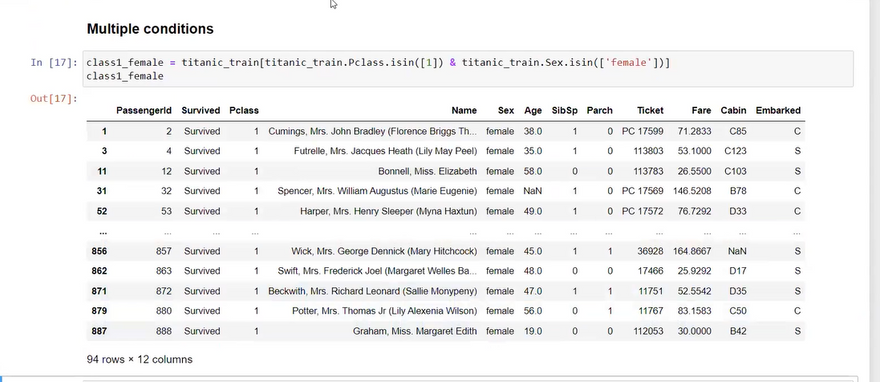
Here are 20 different data cleaning operations you can perform using Django:
Removing leading and trailing whitespace:
cleaned_data_item['name'] = data.name.strip()
def clean_data(request):
if request.method == 'POST':
form = DataForm(request.POST)
if form.is_valid():
text = form.cleaned_data['text']
cleaned_text = text.strip()
return render(request, 'cleaner/result.html', {'cleaned_text': cleaned_text})
else:
form = DataForm()
return render(request, 'cleaner/clean.html', {'form': form})
Converting text to lowercase:
cleaned_data_item['name'] = data.name.lower()
Removing punctuation:
cleaned_data_item['text'] = re.sub(r'[^\w\s]', '', data.text)
Handling missing values by filling them with a default value:
cleaned_data_item['age'] = data.age or 0
def clean_data(request):
if request.method == 'POST':
form = DataForm(request.POST)
if form.is_valid():
text = form.cleaned_data['text']
cleaned_data_item = text if text else 'Default Value'
return render(request, 'cleaner/result.html', {'cleaned_data_item': cleaned_data_item})
else:
form = DataForm()
return render(request, 'cleaner/clean.html', {'form': form})
Removing duplicate records or get unique record like group by:
cleaned_data = list(set(cleaned_data))
Examples
cleaned_data = [1, 2, 3, 2, 4, 3, 5, 1, 6, 7, 6]
unique_data = list(set(cleaned_data))
print(unique_data)
Output:
[1, 2, 3, 4, 5, 6, 7]
2nd way
def clean_data(request):
if request.method == 'POST':
# Remove duplicate records
duplicate_records = Data.objects.values('text').annotate(count=models.Count('id')).filter(count__gt=1)
for record in duplicate_records:
duplicate_items = Data.objects.filter(text=record['text'])
duplicate_items[1:].delete()
# Retrieve cleaned data
cleaned_data = Data.objects.all()
return render(request, 'cleaner/result.html', {'cleaned_data': cleaned_data})
else:
return render(request, 'cleaner/clean.html')
3rd way
def clean_data(request):
if request.method == 'POST':
# Remove duplicate records
cleaned_data = Data.objects.order_by('text').distinct('text')
return render(request, 'cleaner/result.html', {'cleaned_data': cleaned_data})
else:
return render(request, 'cleaner/clean.html')
4th way
def clean_data(request):
if request.method == 'POST':
# Remove duplicate records
cleaned_data = Data.objects.values('text').distinct()
return render(request, 'cleaner/result.html', {'cleaned_data': cleaned_data})
else:
return render(request,
5th way
def clean_data(request):
if request.method == 'POST':
# Retrieve all data
all_data = Data.objects.all()
# Remove duplicate records using sets
cleaned_data = list(set(all_data))
return render(request, 'cleaner/result.html', {'cleaned_data': cleaned_data})
else:
return render(request, 'cleaner/clean.html')
6 th way
def clean_data(request):
if request.method == 'POST':
# Retrieve all data
all_data = Data.objects.all()
# Remove duplicate records using a temporary list
cleaned_data = []
seen_data = set()
for data in all_data:
if data.text not in seen_data:
cleaned_data.append(data)
seen_data.add(data.text)
return render(request, 'cleaner/result.html', {'cleaned_data': cleaned_data})
else:
return render(request, 'cleaner/clean.html')
Removing HTML tags from text:
cleaned_data_item['description'] = strip_tags(data.description)
Another Method
from bs4 import BeautifulSoup
def clean_data(request):
if request.method == 'POST':
# Get the input text
input_text = request.POST.get('text', '')
# Remove HTML tags using BeautifulSoup
cleaned_text = BeautifulSoup(input_text, "html.parser").get_text()
return render(request, 'cleaner/result.html', {'cleaned_text': cleaned_text})
else:
return render(request, 'cleaner/clean.html')
def clean_data(request):
if request.method == 'POST':
# Get the input text
input_text = request.POST.get('text', '')
# Remove HTML tags using regex pattern matching
cleaned_text = re.sub(r'<[^>]+>', '', input_text)
return render(request, 'cleaner/result.html', {'cleaned_text': cleaned_text})
else:
return render(request, 'cleaner/clean.html')
def clean_data(request):
if request.method == 'POST':
# Get the input text
input_text = request.POST.get('text', '')
# Remove HTML tags using Django's strip_tags()
cleaned_text = strip_tags(input_text)
return render(request, 'cleaner/result.html', {'cleaned_text': cleaned_text})
else:
return render(request, 'cleaner/clean.html')
import bleach
def clean_data(request):
if request.method == 'POST':
# Get the input text
input_text = request.POST.get('text', '')
# Remove HTML tags using the bleach library
cleaned_text = bleach.clean(input_text, tags=[], strip=True)
return render(request, 'cleaner/result.html', {'cleaned_text': cleaned_text})
else:
return render(request, 'cleaner/clean.html')
pip install html2text
import html2text
def clean_data(request):
if request.method == 'POST':
# Get the input text
input_text = request.POST.get('text', '')
# Remove HTML tags using the html2text library
cleaned_text = html2text.html2text(input_text)
return render(request, 'cleaner/result.html', {'cleaned_text': cleaned_text})
else:
return render(request, 'cleaner/clean.html')
pip install lxml
from lxml.html.clean import Cleaner
def clean_data(request):
if request.method == 'POST':
# Get the input text
input_text = request.POST.get('text', '')
# Remove HTML tags using the lxml library
cleaner = Cleaner()
cleaned_text = cleaner.clean_html(input_text)
return render(request, 'cleaner/result.html', {'cleaned_text': cleaned_text})
else:
return render(request, 'cleaner/clean.html')
Standardizing date formats:
cleaned_data_item['date'] = datetime.strptime(data.date, '%Y-%m-%d').date()
Handling outliers by replacing them with the median:
cleaned_data_item['income'] = np.where(data.income > threshold, median_income, data.income)
EXample
import numpy as np
import pandas as pd
# Example data
data = pd.DataFrame({
'income': [50000, 60000, 70000, 45000, 80000],
'threshold': [55000, 60000, 65000, 40000, 70000],
'median_income': [55000, 60000, 65000, 50000, 70000]
})
# Applying the condition and assigning new values
threshold = data['threshold']
median_income = data['median_income']
cleaned_data_item = pd.DataFrame()
cleaned_data_item['income'] = np.where(data['income'] > threshold, median_income, data['income'])
print(cleaned_data_item)
Output:
income
0 55000
1 60000
2 65000
3 45000
4 70000
Refer the blog handle-outliers-for-data-cleaning
Handling inconsistent capitalization:
cleaned_data_item['title'] = data.title.capitalize()
Removing stopwords from text:
cleaned_data_item['text'] = remove_stopwords(data.text)
Correcting misspelled words using a spell-checking library:
cleaned_data_item['description'] = spell_correct(data.description)
Example
import pandas as pd
from autocorrect import Speller
# Example data
data = pd.DataFrame({
'description': ['I', 'am', 'misspelled', 'wrod', 'in', 'this', 'sentence']
})
# Function to perform spell correction
def spell_correct(text):
spell = Speller(lang='en')
corrected_text = [spell(word) for word in text.split()]
return ' '.join(corrected_text)
# Applying spell correction to the 'description' column
data['description'] = spell_correct(data['description'])
print(data)
Output:
description
0 I
1 am
2 misspelled
3 word
4 in
5 this
6 sentence
Handling categorical data by encoding them using one-hot encoding:
cleaned_data_item['category'] = pd.get_dummies(data.category)
Example
for the 'category' column of a DataFrame named data. Dummy variables are binary variables representing categories or groups in a categorical variable. Each unique category in the 'category' column is transformed into a separate column, and a binary value (0 or 1) is assigned to indicate whether a particular row belongs to that category.
Here's an example to illustrate the code:
import pandas as pd
# Example data
data = pd.DataFrame({
'category': ['A', 'B', 'A', 'C', 'B', 'C']
})
# Creating dummy variables for the 'category' column
dummy_data = pd.get_dummies(data.category)
print(dummy_data)
Output:
A B C
0 1 0 0
1 0 1 0
2 1 0 0
3 0 0 1
4 0 1 0
5 0 0 1
In this example, the 'category' column has three unique categories: A, B, and C. After applying pd.get_dummies(data.category), three separate columns 'A', 'B', and 'C' are created. Each row in the dummy DataFrame represents the original category value in the 'category' column, and the corresponding column is set to 1 if it belongs to that category, and 0 otherwise.
The resulting dummy DataFrame is useful for encoding categorical variables as numeric values, which can be helpful in machine learning tasks where algorithms typically require numerical inputs. It allows incorporating categorical information into the analysis without assuming any ordinal relationship between the categories.
Removing outliers based on z-score:
cleaned_data = cleaned_data[np.abs(stats.zscore(cleaned_data)) < threshold]
Handling inconsistent date formats:
cleaned_data_item['date'] = dateparser.parse(data.date).strftime('%Y-%m-%d')
Removing irrelevant columns from the dataset:
cleaned_data_item.pop('column_name', None)
Examples
import pandas as pd
# Example dataset
data = pd.DataFrame({
'name': ['John', 'Jane', 'Mike'],
'age': [25, 30, 35],
'gender': ['Male', 'Female', 'Male'],
'income': [50000, 60000, 70000],
'occupation': ['Engineer', 'Doctor', 'Teacher']
})
print("Original Dataset:")
print(data)
# Removing an irrelevant column using pop()
column_name = 'occupation'
cleaned_data_item = data.pop(column_name)
print("\nDataset after removing the '{}' column:".format(column_name))
print(data)
Output:
Original Dataset:
name age gender income occupation
0 John 25 Male 50000 Engineer
1 Jane 30 Female 60000 Doctor
2 Mike 35 Male 70000 Teacher
Dataset after removing the 'occupation' column:
name age gender income
0 John 25 Male 50000
1 Jane 30 Female 60000
2 Mike 35 Male 70000
In this example, the original dataset contains five columns: 'name', 'age', 'gender', 'income', and 'occupation'. We want to remove the 'occupation' column as it is considered irrelevant for the analysis. By using the pop() method with the name of the column to remove, the column is removed from the DataFrame, and the resulting dataset only includes the relevant columns: 'name', 'age', 'gender', and 'income'.
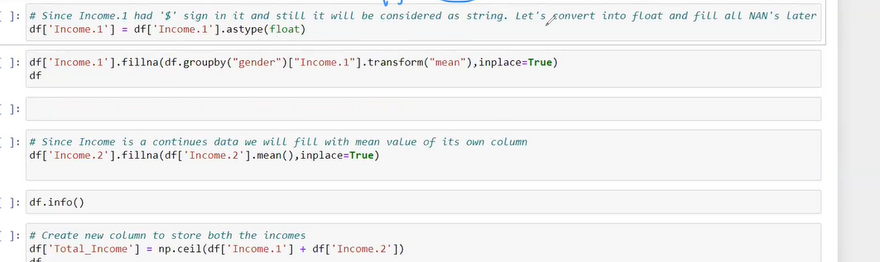
Handling missing values by imputing them with the mean:
cleaned_data_item['height'] = data.height.fillna(data.height.mean())
Normalizing numeric data to a specific range:
cleaned_data_item['rating'] = (data.rating - data.rating.min()) / (data.rating.max() - data.rating.min())
Handling inconsistent units of measurement by converting them to a common unit:
cleaned_data_item['weight'] = data.weight * 0.45359237
# Convert pounds to kilograms
Handling outliers by winsorizing them (replacing extreme values with the nearest non-extreme value):
cleaned_data_item['price'] = winsorize(data.price, limits=(0.05, 0.05))
Handling inconsistent categorical values by mapping them to a standardized set:
cleaned_data_item['gender'] = gender_mapping[data.gender]
These are just some examples of data cleaning operations that you can perform using Django. The specific operations you choose will depend on your dataset and the cleaning requirements.
Dataset

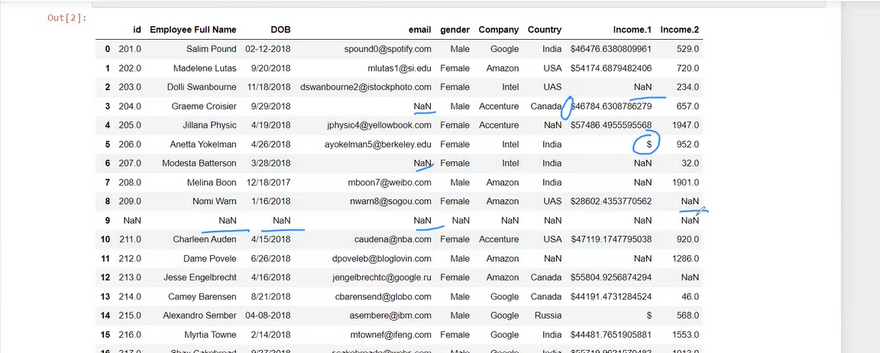
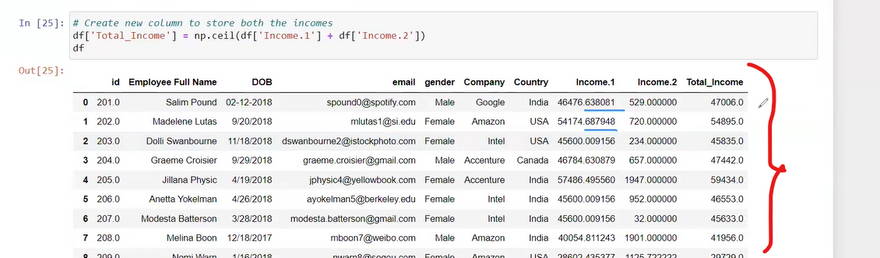
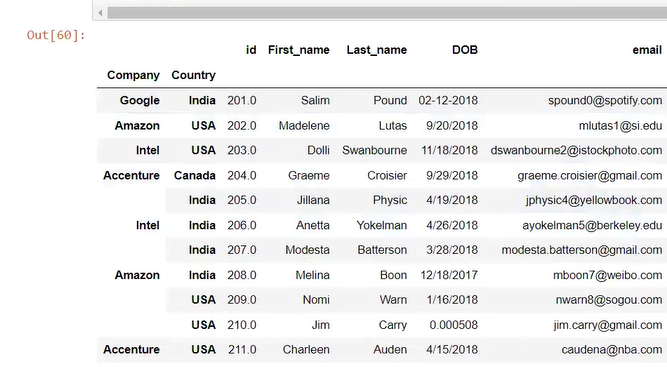
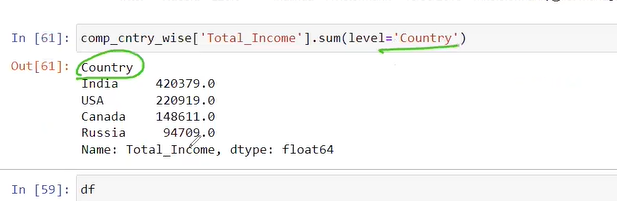
fill all data in index value 9
after running the command


here in all are nan in colunm

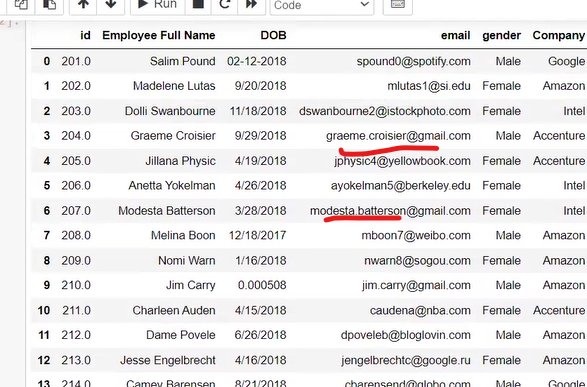
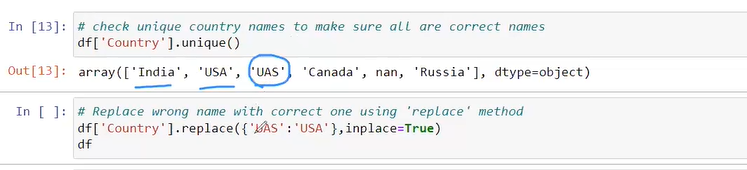

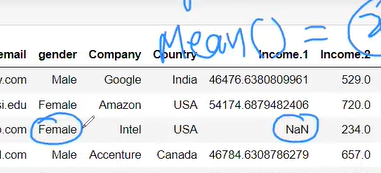
we fill categorical by most frequent category is india by mode not mean ,mean is only for integer or float numerical value



two way to fill nan either by group by or without groupby
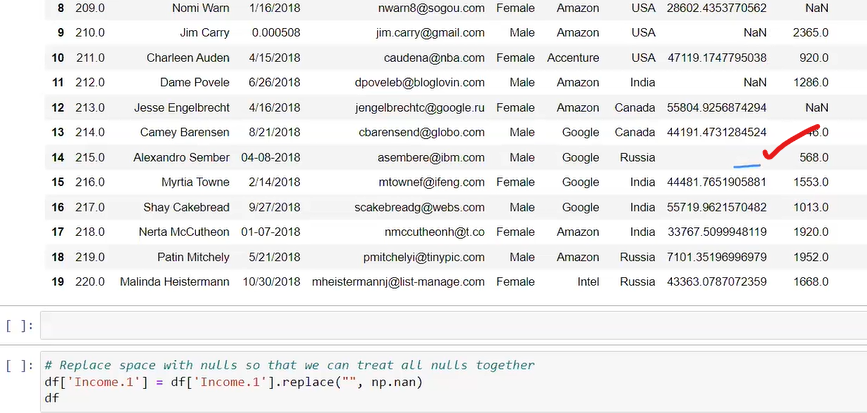
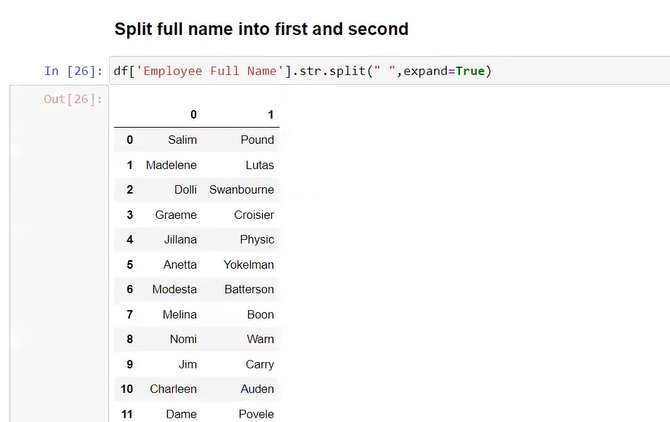
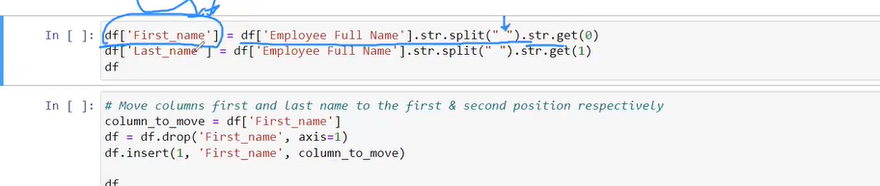
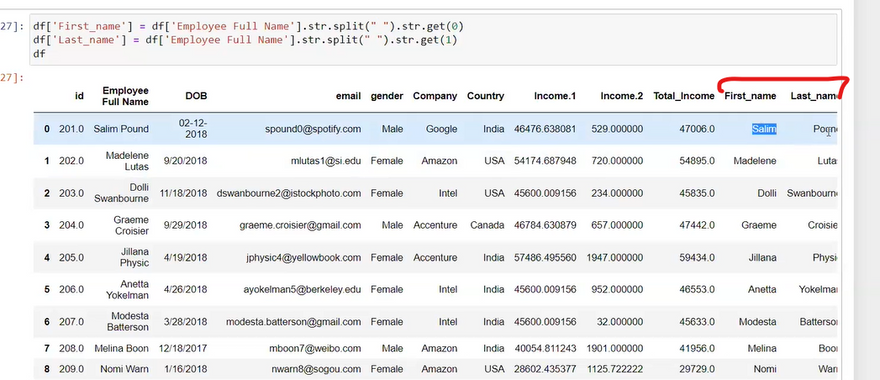

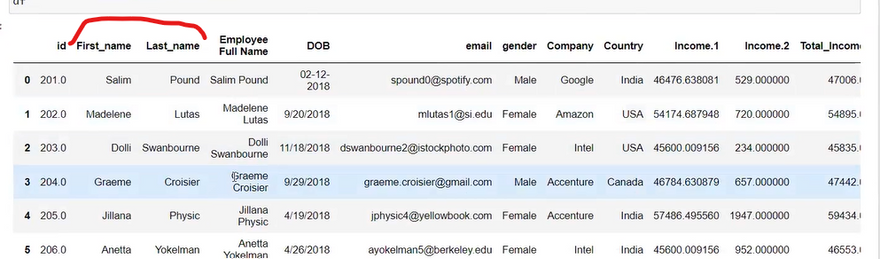





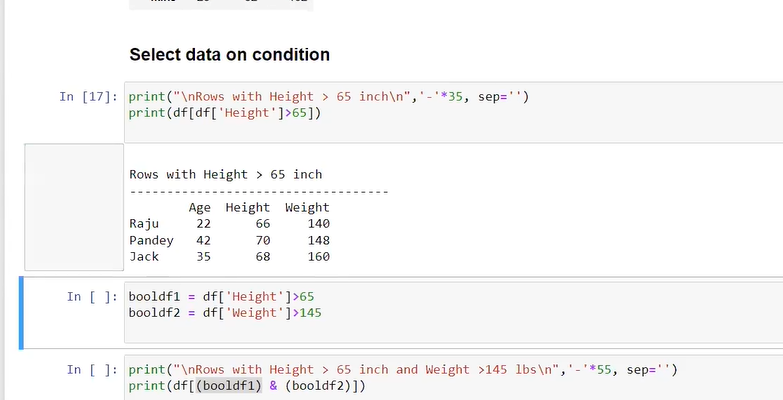
data=data[data['Price']!='Ask For Price']
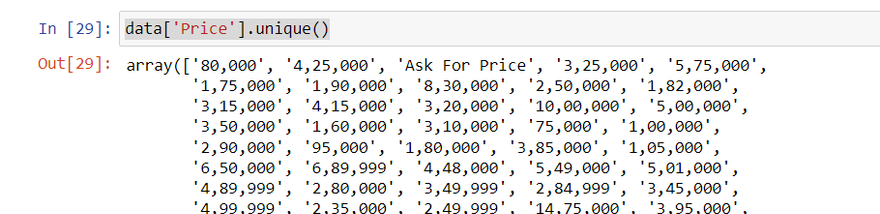
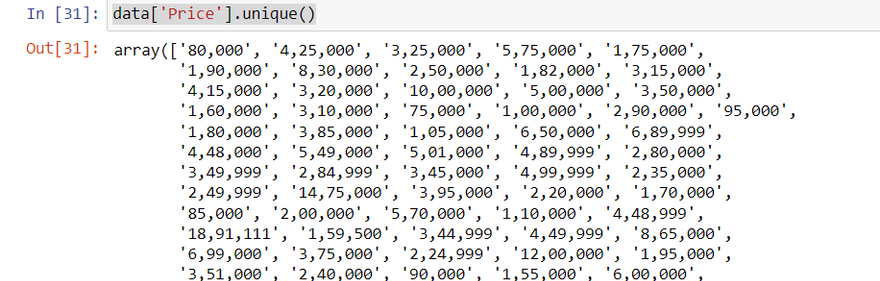
data['Price'] = data['Price'].astype(str).str.replace(',', '')
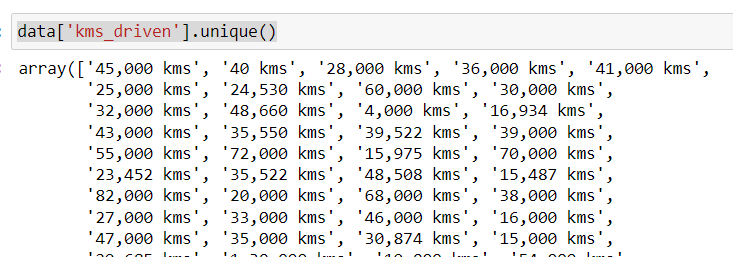
data['kms_driven']=data['kms_driven'].str.split().str.get(0).str.replace(',','')

Top comments (0)